
在VR开发中,除了图形视觉渲染,音频处理是重要的一环,好的音频处理可以欺骗用户的听觉,达到身临其境的效果,本文主要介绍WebVR音频是如何开发的。
VR Audio
VR音频的输出硬件主要是耳机,根据音频源与场景之间的关系,可将VR音频分为两类:静态音频和空间化音频(audio spatialization)。
静态音频
这类音频作用于整个VR场景,可简单的理解成背景音乐,音频输出是静态的,比如微风雨滴声、闹市声等充斥整个场景的背景音效。
对于环境音效的开发,我们可以简单的使用
空间化音频
音频作用在空间的实体上,具有发声体和听者的位置关系,音频输出会根据发声体与用户的距离、方向动态变化,它模拟了现实中声音的传播方式,具有空间感。
实现原理:在虚拟场景中,通过调节音频的振幅来描述发声体与听者之间的距离,再通过调节左右通道(audio channel)之间的差异,控制左右耳机喇叭输出,来描述发声体相对听者的方位。
- 从发声体与用户两点间的距离来看,如距离越远,音频音量(振幅)应越小;
- 从发声体与用户的方向来看,如发声体位于听者左侧,则音频输出的左声道应比右声道音量大。

形如音频空间化此类稍复杂的音频的处理,可通过Web Audio API来实现。
Web Audio API 简介
Web Audio API提供了一个功能强大的音频处理系统,允许我们在浏览器中通过js来实时控制处理音频,比如音频可视化、音频混合等。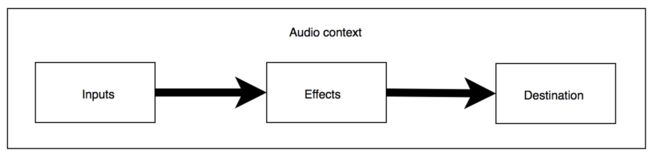
Web Audio处理流程可以比喻成一个加工厂对声源的加工,这个加工厂由多个加工模块AudioNode连接而成,音频源经过一系列的处理加工后,被输送至扬声器。
AudioContext
类似于canvas的context上下文环境,它代表了一个audio加工厂控制中心,负责各个audioNode的创建和组合,通过new AudioContext()的方式创建。
AudioNode
AudioNode音频节点,则是加工厂的加工模块, 按照功能可分为三类:输入结点、处理结点、输出结点。每个结点都拥有connect方法连接下一个节点,将音频输出到下一个模块。
- 输入结点主要负责加载解码音频源,比如获取二进制音频源的
BufferSourceNode、获取 - 处理结点主要对音频数据进行计算处理,比如处理音频振幅的
GainNode等; - 输出结点则将音频输出至扬声器或耳机,
AudioContext.destination便是默认的输出节点。
一个简单的音频处理流程只需要分为四步:
- 创建音频上下文
- 创建并初始化输入结点、处理结点
- 将输入结点、处理结点、输出结点进行有连接
- 动态修改结点属性以输出不同音效
参考以下代码:
const myAudio = document.querySelector('audio');
const audioCtx = new AudioContext(); // 创建音频上下文
// 创建输入结点,解码audio标签的音频源;创建处理结点,处理音频
const source = audioCtx.createMediaElementSource(myAudio);
const gainNode = audioCtx.createGain(); // 创建GainNode结点控制音频振幅
// 将输入结点、处理结点、输出结点两两相连
source.connect(gainNode); // 将输入结点连接到gainNode处理结点
gainNode.connect(audioCtx.destination); // 将gainNode连接到destination输出节点
// 通过动态改变结点属性产生不同音效
source.start(0); // 播放音频
gainNode.gain.value = val; // 设置音量理解了Web Audio的开发流程,接下来看看如何在WebVR中实现Audio Spatialization,这里VR场景使用three.js进行开发。
实现空间化音频
Audio Spatialization的实现主要通过AudioListener和PannerNode结点配合,这两个对象可以根据空间方位信息动态处理音频源,并输出左右声道。
-
AudioListener对象代表三维空间中的听者(用户),通过AudioContext.listener属性获取; -
PannerNode对象指的是三维空间中的发声体,通过AudioContext.createPanner()创建。
我们需要初始化这两个对象,并将空间方位信息作为入参动态传给它们。
设置PannerNode
const myAudio = document.querySelector('audio');
const audioCtx = new AudioContext(); // 创建音频上下文
const source = audioCtx.createMediaElementSource(myAudio);
const panner = audioCtx.createPannerNode();
panner.setPosition(speaker.position.x, speaker.position.y, speaker.position.z); // 将发声体坐标传给PannerNode
source.connect(panner); // 将输入结点连接到PannerNode处理结点
panner.connect(audioCtx.destination);
source.start(0); // 播放音频设置AudioListener
