Spark Core源码精读计划7 | Spark执行环境的初始化
推荐阅读
《Spark源码精度计划 | SparkConf》
《Spark Core源码精读计划 | SparkContext组件初始化》
《Spark Core源码精读计划3 | SparkContext辅助属性及后初始化》
《Spark Core源码精读计划4 | SparkContext提供的其他功能》
《Spark Core源码精读计划5 | 事件总线及ListenerBus》
《Spark Core源码精读计划6 | AsyncEventQueue与LiveListenerBus》
目录
前言
SparkEnv的入口
SparkEnv初始化的组件
SecurityManager
RpcEnv
SerializerManager
BroadcastManager
MapOutputTracker
ShuffleManager
MemoryManager
BlockManager
MetricsSystem
OutputCommitCoordinator
SparkEnv的创建与保存
总结
前言
继事件总线之后,SparkContext第二个初始化的主要组件是SparkEnv,即Spark执行环境。Driver和Executor的正常运行都依赖SparkEnv提供的环境作为支持。SparkEnv初始化成功之后,与Spark存储、计算、监控等相关的底层功能才会真正准备好,可见它几乎与SparkContext同等重要。
SparkEnv内部也包含了很多种组件,比起SparkContext的组件会稍微接地气一点。我们采用与研究SparkContext近似的方式来研究它。
SparkEnv的入口
在文章#2的代码#2.5~#2.6中,我们已经得知Driver执行环境是通过调用SparkEnv.createDriverEnv()方法来创建的,这个方法位于SparkEnv类的伴生对象中。同理,也有createExecutorEnv()方法。我们从这两个方法入手来看一下代码。
代码#7.1 - o.a.s.SparkEnv.createDriverEnv()与createExecutorEnv()方法
private[spark] def createDriverEnv(
conf: SparkConf,
isLocal: Boolean,
listenerBus: LiveListenerBus,
numCores: Int,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv = {
assert(conf.contains(DRIVER_HOST_ADDRESS),
s"${DRIVER_HOST_ADDRESS.key} is not set on the driver!")
assert(conf.contains("spark.driver.port"), "spark.driver.port is not set on the driver!")
val bindAddress = conf.get(DRIVER_BIND_ADDRESS)
val advertiseAddress = conf.get(DRIVER_HOST_ADDRESS)
val port = conf.get("spark.driver.port").toInt
val ioEncryptionKey = if (conf.get(IO_ENCRYPTION_ENABLED)) {
Some(CryptoStreamUtils.createKey(conf))
} else {
None
}
create(
conf,
SparkContext.DRIVER_IDENTIFIER,
bindAddress,
advertiseAddress,
Option(port),
isLocal,
numCores,
ioEncryptionKey,
listenerBus = listenerBus,
mockOutputCommitCoordinator = mockOutputCommitCoordinator
)
}
private[spark] def createExecutorEnv(
conf: SparkConf,
executorId: String,
hostname: String,
numCores: Int,
ioEncryptionKey: Option[Array[Byte]],
isLocal: Boolean): SparkEnv = {
val env = create(
conf,
executorId,
hostname,
hostname,
None,
isLocal,
numCores,
ioEncryptionKey
)
SparkEnv.set(env)
env
}可见,它们都是调用伴生对象内的create()方法来创建SparkEnv的。这个方法很长,所以先来看一看它的声明。
代码#7.2 - o.a.s.SparkEnv.create()方法的声明
private def create(
conf: SparkConf,
executorId: String,
bindAddress: String,
advertiseAddress: String,
port: Option[Int],
isLocal: Boolean,
numUsableCores: Int,
ioEncryptionKey: Option[Array[Byte]],
listenerBus: LiveListenerBus = null,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv = { /*...*/ }其中有几个参数需要说明一下。
executorId:Executor的唯一标识。如果是Driver的话,值就是字符串"driver"。
bindAddress/advertiseAddress:分别是监听Socket绑定的地址,与RPC端点的地址。
isLocal:是否为本地模式。
numUsableCores:分配给Driver或Executor的CPU核心数。
ioEncryptionKey:I/O加密的密钥,当spark.io.encryption.enabled配置项启用时才有效。
SparkEnv初始化的组件
我们按照create()方法中的代码顺序,对SparkEnv内涉及到的组件做简要介绍。
SecurityManager
SecurityManager即安全管理器。它负责通过共享密钥的方式进行认证,以及基于ACL(Access Control List,访问控制列表)管理Spark内部的账号和权限。其初始化代码如下。
代码#7.3 - create()方法中SecurityManager的初始化
val securityManager = new SecurityManager(conf, ioEncryptionKey)
if (isDriver) {
securityManager.initializeAuth()
}
ioEncryptionKey.foreach { _ =>
if (!securityManager.isEncryptionEnabled()) {
logWarning("I/O encryption enabled without RPC encryption: keys will be visible on the " +
"wire.")
