JAVA进阶的基础知识快速通过---自学笔记(二)
温故而知新---陆续学习陆续更新中,你有更好的记忆和学习方法,请在评论区提出来大家一起交流,认真看完,一行行代码备注看完看懂,保证学会,学不会找我。
前言:
代码学完发现很简单,很多初学者搞不明白什么这个那个,其实是没有把概念记住,没有那么多为什么,为什么就这样做,就像小时候学数学,有很多的公式,刚开始学,我们只要死记公式,然后多练习,练习多了就不需要公式了,有时口算都能出来,到现在也不需要去理解公式为何是这样,不需要去深究它。后面你精通后在去专研它也可以。
比如在我的笔记里,里面有很多固定写法,你只需要记住就行,比如有class开头你就知道后面肯定是类对象,有new就是新建一个对象,List这样的你就知道是集合、有<>是泛型的概念等等,多多照着做,一百个人写一个相同的代码都可能有100个为什么这样写可以,这样写不可以,我能不能这样写的念头。
师傅领进门,修行看个人,同一套剑法,同一个师傅,100个学生的等级功力都不一样,更可况后面选择的职业和方向都不一样的,要想厉害就要多磨剑,多练,不然久不练剑法招式会忘光,代码页一样,你天天敲,敲个一年半载,其实来回敲的都是那些代码,换汤不换药,都一个套路,程序员你一个星期不写代码,你都不熟练甚至都不知道了,更可况你一个新入门的新手。
Java基本入门基础已经写完,现在要讲些进阶教程(标红的都是需要掌握的知识),这里让你快速复习这些进阶知识的概念,快速回忆:
- 线程/并发(加锁、死锁)
- 枚举
- IO流(文件操作)
- 集合(容器)
- 泛型
- 反射
- 网络通信
- 注解
- JVM虚拟机(类加载)
- 动态与函数式编程
- 异步/同步
线程
我们原来做的都是属于单线程,就是一步步的执行,那多个线程是什么,就是说你在执行这个的时候,另个线程也在同步执行,就看谁先抢占资源。
单线程:逐行(一行行)去执行,如:先写一个类,在写一个方法,然后写内容。
程序:就是执行的代码;
进程:执行中的程序;
线程:轻量级的进程;(线程本身不能单独运行,必须放在一个进程中才能执行)
线程模型:一般是五种状态,要记住;
1.新建状态:线程被创建后处于新建状态;
2.就绪状态:(1)新建状态的线程调用start()进入就绪状态;(2)阻塞状态的线程解除之后进入就绪状态;
3.运行状态:处于就绪状态的线程获得CPU资源,该线程就进入了运行状态;
4.阻塞状态:是一个正运行的线程,因为一些原因让出CPU资源暂时中止而进入的状态;
5.终止状态:(1)正常终止;(2)强制终止,stop、destroy;(3)异常中止:当线程中产生了异常,线程终止;

一、创建线程Thread:
这个也比较简单,跟我们继承类一样,需要继承,但是继承在java只能继承一个,使用extends来继承Thread线程;
固定写法:
很明显,跟我们继承差不多,就是继承了多线程Thread类(也就是说别人写好了多线程这个类给你用)
class 类名 extends Thread{//Thread具有线程功能
@Override //重写run方法
public void run(){
//相关代码
}
}例子:

如何让它具备线程功能:
步骤1.A a = new A();//要先new一个对象出来,继承的new方法:MyThread thread = new MyThread();
步骤2.A.start();//调用,对象.start();
怎么调用?写个测试类:
public static void main (Strung[] eras){
MyThread thread = new MyThread();//步骤1:new一个thread的对象
thread.run();//我们一般调用继承就是这么调用的,但是这样子会失去多线程的功能;要等这个执行完,才执行后面的语句;
thread.start();//步骤2:调用方法,这才是正确调用多线程的方式,对象.start();可以先执行后面的语句,在执行这句话(谁抢占到资源就执行谁,这就是多线程的)
system.out。ptint(“后面的语句,用来测试最后才输出还是同步输出”);
}二、创建Runnable接口
实现起来也比较简单,接口可以实现多个,使用implements关键字来继承Runnable线程和其他;
固定写法:
Class A implements Runnable{
@Override //重写run方法
public void run(){
//相关代码
}
}如何给它线程的功能,怎么调用:
步骤1.A a = new A();//要先new一个对象出来,接口new对象的方法:MyThread mt = new MyThread();
步骤2.Thread t = new Thread(A);//这个才是让它具备主线程的方法
或者 Thread t1 = new Thread(A,“线程1”);//重载方法,给这个线程取个名字(这样在执行好判断是哪个线程在执行),
步骤3.A.start();//调用,对象.start();
例子:

如何具备线程功能,如何调用,
//主线程,main函数、测试。
public static void main (Strung[] eras){
MyThread mt = new MyThread();//步骤1.new一个对象,接口new对象的方式,实现MyThread这个类,没有实现线程功能
Thread t = new Thread(mt);//步骤2.创建线程功能,Thread才具备线程功能,跟继承写法差不多
t.start();//步骤3.调用线程的方法
//主线程在执行其他代码
for(){
try{
Thread.sleep(100);//休眠
}catch(InterruptedException e){
eprintStackTrace();
}
}
System.out。println(“主线程”+i);
}
三、Thread和Runnable的比较:
从表面看一个是属于继承Thread(extends Tread 这个在java中只能单继承),一个属于接口Runnable(implements Runnable这个能够实现多个接口,灵活,但是需要依赖第一种的写法),这就是继承和接口的概念;
这两个用哪个都可以;
多线程的应用(实战):
举例来讲解:
随便写两个线程,执行下,看他们能否并发执行;
先新建一个线程1:MyRunnable1,输出+号

再新建一个线程1:MyRunnable2,输出*号
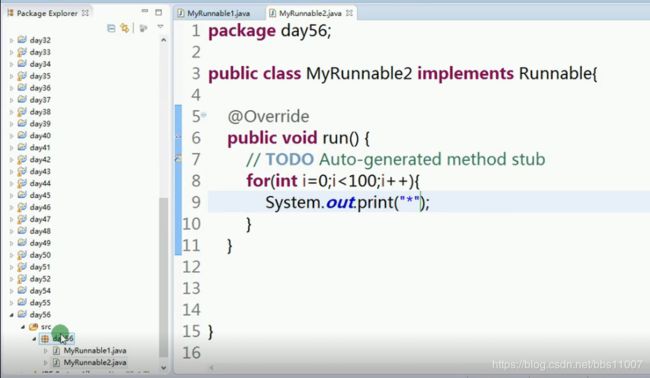
写个main主函数测试方法测试一下:

输出的结果 是+和*杂乱无章,不按顺序输出,每次点输出结果都不一样,都是由计算机判断谁抢到资源谁就先输出;
根据线程的五种状态运行,很符合;
总结:java对于线程启动后唯一能保证的是每个线程都被启动并结束,但对于哪个先执行,什么时候执行,是没有保证的。
线程的优先级(查询or改变线程优先级)
既然输出的规则杂乱无章,没有规律可循,那么优先级是否能影响它们的输出呢?
在java中的优先级是从1-10,默认5,最高时10,最低是1;
查询优先级:对象.getprioity();
上面的例子,我们先查询它们的优先级(main函数里面写):

输出,查询出来的默认优先级都是5
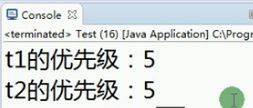
我们来改变优先级(main函数里面写):

最后根据上面的例子,执行的+和*号,输出结果我们发现t1的高优先级输出的概率高,也就是t1先输出,可不是每次都这样,多运行几次,有时就先出t2优先级低的。
总结:java中优先级高的线程有更大的可能获得CPU(优先执行的概率大而已),但并不是优先级高的总是执行,也不是优先级低的不执行;
调度线程的三个方法(常用):
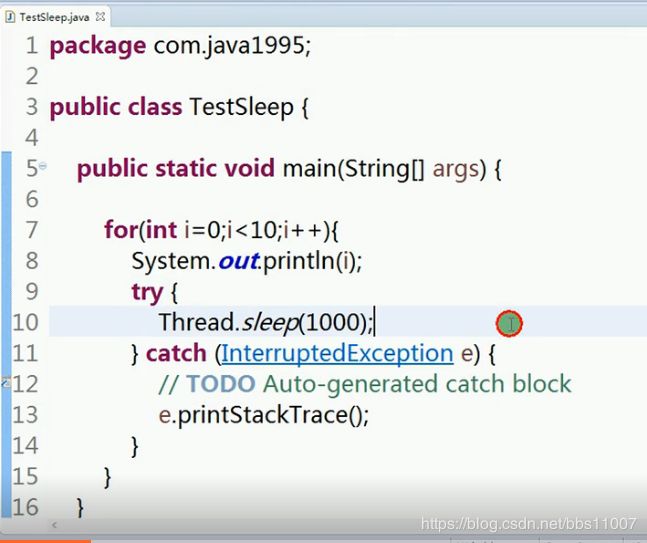
一、休眠方法sleep();
通过这个方法让线程睡一会,睡醒之后,在进入就绪状态,等等调度,休眠多久,转入毫秒,纳秒,如:sleep(毫秒数);
案例:顺序输出0~9,我们每输出一个数字就休眠1秒,即sleep(1000);每打印一个数就休息一秒
二、暂停方法yield();
这个暂停方法是用于释放资源的;
案例:有两个线程a和b,假如a先获得资源,a先执行,a执行完后,就释放资源a.yield,这是a就释放资源给大家抢(注意:这里有个坑:a其实也假如抢资源,它自己释放,它自己也可以抢,有可能也被a再次抢到资源,记住这个知识点),也就是说,当a释放资源后,a、b两个加入随机抢资源的
案例:创建两个资源线程试试
先写第一个资源线程试试(用接口和继承都可以),线程1 MyRunnable1,(a线程),输出200个+号,然后释放资源Thread.yield();

在写第二个线程2 MyRunnable2(与线程1差不多,名字不一样而已,b线程),输出200个*号,

最后写个main主函数,测试类试试:

输出结果:输出线程1和线程2的+和*号是随机出现的,因为线程1和线程2的资源释放后也再次参与抢,一起竞争;
有些资料这么理解,是错误的理解,误人子弟,他们认为输出结果是++++++******,这样交替输出的,这是因为他们理解释放完后其他线程去抢,所以是交替的。---大家要注意这个坑
这个方法会经常被误用,所以用的时候要小心;
三、挂起方法join();
这个方法是用于插队的,让线程插队先执行;
案例:
也是写两个线程输出+和*号,这里略,可以参考上面的,不重要,理解就行;
直接写main主函数测试:
这里解释下,我们在第五行的时候i==5输出+号(就是第五行的时候强行插入*号),即mt.join();的用法;

线程同步
问题的由来(为何需要同步方法):
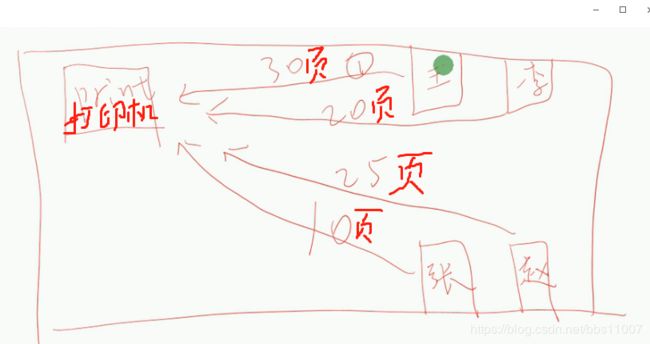
说到同步,我们先来说个例子,在办公室只有一台打印机、有几个人需要打印(如图),这种情况我们知道是多线程状态,无论哪个人先抢到资源,我们知道线程中,执行的线程都是随机的,会出现各种意想不到的情况,无法决定线程的输出顺序。比如:老王先抢到资源,但是他没有打印完30页,资源又被老李抢去了,就打印老李的,然后又随机,可想而知,打印机打印出来的内容都是穿插每个人的内容,还要挑出来多麻烦。
我们能不能这样,谁先抢到资源,然后先执行完他的,在执行第二个抢到资源的那位,比如:老王先抢到资源,打印机把老王的30页先打印出来先,然后再释放给下一位,如老李抢到第二个资源,就接着打印20页完....这样的场景才是真实的场景。
代码例子:
1.先新建一个打印机类,具备打印机功能print类
Thread.sleep();加这个是为了被打印那么快,为了看看效果而已。

2.在写人,如老王、老李的类具有线程功能,因为模拟抢占打印机(报错是里面没有好有重写run方法,写进去就可以 ,然后快捷键出属性的构造方法)

最后写个main方法测试下:
这就是几个人同时用打印机,打印出来时这样的结果,不符合实际运用,我们下节课讲到锁;

这就是我们今天讲的同步资源,我们可以采取加锁(Synchronized)的概念,老王先抢到资源,那我就先给老王加锁,等老王打印完后再释放,以此类推!
解决方法:加锁(Synchronized)---就是同步方法
为什么需要同步,如:小明、小红打印出来的都是随机的,应该是一个人打印完,在打另一个人的。
固定写法(两种方法):
1. 同步方法:在方法中加锁,当线程同步的时候,会获得同步方法所属对象的锁,一旦获得对象的锁,则其他线程不能再执行被锁对象的其他同步方法。只有在同步方法执行完毕后释放了锁,其他线程才能执行。
例如:老王先抢到资源,给老王加了锁,其他人就不能抢资源了,等老王打印后,释放锁释放资源,第二个老李抢到,又给老李加锁,老李才执行第二个人得打印工作,以此类推!
Synchronized 方法声明{
}2.同步块方法:同步块是在run方法中加锁。
//同步块是在run方法中加锁
Synchronized(资源对象){//相当于单线程了,资源对象时哪个需要资源,如老王还是老李
//需要进行同步的方法
}例:还是上面的案例:在run()方法中加锁
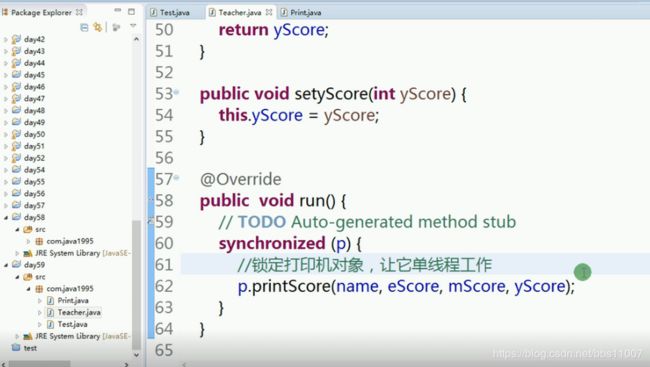
结果:输出的结果很明显,先打印完一个人得,在执行另一个人得

同步方法加锁和同步块加锁,同步方法是在类对象中加锁,这个加锁代表类对象里的都已经都加了锁,同步块加锁是锁住资源对象。
写两个类对象method1()和method2()加锁试试,这里就不试了,理解就行。

死锁
有了锁的概念,我们会出现什么问题呢?比如:a和b线程,a持有锁A,在等待锁B,而b持有锁B,在等待锁A,这样a和b陷入了等待,谁都不获得资源就不释放,两者就这么僵持下去,最后谁都不执行。这就是死锁的概念。
也就是,你不给我资源A,我就不给你资源B,两个对持。最好是一手交钱一手交货才好。
代码例子就省略了,理解这个意思就行,当你给资源加锁,发现不执行,那么就是进入了死锁里了。
看下面的输出,线程123都相互在等待资源,而这些资源也都没有被释放,就这么等下去了,右上角红色图标说明程序还在执行当中,没有结束,这样就是进了死锁里面了。

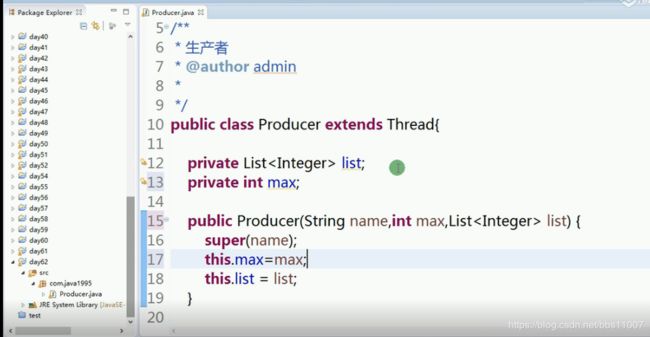
生产者/消费者设计模式
生产者生成东西放仓库,消费者从仓库中取,生产仓库满了,生产者就不生产了,消费者取仓库空了,就不取了。生产者每生产东西就通知消费者,消费取东西也会通知生产者

写程序看看:
生产者
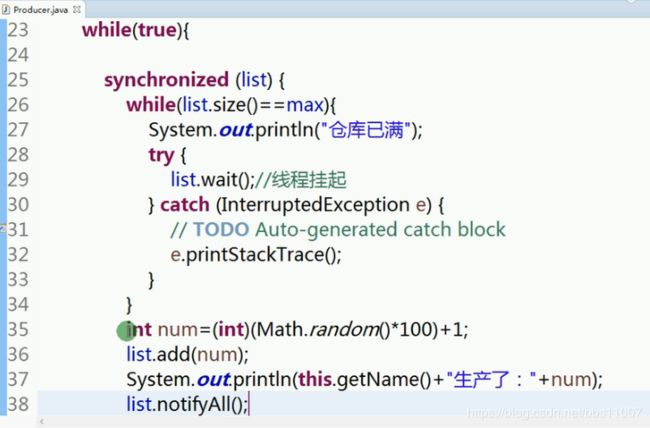
重写生产者run方法,这里子啊线程中给加锁,记住,不能用if,只能用while。
list.notifyAll();唤醒,告诉别人我生产完了,你来消费了。
看下论坛

消费者
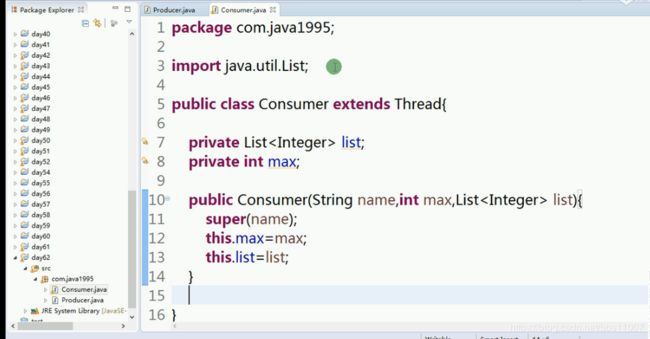
重写消费者run()方法,类似消费者
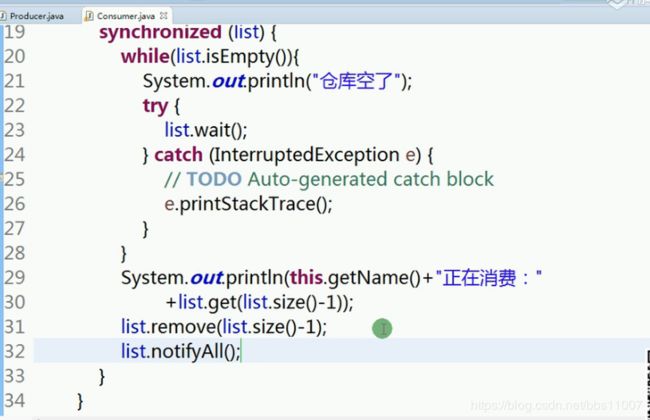
最后测试下,模拟下消费者和生产者的工作流程:

总结:这个模型说明了生产者和消费者两个线程进行并发,还可以进行相互通信,相互告知。
枚举(enum)
是一个小知识点,没有它我们也能写,有它只是更方便,不是重点,这是jdk5出来才有枚举这个概念;
概念:一个类中的对象,认为个数是固定的,可以将每一个对象一一列举出来。
enum是->继承于Enum->再继承Object父类(enum和Enum不一样哦,注意大小写),所以枚举enum也具有Enum和Object的属性和方法;
固定格式:
修饰符 enum 方法名{//注意:方法名后面没有()
//一一列举出类的对象名即可
对象名1,对象名2,......;
}
例子,写一个星期有七天,普通方法怎么写:
//一般我们怎么描述一个星期有7天的对象,因为已知7天,所以可以一个个列出来;
public void Day(){//描述星期类,7天
//类似单例模式
//构造方法Day()
private Day(){//初始化
//所有对象都有属性
//zhou1是周一,要public,但又不允许更改所以需要final,这样我们需要7个对象,我们一般就这么写
public static final Day zhou1 = new Day();//周一
public static final Day zhou2 = new Day();//周二
public static final Day zhou3 = new Day();//周三
public static final Day zhou4 = new Day();//周四
public static final Day zhou5 = new Day();//周五
public static final Day zhou6 = new Day();//周六
public static final Day zhou7 = new Day();//周日
}
}但是我们学习枚举后,我们就可以怎么写呢?
//上面的代码可以用枚举来写,是不是简洁多了
public enum Day{//Day后面是不加括号的
//描述7个当前类的对象,把7个当前类的对象
zhou1,zhou2,zhou3,zhou4,zhou5,zhou6,zhou7;
//系统自动帮你new对象,如zhou1可以加上:public static final Day zhou1 = new Day();
}枚举不影响原来方法的使用,原来该怎么调用就调用,这只是简化而已;
枚举还能干什么事情,前面说了,继承了父类Object,所以具有Object的特点,还有Enum等,这些我就不说了,你调用打“.”出来就看到了。
感兴趣要深入学习:http://c.biancheng.net/view/1100.html
文件/IO流
详情请看我另篇专项讲解:https://blog.csdn.net/bbs11007/article/details/99678127
IP操作类的核心五个类:
文件操作类:File
流操作类 :IntputStream、OutputStream、Reader、Writer
一个接口 : Serializable
File文件
File类是唯一一个与文件本身操作有关的类,即通过File可以实现文件的创建、删除、列表等操作;
(一般只对文件操作,不能对文件内容操作)

例子:操作File
File考虑路径的时候要注意,"\"要“\\”,如:e:\\这里要双斜杠

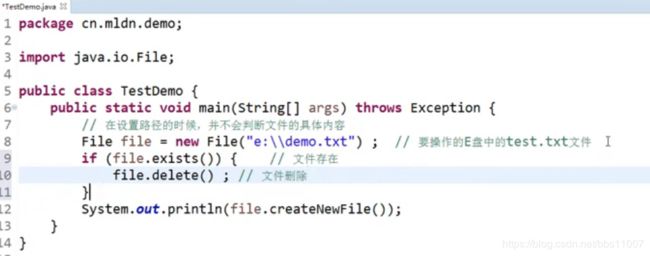

如:
![]() 这个要是放到linux下执行回报错,这是windows的分隔符
这个要是放到linux下执行回报错,这是windows的分隔符
使用windows和linux下的操作通用写法加上:File.separator代表斜杠
![]()
问题二

必须存在目录后才可以创建文件;

exists()这个方法是确认文件是否存在;
mkdir这个方法是适合只有一个父类时,如:e:\\test.txt,如果该目录下存在多级文件夹,那么就用mkdirs方法,如:e:\\hello\\nihao\\test.txt,代码如下:

日后如果要进行文件操作,必须要确保文件的存在;

直接看代码例子2:路径下有个图片约16.1M

结果如下:

对于文件大小这样子我们如法读懂,我们需要转换下格式
![]()
double放哪个位置都可以,可这样输出结果:![]() 这样还是读不懂,我们需要保留两位小数需要这样改写(先记住):
这样还是读不懂,我们需要保留两位小数需要这样改写(先记住):
![]()
输出的结果就是:![]()
我们再来看看加条该图片修写的日期:
![]()
输出的结果:![]() 这样也看不是很清楚,就需要改写下:
这样也看不是很清楚,就需要改写下:
![]()
输出结果就显然易见咯:![]()
扩展其他知识:

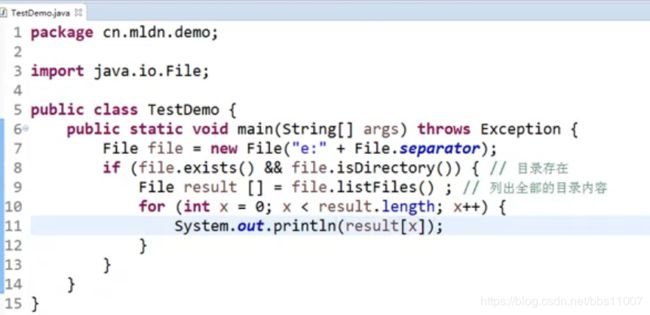

以上的操作方法适当了解即可,不用特意去记,查API,
需要记的方法操作有:判断父目录、判断文件夹、判断文件是否存在、删除;
列出e盘下的(app文件夹里的所有文件,一有文件夹就打开读取、这里采用递归方法)
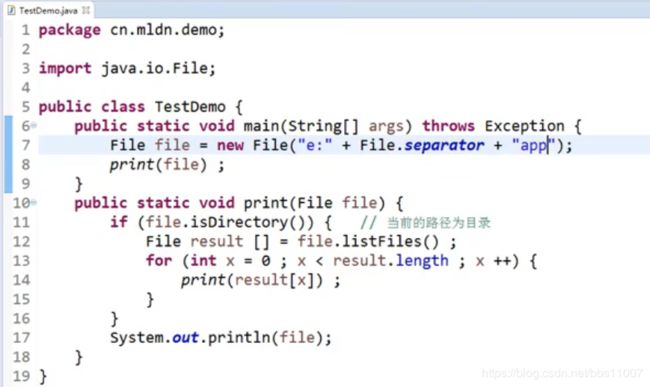
运行中会出现空指针,这是因为e盘下可以会有系统的隐藏文件夹、这些文件夹是加密不能打开,所有程序运行时会报错

这需要修改下,再次运行后就不会出错了:


需要记的方法操作有:判断父目录、判断文件夹、判断文件是否存在、删除;
IO流
为什么要使用IO流:在变量、数组、对象和集合中存储的数据是暂时存在的,一旦程序结束它们就会丢失。为了能够永久地保存程序创建的数据,需要将其保存到磁盘文件中,这样就可以在其他程序中使用它们。Java 的 I/O(输入/输出)技术可以将数据保存到文本文件和二进制文件中, 以达到永久保存数据的要求。
本章首先从基础的流概念、流的分类、系统流的使用开始介绍,进而介绍如何操作文件、读取文件和写入文件。掌握 Java 中 I/O 处理技术能够提高读者对数据的处理能力。
在 Java 中所有数据都是使用流读写的。流是一组有序的数据序列,将数据从一个地方带到另一个地方。根据数据流向的不同,可以分为输入(Input)流和输出(Output)流两种。
什么是输入/输出流
Java 程序通过流来完成输入/输出,所有的输入/输出以流的形式处理。因此要了解 I/O 系统,首先要理解输入/输出流的概念。
输入就是将数据从各种输入设备(包括文件、键盘等)中读取到内存中,输出则正好相反,是将数据写入到各种输出设备(比如文件、显示器、磁盘等)。例如键盘就是一个标准的输入设备,而显示器就是一个标准的输出设备,但是文件既可以作为输入设备,又可以作为输出设备。
数据流是 Java 进行 I/O 操作的对象,它按照不同的标准可以分为不同的类别。
- 按照流的方向主要分为输入流和输出流两大类。
- 数据流按照数据单位的不同分为字节流和字符流。
- 按照功能可以划分为节点流和处理流。
如果要进行文件内容操作必须依靠数据流,数据流分为两种流:
1.字节流:IntputStream(字节输入流)、OutputStream(字节输出流)

