Java架构直通车——锁分段技术:微信如何扛住 10 亿用户同时修改微信号?
文章目录
- 引入
- 从HashMap到ConcurrentHashMap的转变:理解锁分段技术
- HashMap的死循环
- ConcurrentHashMap的实现方式---锁桶(或段)
- ConcurrentHashMap的真实结构
- ConcurrentHashMap小结
- 分段锁优化超卖问题
- 分布式锁并发优化方案的不足
引入
今天在知乎突然看到了这么一个问题:
微信如何扛住 10 亿用户同时修改微信号?
微信号逻辑上应该是每一个微信账号的 unique key,在以往的场景下写入负载不是很高所以问题不大,但是现在允许修改微信号之后应该怎么处理这么大的并发写入并且保证不冲突?
这是个很有趣的问题,题目里的场景虽然在现实中不会出现,但是给了我们一个很好的启示。
首先来看,题目主要就是说,在高并发下,有没有可能有两个用户同时修改成了相同的用户名?这个情况,如果不采用锁的方式,在多线程下一定是会发生的。修改一个用户名的过程是这样的:
- 查找数据库里是否有一个用户名B,如果有不让修改,如果没有就可以修改。
- 将用户的用户名由A修改成B。
我们知道,这是一个很经典的幻读场景,事务在插入或者更新已经检查过不存在的记录时,惊奇的发现这些数据已经存在了。数据库解决幻读的方式很粗暴:Seriliazable_read,也就是采用串行的方式。
很显然,在高并发下使用串行来解决幻读是不可行的,那么是否还有其他的方法呢?
一个方式就是限流:
只存账号id和新微信号的key-value,全扔redis里慢慢存数据库,对外美名曰审核若干工作日。
另一个很自然的方式就是使用锁。当然在高并发下使用表锁是不可行的。
只能是修改锁的粒度。一个我想到最简单的解决方案是增加一个Redis,用来修改:
- 查找数据库里是否有一个用户名B,如果有不让修改,如果没有就可以修改。
- 将可以修改的用户名B存入Redis中,如果Redis已经有了这个用户名了,那么就不可以修改了。如果Redis没有这个用户名B,以一个Expire_time存入Redis中。
- 将用户的用户名由A修改成B。
这样做相当于一个行锁了,也就是用Redis的原子性做一个保障。
当然上面只是我的设想,实际效用如何我也不知道。
修改锁的粒度还有一种解决方案,那就是锁分段技术。 比如,比如张三想修改A0为B1,李四想修改C2为D3。批量提交的数据,A0改为B1的请求提交到 pair
要理解这个锁分段技术,可以从HashMap到ConcurrentHashMap的转变说起。
从HashMap到ConcurrentHashMap的转变:理解锁分段技术
从HashMap到ConcurrentHashMap,其实是因为在并发情况下HashMap 出现了死循环,才导致必须得用带锁的ConcurrentHashMap(HashTable锁住整个数组效率太低)。
那么并发条件下,HashMap是怎么出现死循环的呢?
HashMap的死循环
HashMap是非线程安全的,在并发场景中如果不保持足够的同步,就有可能在执行HashMap.get时进入死循环,将CPU的消耗到100%。这个过程中,其实是HashMap的单链表产生了一个闭环,从而变成了循环链表。
具体一点说,是因为 在多线程并发的情况下,在put操作的时候,如果size > initialCapacity * loadFactor,hash表进行扩容,那么这时候HashMap就会进行rehash操作,随之HashMap的结构就会很大的变化。很有可能就是在两个线程在这个时候同时触发了rehash操作,产生了闭合的回路。然后通过get操作的时候,触发了死循环。
下面是详细的底层代码原理的分析:
Java的HashMap的扩容源代码。
void resize(int newCapacity)
{
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
//创建一个新的Hash Table
Entry[] newTable = new Entry[newCapacity];
//将Old Hash Table上的数据迁移到New Hash Table上
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
上面的代码没有什么好说的,就是创建了一个新的Entry数组,然后调用了transfer函数,重新计算Hash,将旧的数据迁移到新的数组上,所以关键还是要看transfer()。
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
在正常情况下,这个函数应该是这样运作的:
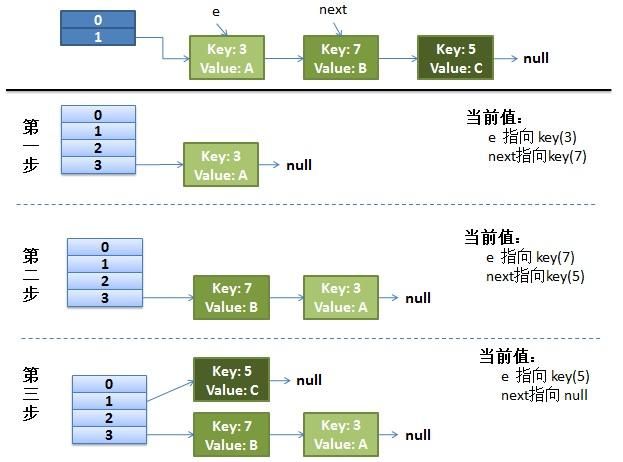
注意上图里的当前值。
而在并发下的Rehash可能产生下面的情况:
假设我们有两个线程,我们再回头看一下我们的 transfer代码中的这个细节:
do {
Entry<K,V> next = e.next; // <--假设线程一执行到这里就被调度挂起了
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
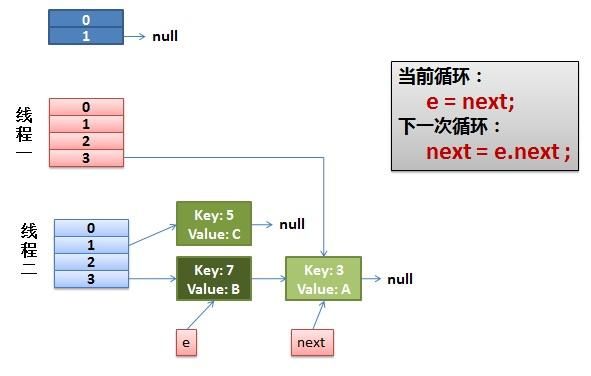
而我们的线程二执行完成了。于是我们有下面的这个样子。