}
}RpcEnv
RpcEnv即RPC环境。在前面已经讲过,Spark的各个实体间必然会涉及大量的网络通信,这些通信实体在Spark的RPC体系中会抽象为RPC端点(RpcEndpoint)及其引用(RpcEndpointRef)。RpcEnv为RPC端点提供处理消息的环境,并负责RPC端点的注册,端点之间消息的路由,以及端点的销毁等。RPC环境的初始化代码如下。
代码#7.4 - create()方法中RpcEnv的初始化
val systemName = if (isDriver) driverSystemName else executorSystemName
val rpcEnv = RpcEnv.create(systemName, bindAddress, advertiseAddress, port.getOrElse(-1), conf,
securityManager, numUsableCores, !isDriver)
if (isDriver) {
conf.set("spark.driver.port", rpcEnv.address.port.toString)
}代码#7.5 - o.a.s.rpc.RpcEnv.create()方法
def create(
name: String,
bindAddress: String,
advertiseAddress: String,
port: Int,
conf: SparkConf,
securityManager: SecurityManager,
numUsableCores: Int,
clientMode: Boolean): RpcEnv = {
val config = RpcEnvConfig(conf, name, bindAddress, advertiseAddress, port, securityManager,
numUsableCores, clientMode)
new NettyRpcEnvFactory().create(config)
}Spark的RPC底层是利用Netty实现的,NettyRpcEnv目前也是RpcEnv唯一的实现类。RPC的内部细节很多,之后会用多篇文章来详细分析。
SerializerManager
SerializerManager即序列化管理器。在Spark存储或交换数据时,往往先需要将数据序列化或反序列化,为了节省空间可能还要对数据进行压缩,SerializerManager就是负责这些工作的组件。其初始化代码如下。
代码#7.6 - create()方法中SerializerManager的初始化
val serializer = instantiateClassFromConf[Serializer](
"spark.serializer", "org.apache.spark.serializer.JavaSerializer")
logDebug(s"Using serializer: ${serializer.getClass}")
val serializerManager = new SerializerManager(serializer, conf, ioEncryptionKey)
val closureSerializer = new JavaSerializer(conf)
instantiateClassFromConf()方法是create()方法内定义的,它调用了工具类Utils的classForName()方法,通过反射创建类的实例。序列化器的类型可以用SparkConf配置项spark.serializer指定,其默认值是org.apache.spark.serializer.JavaSerializer。我们在日常开发中常用的还有KryoSerializer。
序列化器有两个,serializer是数据的序列化器,closureSerializer则是闭包的序列化器。后者在调度逻辑(如DAGScheduler、TaskSetManager)中经常用到,其类型固定为JavaSerializer,不能修改。
BroadcastManager
BroadcastManager即广播管理器,它在前面的代码#4.3中已经出现过。它除了为用户提供广播共享数据的功能之外,在Spark Core内部也有广泛的应用,如共享通用配置项或通用数据结构等等。其初始化代码只有一句,不再贴了。
MapOutputTracker
MapOutputTracker即Map输出跟踪器。在Shuffle过程中,Map任务通过Shuffle Write阶段产生了中间数据,Reduce任务进行Shuffle Read时需要知道哪些数据位于哪个节点上,以及Map输出的状态等信息。MapOutputTracker就负责维护这些信息,其初始化代码如下。
代码#7.7 - create()方法中MapOutputTracker的初始化
val mapOutputTracker = if (isDriver) {
