使用MongoShake实现MongoDB副本集间的单向同步
MongoShake介绍
MongoShake是阿里云以golang语言编写的通用平台型服务工具,它通过读取MongoDB的Oplog操作日志来复制MongoDB的数据以实现特定需求。
MongoShake还提供了日志数据的订阅和消费功能,可通过SDK、Kafka、MetaQ等方式的灵活对接,适用于日志订阅、数据中心同步、Cache异步淘汰等场景。
说明 如需了解更多MongoShake相关信息,请参见MongoDB-shake Github主页。
支持的数据源
| 源数据库 | 目标数据库 |
|---|---|
| ECS上的自建MongoDB数据库 | ECS上的自建MongoDB数据库 |
| 本地自建的MongoDB数据库 | 本地自建的MongoDB数据库 |
| 阿里云MongoDB实例 | 阿里云MongoDB实例 |
| 第三方云MongoDB数据库 | 第三方云MongoDB数据库 |
注意事项
- 在全量数据同步完成之前,请勿对源库进行DDL操作,否则可能导致数据不一致。
- 不支持同步admin和local数据库。
数据库用户的权限要求
| 同步的数据源 | 所需权限 |
|---|---|
| 源MongoDB实例 | readAnyDatabase权限、local库的read权限和mongoshake库的readWrite权限。 |
| 目标MongoDB实例 | readWriteAnyDatabase权限或目标库的readWrite权限。 |
说明 关于MongoDB数据库用户的创建及授权操作请参见使用DMS管理MongoDB数据库用户或db.createUser命令介绍。
准备工作
- 创建作为同步目标端的MongoDB副本集实例,详情请参见创建副本集实例。
说明 选择与源端的MongoDB实例相同的专有网络,便于ECS通过专有网络进行连接。
- 创建用于运行MongoShake的ECS实例,详情请参见创建ECS实例。
说明 ECS的操作系统选择为Linux,并选择与MongoDB实例相同的专有网络。
- 将ECS的IP地址加入至源端和目标端MongoDB实例的白名单中,并确保ECS可以连接源端和目标端MongoDB实例。
说明 建议通过专有网络进行互连,以获取最低的网络延迟。
操作步骤
- 登录ECS实例。
- 执行如下命令格式下载MongoShake程序。
wget 最新版MongoShake包下载地址说明 最新版本的MongoShake包下载地址请参见releases页面。
- 执行如下命令格式解压MongoShake程序。
tar xvf mongoshake包文件名 - 通过
vim命令,修改MongoShake的配置文件collector.conf,涉及的主要参数的说明如下表所示。参数目录 参数 说明 示例值 无 conf.version 当前配置文件的版本号,请不要修改该值。 conf.version = 4全局配置选项 id 同步任务的ID,可自定义。主要用于本次任务的日志名称、断点续传(checkpoint)位点信息存储的数据库名称、同步到目的端的数据库名称等。 id = mongoshakemaster_quorum 高可用选项。当主备MongoShake同时从一个源端同步数据时,主MongoShake中需要设置该参数为 ture。取值:- ture:开启
- false:关闭
说明 默认值为false。
master_quorum = falsefull_sync.http_port HTTP端口,开放该端口可通过外网查看MongoShake的当前全量同步状态。 说明 默认值为9101。
full_sync.http_port = 9101incr_sync.http_port HTTP端口,开放该端口可通过外网查看MongoShake的当前增量同步状态。 说明 默认值为9100。
incr_sync.http_port = 9100system_profile_port Profiling端口,用于查看内部堆栈信息。 system_profile_port = 9200log.level 日志的等级,取值: - error:包含错误级别信息的日志。
- warning:包含警告级别信息的日志。
- info:反馈当前系统状态的日志。
- debug:包含调试信息的日志。
默认值:info。
log.level = infolog.dir 日志文件和pid文件的目录,不设置则默认使用当前路径的logs目录。 log.dir = ./logs/log.file 日志文件的名称,可自定义。 说明 默认值为collector.log。
log.file = collector.loglog.flush 日志在屏幕上的刷新频率。取值: - ture:打印每一条日志(对性能有影响)。
- false:不一定能打印日志,但是保证性能。
说明 默认值为false。
log.flush = falsesync_mode 数据同步的方式,取值: - all:执行全量数据同步和增量数据同步。
- full:仅执行全量数据同步。