VR用户头显最多有6-Dof:position位置3-Dof系统和orientation方向3-Dof系统,我们需要将这6-Dof的信息传入AudioListener,由它为我们处理音频数据。
对于用户位置数据,AudioListener提供了三个位置属性:positionX,positionY,positionZ,它分别代表听者当前位置的xyz坐标,我们可将用户在场景中的位置(一般用camera的position)赋值给这三个属性。
// 为listener设置position
const listener = audioCtx.listener;
listener.positionX = camera.position.x;
listener.positionY = camera.position.y;
listener.positionZ = camera.position.z;除了传入用户的位置,我们还需要将用户的视角方向信息传给AudioListener,具体是给AudioListener的Forward向量三个分量forwardX,forwardY,forwardZ和Up向量三个分量upX,upY,upZ赋值。
- Forward向量沿着鼻子方向指向前,默认是(0,0,-1);
- Up向量沿着头顶方向指向上,默认是(0,1,0)。

- 在VR场景中,当用户转动头部改变视角时,up向量或forward向量会随之改变,但两者始终垂直。
Up向量 = Camera.旋转矩阵 × [0,1,0]
Forward向量 = Camera.旋转矩阵 × [0,0,-1]
参照上方公式,这里的camera是three.js的camera,指代用户的头部,通过camera.quaternion获取相机的旋转(四元数)矩阵,与初始向量相乘,得到当前Up向量和Forward向量,代码如下:
// 计算当前listener的forward向量
let forward = new THREE.Vector3(0,0,-1);
forward.applyQuaternion(camera.quaternion); // forward初始向量与camera四元数矩阵相乘,得到当前的forward向量
forward.normalize(); // 向量归一
// 赋值给AudioListener的forward分量
listener.forwardX.value = forward.x;
listener.forwardY.value = forward.y;
listener.forwardZ.value = forward.z;
// 计算当前listener的up向量
let up = new THREE.Vector3(0,1,0);
up.applyQuaternion(camera.quaternion); // up初始向量与camera四元数矩阵相乘,得到当前的up向量
up.normalize(); // 向量归一
// 赋值给AudioListener的up分量
listener.upX.value = up.x;
listener.upY.value = up.y;
listener.upZ.value = up.z;WebVR实现音频角色
在VR场景中,根据音频的发起方和接收方可以分为两个角色:Speaker发声体与Listener听者,即用户。
一个VR场景音频角色由一个Listener和多个Speaker组成,于是笔者将PannerNode和AudioListener进行独立封装,整合为Speaker类和Listener对象。
PS:这里沿用前几期three.js开发WebVR的方式,可参考《WebVR开发——标准教程》
Speaker实现
Speaker类代表发声体,主要做了以下事情:
- 初始化阶段加载解析音频源,创建并连接输入结点、处理结点、输出结点
- 提供
update公用方法,在每一帧中更新PannerNode位置。
class Speaker {
constructor(ctx,path) {
this.path = path;
this.ctx = ctx;
this.source = ctx.createBufferSource();
this.panner = ctx.createPanner();
this.source.loop = true; // 设置音频循环播放
this.source.connect(this.panner); // 将输入结点连至PannerNode
this.panner.connect(ctx.destination); // 将PannerNode连至输出结点
this._processAudio(); // 异步函数,请求与加载音频数据
}
update(position) {
const { panner } = this;
panner.setPosition(position.x, position.y, position.z); // 将发声体坐标传给PannerNode
}
_loadAudio(path) {
// 使用fetch请求音频文件
return fetch(path).then(res => res.arrayBuffer());
}
async _processAudio() {
const { path, ctx, source } = this;
try {
const data = await this._loadAudio(path); // 异步请求音频
const buffer = await ctx.decodeAudioData(data); // 解码音频数据
