大数据实验报告七 Spark
一.Spark是什么?
Spark,是一种通用并行分布式大数据计算框架,2009年由加州大学的伯克利分校的AMP实验室开发,它是当前大数据领域最活跃的开源项目之一,它基于MapReduce算法的分布式计算,拥有MapReduce的所有的优点。它将操作过程的中间结果放于内存中,所以不需要读写HDFS,能更好的适用于数据挖掘和机器学习的迭代算法。
Spark被称为快数据,它于Hadoop的传统计算方式MapReduce相比快100倍,它还支持多语言。
Spark相关介绍可参照 大数据之谜Spark基础篇,Spark是什么
大数据学习:Spark是什么,如何用Spark进行数据分析
二.Spark好在哪里?
Spark的中间数据放到内存中,所以不需要读写HDFS,更好的适用于数据挖掘和机器学习的迭代算法。
Spark更适合于迭代运算比较多的ML和DM运算。因为在Spark里面,有RDD的抽象概念。
Spark比Hadoop更通用 Spark提供的数据集操作类型有很多。
Spark开发者可以快速的用Java、Scala或Python编写程序,并且它也在开发R语言。
Spark优势认知相关介绍 Spark的好处及优势
Spark与Hadoop相比的优缺点
三.Spark编程模型
1.运用程序
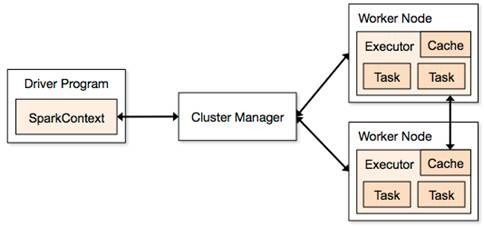
Spark应用程序分为两个部分:Driver部分和Executor部分
2.运行流程
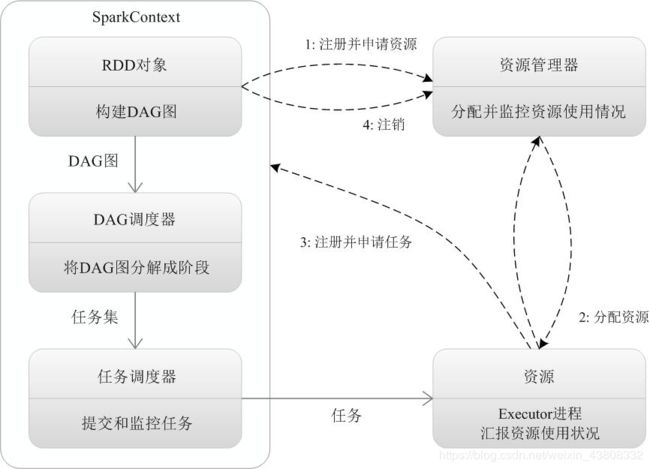
四.RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark最核心的东西,也是最基本的抽象,它表示一个不可变、可分区、里面的元素可并行计算的集合。不同的数据集格式对应不同的RDD实现。RDD必须是可序列化的。RDD可以cache到内存中,每次对RDD数据集的操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘IO操作。这对于迭代运算比较常见的机器学习算法, 交互式数据挖掘来说,效率提升非常大。
Spark计算模型RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将数据缓存在内存中,后续的查询能够重用这些数据,这极大地提升了查询速度。
RDD模型
常用的Transformation:
| 转换 |
含义 |
| map(func) |
返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
| filter(func) |
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
| flatMap(func) |
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
| mapPartitions(func) |
类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) |
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是 (Int, Interator[T]) => Iterator[U] |
| union(otherDataset) |
对源RDD和参数RDD求并集后返回一个新的RDD |
| intersection(otherDataset) |
对源RDD和参数RDD求交集后返回一个新的RDD |
| distinct([numTasks])) |
对源RDD进行去重后返回一个新的RDD |
| groupByKey([numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
| sortByKey([ascending], [numTasks]) |
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
| sortBy(func,[ascending], [numTasks]) |
与sortByKey类似,但是更灵活 |
| join(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
| cogroup(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable |
| coalesce(numPartitions) |
减少 RDD 的分区数到指定值。 |
| repartition(numPartitions) |
重新给 RDD 分区 |
| repartitionAndSortWithinPartitions(partitioner)
|
重新给 RDD 分区,并且每个分区内以记录的 key 排序 |
Action
触发整个任务真正的运行
| 动作 |
含义 |
| reduce(func) |
reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。 |
| collect() |
在驱动程序中,以数组的形式返回数据集的所有元素 |
| count() |
返回RDD的元素个数 |
| first() |
返回RDD的第一个元素(类似于take(1)) |
| take(n) |
返回一个由数据集的前n个元素组成的数组 |
| takeOrdered(n, [ordering]) |
返回自然顺序或者自定义顺序的前 n 个元素 |
| saveAsTextFile(path) |
将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) |
将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
| saveAsObjectFile(path) |
将数据集的元素,以 Java 序列化的方式保存到指定的目录下 |
| countByKey() |
针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
| foreach(func) |