2.字符流:Reader(字符输入流)、Writer(字符输出流)
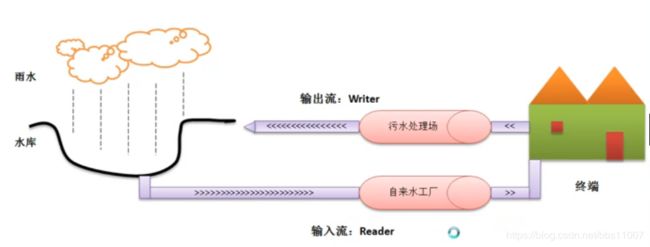
数据流的处理只能按照数据序列的顺序来进行,即前一个数据处理完之后才能处理后一个数据。数据流以输入流的形式被程序获取,再以输出流的形式将数据输出到其他设备。图 1 所示的是输入流模式,图 2 所示的是输出流模式。
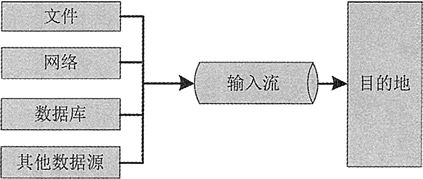
图1 输入流模式
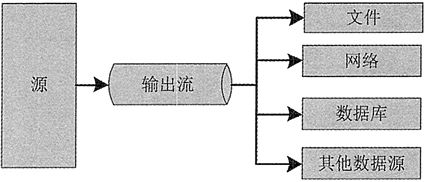
图2 输出流模式
输入流
Java 流功能相关的类都封装在 java.io 包中,而且每个数据流都是一个对象。所有输入流类都是 InputStream 抽象类(字节输入流)和 Reader 抽象类(字符输入流)的子类。其中 InputStream 类是字节输入流的抽象类,是所有字节输入流的父类,其层次结构如图 3 所示。
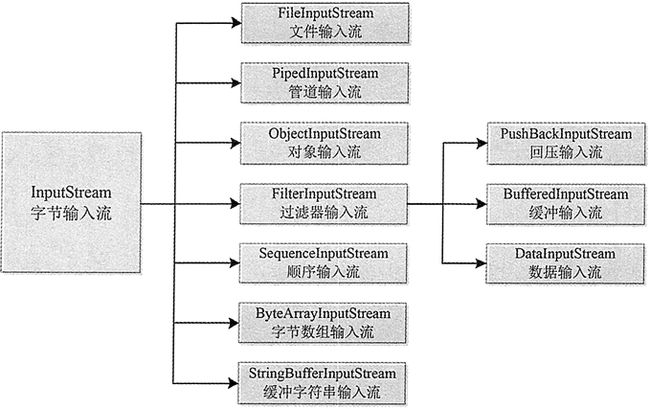
图3 InputStream类的层次结构图
InputStream 类中所有方法遇到错误时都会引发 IOException 异常。如下是该类中包含的常用方法。
- int read():从输入流读入一个 8 字节的数据,将它转换成一个 0~255 的整数,返回一个整数,如果遇到输入流的结尾返回 -1。
- int read(byte[] b):从输入流读取若干字节的数据保存到参数 b 指定的字芳数组中,返回的字芾数表示读取的字节数,如果遇到输入流的结尾返回 -1。
- int read(byte[] b,int off,int len):从输入流读取若干字节的数据保存到参数 b 指定的字节数组中,其中 off 是指在数组中开始保存数据位置的起始下标,len 是指读取字节的位数。返回的是实际读取的字节数,如果遇到输入流的结尾则返回 -1。
- void close():关闭数据流,当完成对数据流的操作之后需要关闭数据流。
- int available():返回可以从数据源读取的数据流的位数。
- skip(long n):从输入流跳过参数 n 指定的字节数目。
- boolean markSupported():判断输入流是否可以重复读取,如果可以就返回 true。
- void mark(int readLimit):如果输入流可以被重复读取,从流的当前位置开始设置标记,readLimit 指定可以设置标记的字苟数。
- void reset():使输入流重新定位到刚才被标记的位置,这样可以重新读取标记过的数据。
上述最后 3 个方法一般会结合在一起使用,首先使用 markSupported() 判断,如果可以重复读取,则使用 mark(int readLimit) 方法进行标记,标记完成之后可以使用 read() 方法读取标记范围内的字节数,最后使用 reset() 方法使输入流重新定位到标记的位置,继而完成重复读取操作。
Java 中的字符是 Unicode 编码,即双字节的,而 InputerStream 是用来处理单字节的,在处理字符文本时不是很方便。这时可以使用 Java 的文本输入流 Reader 类,该类是字符输入流的抽象类,即所有字输入流的实现都是它的子类。
Reader类的具体层次结构如图 4 所示,该类的方法与 InputerSteam 类的方法类似,这里不再介绍。
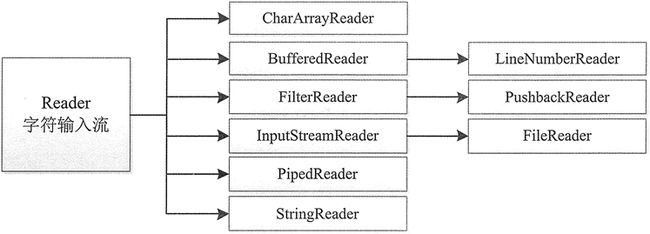
图4 Reader类的层次结构
输出流
在 Java 中所有输出流类都是 OutputStream 抽象类(字节输出流)和 Writer 抽象类(字符输出流)的子类。其中 OutputStream 类是字节输出流的抽象类,是所有字节输出流的父类,其层次结构如图 5 所示。
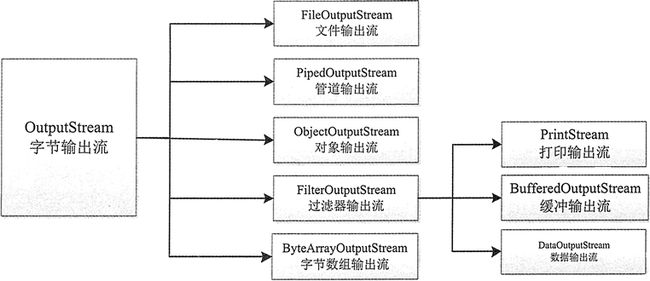
图5 OutputStream类的层次结构图
OutputStream 类是所有字节输出流的超类,用于以二进制的形式将数据写入目标设备,该类是抽象类,不能被实例化。OutputStream 类提供了一系列跟数据输出有关的方法,如下所示。
- int write (b):将指定字节的数据写入到输出流。
- int write (byte[] b):将指定字节数组的内容写入输出流。
- int write (byte[] b,int off,int len):将指定字节数组从 off 位置开始的 len 字芳的内容写入输出流。
- close():关闭数据流,当完成对数据流的操作之后需要关闭数据流。
- flush():刷新输出流,强行将缓冲区的内容写入输出流。
字符输出流的父类是 Writer,其层次结构如图 6 所示。
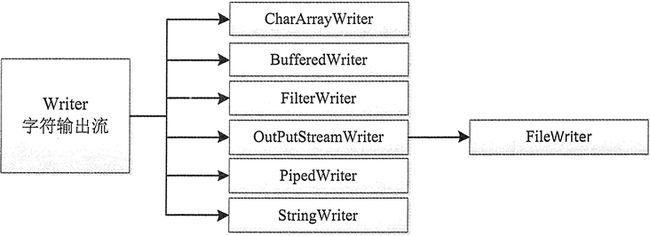
图6 OutputStream类的层次结构图
集合
详情讲解:https://blog.csdn.net/bbs11007/article/details/99687906
概念:集合是一种特殊的类,相当于容器,用来存放其他类,或者类的对象,主要用于完成数据库和数据结构,编写较大的的工程用起来会较简单;
集合在java中属于重点,但不是难点,学起来很简单,计算机有一门叫数据结构,对应的就是java的容器类(集合类);
集合有点类似数组,数组放的是值,集合放的是类或对象;
在 Java 中数组的长度是不可修改的。然而在实际应用的很多情况下,无法确定数据数量。这些数据不适合使用数组来保存,这时候就需要使用集合。
Java 的集合就像一个容器,用来存储 Java 类的对象。有些容器内部存放的东西在容器内部是不可操作的,像水瓶里的水,除了将其装入和倒出之外,就不能再进行别的操作了,但是很容易装入和倒出;而有些容器内部存放的东西在容器内部是可以操作的,例如,衣柜里面摆放的衣服,不仅可以将衣服存放到衣柜中,还可以将衣服有序地摆放,以便在使用时快速查找,但是却不容易取出。Java 的集合类比这些容器功能还多,其中有些是方便放入和取出的,有些是方便查找的。在集合中经常会用到泛型来使集合更加安全。
Java 的所有集合类都位于 java.util 包,其中提供了一个表示和操作对象集合的统一构架,包含大量集合接口,以及这些接口的实现类和操作它们的算法。
一个集合是一个对象,但它表示一组对象,Java 集合中实际存放的是对象的引用值,不能存放基本数据类型值。
集合有两大类:单列集合Collection和双列集合Map;
单列集合:
Collection
List set
ArrayList LinkedList Vector HashSet TreeSet
LinkeHashSet
双列集合
Map
Hashtable HashMap TreeMap
Properties LinkedHashMap
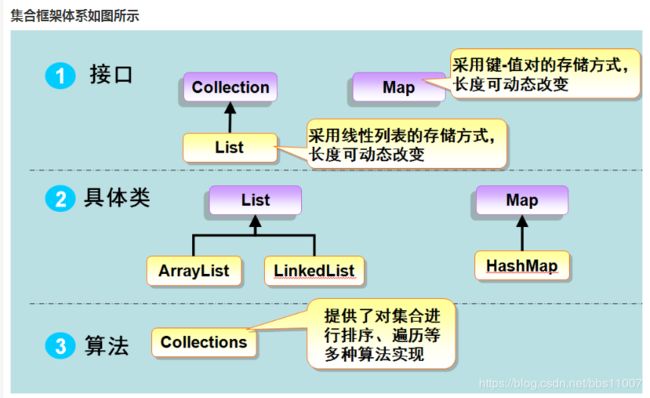
概念:
Collection:该接口是最基本的集合接口,一个 Collection 代表一个元素。
|--List(列表):有索引,可存放重复元素,元素存取是有序的;该接口实现了 Collection 接口。List 是有序集合,允许有相同的元素。使用 List 能够精确地控制每个元素插入的位置,用户能够使用索引(元素在 List 中的位置,类似于数组下标)来访问 List 中的元素,与数组类似。
|--ArrayList:底层数据结构是数组结构,查询速度快,增删速度慢;一个用数组实现的 List,能进行快速的随机访问,效率高而且实现了可变大小的数组。
|--LinkedList:底层数据结构是链表结构,查询速度慢,增删速度快;对顺序访问进行了优化,但随机访问的速度相对较慢。此外它还有 addFirst()、addLast()、getFirst()、getLast()、removeFirst() 和 removeLast() 等方法,能把它当成栈(Stack)或队列(Queue)来用。
|--Vector:底层数据结构是数组结构,线程安全,但速度慢,已被ArrayList替代
|--Set(集):无索引,不可以存放重复元素,元素存取是无序的;该接口也实现了 Collection 接口。它不能包含重复的元素,SortedSet 是按升序排列的 Set 集合
|--HashSet:底层数据结构是哈希表,存取速度快;为优化査询速度而设计的 Set。它是基于 HashMap 实现的,HashSet 底层使用 HashMap 来保存所有元素,实现比较简单
|--TreeSet:底层数据结构是二叉树,可以对Set集合中的元素进行排序;该类不仅实现了 Set 接口,还实现了 java.util.SortedSet 接口,该实现类是一个有序的 Set,这样就能从 Set 里面提取一个有序序列。
|--LinkedHashSet:保留存储顺序, 并且可以过滤重复元素
Map:存储的是键值对,需要保证键的唯一性;包含键值对,Map 不能包含重复的键。SortedMap 是一个按升序排列的 Map 集合。
|--Hashtable:底层数据结构是哈希表,线程安全,速度慢,不允许存放null键和null值
|--HashMap:底层数据结构是哈希表,速度快,允许存放null键和null值。
|--LinkedHashMap
|--TreeMap:底层数据结构是二叉树,对键进行排序,排序原理与TreeSet相同
接下来我们一一细讲:
Collection接口
Collection 接口是 List 接口和 Set 接口的父接口,通常情况下不被直接使用。Collection 接口定义了一些通用的方法,通过这些方法可以实现对集合的基本操作。因为 List 接口和 Set 接口继承自 Collection 接口,所以也可以调用这些方法。
| 方法名称 | 说明 |
|---|---|
| boolean add(E e) | 向集合中添加一个元素,E 是元素的数据类型 |
| boolean addAll(Collection c) | 向集合中添加集合 c 中的所有元素 |
| void clear() | 删除集合中的所有元素 |
| boolean contains(Object o) | 判断集合中是否存在指定元素 |
| boolean containsAll(Collection c) | 判断集合中是否包含集合 c 中的所有元素 |
| boolean isEmpty() | 判断集合是否为空 |
| Iterator |
返回一个 Iterator 对象,用于遍历集合中的元素 |
| boolean remove(Object o) | 从集合中删除一个指定元素 |
| boolean removeAll(Collection c) | 从集合中删除所有在集合 c 中出现的元素 |
| boolean retainAll(Collection c) | 仅仅保留集合中所有在集合 c 中出现的元素 |
| int size() | 返回集合中元素的个数 |
| Object[] toArray() | 返回包含此集合中所有元素的数组 |
例 1:
我们知道 Collection 是非常重要的一个接口,在表 1 中列出了其常用方法。本例将编写一个简单的程序,演示如何使用 Collection 接口向集合中添加方法add(E e)。具体实现代码如下:
public static void main(Strmg[] args)
{
ArrayList list1=new ArrayList(); //创建集合 iist1
ArrayList list2=new ArrayList(); //创建集合 Iist2
list1.add("one"); //向 list1 添加一个元素
list1.add("two"); //向 list1 添加一个元素
list2.addAll(list1); //将 list1 的所有元素添加到 list2
list2.add("three"); //向 list2 添加一个元素
System.out.println("list2 集合中的元素如下:");
Iterator it1=list2.iterator();
while(it1.hasNext())
{
System.out.print(it1.next()+"、");//输出it1的所有值
}
}
由于 Collection 是接口,不能对其实例化,所以上述代码中使用了 Collection 接口的 ArrayList 实现类来调用 Collection 的方法。add() 方法可以向 Collection 中添加一个元素,而调用 addAll() 方法可以将指定 Collection 中的所有元素添加到另一个 Collection 中。
创建了两个集合 list1 和 list2,然后调用 add() 方法向 list1 中添加了两个元素,再调用 addAll() 方法将这两个元素添加到 list2 中。接下来又向 list2 中添加了一个元素,最后输出 list2 集合中的所有元素,结果如下:
list2 集合中的元素如下:
one、two、three、例 2:
创建一个案例,演示 Collection 集合中 size()、remove() 和 removeAll() 方法的应用。具体代码如下:
public static void main(String[] args)
{
ArrayList list1=new ArrayList(); //创建集合 list1
ArrayList list2=new ArrayList(); //创建集合 list2
list1.add("one");
list1.add("two");
list1.add("three");
System.out.println("list1 集合中的元素数量:"+list1.size()); //输出list1中的元素数量
list2.add("two");
list2.add("four");
list2.add("six");