new MapOutputTrackerMaster(conf, broadcastManager, isLocal)
} else {
new MapOutputTrackerWorker(conf)
}
mapOutputTracker.trackerEndpoint = registerOrLookupEndpoint(MapOutputTracker.ENDPOINT_NAME,
new MapOutputTrackerMasterEndpoint(
rpcEnv, mapOutputTracker.asInstanceOf[MapOutputTrackerMaster], conf))可见是按照当前实体是Driver或Executor分为两种情况处理的。创建完MapOutputTracker实例之后,还会调用registerOrLookupEndpoint()方法,注册(Driver情况)或查找(Executor情况)对应的RPC端点,并返回其引用。
ShuffleManager
ShuffleManager即Shuffle管理器。顾名思义,它负责管理Shuffle阶段的机制,并提供Shuffle方法的具体实现。其初始化代码如下。
代码#7.8 - create()方法中ShuffleManager的初始化
val shortShuffleMgrNames = Map(
"sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName,
"tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName)
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
val shuffleMgrClass =
shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase(Locale.ROOT), shuffleMgrName)
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)ShuffleManager的种类可以通过配置项spark.shuffle.manager设置,默认为sort,即SortShuffleManager。取得对应的ShuffleManager类名之后,通过反射构建其实例。Shuffle是Spark计算过程中非常重要的一环,之后会深入地研究它。
MemoryManager
MemoryManager即内存管理器。顾名思义,它负责Spark集群节点内存的分配、利用和回收。Spark作为一个内存优先的大数据处理框架,内存管理机制是非常精细的,主要涉及存储和执行两大方面。其初始化代码如下。
代码#7.9 - create()方法中MemoryManager的初始化
val useLegacyMemoryManager = conf.getBoolean("spark.memory.useLegacyMode", false)
val memoryManager: MemoryManager =
if (useLegacyMemoryManager) {
new StaticMemoryManager(conf, numUsableCores)
} else {
UnifiedMemoryManager(conf, numUsableCores)
}MemoryManager有两种实现,可以使用spark.memory.useLegacyMode配置项控制使用哪种。旧版的内存管理器是StaticMemoryManager,即静态内存管理器。新版(1.6.0版本之后)的内存管理器是UnifiedMemoryManager,即统一内存管理器,它也是当前的默认实现,相对于静态内存管理而言也更为先进。在之后讲解涉及存储和计算方面的细节时,会一同探究MemoryManager的具体实现。
BlockManager
BlockManager即块管理器。块作为Spark内部数据的基本单位,与操作系统中的“块”和HDFS中的“块”都不太相同。它可以存在于堆内内存,也可以存在于堆外内存和外存(磁盘)中,是Spark数据的通用表示方式。BlockManager就负责管理块的存储、读写流程和状态信息,其初始化代码如下。
代码#7.10 - create()方法中BlockManager的初始化
val blockTransferService =
new NettyBlockTransferService(conf, securityManager, bindAddress, advertiseAddress,
blockManagerPort, numUsableCores)
val blockManagerMaster = new BlockManagerMaster(registerOrLookupEndpoint(
BlockManagerMaster.DRIVER_ENDPOINT_NAME,
