分布式id生成策略,我和面试官扯了一个半小时
原文链接:https://mp.weixin.qq.com/s/yIE5NOj7nqCu2AnWCte1Rg
作者: 非科班的科班
面试官:小伙子,你还记得我吗?我是上次面试你的那个面试官。
我心想:我去,怎么会不记得,我又不是青年痴呆,上次害我画了那么多图,还使劲敲了一个多钟的电脑,满脑子都是你的阴影。
我:记得记得,您好,很高兴能通过二面,能够继续和您交流技术问题。
我违背良心说这话真的好吗,姑且就那么一次吧,面个试都那么难?
面试官又快速的扫了一下的简历,可能上次看过一次,都快过了一个多星期了,估计他都都忘了我的简历了吧。
面试官:我看你简历上面写着深入了解分布式,并且也做过分布式项目,挺好的,那你知道分布式项目中生成分布式ID的方法有哪些吗?
我:这个我知道,生成分布式Id的方法主要有以下几种:
-
数据库自增ID。
-
数据库水平拆分,设置初始值和相同的自增步长。
-
批量申请自增ID。
-
UUID生成。
-
Redis的方式。
-
雪花算法。
-
百度UidGenerator算法
-
美团Leaf算法
面试官:哦,不错能说出那么多,你能说一说对于上面的每一种方式的分析和理解吗?
我心想:我去,这下可糗大了,那么多,我只是大概知道主要的,怎么可能每一种都去了解和深入,一下子说了那么多不是给自己挖坑吗?
哎,没办法出来混,总是要还的,只能说自己知道的吧?不知道的大概粗糙的略过。
我:嗯嗯,好的。数据库的自增,很容易理解,开发过的人员都知道,在创建表的时候,指定主键auto_increment(自增)便可以实现。
我:但是使用数据库的自增ID,虽然简单,会带来ID重复的问题,并且单机版的ID自增,并且每次生成一个ID都会访问数据库一次,DB的压力也很大,并没有什么并发性能可言。
面试官:恩额。
我看看面试官正听着有味,时不时摸摸他稀少的发量额头,深邃的目光透露出他的沉稳,这可能就是一个成熟架构师的魅力吧,让多少码渣苦读《Java编程思想》《Java核心技术》《Effectice java》《Java并发编程实战》《代码整洁之道》《重构: 改善既有代码的设计》......,都无法达到的境界,我乘热打铁,接着下面的回答。
我:针对上面的数据库自增ID出现的问题:ID重复、性能不好。就出现了集群版的生成分布式ID方案。「数据库水平拆分,设置初始值和相同的自增步长」和「批量申请自增ID」。
我:「数据库水平拆分,设置初始值和相同的自增步长」是指在DB集群的环境下,将数据库进行水平划分,然后每个数据库设置「不同的初始值」和「相同的步长」,这样就能避免ID重复的情况。
面试官:小伙子,不好意思打断一下,你可以画个图吗,这个我有点没明白你讲的意思?
我能有什么办法啊,完全没办法,只能从裤兜里拿出笔和纸,快速的画了一张图。

我:我这里假设有三个数据库,为每一个数据库设置初始值,设置初始值可以通过下面的sql进行设置:
set @@auto_increment_offset = 1; // 设置初始值
set @@auto_increment_increment = 2; // 设置步长我:三个数据的初始值分别设置为1、2、3,一般步长设置为数据库的数据,这里数据库数量为3,所以步长也设置为3。
面试官:若是面对再次扩容的情况呢?