注意,因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表,而不是原来指向的位置(比如上图,之前指向的是哈希桶1的e和next,现在指向了哈希桶3的e和next)。
线程二执行完毕后,线程一被调度回来执行。
- 先是执行 newTalbe[i] = e;
- 然后是e = next,导致了e指向了key(7),
- 而下一次循环的next = e.next导致了next指向了key(3)
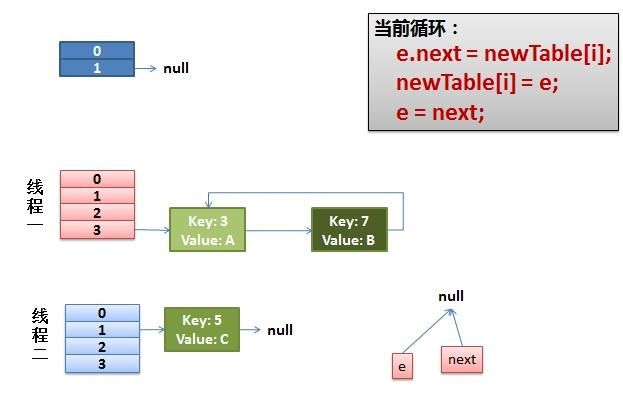
- 线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。

- 环形链接出现。
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
ConcurrentHashMap的实现方式—锁桶(或段)
ConcurrentHashMap的读取并发,因为在读取的大多数时候都没有用到锁定,所以读取操作几乎是完全的并发操作,而写操作锁定的粒度又非常细。只有在求size等操作时才需要锁定整个表。
而在迭代时,ConcurrentHashMap使用了不同于传统集合的快速失败迭代器的弱一致迭代器。在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出ConcurrentModificationException,取而代之的是在改变时new新的数据从而不影响原有的数据,iterator完成后再将头指针替换为新的数据,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变,更重要的,这保证了多个线程并发执行的连续性和扩展性,是性能提升的关键。
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法时,其他线程访问HashTable的同步方法时,可能会进入阻塞或轮询状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因,是因为所有访问HashTable的线程都必须竞争同一把锁,那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率。
这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。

从上面看出,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部,因此,这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长,但是带来的好处是写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment。
ConcurrentHashMap的真实结构
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。
ConcurrentHashMap的主干是个Segment数组。Segment继承了ReentrantLock,所以它就是一种可重入锁(ReentrantLock)。在ConcurrentHashMap,一个Segment就是一个子哈希表,Segment里维护了一个HashEntry数组,并发环境下,对于不同Segment的数据进行操作是不用考虑锁竞争的。
CurrentHashMap的初始化一共有三个参数,一个initialCapacity,表示初始的容量,一个loadFactor,表示负载参数,最后一个是concurrentLevel,代表ConcurrentHashMap内部的Segment的数量,ConcurrentLevel一经指定,不可改变,后续如果ConcurrentHashMap的元素数量增加导致ConrruentHashMap需要扩容,ConcurrentHashMap不会增加Segment的数量,而只会增加Segment中链表数组的容量大小,这样的好处是扩容过程不需要对整个ConcurrentHashMap做rehash,而只需要对Segment里面的元素做一次rehash就可以了。
Segment数组:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
/**
* 在本 segment 范围内,包含的 HashEntry 元素的个数
* 该变量被声明为 volatile 型,保证每次读取到最新的数据
*/
transient volatile int count;
/**
*table 被更新的次数
*/
transient int modCount;
/**
* 当 table 中包含的 HashEntry 元素的个数超过本变量值时,触发 table 的再散列
*/
transient int threshold;
/**
* table 是由 HashEntry 对象组成的数组
* 如果散列时发生碰撞,碰撞的 HashEntry 对象就以链表的形式链接成一个链表
* table 数组的数组成员代表散列映射表的一个桶
* 每个 table 守护整个 ConcurrentHashMap 包含桶总数的一部分
* 如果并发级别为 16,table 则守护 ConcurrentHashMap 包含的桶总数的 1/16
*/
transient volatile HashEntry<K,V>[] table;
/**
* 装载因子
*/
final float loadFactor;
