HashMap中的hash函数
1. 什么是 hash 函数
hash 函数,即散列函数,或叫哈希函数。它可以将不定长的输入,通过散列算法转换成一个定长的输出,这个输出就是散列值。需要注意的是,不同的输入通过散列函数,也可能会得到同一个散列值。因此我们不能使用散列函数来获取唯一值。
2. HashMap 为什么要使用 hash 函数
Java 的 HashMap 中使用的是数组 + 链表的结构,但在保存时,一个 K - V 键值对应该被存放到数组的哪个位置?
通常我们都会想到:按照存入顺序存放。但是,按照这种策略,在取值时势必需要遍历整个数组,然后一个个去比较它们的 key 是否相等,这对于性能的损耗无疑是很大的。也许你已经猜到了,解决这个问题的办法就是散列函数。
3. 常见的 hash 算法及冲突的解决
在具体介绍 HashMap 如何使用散列函数之前,先简单介绍一下常见的 hash 算法,以便于你可以更加系统地了解它。
a. 直接定址法:直接以关键字k或者k加上某个常数(k+c)作为哈希地址(H(k)=ak+b)。
b. 数字分析法:提取关键字中取值比较均匀的数字作为哈希地址(如一组出生日期,相较于年-月,月-日的差别要大得多,可以降低冲突概率)
c. 分段叠加法:按照哈希表地址位数将关键字分成位数相等的几部分,其中最后一部分可以比较短。然后将这几部分相加,舍弃最高进位后的结果就是该关键字的哈希地址。
d. 平方取中法:如果关键字各个部分分布都不均匀的话,可以先求出它的平方值,然后按照需求取中间的几位作为哈希地址。
e. 伪随机数法:选择一随机函数,取关键字的随机值作为散列地址,通常用于关键字长度不同的场合。
f. 除留余数法:用关键字k除以某个不大于哈希表长度m的数p,将所得余数作为哈希表地址(H(k)=k%p, p<=m; p一般取m或素数)。
上文已经说到,不同的输入通过散列函数,有可能会得到相同的输出。既然通过不同的输入可以得到相同的输出,那么如果发生冲突了怎么办?比如在 HashMap 中,如果两个不同的 key 计算得出的散列值相同,后来的岂不是会覆盖先来的?不用担心,解决 hash 冲突的方法也是有的,常见的有:
a. 链地址法:将哈希表的每个单元作为链表的头结点,所有哈希地址为 i 的元素构成一个同义词链表。即发生冲突时就把该关键字链在以该单元为头结点的链表的尾部。
b. 开放定址法:即发生冲突时,去寻找下一个空的哈希地址。只要哈希表足够大,总能找到空的哈希地址。
c. 再哈希法:即发生冲突时,由其他的函数再计算一次哈希值。
d. 建立公共溢出区:将哈希表分为基本表和溢出表,发生冲突时,将冲突的元素放入溢出表。
可能你已经注意到,HashMap 就是使用链地址法来解决冲突的(jdk8中采用平衡树来替代链表存储冲突的元素,但hash() 方法原理相同)。数组中的每一个单元都会指向一个链表,如果发生冲突,就将 put 进来的 K- V 插入到链表的尾部。
4. HashMap 是如何使用 hash 函数的
该部分引用了博客园:淡腾的枫的文章(https://www.cnblogs.com/zhengwang/p/8136164.html)
首先,我们来看一下在 HashMap 中,最常用的 put() 和 get() 是怎么使用 hash() 的。以下源码均为 jdk8。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}在看到这段代码时疑问产生了,为什么hash函数这么设计?查过资料之后解释如下:这段代码叫“扰动函数”。
这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来访问数组下标。源码中模运算是在这个indexFor( )函数里完成的。indexFor的代码也很简单,就是把散列值和数组长度做一个"与"操作,
static int indexFor(int h, int length) {
return h & (length-1);
}顺便说一下,这也正好解释了为什么HashMap的数组长度要取2的整数幂。因为这样(数组长度-1)正好相当于一个“低位掩码”。“与”操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。以初始长度16为例,16-1=15。2进制表示是00000000 00000000 00001111。和某散列值做“与”操作如下,结果就是截取了最低的四位值。
10100101 11000100 00100101
& 00000000 00000000 00001111
----------------------------------
00000000 00000000 00000101 //高位全部归零,只保留末四位但这时候问题就来了,这样就算我的散列值分布再松散,要是只取最后几位的话,碰撞也会很严重。更要命的是如果散列本身做得不好,分布上成等差数列的漏洞,恰好使最后几个低位呈现规律性重复,就无比蛋疼。
这时候“扰动函数”的价值就体现出来了,说到这里大家应该猜出来了。看下面这个图,
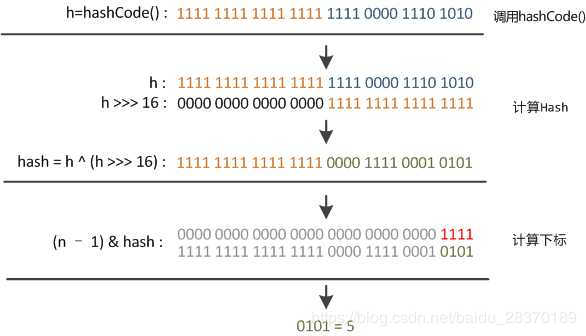
右位移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。
5. 总结
a. hash 函数并不能保证得到唯一的输出值,不同的输入也有可能得到相同的输出。
b. HashMap 中的 hash() 方法,将 hashCode 的高位和低位混合起来,降低冲突概率。
c. HashMap 中解决冲突的办法是采用链地址法(jdk7)。
d. HashMap 的初始长度为 16,且每次扩容都必须以 2 的倍数(2^n)扩充。因为在 HashMap 中,采用按位与运算(&)代替取模运算(&),当 b = 2^n 时,a % b = a & (b - 1) 。