source.buffer = buffer; // 将解码数据赋值给BufferSourceNode输入结点
source.start(0); // 播放音频
} catch(err) {
console.err(err);
}
}
}这里初始化的流程跟前面略有不同,这里使用的是fetch请求音频文件,通过BufferSourceNode输入结点解析音频数据。update方法传入发声体position,设置PannerNode位置。
Listener实现
Listener对象代表听者,提供update公用方法,在每帧中传入AudioListener的位置和方向。
// 创建Listener对象
const Listener = {
init(ctx) {
this.ctx = ctx;
this.listener = this.ctx.listener;
},
update(position,quaternion) {
const { listener } = this;
listener.positionX = position.x;
listener.positionY = position.y;
listener.positionZ = position.z;
// 计算当前listener的forward向量
let forward = new THREE.Vector3(0,0,-1);
forward.applyQuaternion(quaternion);
forward.normalize();
listener.forwardX.value = forward.x;
listener.forwardY.value = forward.y;
listener.forwardZ.value = forward.z;
// 计算当前listener的up向量
let up = new THREE.Vector3(0,1,0);
up.applyQuaternion(quaternion);
up.normalize();
listener.upX.value = up.x;
listener.upY.value = up.y;
listener.upZ.value = up.z;
}
}这里只是简单的将AudioListener作一层封装,update方法传入camera的position和四元数矩阵,设置AudioListener位置、方向。
接下来,将Listener和Speaker引入到WebVR应用中,下面例子描述了这样一个简陋场景:一辆狂响喇叭的汽车从你身旁经过,并驶向远方。
class WebVRApp {
...
start() {
const { scene, camera } = this;
... // 创建灯光、地面
// 创建一辆简陋小车
const geometry = new THREE.CubeGeometry(4, 3, 5);
const material = new THREE.MeshLambertMaterial({ color: 0xef6500 });
this.car = new THREE.Mesh(geometry, material);
this.car.position.set(-12, 2, -100);
scene.add(this.car);
const ctx = new AudioContext(); // 创建AudioContext上下文
Listener.init(ctx); // 初始化listener
this.car_speaker = new Speaker(ctx,'audio/horn.wav'); // 创建speaker,传入上下文和音频路径
}
}首先在start方法创建小汽车,接着初始化Listener并创建一个Speaker。
class WebVRApp {
...
update() {
const { scene, camera, renderer} = this;
// 启动渲染
this.car.position.z += 0.4;
this.car_speaker.update(this.car.position); // 更新speaker位置
Listener.update(camera.position, camera.quaternion); // 更新Listener位置以及头部朝向
renderer.render(scene, camera);
}
}
new WebVRApp();在动画渲染update方法中,更新小汽车的位置,并调用Speaker和Listener的update方法,传入小汽车的位置、用户的位置和旋转矩阵,更新音频空间信息。
示例地址:https://yonechen.github.io/We...(需要支持es7的浏览器如新版chrome,太懒没做打包编译?)
源码地址:https://github.com/YoneChen/W...
小结
本文主要讲解了WebVR应用音频空间化的实现步骤,核心是运用了Web Audio API的PannerNode和AudioListener两个对象处理音频源,文末展示了VR Audio的一个简单代码例子,three.js本身也提供了完善的音频空间化支持,可以参考PositinalAudio。
最近笔者正在实现WebVR多人聊天室,下期文章围绕此展开,敬请期待~
更多文章可关注WebVR技术庄园
WebVR开发教程——交互事件(二)使用Gamepad
WebVR开发教程——深度剖析 关于WebVR的开发调试方案以及原理机制
WebVR开发教程——标准入门 使用Three.js开发WebVR场景的入门教程