System.out.println("list2 集合中的元素数量:"+list2.size()); //输出list2中的元素数量
list2.remove(2); //删除第 3 个元素,remove()的用法
System.out.println("\nremoveAll() 方法之后 list2 集合中的元素数量:"+list2.size());
System.out.println("list2 集合中的元素如下:");
Iterator it1=list2.iterator();//返回一个 Iterator 对象,用于遍历集合中的元素,Iteratoriterator()的用法
while(it1.hasNext())
{
System.out.print(it1.next()+"、");
}
list1.removeAll(list2);//删除与list2所有相同的元素,remove()的用法
System.out.println("\nremoveAll() 方法之后 list1 集合中的元素数量:"+list1.size());
System.out.println("list1 集合中的元素如下:");
Iterator it2=list1.iterator();//返回一个 Iterator 对象,用于遍历集合中的元素,Iteratoriterator()的用法
while(it2.hasNext())
{
System.out.print(it2.next()+"、");//输出it2的值
}
}
list2 集合在调用 remove(2) 方法删除第 3 个元素之后剩下了 two 和 four。list1.removeAll(list2) 语句会从 list1 中将 list1 和 list2 中相同的元素删除,即删除 two 元素。最后输出结果如下:
list1 集合中的元素数量:3
Iist2 集合中的元素数量:3
remove() 方法之后 list2 集合中的元素数量:2
list2 集合中的元素如下:
two、four、
removeAH() 方法之后 list1 集合中的元素数量:2
list1 集合中的元素如下:
one、 three、
注意:retainAll() 方法的作用与 removeAll() 方法相反,即retainAll()保留两个集合中相同的元素,其他全部删除。
List接口的两种类使用方法
List 接口实现了 Collection 接口,它主要有两个实现类:ArrayList 类和 LinkedList 类。在 List 集合中允许出现重复元素。与 Set 集合不同的是,在 List 集合中的元素是有序的,可以根据索引位置来检索 List 集合中的元素,第一个添加到 List 集合中的元素的索引为 0,第二个为 1,依此类推。
--1.ArrayList 类
ArrayList 类提供了快速的基于索引的成员访问方式,对尾部成员的增加和删除支持较好。使用 ArrayList 创建的集合,允许对集合中的元素进行快速的随机访问,不过,向 ArrayList 中插入与删除元素的速度相对较慢。该类的常用构造方法有如下两种重载形式。
- ArrayList():构造一个初始容量为 10 的空列表。
- ArrayList(Collectionc):构造一个包含指定 Collection 的元素的列表,这些元素是按照该 Collection 的迭代器返回它们的顺序排列的。
ArrayList 类除了包含 Collection 接口中的所有方法之外,还包括 List 接口中提供的如表 1 所示的方法。
| 方法名称 | 说明 |
|---|---|
| E get(int index) | 获取此集合中指定索引位置的元素,E 为集合中元素的数据类型 |
| int index(Object o) | 返回此集合中第一次出现指定元素的索引,如果此集合不包含该元 素,则返回 -1 |
| int lastIndexOf(Obj ect o) | 返回此集合中最后一次出现指定元素的索引,如果此集合不包含该 元素,则返回 -1 |
| E set(int index, E element) | 将此集合中指定索引位置的元素修改为 element 参数指定的对象。 此方法返回此集合中指定索引位置的原元素 |
| List |
返回一个新的集合,新集合中包含 fromlndex 和 tolndex 索引之间 的所有元素。包含 fromlndex 处的元素,不包含 tolndex 索引处的 元素,取区间:[fromlndex , tolndex ) |
例 1
使用 ArrayList 类向集合中添加三个商品信息,包括商品编号、名称和价格,然后遍历集合输出这些商品信息。
(1) 创建一个商品类 Product,在该类中定义 3 个属性和 toString() 方法,分别实现 setter/getter 方法。代码的实现如下:
public class Product //商品类
{
private int id; //商品编号
private String name; //名称
private float price; //价格
public Product(int id,String name,float price)//构造方法,初始化
{
this.name=name;
this.id=id;
this.price=price;
}
//这里是上面3个属性的setter/getter方法,这里省略
public String toString()
{
return"商品编号:"+id+",名称:"+name+",价格:"+price;
}
}(2) 创建一个测试类(main函数),调用 Product 类的构造函数实例化三个对象,并将 Product 对象保存至 ArrayList 集合中。最后遍历该集合,输出商品信息。测试类的代码实现如下:
import Java.util.ArrayList;
import java.util.List;
public class Test03
{
public static void main(String[] args)
{
Product pd1=new Product(4,"口香糖",10);
Product pd2=new Product(5,"沐浴露",12);
Product pd3=new Product(3,"烧水壶",49);
List list=new ArrayList(); //创建集合
list.add(pd1);
list.add(pd2);
list.add(pd3);
System.out.println("*************** 商品信息 ***************");
for(int i=0;i该示例中的 ArrayList 集合中存放的是自定义类 Product 的对象,这与存储的 String 类的对象是相同的。与 Set 不同的是,List 集合中存在 get() 方法,该方法可以通过索引来获取所对应的值,获取的值为 Object 类,因此需要将该值转换为 Product 类,从而获取商品信息。
该程序的运行结果如下所示。
*************** 商品信息 ***************
商品编号:4,名称:口香糖,价格:10.0
商品编号:5,名称:沐浴露,价格:12.0
商品编号:3,名称:烧水壶,价格:49.0例 2
在使用 List 集合时需要注意区分 indexOf() 方法和 lastIndexOf() 方法。前者是获得指定对象的最小索引位置,而后者是获得指定对象的最大索引位置。前提条件是指定的对象在 List 集合中有重复的对象,否则这两个方法获取的索引值相同。
下面的案例代码演示了 indexOf() 方法和 lastIndexOf() 方法的区别。
public static void main(String[] args)
{
List list=new ArrayList();//创建集合
list.add("One");
list.add("|"); //“|”这个第一次出现的位置
list.add("Two");
list.add("|");
list.add("Three");
list.add("|"); //“|”这个最后出现的位置
list.add("Four");
System.out.println("list 集合中的元素数量:"+list.size());
System.out.println("list 集合中的元素如下:");
Iterator it=list.iterator();//用于遍历集合元素的
while(it.hasNext())
{
System.out.print(it.next()+"、");
}
/* indexOf()方法的使用:返回此集合中第一次出现指定元素的索引,如果此集合不包含该元素,则返回 -1 */
System.out.println("\n在 list 集合中'丨'第一次出现的位置是:"+list.indexOf("|"));
/* lastIndexOf()方法的使用:返回此集合中最后一次出现指定元素的索引,如果此集合不包含该元素,则返回 -1 */
System.out.println("在 list 集合中'丨'最后一次出现的位置是:"+list.lastIndexOf("|"));
}indexOf()用于第一次出现的位置;
lastIndexOf() 用于最后一次出现的位置;
上述代码创建一个 List 集合 list,然后添加了 7 个元素,由于索引从 0 开始,所以最后一个元素的索引为 6。输出结果如下:
list 集合中的元素数量:7
list 集合中的元素如下:
One、|、Two、|、Three、|、Four、
在 list 集合中'|'第一次出现的位置是:1
在 list 集合中'|'最后一次出现的位置是:5例 3
使用 subList() 方法截取 List 集合中部分元素时要注意,新的集合中包含起始索引位置的元素,但是不包含结束索引位置的元素。例如,subList(1,4) 方法实际截取的是索引 1 到索引 3 的元素,并组成新的 List 集合。
下面的案例代码演示了 subList() 方法的具体用法。
public static void main(String[] args)
{
List list=new ArrayList();
list.add("One");
list.add("Two");
list.add("Three");
list.add("Four");
list.add("Five");
list.add("Six");
list.add("Seven");
System.out.println("list 集合中的元素数量:"+list.size());
System.out.println("list 集合中的元素如下:");
Iterator it=list.iterator();
while(it.hasNext())
{
System.out.print(it.next()+"、");
}
List sublist=new ArrayList();
sublist=list.subList(2,5); //从list集合中截取索引[2~5)的元素,保存到sublist集合中
System.out.println("\nsublist 集合中元素数量:"+sublist.size());//输出2、3、4位置的元素(从左到右,从0开始数),包含第2元素不包含第5元素
System.out.println("sublist 集合中的元素如下:");
it=sublist.iterator();
while(it.hasNext())
{
System.out.print(it.next()+"、");
}
}输出结果如下:
list 集合中的元素数量:7
list 集合中的元素如下:
One、Two、Three、Four、Five、Six、Seven、
sublist 集合中元素数量:3
sublist 集合中的元素如下:
Three、Four、Five、注意:subList(2,5)取得边界是:[2,5), 即:2<=subList<5 ,包含2不包含5
---2.LinkList类
LinkedList 类采用链表结构保存对象,这种结构的优点是便于向集合中插入或者删除元素。需要频繁向集合中插入和删除元素时,使用 LinkedList 类比 ArrayList 类效果高,但是 LinkedList 类随机访问元素的速度则相对较慢。这里的随机访问是指检索集合中特定索引位置的元素。
LinkedList 类除了包含 Connection 接口和 List 接口中的所有方法之外,还特别提供了表 2 所示的方法。
| 方法名称 | 说明 |
|---|---|
| void addFirst(E e) | 将指定元素添加到此集合的开头 |
| void addLast(E e) | 将指定元素添加到此集合的末尾 |
| E getFirst() | 返回此集合的第一个元素 |
| E getLast() | 返回此集合的最后一个元素 |
| E removeFirst() | 删除此集合中的第一个元素 |
| E removeLast() | 删除此集合中的最后一个元素 |
例 4
在仓库管理系统中要记录入库的商品名称,并且需要输出第一个录入的商品名称和最后—个商品名称。下面使用 LinkedList 集合来完成这些功能,实现代码如下:
public static void main(String[] args)
{
LinkedList products=new LinkedList(); //创建products集合对象,都是String类型
/*对象一定是String类型*/
String p1=new String("六角螺母");
String p2=new String("10A 电缆线");
String p3=new String("5M 卷尺");
String p4=new String("4CM 原木方板");