在数据集的每一个元素上,运行函数func |
| foreachPartition(func) |
在数据集的每一个分区上,运行函数func |
RDD依赖关系
窄依赖(narrow dependency)和宽依赖(wide dependency)
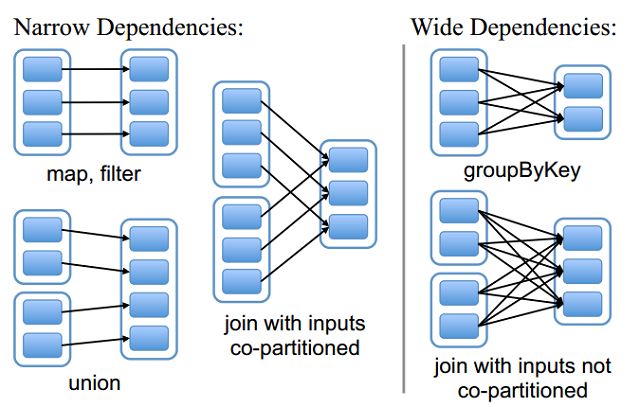
原文 Spark计算模型RDD
Spark计算模型RDD
五.Spark程序Scala
Scala是一种多范式的编程语言,其设计的初衷是要集成面向对象编程和函数式编程的各种特性。Scala运行于Java平台(Java虚拟机),并兼容现有的Java程序。
原文 Spark学习之scala编程
Spark shell 编写代码
读取本地文件
![]()
显示第一行内容
![]()
读取HDFS文件
![]()
对hdfs根目录下f1.txt文件进行词频统计
![]()
查看结果
![]()
使用Scala编写Spark程序
val spark = new SparkContext(master, appName, [sparkHome], [jars])
al file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
file是根据HDFS上的文件创建的RDD, flatMap、map、reduceByKe都创建出一个新的RDD, 一个简短的程序就能够执行很多个转换和动作。
Spark shell 编写代码 Spark Shell编写第一个代码
Scala编写Spark程序 Spark官方文档——本地编写并运行scala程序
https://www.cnblogs.com/shishanyuan/p/4721102.html
六.作业
安装Scala
安装Spark
使用Spark Shell
读取本地文件
读取HDFS文件
编写wordcount程序
用Scala编写Spark应用程序
用Java编写Spark应用程序
1.实验环境准备
官网下载安装Scala:scala-2.12.8.tgz
https://pan.baidu.com/s/1VDazlFWeWJi-Jtd9LMNSLg
官网下载安装Spark:spark-2.4.2-bin-hadoop2.7.tgz
https://www.apache.org/dyn/closer.lua/spark/spark-2.4.2/spark-2.4.2-bin-hadoop2.7.tgz
2、安装scala
用xftp把文件从本地路径上传到centos路径下
解压
tar -zxvf scala-2.12.8.tgz -C /opt/module
修改文件名
mv scala-2.12.8 scala
测试
scala -version
安装配置成功
3、安装安装spark
用xftp把文件从本地路径上传到centos路径下
解压压缩包
tar -zxvf spark-2.4.2-bin-hadoop2.7.tgz -C /opt/module
启动hadoop 环境
start-all.sh
启动spark环境:进入到SPARK_HOME/sbin下运行start-all.sh
cd /opt/module/spark/sbin
start-all.sh
4、搭建spark伪分布
(1)、配置spark-env.sh
vi spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_211-amd64
export SCALA_HOME=/usr/share/scala
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.7.7/etc/hadoop
export SPARK_MASTER_HOST=bigdata
export SPARK_MASTER_PORT=7077
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
(2)、配置etc/profile
vi etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_211-amd64
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HBASE_HOME=/usr/local/hbase/hbase-1.4.9
export HIVE_HOME=/usr/local/hive/apache-hive-2.3.4-bin
export SPARK_HOME=/usr/local/spark/spark-2.4.2-bin-hadoop2.7
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
配置文件生效
source profile
(3)、进入Spark 的 sbin 目录执行 start-all.sh 启动 spar:
./start-all.sh
(4)、进入spark
spark-shell
5、安装sbt
参考网址:http://dblab.xmu.edu.cn/blog/1307-2/
6、统计本地文件
val textFile = sc.textFile("file:///usr/local/spark/mycode/wordcount/word.txt")
wordCount.collect()
7、scala程序实现wordcount统计
spark-submit --class "WordCount" /usr/local/spark/mycode/wordcount/target/scala-2.11/simple-project_2.11-4.1.jar
相关scala程序:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val inputFile = "file:///usr/local/spark/mycode/wordcount/word.txt"
val conf = new SparkConf().setAppName("WordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}
原文:安装spark并编写scala 实现wordcount