我:恩额,扩容的情况是这种方法的一个缺点,上面我说的步长一般设置为数据库的数量,这是在确保后期不会扩容的情况下,若是确定后期会有扩容情况,在前期设计的的时候可以将步长设置长一点,「预留一些初始值给后续扩容使用」。
我:总之,这种方案还是优缺点的,但是也有自己的优点,缺点就是:「后期可能会面对无ID初始值可分的窘境,数据库总归是数据库,抗高并发也是有限的」。
我:它的优点就是算是解决了「DB单点的问题」。
面试官:恩额。
我:「批量申请自增ID」的解决方案可以解决无ID可分的问题,它的原理就是一次性给对应的数据库上分配一批的id值进行消费,使用完了,再回来申请。
这次我很自觉的从裤兜里拿出笔和纸,画出了下面的这张图,历史总是那么惊人的相似。
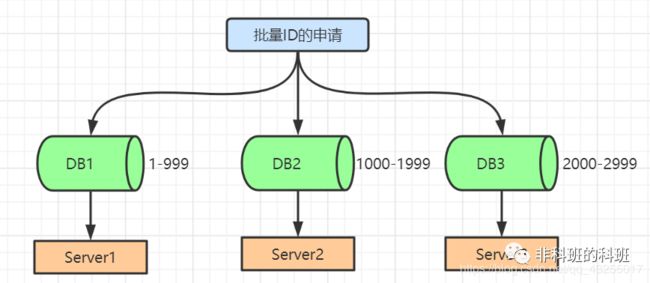
我:在设计的初始阶段可以设计一个有初始值字段,并有步长字段的表,当每次要申请批量ID的时候,就可以去该表中申请,每次申请后「初始值=上一次的初始值+步长」。
我:这样就能保持初始值是每一个申请的ID的最大值,避免了ID的重复,并且每次都会有ID使用,一次就会生成一批的id来使用,这样访问数据库的次数大大减少。
我:但是这一种方案依旧有自己的缺点,依然不能抗真正意义上的高并发。
我:第四种方式是使用「UUID生成」的方式生成分布式ID,UUID的核心思想是使用「机器的网卡、当地时间、一个随机数」来生成UUID。
我:使用UUID的方式只需要调用UUID.randomUUID().toString()就可以生成,这种方式方便简单,本地生成,不会消耗网络。
我:当时简单的东西,出现的问题就会越多,不利于存储,16字节128位,通常是以36位长度的字符串表示,很多的场景都不适合。
我:并且UUID生成的无序的字符串,查询效率低下,没有实际的业务含义,不具备自增特性,所以都不会使用UUID作为分布式ID来使用。
面试官:恩额,那你知道生成UUID的方式有几种吗?不知道没关系,这个只是作为一个扩展。
我:这个我只知道可以通过「当前的时间戳及机器mac地址」来生成,可以确保生成的UUID全球唯一,其它的没有了解过。
面试官:嗯嗯,没关系的。
我:为了解决上面纯关系型数据库生成分布式ID无法抗高并发的问题,可以使用Redis的方式来生成分布式ID。
我:Redis本身有incr和increby 这样自增的命令,保证原子性,生成的ID也是有序的。
我:Redis基于内存操作,性能高效,不依赖于数据库,数据天然有序,利于分页和排序。
我:但是这个方案也会有自己的缺点,因为增加了中间件,需要自己编码实现工作量增大,增加复杂度。
我:使用Redis的方式还要考虑持久化,Redis的持久化有两种「RDB和AOF」,「RDB是以快照的形式进行持久化,会丢失上一次快照至此时间的数据」。
我:「AOF可以设置一秒持久化一次,丢失的数据是秒内的」,也会存在可能上一次自增后的秒内的ID没有持久化的问题。
我:但是这种方法相对于上面的关系型数据库生成分布式ID的方法而言,已经优越了许多。
我:若是数据量比较大的话,重启Redis的时间也会比较长,可以采用Redis的集群方式。
面试官:你能手写一下Redis的生成分布式ID的工具类代码吗?
我奔溃了,我最怕手写了,因为工具类这种东西,基本就是项目开始的时候写一次,后面对后市重复使用,记不住,还要手写,这也太难为我怕虎了吧。
我:手写应该不行,因为有些API记不住,工具类基本就是项目开始的时候写一些,后续都没有去看过了,没有专门去记它。
我:我可以使用您的电脑吗?使用电脑应该可以敲出这些工具类。
面试官:可以的,这边电脑给你,你在这个测试项目下吧。
我:好的,谢谢。
时间流逝中........