products.add(p1); //将 pi 对象添加到 LinkedList 集合中
products.add(p2); //将 p2 对象添加到 LinkedList 集合中
products.add(p3); //将 p3 对象添加到 LinkedList 集合中
products.add(p4); //将 p4 对象添加到 LinkedList 集合中
String p5=new String("标准文件夹小柜");
products.addLast(p5); //向集合的末尾添加p5对象,addLast()方法的使用
System.out.print("*************** 商品信息 ***************");
System.out.println("\n目前商品有:");
for(int i=0;i
如上述代码,首先创建了 5 个 String 对象,分别为 p1、p2、p3、p4 和 p5。同时将 pl、 p2、p3 和 p4 对象使用 add() 方法添加到 LinkedList 集合中,使用 addLast() 方法将 p5 对象添加到 LinkedList 集合中。分别调用 LinkedList 类中的 getFirst() 方法和 getLast()方法获取第一个和最后一个商品名称。最后使用 removeLast() 方法将最后一个商品信息删除,并将剩余商品信息打印出来。
LinkedList
运行程序,执行结果如下:
*************** 商品信息 ***************
目前商品有:
六角螺母 10A 电缆线 5M 卷尺 4CM 原木方板 标准文件夹小柜
第一个商品的名称为:六角螺母
最后一个商品的名称为:标准文件夹小柜
删除最后的元素,目前商品有:
六角螺母 10A 电缆线 5M 卷尺 4CM 原木方板Set接口的两种类使用方法
Set 集合也实现了 Collection 接口,它主要有两个实现类:HashSet 类和 TreeSet类。Set 集合中的对象不按特定的方式排序,只是简单地把对象加入集合,集合中不能包含重复的对象,并且最多只允许包含一个 null 元素。
--1.HashSet 类
HashSet 类是按照哈希算法来存储集合中的元素,使用哈希算法可以提高集合元素的存储速度,当向 Set 集合中添加一个元素时,HashSet 会调用该元素的 hashCode() 方法,获取其哈希码,然后根据这个哈希码计算出该元素在集合中的存储位置。
在 HashSet 类中实现了 Collection 接口中的所有方法。HashSet 类的常用构造方法重载形式如下。
- HashSet():构造一个新的空的 Set 集合。
- HashSet(Collectionc):构造一个包含指定 Collection 集合元素的新 Set 集合。其中,“< >”中的 extends 表示 HashSet 的父类,即指明该 Set 集合中存放的集合元素类型。c 表示其中的元素将被存放在此 Set 集合中。
下面的代码演示了创建两种不同形式的 HashSet 对象。
HashSet hs=new HashSet(); //调用无参的构造函数创建HashSet对象
HashSet hss=new HashSet(); //创建泛型的 HashSet 集合对象 例 1
编写一个 Java 程序,使用 HashSet 创建一个 Set 集合,并向该集合中添加 5 本图书名称。具体实现代码如下:
public static void main(String[] args)
{
HashSet bookSet=new HashSet(); //创建一个空的 Set 集合
String book1=new String("如何成为 Java 编程高手");
String book2=new String("Java 程序设计一百例");
String book3=new String("从零学 Java 语言");
String book4=new String("论 java 的快速开发");
bookSet.add(book1); //将 bookl 存储到 Set 集合中
bookSet.add(book2); //将 book2 存储到 Set 集合中
bookSet.add(book3); //将 book3 存储到 Set 集合中
bookSet.add(book4); //将 book4 存储到 Set 集合中
System.out.println("新进图书有:");
Iterater it=bookSet.iterator();
while(it.hasNext())
{
System.out.println("《"+(String)it.next()+"》"); //输出 Set 集合中的元素
}
System.out.println("共采购 "+bookSet.size()+" 本图书!");
} 如上述代码,首先使用 HashSet 类的构造方法创建了一个 Set 集合,接着创建了 4 个 String 类型的对象,并将这些对象存储到 Set 集合中。使用 HashSet 类中的 iterator() 方法获取一个 Iterator 对象,并调用其 hasNext() 方法遍历集合元素,再将使用 next() 方法读取的元素强制转换为 String 类型。最后调用 HashSet 类中的 size() 方法获取集合元素个数。
运行该程序,输出的结果如下:
新进图书有:
《如何成为 Java 编程高手》
《从零学 Java 语言》
《Java 程序设计一百例》
《论 java 的快速开发》
共采购 4 本图书!
注意:在该示例中,如果再向 bookSet 集合中添加一个名称为“Java 程序设计一百例”的 String 对象,则输出的结果与上述执行结果相同。也就是说,如果向 Set 集合中添加两个相同的元素,则后添加的会覆盖前面添加的元素,即在 Set 集合中不会出现相同的元素。
---2.TreeSet 类
TreeSet 类同时实现了 Set 接口和 SortedSet 接口。SortedSet 接口是 Set 接口的子接口,可以实现对集合进行自然排序,因此使用 TreeSet 类实现的 Set 接口默认情况下是自然排序的,这里的自然排序指的是升序排序。
TreeSet 只能对实现了 Comparable 接口的类对象进行排序,因为 Comparable 接口中有一个 compareTo(Object o) 方法用于比较两个对象的大小。例如 a.compareTo(b),如果 a 和 b 相等,则该方法返回 0;如果 a 大于 b,则该方法返回大于 0 的值;如果 a 小于 b,则该方法返回小于 0 的值。
表 1 列举了 JDK 类库中实现 Comparable 接口的类,以及这些类对象的比较方式。
| 类 | 比较方式 | |
|---|---|---|
| 包装类(BigDecimal、Biglnteger、 Byte、Double、 Float、Integer、Long 及 Short) |
按数字大小比较 | |
| Character | 按字符的 Unicode 值的数字大小比较 | |
| String | 按字符串中字符的 Unicode 值的数字大小比较 | |
TreeSet 类除了实现 Collection 接口的所有方法之外,还提供了如表 2 所示的方法。
| 方法名称 | 说明 |
|---|---|
| E first() | 返回此集合中的第一个元素。其中,E 表示集合中元素的数据 类型 |
| E last() | 返回此集合中的最后一个元素 |
| E poolFirst() | 获取并移除此集合中的第一个元素 |
| E poolLast() | 获取并移除此集合中的最后一个元素 |
| SortedSet |
返回一个新的集合,新集合包含原集合中 fromElement 对象与 toElement 对象之间的所有对象。包含 fromElemen t对象,不包含 toElement 对象 |
SortedSet| 返回一个新的集合,新集合包含原集合中 toElement 对象之前的所有对象。 |
不包含 toElement 对象 |
| SortedSet |
返回一个新的集合,新集合包含原集合中 fromElement 对象之后的所有对 象。包含 fromElement 对象 |
例 2
本次有 5 名学生参加考试,当老师录入每名学生的成绩后,程序将按照从低到高的排列顺序显示学生成绩。此外,老师可以查询本次考试是否有满分的学生存在,不及格的成绩有哪些,90 分以上成绩的学生有几名。
下面使用TreeSet类来创建Set集合,完成学生成绩查询功能。具体的代码如下:
import java.util.Iterator;
import java.util.Scanner;
import java.util.SortedSet;
import java.util.TreeSet;
public class Test08
{
public static void main(String[] args)
{
TreeSet scores=new TreeSet(); //创建 TreeSet 集合
Scanner input=new Scanner(System.in);//由用户输入
System.out.println("------------学生成绩管理系统-------------");
for(int i=0;i<5;i++)
{
System.out.println("第"+(j+1)+"个学生成绩:");
double score=input.nextDouble();
//将学生成绩转换为Double类型,添加到TreeSet集合中
scores.add(Double.valueOf(score));
}
Iterator it=scores.iterator(); //创建 Iterator 对象
System.out.println("学生成绩从低到高的排序为:");
while(it.hasNext())
{
System.out.print(it.next()+"\t");
}
System.out.println("\n请输入要查询的成绩:");
double searchScore=input.nextDouble();
if(scores.contains(searchScore))
{
System.out.println("成绩为: "+searchScore+" 的学生存在!");
}
else
{
System.out.println("成绩为: "+searchScore+" 的学生不存在!");
}
//查询不及格的学生成绩
SortedSet score1=scores.headSet(60.0);
System.out.println("\n不及格的成绩有:");
for(int i=0;i score2=scores.tailSet(90.0);
System.out.println("\n90 分以上的成绩有:");
for(int i=0;i 如上述代码,首先创建一个 TreeSet 集合对象 scores,并向该集合中添加 5 个 Double 对象。接着使用 while 循环遍历 scores 集合对象,输出该对象中的元素,然后调用 TreeSet 类中的 contains() 方法获取该集合中是否存在指定的元素。最后分别调用 TreeSet 类中的 headSet() 方法和 tailSet() 方法获取不及格的成绩和 90 分以上的成绩。
运行该程序,执行结果如下所示。
------------学生成绩管理系统-------------
第1个学生成绩:
53
第2个学生成绩:
48
第3个学生成绩:
85
第4个学生成绩:
98
第5个学生成绩:
68
学生成绩从低到高的排序为:
48.0 53.0 68.0 85.0 98.0
请输入要查询的成绩:
90
成绩为: 90.0 的学生不存在!
不及格的成绩有:
48.0 53.0
90 分以上的成绩有:
98.0
注意:在使用自然排序时只能向 TreeSet 集合中添加相同数据类型的对象,否则会抛出 ClassCastException 异常。如果向 TreeSet 集合中添加了一个 Double 类型的对象,则后面只能添加 Double 对象,不能再添加其他类型的对象,例如 String 对象等。
Map集合
Map 是一种键-值对(key-value)集合,Map 集合中的每一个元素都包含一个键对象和一个值对象。其中,键对象不允许重复,而值对象可以重复,并且值对象还可以是 Map 类型的,就像数组中的元素还可以是数组一样。
Map 接口主要有两个实现类:HashMap 类和 TreeMap 类。其中,HashMap 类按哈希算法来存取键对象,而 TreeMap 类可以对键对象进行排序。
Map 接口中提供的常用方法如表 1 所示。
| 方法名称 | 说明 |
|---|---|
| V get(Object key) | 返回 Map 集合中指定键对象所对应的值。V 表示值的数据类型 |
| V put(K key, V value) | 向 Map 集合中添加键-值对,返回 key 以前对应的 value,如果没有, 则返回 null |
| V remove(Object key) | 从 Map 集合中删除 key 对应的键-值对,返回 key 对应的 value,如 果没有,则返回null |
| Set entrySet() | 返回 Map 集合中所有键-值对的 Set 集合,此 Set 集合中元素的数据 类型为 Map.Entry |
| Set keySet() | 返回 Map 集合中所有键对象的 Set 集合 |
例 1
每名学生都有属于自己的唯一编号,即学号。在毕业时需要将该学生的信息从系统中移除。
下面编写 Java 程序,使用 HashMap 来存储学生信息,其键为学生学号,值为姓名。毕业时,需要用户输入学生的学号,并根据学号进行删除操作。具体的实现代码如下:
import java.util.HashMap;
import java.util.Iterator;
import java.util.Scanner;
public class Test09
{
public static void main(String[] args)
{
HashMap users=new HashMap();
users.put("11","张浩太"); //将学生信息键值对存储到Map中
users.put("22","刘思诚");
users.put("33","王强文");
users.put("44","李国量");
users.put("55","王路路");
System.out.println("******** 学生列表 ********");
Iterator it=users.keySet().iterator();
while(it.hasNext())
{
//遍历 Map
Object key=it.next();
Object val=users.get(key);
System.out.println("学号:"+key+",姓名:"+val);
}
Scanner input=new Scanner(System.in);
System.out.println("请输入要删除的学号:");
int num=input.nextInt();
if(users.containsKey(String.valueOf(num)))
{ //判断是否包含指定键
users.remove(String.valueOf(num)); //如果包含就删除
}
else
{
System.out.println("该学生不存在!");
}
System.out.println("******** 学生列表 ********");
it=users.keySet().iterator();
while(it.hasNext())
{
Object key=it.next();
Object val=users.get(key);
System.out.println("学号:"+key+",姓名:"+val);
}
}
}
在该程序中,两次使用 while 循环遍历 HashMap 集合。当有学生毕业时,用户需要输入该学生的学号,根据学号使用 HashMap 类的 remove() 方法将对应的元素删除。程序运行结果如下所示。
******** 学生列表 ********
学号:44,姓名:李国量
学号:55,姓名:王路路
学号:22,姓名:刘思诚
学号:33,姓名:王强文
学号:11,姓名:张浩太
请输入要删除的学号:
22
******** 学生列表 ********
学号:44,姓名:李国量
学号:55,姓名:王路路
学号:33,姓名:王强文
学号:11,姓名:张浩太******** 学生列表 ********
学号:44,姓名:李国量
学号:55,姓名:王路路
学号:22,姓名:刘思诚
学号:33,姓名:王强文
学号:11,姓名:张浩太
请输入要删除的学号:
44
******** 学生列表 ********
学号:55,姓名:王路路
学号:22,姓名:刘思诚
学号:33,姓名:王强文
学号:11,姓名:张浩太
注意:TreeMap 类的使用方法与 HashMap 类相同,唯一不同的是 TreeMap 类可以对键对象进行排序,这里不再赘述。
Collection类:sort()升序排序、reverse()降序排序、copy()复制、fill()填充
正向排序/升序排序sort()
----从低到高排序
使用 Collections 类的静态方法 sort() 可以对集合中的元素进行升序排序。这要求列表中的所有元素都必须实现 Comparable 接口,而且所有元素都必须是使用指定比较器可相互比较的。
sort() 方法主要有如下两种重载形式,固定格式。
void sort(List list):根据元素的自然顺序对集合中的元素进行升序排序。
void sort(List list,Comparator comparator):按 comparator 参数指定的排序方式对集合中的元素进行排序。例 1
编写一个程序,对用户输入的 5 个商品价格进行排序后输出。这里要求使用 Collections 类中 sort() 方法按从低到局的顺序对其进行排序,最后将排序后的成绩输出。
具体实现代码如下:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Scanner;
public class Test10
{
public static void main(String[] args)
{
Scanner input=new Scanner(System.in);
List prices=new ArrayList();
for(int i=0;i<5;i++)
{
System.out.println("请输入第 "+(i+1)+" 个商品的价格:");
int p=input.nextInt();
prices.add(Integer.valueOf(p)); //将录入的价格保存到List集合中
}
Collections.sort(prices); //调用sort()方法对集合进行排序
System.out.println("价格从低到高的排列为:");
for(int i=0;i如上述代码,循环录入 5 个价格,并将每个价格都存储到已定义好的 List 集合 prices 中,然后使用 Collections 类的 sort() 方法对该集合元素进行升序排序。最后使用 for 循环遍历 users 集合,输出该集合中的元素。
该程序的执行结果如下所示:请输入第 1 个商品的价格:
85
请输入第 2 个商品的价格:
48
请输入第 3 个商品的价格:
66
请输入第 4 个商品的价格:
80
请输入第 5 个商品的价格:
18
价格从低到高的排列为:
18 48 66 80 85逆向排序/reverse()降序排序
---从高到低排序
与 sort() 方法的作用相反,调用 reverse() 静态方法可以对指定集合元素进行逆向排序。该方法的定义如下,固定格式:
void reverse(List list) //对集合中的元素进行反转排序例 2
循环录入 5 个商品的名称,并按录入时间的先后顺序进行降序排序,即后录入的先输出。
下面编写程序,使用 Collections 类的 reverse() 方法对保存到 List 集合中的 5 个商品名称进行反转排序,并输出排序后的商品信息。按照时间先后,此案例是按时间降序输出,具体的实现代码如下:
import java.util.ArrayList;
import java.util.Coliections;
import java.util.List;
import java.util.Scanner;
public class Test11
{
public static void main(String[] args)
{
Scanner input=new Scanner(System.in);//由用户输入内容
List students=new ArrayList();//创建集合
System.out.println("******** 商品信息 ********");
for(int i=0;i<5;i++)
{
System.out.println("请输入第 "+(i+1)+" 个商品的名称:");
String name=input.next(); //获取用户的输入内容
students.add(name); //将录入的商品名称存到List集合中
}
Collections.reverse(students); //调用reverse()方法对集合元素进行反转排序
System.out.println("按录入时间的先后顺序进行降序排列为:");
for(int i=0;i<5;i++)
{
System.out.print(students.get(i)+"\t");
}
}
}
如上述代码,首先循环录入 5 个商品的名称,并将这些名称保存到 List 集合中,然后调用 Collections 类中的 reverse() 方法对该集合元素进行反转排序。最后使用 for 循环将排序后的集合元素输出。
执行该程序,输出结果如下所示。
******** 商品信息 ********
请输入第 1 个商品的名称:
果粒橙
请输入第 2 个商品的名称:
冰红茶
请输入第 3 个商品的名称:
矿泉水
请输入第 4 个商品的名称:
软面包
请输入第 5 个商品的名称:
巧克力
按录入时间的先后顺序进行降序排列为:
巧克力 软面包 矿泉水 冰红茶 果粒橙 复制copy()
Collections 类的 copy() 静态方法用于将指定集合中的所有元素复制到另一个集合中。执行 copy() 方法后,目标集合中每个已复制元素的索引将等同于源集合中该元素的索引。
copy() 方法的语法格式如下:
void copy(List dest,List src)其中,dest 表示目标集合对象,src 表示源集合对象。
注意:目标集合的长度至少和源集合的长度相同,如果目标集合的长度更长,则不影响目标集合中的其余元素。如果目标集合长度不够而无法包含整个源集合元素,程序将抛出 IndexOutOfBoundsException 异常。
例 3
在一个集合中保存了 5 个商品名称,现在要使用 Collections 类中的 copy() 方法将其中的 3 个替换掉。具体实现的代码如下:
public class Test12
{
public static void main(String[] args)
{
Scanner input=new Scanner(System.in);
List srcList=new ArrayList();
List destList=new ArrayList();
destList.add("苏打水");
destList.add("木糖醇");
destList.add("方便面");
destList.add("火腿肠");
destList.add("冰红茶");
System.out.println("原有商品如下:");
for(int i=0;i
如上述代码,首先创建了两个 List 对象 srcList 和 destList,并向 destList 集合中添加了 5 个元素,向 srcList 集合中添加了 3 个元素,然后调用 Collections 类中 copy() 方法将 srcList 集合中的全部元素复制到 destList 集合中。由于 destList 集合中含有 5 个元素,故最后两个元素不会被覆盖。
运行该程序,具体的执行结果如下所示。
原有商品如下:
苏打水
木糖醇
方便面
火腿肠
冰红茶
输入替换的商品名称:
第 1 个商品:
燕麦片
第 2 个商品:
八宝粥
第 3 个商品:
软面包
当前商品有:
燕麦片 八宝粥软面包 火腿肠 冰红茶填充fill()
Collections 类的 fill() 静态方法可以对指定集合的所有元素进行填充操作。fill() 方法的定义如下:
void fill(List list,T obj) //使用指定元素替换指定列表中的所有元素其中,list 表示要替换的集合对象,obj 表示用来替换指定集合的元素值。
例 4
编写一个程序,要求用户输入 3 个商品名称,然后使用 Collections 类中的 fill() 方法对商品信息进行重置操作,即将所有名称都更改为“未填写”。具体的实现代码如下:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Scanner;
public class Test13
{
public static void main(String[] args)
{
Scanner input=new Scanner(System.in);
List products=new ArrayList();
System.out.println("******** 商品信息 ********");
for(int i=0;i<3;i++)
{
System.out.println("请输入第 "+(i+1)+" 个商品的名称:");
String name=input.next();
products.add(name); //将用户录入的商品名称保存到List集合中
}
System.out.println("重置商品信息,将所有名称都更改为'未填写'");
Collections.fill(products,"未填写");
System.out.println("重置后的商品信息为:");
for(int i=0;i
如上述代码,首先循环录入 3 个商品名称,并将这些商品信息存储到 List 集合中,然后调用 Collections 类中的 fill() 方法将该集合中的所有元素值替换为“未填写”。最后使用 for 循环将替换后的集合元素输出。
运行该程序,执行结果如下所示。
******** 商品信息 ********
请输入第 1 个商品的名称:
苏打水
请输入第 2 个商品的名称:
矿泉水
请输入第 3 个商品的名称:
冰红茶
重置商品信息,将所有名称都更改为'未填写'
重置后的商品信息为:
未填写 未填写 未填写
泛型
概念:由于类型转换错误,java虚拟机编译时不会报错,而在运行时报异常,所以安全隐患非常明显,----所以用泛型来弥补这一缺陷;有个<>;在代码中会经常看到泛型,所以要学好它,
泛型也类似数组,数组是[],泛型是<>,数组里面放的数值,泛型里面放的类型,可以这么理解,泛型就是取数组里面的类型,如:ArratList
我另篇详细介绍了泛型:https://blog.csdn.net/bbs11007/article/details/80835234
泛型<>里面必须是引用类型,不能使基本类型(如int、long这些)