}
HashEntry:
static final class HashEntry<K,V> {
final K key; // 声明 key 为 final 型
final int hash; // 声明 hash 值为 final 型
volatile V value; // 声明 value 为 volatile 型
final HashEntry<K,V> next; // 声明 next 为 final 型
HashEntry(K key, int hash, HashEntry<K,V> next, V value) {
this.key = key;
this.hash = hash;
this.next = next;
this.value = value;
}
}
可以看到除了value不是final的,其它值都是final的。
这意味着不能从hash链的中间或尾部添加或删除节点,因为这需要修改next引用值,所有的节点的修改只能从头部创建一个新的HashEntry开始(next指向之前的头部)。
- 对于put操作,可以一律添加到Hash链的头部。
- 但是对于remove操作,可能需要从中间删除一个节点,这就需要将要删除节点的前面所有节点整个复制一遍,最后一个节点指向要删除结点的下一个结点,为了确保读操作能够看到最新的值,将value设置成volatile,这避免了加锁。
ConcurrentHashMap小结
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
- 底层数据结构: JDK1.7 的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟 HashMap1.8 的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
- 实现线程安全的方式(重要): ① 在 JDK1.7 的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 到了 JDK1.8 的时候已经摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6 以后 对 synchronized 锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② Hashtable(同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
分段锁优化超卖问题
之前在Java架构直通车——订单扣库存问题一文中使用了分布式锁。
@Transactional(propagation=Propagation.REQUIRED)
@Override
public void decreaseItemSpecStock(String specId,Integer buysCounts){
lockUtil().getLock(); //--分布式加锁
//1.查询库存
int stock=10;//假设查询数据库后,其值为10.
//2.判断库存,是否能够扣除
if(stock<buysCounts){
//提示用户库存不够
}
//3.扣库存
...
lockUtil().unLock();//--分布式解锁
}
分布式锁一旦加了之后,对同一个商品的下单请求,会导致所有客户端都必须对同一个商品的库存锁key进行加锁。这样会导致对同一个商品的下单请求,就必须串行化,一个接一个的处理。
假设加锁之后,释放锁之前,查库存 -> 创建订单 -> 扣减库存,这个过程性能很高吧,算他全过程20毫秒,这应该不错了。那么1秒是1000毫秒,只能容纳50个对这个商品的请求依次串行完成处理。
这种方案,要是应对那种低并发、无秒杀场景的普通小电商系统,可能还可以接受。但是对于高并发,显得不足了。
对分布式锁进行高并发优化,就可以使用分段锁的思路。
假如你现在iphone有1000个库存,那么你完全可以给拆成20个库存段,要是你愿意,可以在数据库的表里建20个库存字段,每个库存段是50件库存,比如stock_01对应50件库存,stock_02对应50件库存。类似这样的,也可以在redis之类的地方放20个库存key。
接着,1000个/s 请求,用一个简单的随机算法,每个请求都是随机在20个分段库存里,选择一个进行加锁。
一旦对某个数据做了分段处理之后,有一个坑一定要注意:就是如果某个下单请求,咔嚓加锁,然后发现这个分段库存里的库存不足了,此时咋办?
这时你得自动释放锁,然后立马换下一个分段库存,再次尝试加锁后尝试处理。 这个过程一定要实现。
分布式锁并发优化方案的不足
最大的不足,很不方便,实现太复杂。
首先,你得对一个数据分段存储,一个库存字段本来好好的,现在要分为20个分段库存字段;
其次,你在每次处理库存的时候,还得自己写随机算法,随机挑选一个分段来处理;
最后,如果某个分段中的数据不足了,你还得自动切换到下一个分段数据去处理。
这个过程都是要手动写代码实现的,还是有点工作量,挺麻烦的。
不过我们确实在一些业务场景里,因为用到了分布式锁,然后又必须要进行锁并发的优化,又进一步用到了分段加锁的技术方案,效果当然是很好的了,一下子并发性能可以增长几十倍。
以我们本文所说的库存超卖场景为例,你要是这么玩,会把自己搞的很痛苦!
再次强调,我们这里的库存超卖场景,仅仅只是作为演示场景而已,以后有机会,再单独聊聊高并发秒杀系统架构下的库存超卖的其他解决方案。