大概敲了几分钟,废了九牛二虎之力,终于敲出来了,有好多API记不住,只能慢慢的找了,写了主要两种方式来生成分布式ID。
第一种是使用RedisAtomicLong 原子类使用CAS操作来生成ID。
@Service
public class RedisSequenceFactory {
@Autowired
RedisTemplate redisTemplate;
public void setSeq(String key, int value, Date expireTime) {
RedisAtomicLong counter = new RedisAtomicLong(key, redisTemplate.getConnectionFactory());
counter.set(value);
counter.expireAt(expireTime);
}
public void setSeq(String key, int value, long timeout, TimeUnit unit) {
RedisAtomicLong counter = new RedisAtomicLong(key, redisTemplate.getConnectionFactory());
counter.set(value);
counter.expire(timeout, unit);
}
public long generate(String key) {
RedisAtomicLong counter = new RedisAtomicLong(key, redisTemplate.getConnectionFactory());
return counter.incrementAndGet();
}
public long incr(String key, Date expireTime) {
RedisAtomicLong counter = new RedisAtomicLong(key, redisTemplate.getConnectionFactory());
counter.expireAt(expireTime);
return counter.incrementAndGet();
}
public long incr(String key, int increment) {
RedisAtomicLong counter = new RedisAtomicLong(key, redisTemplate.getConnectionFactory());
return counter.addAndGet(increment);
}
public long incr(String key, int increment, Date expireTime) {
RedisAtomicLong counter = new RedisAtomicLong(key, redisTemplate.getConnectionFactory());
counter.expireAt(expireTime);
return counter.addAndGet(increment);
}
} 第二种是使用redisTemplate.opsForHash()和结合UUID的方式来生成生成ID。
public Long getSeq(String key,String hashKey,Long delta) throws BusinessException{
try {
if (null == delta) {
delta=1L;
}
return redisTemplate.opsForHash().increment(key, hashKey, delta);
} catch (Exception e) { // 若是redis宕机就采用uuid的方式
int first = new Random(10).nextInt(8) + 1;
int randNo=UUID.randomUUID().toString().hashCode();
if (randNo < 0) {
randNo=-randNo;
}
return Long.valueOf(first + String.format("%16d", randNo));
}
}我把电脑移回给面试官,他很快的扫了一下我的代码,说了一句。
面试官:小伙子,不写注释哦,这个习惯不好哦。
我:哦哦,谢谢提醒,不好意思,下次我会注意的。
我:第六种方式是「雪花算法」,也是现在市面上比较流行的生成分布式ID的方法。
说着说着,我知道画图又是必不可少的了,于是在桌子上又画了起来,面试官好奇的看看我,知道了我在干啥,又耐心的等了等。
我:他是采用64bit作为id生成类型,并且将64bit划分为,如下图的几段。
我顺手把我画的图递给他看了看,接着对着这个图进行解释。

我:第一位作为标识位,因为Java中long类型的时代符号的,因为ID位正数,所以第一位位0。
我:接着的41bit是时间戳,毫秒级位单位,注意这里的时间戳并不是指当前时间的时间戳,而是值之间差(「当前时间-开始时间」)。
我:这里的开始时间一般是指ID生成器的开始时间,是由我们程序自己指定的。
我:接着后面的10bit:包括5位的「数据中心标识ID(datacenterId)和5位的机器标识ID(workerId)」,可以最多标识1024个节点(1<<10=1024)。
我:最后12位是序列号,12位的计数顺序支持每个节点每毫秒差生4096序列号(1<<12=4096)。
我:雪花算法使用数据中心ID和机器ID作为标识,不会产生ID的重复,并且是在本地生成,不会消耗网络,效率高,有数据显示,每秒能生成26万个ID。
我:但是雪花算法也是有自己的缺点,因为雪花算法的计算依赖于时间,若是系统时间回拨,就会产生重复ID的情况。
面试官:那对于时间回拨产生重复ID的情况,你有什么比较好的解决方案吗?
