内容简述:
一:Bs4
二:jsonpath
三:selenium库
一:bs4(BeautifulSoup)
1-bs4解析器
概述:
和lxml相同点:是html和xml解析器,主要功能也是解析和提取数据。
不同点:bs4效率没有lxml的效率高,但其API接口灵活好用
官方文档: http://beautifulsoup.readthedocs.io/zh_CN/v4.4.0
安装:pip install bs4
工具对比:

使用:
from bs4 import BeautifulSoup
A-网上文件生成对象
soup = BeautifulSoup('网上下载的字符串', 'lxml')
B-本地文件生成对象
soup =BeautifulSoup(open('bs4_test.html'), 'lxml')
2-bs4解析器规则:
按标签名查找
soup.a soup.title 注意:只能找到第一个
节点属性
name:获取标签名的 attrs: 将属性作为一个字典返回
获取节点属性值(3种方式)
obj.attrs.get('title') obj.get('title') obj['title']
获取节点内容 obj.string obj.get_text()
【温馨提示】
` a-如果内容中有注释,string会获取到注释的值,
get_text()获取不到注释内容,但可以获取非注释内容
b-如果内容中有标签,string返回None,get_text()返回文本内容。
判断获取的内容是不是注释的内容
if type(obj.string) ==bs4.element.Comment:
获取【直接子】节点
contents 返回的是一个列表 【注】中间有换行符
获取【子孙】节点
descendants 返回的是一个生成器 通过for in进行迭代即可
3-bs4解析器-方法
find(返回的是一个对象)
find('a') 返回第一个a标签
find('a', title='名字') find('a',class_='名字')
find_all(返回的是一个列表)
find_all('a') 查找到所有的a
find_all(['a', 'span']) 返回所有的a和span
find_all('a', limit=2) 只找前两个a
select(根据选择器得到节点对象)
【温馨提示】返回一个列表,列表中都是对象,需要进行筛选
选择器:
标签选择器 标签名:
类选择器 .类名
id选择器 #id名
层级选择器 标签名 .类名 #id名 .类名
标签名 > .类名 > #id名
【温馨提示】中间是空格,返回子类或者子孙类;中间是>返回直接子类
属性选择器 input[type="text"]
radio checkbox submit password select option
4-bs4解析器示例: 糗事百科-简单获取(一条数据)
5-bs4前程无忧批量爬取:
二:jsonpath(了解)
JsonPath是一种信息抽取类库,是从JSON文档中抽取指定信息的工具。
提供多种语言实现版本,包括:Javascript,Python,PHP 和 Java。
JsonPath 对于 JSON 来说,相当于 XPATH 对于 XML和HTML
简单来讲:解析json字符串,抽取需要的内容。
pip安装:pip install jsonpath
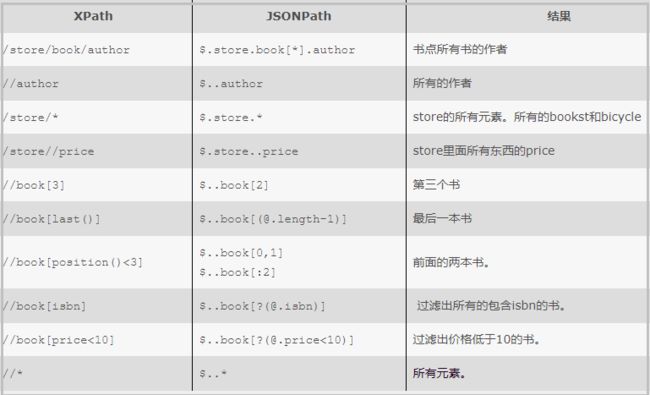
JsonPath对比XPATH:

BookStore.json文件如下
{"store": {"book": [ {"category":"reference","author":"Nigel Rees","title":"Sayings of the Century","price": 8.95 }, {"category":"fiction","author":"Evelyn Waugh","title":"Sword of Honour","price": 12.99 }, {"category":"fiction","author":"Herman Melville","title":"Moby Dick","isbn":"0-553-21311-3","price": 8.99 }, {"category":"fiction","author":"J. R. R. Tolkien","title":"The Lord of the Rings","isbn":"0-395-19395-8","price": 22.99 } ],"bicycle": {"color":"red","price": 19.95 } }}
json.loads(): json字符串 ==> python对象
json.dumps(): python对象==> json字符串
json.load():读取json格式的文本,转化为python对象
json.dump():将python对象写入到文本中
三:selenium库-自动化测试工具
Selenium是一个Web的自动化测试工具, 可根据我们的指令让浏览器自动加载
页面,获取需要的数据,包括页面截屏及判断网站上某些动作是否发生等等。
自己不带浏览器通常和第三方浏览器结合使用
安装:pip3 install selenium
官方文档:http://selenium-python.readthedocs.io/index.html
WebDriver:属于SeleniumAPI,可以像 BeautifulSoup一样用来查找页面元素
与页面上的元素进行交互 (发送文本、点击等),以及执行其他动作来运行网络爬虫。
通过selenium操作谷歌浏览器:
下载操作谷歌浏览器驱动的页面
http://chromedriver.storage.googleapis.com/index.html
谷歌驱动和谷歌浏览器版本之间的映射表
http://blog.csdn.net/huilan_same/article/details/51896672
常见选择方法:
browser.find_element_by_id()
browser.find_elements_by_name()
browser.find_elements_by_xpath()
browser.find_elements_by_tag_name()
browser.find_elements_by_css_selector()
browser.find_elements_by_link_text()
browser.find_elements_by_class_name()
四:作业
1-完成课堂代码
2-使用selenium打开百度==hao123==>点击==》后退==》再百度帅哥==》
图片==》前进==》后退==》退出
3-分别使用xpath和bs4批量下载糗事百科糗图里面的内容