- incr:仅执行增量数据同步。
说明 默认值为full。
sync_mode = allmongo_urls 源端MongoDB实例的ConnectionStringURI格式连接地址。说明 - 建议通过专有网络地址进行互连,以获取最低的网络延迟。
- 关于ConnectionStringURI格式详情请参见副本集实例连接说明或分片集群实例连接说明。
mongo_urls = mongodb://root:[email protected]:3717,dds-bpxxxxxxxx.mongodb.rds.aliyuncs.com:3717mongo_cs_url 如果源端的MongoDB类型为分片集群实例,需要输入ConfigServer(CS)节点的连接地址。如何申请ConfigServer节点的连接地址请参见申请Shard或ConfigServer节点连接地址。 mongo_cs_url = mongodb://root:[email protected]:3717,dds-bpxxxxxxxx-csxxx.mongodb.rds.aliyuncs.com:3717/adminmongo_s_url 如果源端的MongoDB类型为分片集群实例,需要输入至少一个Mongos节点的连接地址,多个Mongos地址之间以英文逗号(,)分隔。如何申请Mongos节点的连接地址请参见申请Shard或ConfigServer节点连接地址。 mongos_s_url = mongodb://root:[email protected]:3717,s-bpxxxxxxxx.mongodb.rds.aliyuncs.com:3717/admintunnel 同步的通道类型。取值: - Direct:直接同步到目标MongoDB实例。
- RPC:通过NET/RPC方式同步。
- TCP:通过TCP方式同步。
- File:通过文件传输方式同步。
- Kafka:通过Kafka方式同步。
- Mock:仅用于测试,不写入通道。
说明 默认值为Direct。
tunnel = Directtunnel.address 目标端的链接地址,支持如下地址: - 当turnel参数为
direct时,请输入目标端MongoDB实例的ConnectionStringURI格式连接地址。 - 当turnel参数为
rpc时,请输入目标端实例rpc的接收地址。 - 当turnel参数为
tcp时,请输入目标端实例的tcp接收地址。 - 当turnel参数为
file时,请输入目标端实例数据的文件路径。 - 当turnel参数为
kafka时,请输入kafka的地址,例如topic@brokers1,brokers2 - 当turnel参数为
mock时,此参数不填。
tunnel.address = mongodb://root:[email protected]:3717,dds-bpxxxxxxxx.mongodb.rds.aliyuncs.com:3717tunnel.message 通道数据的类型,仅限tunnel参数为 kafka或file时有效。取值:- raw:默认的类型,采用聚合的模式进行写入和读取。
- json:以
JSON格式写入kafka,便于用户直接读取。 - bson:以
BSON二进制的格式写入kafka。
说明 默认值为raw。
tunnel.message = rawmongo_connect_mode MongoDB实例的连接模式,仅限tunnel参数为 direct时有效。取值:- primary:从primary节点中拉取数据。
- secondaryPreferred:从secondary节点中拉取数据。
- standalone:从指定的单个节点中拉取数据。
说明 默认值为secondaryPreferred。
mongo_connect_mode = secondaryPreferredfilter.namespace.black 指定数据同步的黑名单,这些指定的命名空间不会被同步至目标数据库,多个命名空间用英文分号(;)分隔。 说明 命名空间是指MongoDB中集合或索引的规范名称,是由数据库名称和集合或索引名称的组合,例如
mongodbtest.customer。filter.namespace.black = mongodbtest.customer;testdata.test123filter.namespace.white 指定数据同步的白名单,只有这些指定的命名空间会被同步至目标数据库,多个命名空间用英文分号(;)分隔。 filter.namespace.white = mongodbtest.customer;test123filter.pass.special.db 启用特殊库的同步。正常同步过程中,admin、local、mongoshake、config、system.views等库会被系统过滤掉,您可以在有特殊需求时启用上述库的同步。多个库名用英文分号(;)分隔。 filter.pass.special.db = admin;mongoshakefilter.ddl_enable 是否开启DDL同步。取值: - true:开启