我:在雪花算法的实现中,若是其前置的时间等于当前的时间,就抛出异常,也可以关闭掉时间回拨。
我:对于回拨时间比较短的,可以等待回拨时间过后再生成ID。
面试官:你可以帮我敲一个雪花算法吗?我这键盘给你。
我:。。。
我:好的。
时间流逝中......
过了几分钟时间,也总算是把雪花算法给敲出来了,真正要老命,面个试怎么就那么难呢?
/**
* 雪花算法
* @author:黎杜
*/
public class SnowflakeIdWorker {
/** 开始时间截 */
private final long twepoch = 1530051700000L;
/** 机器id的位数 */
private final long workerIdBits = 5L;
/** 数据标识id的位数 */
private final long datacenterIdBits = 5L;
/** 最大的机器id,结果是31 */
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/** 最大的数据标识id,结果是31 */
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/** 序列的位数 */
private final long sequenceBits = 12L;
/** 机器ID向左移12位 */
private final long workerIdShift = sequenceBits;
/** 数据标识id向左移17位 */
private final long datacenterIdShift = sequenceBits + workerIdBits;
/** 时间截向左移22位*/
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/** 生成序列的掩码 */
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/** 工作机器ID(0~31) */
private long workerId;
/** 数据中心ID(0~31) */
private long datacenterId;
/** 毫秒内序列(0~4095) */
private long sequence = 0L;
/** 上次生成ID的时间截 */
private long lastTimestamp = -1L;
/**
* 构造函数
* @param workerId 工作ID (0~31)
* @param datacenterId 数据中心ID (0~31)
*/
public SnowflakeIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 获得下一个ID (该方法是线程安全的)
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = getCurrentTime();
//如果当前时间小于上一次生成的时间戳,说明系统时钟回退过就抛出异常
if (timestamp < lastTimestamp) {
throw new BusinessionException("回拨的时间为:"+lastTimestamp - timestamp);
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
} else { //时间戳改变,毫秒内序列重置
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) // 计算时间戳
| (datacenterId << datacenterIdShift) // 计算数据中心
| (workerId << workerIdShift) // 计算机器ID
| sequence; // 序列号
}
/**
*获得新的时间戳
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = getCurrentTime();
// 若是当前时间等于上一次的1时间就一直阻塞,知道获取到最新的时间(回拨后的时间)
while (timestamp <= lastTimestamp) {
timestamp = getCurrentTime();
}
return timestamp;
}
/**
* 获取当前时间
* @return 当前时间(毫秒)
*/
protected long getCurrentTime() {
return System.currentTimeMillis();
}为了给面试官留下个好印象,这下也写上了注解,免得他又说我,敲完我又把电脑移回给他,他快速的看了看,点了点头,嘴角露出一丝丝的笑意。
面试官:嗯,你的底子还算比价扎实,面试之前早有准备吧,看了很多的面试资料。
我心想怎么是面试之前准备呢?我是一直在准备,从工作到现在都在总结自己的知识点,形成自己的知识体系,为了迎合他,也只能说是。
我:嗯嗯,是的,准备了很久,算是比较充分。
面试官:嗯,最后的两种算法,你还深入了解吗?
我:最后两种确实没有深入了解,之前有看网上的资料说美团Leaf算法需要依赖于数据库,ZK,并且也能保证去全局ID的唯一性,单项递增。
我:而百度UidGenerator算法是基于雪花算法进行实现的,也是需要借助于数据库,与雪花算法不同的是,「UidGenerator支持自定义时间戳、主句中心ID和机器ID、序列号的位数」。
面试官:嗯嗯,好的,小伙子今天的面试就到这里,下次我们再见吧。