从主坐标分析(PCO)到kernel PCA
- Principal coordinate analysis
PCA是一种经典的降维方法,相信大家都很熟悉PCA的原理了,PCO其实只是PCA换一种角度来做,都是在做奇异值分解。PCA做法:原始数据矩阵  ,
, ![]() , 先做中心化处理得到
, 先做中心化处理得到 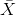 ,计算方差矩阵
,计算方差矩阵 ![]() ,然后计算
,然后计算  的最大
的最大  个特征值对应的特征向量,然后和原始特征相乘,即得到降维的结果。为了更清楚的显示它的本质,将这个过程表示成矩阵。
个特征值对应的特征向量,然后和原始特征相乘,即得到降维的结果。为了更清楚的显示它的本质,将这个过程表示成矩阵。
将 中心化表示成矩阵的形式, 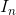 表示单位矩阵,
表示单位矩阵,![]() 表示全1 的
表示全1 的 维列向量:
维列向量: ![]()
记 ![]() , 我们称之为中心矩阵,它的本质就是对数据做中心化处理,即数据矩阵,减去均值矩阵。它有一个很好的性质就是
, 我们称之为中心矩阵,它的本质就是对数据做中心化处理,即数据矩阵,减去均值矩阵。它有一个很好的性质就是![]() ,即它是等幂的,可以手动验证一下。那么我们终于可以得到方差矩阵理想的形式了。
,即它是等幂的,可以手动验证一下。那么我们终于可以得到方差矩阵理想的形式了。 ![]() ,希望大家没有晕。PCA其实就是在对
,希望大家没有晕。PCA其实就是在对![]() 操作。好,重点来了,PCO马上就呼之欲出了,它就是,是是是真的是,对
操作。好,重点来了,PCO马上就呼之欲出了,它就是,是是是真的是,对![]() 求特征值,然后就可以直接得到降维结果了,连和数据矩阵相乘都不需要。下面来证明这一点。
求特征值,然后就可以直接得到降维结果了,连和数据矩阵相乘都不需要。下面来证明这一点。
假设 ![]() , 那么
, 那么 ![]() ,即
,即![]() 与
与 的特征值一样,特征向量之间存在一定的关系,后面的kernel pca还要要用到这个关系。我们把
的特征值一样,特征向量之间存在一定的关系,后面的kernel pca还要要用到这个关系。我们把![]() 看作
看作 , 把
, 把![]() 看作
看作 。原来我们做pca时是求出 个特征向量之后,将其排成矩阵
。原来我们做pca时是求出 个特征向量之后,将其排成矩阵 ![]() , 然后
, 然后 ![]() 就是我们的结果。现在由于
就是我们的结果。现在由于![]() 与
与![]() 的特征值之间存在一定的关系,所以如果
的特征值之间存在一定的关系,所以如果 ![]() 是 原来方差矩阵的特征值,那么
是 原来方差矩阵的特征值,那么![]() 的特征值就是
的特征值就是![]() ,这说明直接对
,这说明直接对![]() 求特征值就得到了pca的结果,这样是不是就直接得到了结果,有没有很神奇呢?这里本质上就是对
求特征值就得到了pca的结果,这样是不是就直接得到了结果,有没有很神奇呢?这里本质上就是对![]() 与
与![]() 做奇异值分解,奇异值是一样的。还没有结束,我们还需要对
做奇异值分解,奇异值是一样的。还没有结束,我们还需要对![]() 的特征值做归一化处理,这里不是归一化到1,我们记
的特征值做归一化处理,这里不是归一化到1,我们记![]() 的特征值为
的特征值为  , 要让
, 要让 ![]() ,
,  是对应的第
是对应的第  个特征值。我们再来总结一下PCO的做法:
个特征值。我们再来总结一下PCO的做法:
记 ![]() ,令 是
,令 是 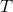 的第 个特征值,即
的第 个特征值,即 ![]() ,对其做归一化处理,