new BlockManagerMasterEndpoint(rpcEnv, isLocal, conf, listenerBus)),
conf, isDriver)
val blockManager = new BlockManager(executorId, rpcEnv, blockManagerMaster,
serializerManager, conf, memoryManager, mapOutputTracker, shuffleManager,
blockTransferService, securityManager, numUsableCores)在初始化BlockManager之前,还需要先初始化块传输服务BlockTransferService,以及BlockManager的主节点BlockManagerMaster。BlockManager也是采用主从结构设计的,Driver上存在主RPC端点BlockManagerMasterEndpoint,而各个Executor上都存在从RPC端点BlockManagerSlaveEndpoint。
BlockManager是整个Spark存储子系统的基石,之后会先于上面的MemoryManager做介绍。
MetricsSystem
MetricsSystem即度量系统。它是Spark监控体系的后端部分,负责收集与输出度量(也就是各类监控指标)数据。度量系统由系统实例Instance、度量数据源Source、度量输出目的地Sink三部分组成。其在SparkEnv里的初始化代码如下。
代码7.11 - create()方法中MetricsSystem的初始化
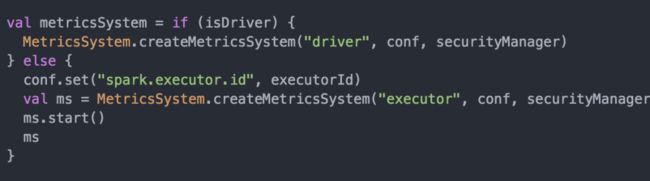
这里也是分两种情况处理的。在Driver端初始化MetricsSystem时,需要依赖TaskScheduler初始化完毕后生成的Application ID,故不会马上启动它,可以参见代码#2.7。在Executor端初始化时就不用等待,因为Executor ID已经存在了。
OutputCommitCoordinator
OutputCommitCoordinator即输出提交协调器。如果需要将Spark作业的结果数据持久化到外部存储(最常见的就是HDFS),就需要用到它来判定作业的每个Stage是否有权限提交。其初始化代码如下。
代码#7.12 - create()方法中OutputCommitCoordinator的初始化
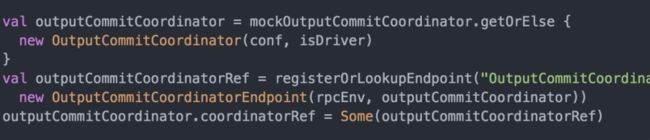
可见,在Driver上还注册了其RPC端点OutputCommitCoordinatorEndpoint,各个Executor会通过其引用来访问它。
SparkEnv的创建与保存
在create()方法的最后,会构建SparkEnv类的实例,创建Driver端的临时文件夹,并返回该实例。
代码#7.13 - SparkEnv.create()方法的结尾
val envInstance = new SparkEnv(
executorId,
rpcEnv,
serializer,
closureSerializer,
serializerManager,
mapOutputTracker,
shuffleManager,
broadcastManager,
blockManager,
securityManager,
metricsSystem,
memoryManager,
outputCommitCoordinator,
conf)
if (isDriver) {
val sparkFilesDir = Utils.createTempDir(Utils.getLocalDir(conf), "userFiles").getAbsolutePath
envInstance.driverTmpDir = Some(sparkFilesDir)
}
envInstanceSparkEnv的全部初始化流程都在伴生对象中,其类中反而没有太多东西,主要是控制SparkEnv停止的相关逻辑,不再赘述。
如同SparkContext一样,SparkEnv在伴生对象中也会将已创建的实例保存起来,避免重复创建,也保证在同一节点上执行环境的一致性。get()与set()方法的代码非常简单,就不贴出来了。
总结
本文从SparkEnv的初始化方法入手,按顺序简述了十余个与Spark执行环境相关的内部组件及其初始化逻辑。这些组件与Spark框架的具体执行流程息息相关,我们之后也会深入研究其中的一部分,特别重要的如RPC环境RpcEnv、Shuffle管理器ShuffleManager、内存管理器MemoryManager、块管理器BlockManager等。
最后仍然用一张简图来概括。

图#7.1 - SparkEnv初始化顺序
下一篇文章计划研究RPC环境。它比前面讲过的事件总线更加底层,因此也有更多的细节等着我们去探索。
