Java HashCode详解
一、为什么要有Hash算法
Java中的集合有两类,一类是List,一类是Set。List内的元素是有序的,元素可以重复。Set元素无序,但元素不可重复。要想保证元素不重复,两个元素是否重复应该依据什么来判断呢?用Object.equals方法。但若每增加一个元素就检查一次,那么当元素很多时,后添加到集合中的元素比较的次数就非常多了。也就是说若集合中已有1000个元素,那么第1001个元素加入集合时,它就要调用1000次equals方法。这显然会大大降低效率。于是Java采用了哈希表的原理。哈希(Hash)是个人名,由于他提出哈希算法的概念就以他的名字命名了。
二、Hash算法原理
HashCode的官方文档定义:
hashCode 的常规协定是:
1.在 Java 应用程序执行期间,只要对象的 equals 比较操作所用的信息没有被修改,那么在同一对象上多次调用 hashCode 方法时,必须一致地返回相同的整数,。从某一应用程序的一次执行到同一应用程序的另一次执行,该整数无需保持一致。
2.如果根据 equals(Object) 方法,两个对象是相等的,那么在两个对象中的每个对象上调用 hashCode 方法都必须生成相同的整数结果。
3.如果根据 equals(java.lang.Object) 方法,两个对象不相等,那么在两个对象中的任一对象上调用 hashCode 方法不一定要产生不同的整数结果。但是,程序员应该知道,为不相等的对象生成不同整数结果可以提高哈希表的性能。 1.hashcode是用来查找的,如果你学过数据结构就应该知道,在查找和排序这一章有
例如内存中有这样的位置
0 1 2 3 4 5 6 7
而我有个类,这个类有个字段叫ID,我要把这个类存放在以上8个位置之一,如果不用hashcode而任意存放,那么当查找时就需要到这八个位置里挨个去找,或者用二分法一类的算法。
但如果用hashcode那就会使效率提高很多。
我们这个类中有个字段叫ID,那么我们就定义我们的hashcode为ID%8,然后把我们的类存放在取得得余数那个位置。比如我们的ID为9,9除8的余数为1,那么我们就把该类存在1这个位置,如果ID是13,求得的余数是5,那么我们就把该类放在5这个位置。这样,以后在查找该类时就可以通过ID除 8求余数直接找到存放的位置了。
2.但是如果两个类有相同的hashcode怎么办那(我们假设上面的类的ID不是唯一的),例如9除以8和17除以8的余数都是1,那么这是不是合法的,回答是:可以这样。那么如何判断呢?在这个时候就需要定义 equals了。
也就是说,我们先通过 hashcode来判断两个类是否存放某个桶里,但这个桶里可能有很多类,那么我们就需要再通过 equals 来在这个桶里找到我们要的类。
那么。重写了equals(),为什么还要重写hashCode()呢?
想想,你要在一个桶里找东西,你必须先要找到这个桶啊,你不通过重写hashcode()来找到当Set接收一个元素时根据该对象的信息算出hashCode,看它属于哪一个区间,在这个区间里调用equeals方法。
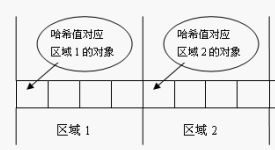
确实提高了效率。但一个面临问题:若两个对象equals相等,但不在一个区间,根本没有机会进行比较,会被认为是不同的对象。所以Java对于eqauls方法和hashCode方法是这样规定的:
1 如果两个对象相同,那么它们的hashCode值一定要相同。也告诉我们重写equals方法,一定要重写hashCode方法。
2 如果两个对象的hashCode相同,它们并不一定相同,这里的对象相同指的是用eqauls方法比较。
三、hashCode方法的分析
哈希表这个数据结构想必大多数人都不陌生,而且在很多地方都会利用到hash表来提高查找效率。在Java的Object类中有一个方法:
public native int hashCode();为何Object类需要这样一个方法?它有什么作用呢?今天我们就来具体探讨一下hashCode方法。根据这个方法的声明可知,该方法返回一个int类型的数值,并且是本地方法,因此在Object类中并没有给出具体的实现。
对于包含容器类型的程序设计语言来说,基本上都会涉及到hashCode。在Java中也一样,hashCode方法的主要作用是为了配合基于散列的集合一起正常运行,这样的散列集合包括HashSet、HashMap以及HashTable。
为什么这么说呢?考虑一种情况,当向集合中插入对象时,如何判别在集合中是否已经存在该对象了?(注意:集合中不允许重复的元素存在)
也许大多数人都会想到调用equals方法来逐个进行比较,这个方法确实可行。但是如果集合中已经存在一万条数据或者更多的数据,如果采用equals方法去逐一比较,效率必然是一个问题。此时hashCode方法的作用就体现出来了,当集合要添加新的对象时,先调用这个对象的hashCode方法,得到对应的hashcode值,实际上在HashMap的具体实现中会用一个table保存已经存进去的对象的hashcode值,如果table中没有该hashcode值,它就可以直接存进去,不用再进行任何比较了;如果存在该hashcode值, 就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址,所以这里存在一个冲突解决的问题,这样一来实际调用equals方法的次数就大大降低了,说通俗一点:Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为散列值。下面这段代码是java.util.HashMap的中put方法的具体实现:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