,对其做归一化处理,![]() ,
,![]() ,那么
,那么![]() 就是在维空间的principal coordinates。
就是在维空间的principal coordinates。
注意上面![]() 矩阵中存在
矩阵中存在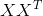 ,是样本之间的内积,可以看作是一个线性核的核矩阵,是不是马上就感觉可以用强大的kernel方法呢,kernel函数本质上是某个高维空间的内积,如果我们将上面的数据矩阵内积用kernel矩阵代替,是不是就可以看作是在某个高维空间进行pca处理呢,因此kernel pca 也呼之欲出了,鼓掌...。kernel方法只需要提供kernel就行了,并不需要直接用到低维空间特征在高维空间的表示。下面来介绍一波kernel pca。
,是样本之间的内积,可以看作是一个线性核的核矩阵,是不是马上就感觉可以用强大的kernel方法呢,kernel函数本质上是某个高维空间的内积,如果我们将上面的数据矩阵内积用kernel矩阵代替,是不是就可以看作是在某个高维空间进行pca处理呢,因此kernel pca 也呼之欲出了,鼓掌...。kernel方法只需要提供kernel就行了,并不需要直接用到低维空间特征在高维空间的表示。下面来介绍一波kernel pca。
- Kernel PCA
假设高维空间特征矩阵为 ,kernel 矩阵
,kernel 矩阵![]() ,注意这里只是假定高维空间矩阵,它的形式我们根本不需要知道。那么现在是对来做PCA,但是我们根本就不知道 是什么,因此方差矩阵
,注意这里只是假定高维空间矩阵,它的形式我们根本不需要知道。那么现在是对来做PCA,但是我们根本就不知道 是什么,因此方差矩阵![]() 没办法来求,但是,还记得前面PCO的做法吗,做不了
没办法来求,但是,还记得前面PCO的做法吗,做不了![]() ,我们可以来做
,我们可以来做![]() 啊,而
啊,而![]() 是已知的,就是kernel 矩阵
是已知的,就是kernel 矩阵 ,到这里,是不是就一下子光明起来了呢?
,到这里,是不是就一下子光明起来了呢?
![]() , 即
, 即![]() 对应特征值为
对应特征值为 的特征向量是
的特征向量是![]() ,做归一化处理,
,做归一化处理,
![]()
这就是pca降维时要用到的特征向量,当对一个高维空间特征  进行降维时,首先减去均值,
进行降维时,首先减去均值,![]() ,然后乘
,然后乘 ,
,
得到投影 :![]() ,
,![]() 是 与中每一个特征的内积,可以利用核函数求出来,而
是 与中每一个特征的内积,可以利用核函数求出来,而![]() 就是kernel ,是已知的,因此整个结果也就可以求出来的,这就是kernel pca, 这个过程中尽管我们用到了
就是kernel ,是已知的,因此整个结果也就可以求出来的,这就是kernel pca, 这个过程中尽管我们用到了 ![]() ,但我们不需要具体知道它们是什么,只需要一个核函数就行了,这样就等价于在一个高维空间做了pca降维。
,但我们不需要具体知道它们是什么,只需要一个核函数就行了,这样就等价于在一个高维空间做了pca降维。
最后来一个总结,pca利用方差矩阵![]() 求得特征值,pco利用
求得特征值,pco利用![]() 直接可以得到降维结果,因为它们的特征值相同,特征向量存在对应关系,而kpca是在变换后的高维特征空间进行pca,即需要求得
直接可以得到降维结果,因为它们的特征值相同,特征向量存在对应关系,而kpca是在变换后的高维特征空间进行pca,即需要求得![]() 的特征值,然而我们不知道 的具体形式,从而借助
的特征值,然而我们不知道 的具体形式,从而借助![]() 来求特征值,做到最后,只需要核矩阵,就可以完成在高维空间的降维。
来求特征值,做到最后,只需要核矩阵,就可以完成在高维空间的降维。