基本类型解决方案(引用包装类知识,请查看该内容知识):

基本类型引用包装类就可以使用泛型了。
![]()
具体使用
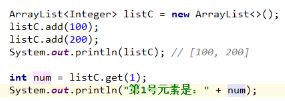
输出时200;
ArayList
比如在集合类添加对象的时候,我们经常做格式强转操作,
说白了,泛型就是在你写强转类型的时候,给你个错误提示,让你知道这个是错误了。
固定格式(加个"<>"):
集合类 <需要转换的类>
例如(下面的就是泛型):类似定义数组,相当于数组都是String
ArrayList
ArrayList
//JDK1.6以下:左右两边尖括号都不能为空,如:ArrayList
加上泛型,强转类型会提前报错,不加泛型,强转类型不会报错,但你一旦运行就报错;
代码案例来说明(注意看注释说明就明白了):

如图,本来定于

//代码简单缩写,说明下泛型的作用
//不加泛型的时候
ArrayList ff = new ArrayList();//这个没有加泛型
Ls ls1 = new ls("薯片");//LS是零食的类
ff.add(ls1);
Ls cls=ff.get(0);//这个ff是ArrayList类,cls是LS的类,这两个类不能直接赋值,会直接报错,如int和char不能直接赋值,需要强转,如:int a = (int)b
Ls cls=(LS)ff.get(0);//强转操作,所以需要强转操作,这样子编译器不会报错,但这个get 0不能直接添加到零食里,所以一运行,就报错了,这就是没有加泛型的缺点
//我们在来看看加泛型以后的区别
ArrayList ff = new ArrayList();//这个是加泛型的,意思是我只允许你添加零食,其他都不给你添加
Ls ls1 = new ls("薯片");//LS是零食的类
ff.add(ls1);
Ls cls=(LS)ff.get(0);//注意:加泛型后,这句话就直接报错了,不用等允许才知道错误,这样子程序员不运行,在写代码的时候一眼就看出问题了。
除了add,还要其他方法。
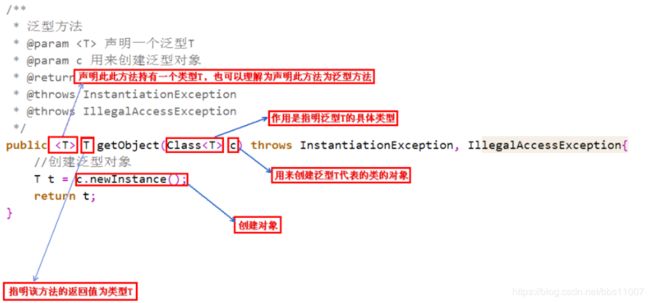
https://blog.csdn.net/github_37130188/article/details/96508766
反射reflect
详解请看我另篇专项讲解:https://blog.csdn.net/bbs11007/article/details/99678074
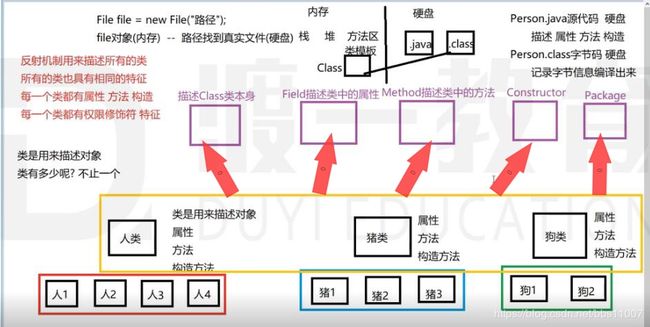
首先介绍 Java 中 Class 类与 Java 反射的基本用法,然后介绍具体的反射应用。为了便于读者理解,在讲解过程中还结合了大量案例
通过 Java 的反射机制,程序员可以更深入地控制程序的运行过程。例如,在程序运行时由用户输入一个类名,然后动态获取该类拥有的构造、属性和方法,甚至调用任意类的任意方法。
泛型是提示强转类型,就一行,就在;反射的功能就强大点,可以写在类或方法中。
动态的获取指定的类以及动态的调用类中的内容。以前,先有类,再new对象。有了反射后:先new对象,至于new哪个类由用户通过配置文件传递。即在没有类之前就将创建对象的动作完成了。
好处:大大的提高了程序的扩展性。应用:当使用的类不确定的时候,可以通过配置文件告诉应用程序,只要应用程序中使用反射技术即可。
Java 反射机制是 Java 语言的一个重要特性,它在服务器程序和中间件程序中得到了广泛运用。在服务器端,往往需要根据客户的请求,动态调用某一个对象的特定方法。此外,在 ORM 中间件的实现中,运用 java 反射机制可以读取任意一个 JavaBean 的所有属性,或者给这些属性赋值。
视频教学https://ke.qq.com/webcourse/index.html#cid=375599&term_id=100447257&taid=2891999049268015&vid=v1431lhb455

我另篇详细介绍了反射:
【转载】反射进阶学习:https://blog.csdn.net/bbs11007/article/details/80835247
【转载】细说反射,Java 和 Android 开发者必须跨越的坎:https://blog.csdn.net/bbs11007/article/details/80835266
一个反射概念简单学习的网址:http://c.biancheng.net/view/1103.html
代码说明:
//如果别的程序员写的一个玩具(wj)方法,我也不知道这个方法有什么
class Wj//玩具类
{
public void wan()//玩的方法
{
system.out。println(“正在玩游戏”);
}
public void 加法(int a,int b)//一个加游戏的方法
{
return a+b;
}
}我可以通过类和泛型传进来,因为我不知道那个写方法的程序员用的是什么类型,这样经常会搞错,所以我们可以通过泛型来解决这一个问题;
JVM虚拟机
https://blog.csdn.net/bbs11007/article/details/100066875
类加载:https://blog.csdn.net/github_37130188/article/details/97254899
---------------------未完,陆续更新中!------------------------