public V put(K key, V value) { if (key == null) return putForNullKey(value); int hash = hash(key.hashCode()); int i = indexFor(hash, table.length); for (Entry Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } }
modCount++; addEntry(hash, key, value, i); return null; } |
put方法是用来向HashMap中添加新的元素,从put方法的具体实现可知,会先调用hashCode方法得到该元素的hashCode值,然后查看table中是否存在该hashCode值,如果存在则调用equals方法重新确定是否存在该元素,如果存在,则更新value值,否则将新的元素添加到HashMap中。从这里可以看出,hashCode方法的存在是为了减少equals方法的调用次数,从而提高程序效率。
因此有人会说,可以直接根据hashcode值判断两个对象是否相等吗?肯定是不可以的,因为不同的对象可能会生成相同的hashcode值。虽然不能根据hashcode值判断两个对象是否相等,但是可以直接根据hashcode值判断两个对象不等,如果两个对象的hashcode值不等,则必定是两个不同的对象。如果要判断两个对象是否真正相等,必须通过equals方法。
也就是说对于两个对象,如果调用equals方法得到的结果为true,则两个对象的hashcode值必定相等;
如果equals方法得到的结果为false,则两个对象的hashcode值不一定不同;
如果两个对象的hashcode值不等,则equals方法得到的结果必定为false;
如果两个对象的hashcode值相等,则equals方法得到的结果未知。
四、覆写equals时总要覆盖HashCode
如果不覆盖会怎么样,这样就违反了第二条规定,相等的对象必须具有相等的散列码
如果不写,即使是相等的对象,返回的就是两个不同的散列码
public class Person {
private String name;
private Integer age;
public Person(Stringname, Integerage) {
super();
this.name =name;
this.age =age;
}
@Override
public boolean equals(Objectobj) {
if (this ==obj)
return true;
if (obj ==null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age ==null) {
if (other.age !=null)
return false;
} else if (!age.equals(other.age))
return false;
if (name ==null) {
if (other.name !=null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
public static void main(String[]args) {
Person p=new Person("汤高",20);
Person p1=new Person("汤高",20);
Map
m.put(p,"student");
System.out.println(p1.hashCode()==p.hashCode());
System.out.println("我要得到刚刚的对象");
m.put(p1,"student");
System.out.println(m.get(p1));
System.out.println(m.size());
}
}
结果:
false
我要得到刚刚的对象
Null
2
虽然通过重写equals方法使得逻辑上姓名和年龄相同的两个对象被判定为相等的对象(跟String类类似),但是要知道默认情况下,hashCode方法是将对象的存储地址进行映射。那么上述代码的输出结果为“null”就不足为奇了。原因很简单,p指向的对象和P1指向的对象是两个对象,它们的存储地址肯定不同。下面是HashMap的get方法的具体实现:
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
所以在hashmap进行get操作时,因为得到的hashcdoe值不同(注意,上述代码也许在某些情况下会得到相同的hashcode值,不过这种概率比较小,因为虽然两个对象的存储地址不同也有可能得到相同的hashcode值),所以导致直接返回null。
看看重写了hashcode方法的结果
加入hashcode方法
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((age ==null) ? 0 :age.hashCode());
result = prime * result + ((name ==null) ? 0 :name.hashCode());
return result;
}
结果:
true
我要得到刚刚的对象
Student
1
实际上,由 Object 类定义的 hashCode 方法确实会针对不同的对象返回不同的整数。(这一般是通过将该对象的内部地址转换成一个整数来实现的,)
当equals方法被重写时,通常有必要重写 hashCode 方法,以维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码。
参考
http://www.cnblogs.com/dolphin0520/p/3681042.html
http://blog.csdn.net/fenglibing/article/details/8905007
http://blog.csdn.net/woshixuye/article/details/8189398