- false:关闭
说明 源端为MongoDB分片集群实例时不支持开启。
filter.ddl_enable = falsecheckpoint.storage.url 配置Checkpoint存储地址,用于支持断点续传。如不配置,程序将根据实例类型写入如下对应的数据库: - MongoDB副本集实例:写入mongoshake库中。
- MongoDB分片集群实例:写入ConfigServer节点的admin库中。
checkpoint.storage.url = mongodb://root:[email protected]:3717,dds-bpxxxxxxxx.mongodb.rds.aliyuncs.com:3717checkpoint.storage.db Checkpoint存储的数据库名。 说明 默认为mongoshake。
checkpoint.storage.db = mongoshakecheckpoint.storage.collection Checkpoint存储的集合名。在开启主备MongoShake同时从一个源端同步数据时,可以修改该表名以防止表名重复引起冲突。 说明 默认为ckpt_default。
checkpoint.storage.collection = ckpt_defaultcheckpoint.start_position 断点续传的开始位置,如果checkpoint位点已经存在则本参数无效。取值的格式: YYYY-MM-DDTHH:MM:SSZ。说明 默认值为1970-01-01T00:00:00Z。
checkpoint.start_position = 1970-01-01T00:00:00Ztransform.namespace 将源库的库名或集合名重新命名并同步到目的库。如:将源库中的 A库.B集合重新命名成C库.D集合并同步到目的库。transform.namespace = fromA.fromB:toC.toD全量数据同步选项 full_sync.reader.collection_parallel 设置MongoShake单次最多并发拉取多少个集合。 full_sync.reader.collection_parallel = 6full_sync.reader.write_document_parallel 设置MongoShake对单个集合写入的并发线程数。 full_sync.reader.write_document_parallel = 8full_sync.reader.document_batch_size 设置MongoShake对目的端单次写入文档的聚合(batch)大小。如:128表示单次聚合128个文档后再写入。 full_sync.reader.document_batch_size = 128full_sync.collection_exist_drop 设置目的库存在同名集合时的处理方式。取值: - true:先删除目标重名集合再同步。
警告 此操作会删除目的端的集合,请务必提前做好备份。
- false:如检测到目的库中有重名集合则直接报错退出。
full_sync.collection_exist_drop = truefull_sync.create_index 完成同步后是否创建索引。取值: - foreground:创建前台索引
- background:创建后台索引
- none:不创建索引
full_sync.create_index = nonefull_sync.executor.insert_on_dup_update 目的库中有 _id重复字段时是否将INSERT语句更改为UPDATE语句。取值:- true:更改
- false:不更改
full_sync.executor.insert_on_dup_update = falsefull_sync.executor.filter.orphan_document 源端为分片集群实例时,是否过滤孤儿文档(Orphaned document)。取值: - true:过滤
- false:不过滤
full_sync.executor.filter.orphan_document = falsefull_sync.executor.majority_enable 是否启用目的端的多数写(Majority write)功能。取值: - true:启用
- false:不启用
full_sync.executor.majority_enable = false增量数据同步选项 incr_sync.mongo_fetch_method 配置增量数据拉取方法。取值: - oplog:从源库中拉取oplog。
- change_stream:从源库中拉取change事件(仅支持MongoDB 4.0及以上版本)。
默认值:oplog
