深入理解HashMap(一)hashmap所用算法、构造函数
前言
大二的时候学习过hashmap的结构以及算法,但是一直都是通过使用JDK自带的hashmap,一直没有深究hashmap是如何实现的。最近重新阅读了hashmap的源码,发现hashmap的实现远比我想象的难。于是打算记录一下自己学习hashmap 的过程,如果没有学过数据结构的同学可以先去学习一下数据结构,hash的基础我就不再讲了。(本文的代码都是基于JDK8实现的)
传送门
深入理解HashMap(二)put方法解析
深入理解HashMap(三)resize方法解析
深入理解HashMap(四)get方法解析
深入理解HashMap(五)remove方法解析
1、hash算法实现
我们都知道,hashmap是先通过key算出hash值,然后对通过&操作得到对应数组的下标然后再通过链表or数组将元素插入,hashmap的结构示意图大概如下:
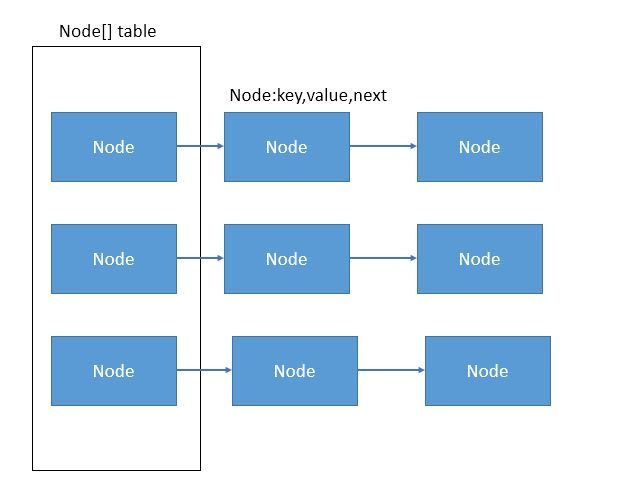
本文要讲的算法是hashmap中是如何得到hash值的,hash值的算法有许多,本文只讲hashmap的算法:链地址法。
啥叫链地址法呢?其实就是将数组和链表组合在一起,就像上图一样,table是hashmap中的数组,数组中储存了链表的头节点。
知道了结构,那么重点来了,我们如何去计算hash值,并且通过hash值去得到table中的下标呢?
首先我们应该明确的是,hash值算出的下标出现的概率应该百分之百相等,如果不相等的话就会出现table中某个下标下的链表特别长,影响查询的效率。
正好,object类中提供了hashCode()方法,通过使用hashCode()方法,我们可以获得key对应的hash值。那我们直接拿这里的hash值去做&运算不就得到对应的下标了吗?其实不然,因为table的长度都是2的幂,因此index仅与hash值的低n位有关,hash值的高位都被与操作置为0了,那么hash的高位的存在就等于毫无意义,这显然不是公平的算法。
n = table.length;
index = (n-1) & hash;
那么在hashmap中,是如何得到hash值的呢?来看一下源码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这段代码是什么意思呢?将key的hashcode与key右移16位进行异或得到的才是真正的hash值?
为了更好的理解,我们来看一个例子,假设table.length=2^4=16。

由上图可以发现,在计算下标时,只有hash值的低四位参与了下标的计算。key的hashcode与key右移16位进行异或得到的hash值,结合了前16位和后16位,所以相对来说是非常公平的。仅仅异或一下,既减少了系统的开销,也不会造成的因为高位没有参与下标的计算(table长度比较小时),从而引起的碰撞。
HashMap的tableSizeFor()方法
第一次见到HashMap的tableSizeFor()时,我被这个算法给惊呆了,这个算法实在是太精妙了。那么tableSizeFor()方法是做什么用的呢?hashmap中有两个变量,分别为loadFactor、threshold,其中loadFactor的含义为负载因子,threshold的含义是阈值用于判断是否需要扩容,threshold = capacity * load factor,但是在初始化的时候,是使用tableSizeFor()方法来初始化threshold,看一下tableSizeFor方法的源码:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
先来假设n的二进制为01xxx…xxx,
对n右移1位:001xx…xxx,再与01xxx…xxx位或得:011xx…xxx
对n右移2为:00011…xxx,再与011xx…xxx位或得:01111…xxx
对n右移4为:000001111…xxx,再与01111xx…xxx位或得:011111111…xxx
当右移8位时,我想应该都知道得到什么结果了吧,
综上可得,该算法让最高位的1后面的位全变为1。
最后再让结果n+1,即得到了2的整数次幂的值了。
现在回来看看第一条语句:
int n = cap - 1;
让cap-1再赋值给n的目的是另找到的目标值大于或等于原值。例如二进制1000,十进制数值为8。如果不对它减1而直接操作,将得到答案10000,即16。显然不是结果。减1后二进制为111,再进行操作则会得到原来的数值1000,即8。
构造方法及一些常量
看完hashmap的算法,再来看一下hashmap的构造方法以及一下常量,理解起来会更容易一些,先看一下hashmap中有哪些常量:
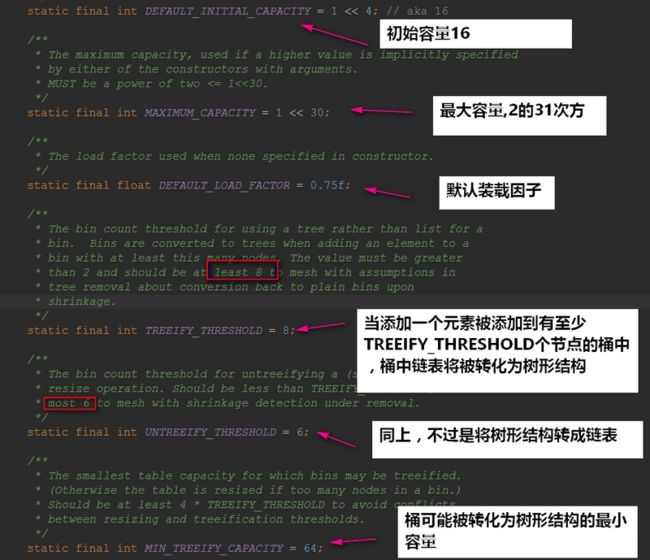
hashmap共有4种构造方法:

先看一下HashMap(int initialCapacity, float loadFactor):
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
//初始化阈值为比容量大的最接近容量的2的幂的数
this.threshold = tableSizeFor(initialCapacity);
}
其中的tableSizeFor方法我们之前已经分析过它的作用了,其他的构造方法比较简单,就不细讲了
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* Constructs an empty HashMap with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
/**
* Constructs a new HashMap with the same mappings as the
* specified Map. The HashMap is created with
* default load factor (0.75) and an initial capacity sufficient to
* hold the mappings in the specified Map.
*
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}