incr_sync.mongo_fetch_method = oplogincr_sync.oplog.gids 用于云上集群搭建双向复制。如有需求请提交工单申请GIDS。 incr_sync.oplog.gids = xxxxxxxxxxxxincr_sync.shard_key MongoShake内部处理并发的方式。请勿修改该参数。 incr_sync.shard_key = collectionincr_sync.worker 传输oplog的并发线程数。如果主机性能足够,可以提高线程数。 说明 如果是分片集群实例,线程数必须等同于分片(shard)数量。
incr_sync.worker = 8incr_sync.worker.oplog_compressor 启用压缩数据功能以减少网络带宽消耗。取值: - none:不压缩
- gzip:以gzip格式压缩
- zlib:以zlib格式压缩
- deflate:以deflate格式压缩
说明 本参数仅限于tunnel参数非
direct模式下使用。当tunnel为direct时,请将本参数设置为none。incr_sync.worker.oplog_compressor = noneincr_sync.target_delay 设置源端与目的端的延迟同步。通常源端中的变更会实时同步到目的端,为了防止误操作,您可以通过设置本参数达到延迟同步的目的。如: incr_sync.target_delay = 1800为设置30分钟的延迟。单位:秒。说明 0表示不启用延迟同步。
incr_sync.target_delay = 1800incr_sync.worker.batch_queue_size MongoShake内部队列的配置参数。如无特殊情况请勿修改。 incr_sync.worker.batch_queue_size = 64incr_sync.adaptive.batching_max_size incr_sync.adaptive.batching_max_size = 1024incr_sync.fetcher.buffer_capacity incr_sync.fetcher.buffer_capacity = 256MongoDB同步选项(仅适用于 direct模式)incr_sync.executor.upsert 当 _id(重复字段)或唯一索引不存在时,是否将UPDATE语句更改为INSERT语句。取值:- true:更改
- false:不更改
incr_sync.executor.upsert = falseincr_sync.executor.insert_on_dup_update 当 _id(重复字段)或唯一索引不存在时,是否将INSERT语句更改为UPDATE语句。取值:- true:更改
- false:不更改
incr_sync.executor.insert_on_dup_update = falseincr_sync.conflict_write_to 同步时如果存在写冲突,是否记录冲突文档。取值: - none:不记录
- db:将冲突日志写入mongoshake_conflict
- sdk:将冲突日志写入sdk
incr_sync.conflict_write_to = noneincr_sync.executor.majority_enable 是否在目的端启用多数写(Majority write)。取值: - true:启用
- false:不启用
说明 如果启用则会对性能造成一定影响。
incr_sync.executor.majority_enable = false - 执行下述命令启动同步任务,并打印日志信息。
./collector -conf=collector.conf -verbose - 观察打印的日志信息,当出现如下日志时,即代表全量数据同步已完成,并进入增量数据同步模式。
[09:38:57 CST 2019/06/20] [INFO] (mongoshake/collector.(*ReplicationCoordinator).Run:80) finish full sync, start incr sync with timestamp: fullBeginTs[1560994443], fullFinishTs[1560994737]
监控MongoShake状态
增量数据同步开始后,您可以再开启一个命令行窗口,通过如下命令来监控MongoShake。
./mongoshake-stat --port=9100监控输出示例。
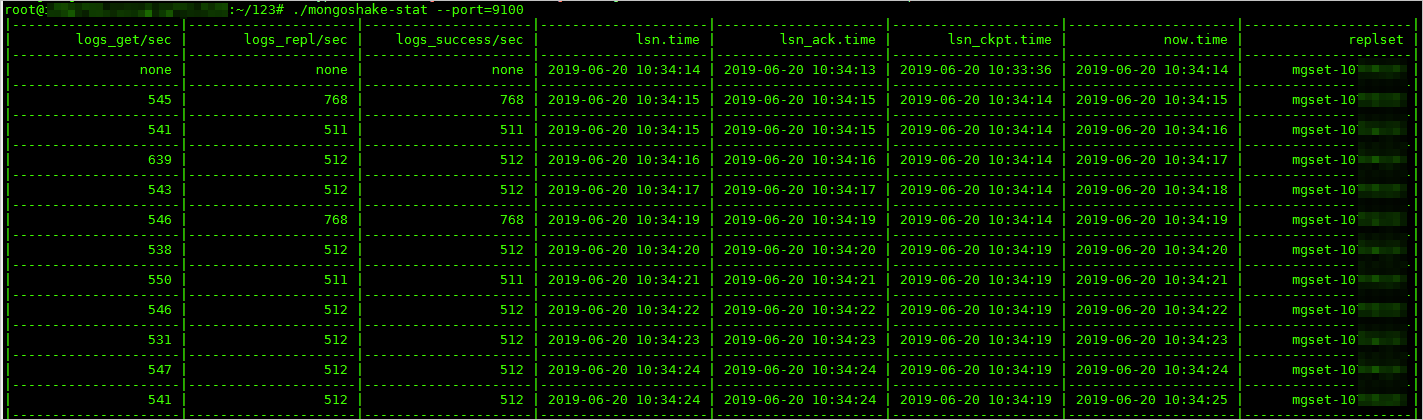
| 参数 | 说明 |
|---|---|
| logs_get/sec | 每秒获取的oplog数量。 |
| logs_repl/sec | 每秒执行重放操作的oplog数量。 |
| logs_success/sec | 每秒成功执行重放操作的oplog数量。 |
| lsn.time | 最后发送oplog的时间。 |
| lsn_ack.time | 目标端确认写入的时间。 |
| lsn_ckpt.time | CheckPoint持久化的时间。 |
| now.time | 当前时间。 |
| replset | 源数据库的副本集名称。 |