第一次作业:深度学习基础
【第一部分】视频学习心得及问题总结
绪论
-
人工智能的概念:让机器像人一样进行感知、认知、决策、执行的人工程序或系统。
-
人工智能发展的历史及标志性事件:达特茅斯会议AI诞生、感知机、专家系统、决策树、逻辑、统计学、深度学习。
-
人工智能三个层面:
- 计算智能:能存能算——具备快速计算和记忆存储能力
- 感知智能:能听会说,能看会认——类似人的视觉、听觉、触觉等感知能力
- 认知智能:能理解。会思考——概念、意识、观念
-
专家系统和机器学习
- 知识工程/专家系统:人工定义规则
- 基于手工设计规则建立
- 容易解释结果
- 系统构建费时费力
- 依赖专家主观经验,难以保证已制定和准确性
- 机器学习:机器自动训练
- 基于数据自动学习
- 减少人工工作,但结果可能不易解释
- 提高信息处理效率,准确度较高
- 来源于真实数据,减少人工规则主观性,可信度高
- 知识工程/专家系统:人工定义规则
-
机器学习的应用技术领域
- 计算机视觉
- 语音技术
- 自然语言处理
-
机器学习定义:从数据中自动提取知识
- 常用定义:计算机系统能够利用经验提高自身的性能
- 可操作定义:机器学习本质是一个基于经验数据的函数估计问题
- 统计学定义:提取重要模式、趋势,并理解数据,即从数据中学习
-
机器学习学什么:问题规模大、准则复杂、有数据、有意义的模式
-
机器学习学习方式
- 模型:问题建模,确定假设空间
- 策略:确定目标函数
- 算法:求解模型参数
-
机器学习模型分类
-
数据标记
- 监督学习模型:输出目标有标记
- 无监督学习模型
- 半监督学习模型:部分标记已知
- 强化学习模型:标记未知,但知道与输出目标相关的反馈——决策类问题
-
数据分布
- 参数模型:数据分布可以使用有限且固定数目的参数进行刻画——线性回归、逻辑回归、感知机
- 非参数模型:统计特性来源于数据本身:k近邻模型
-
建模对象
- 判别模型:对已知输入条件下输出的条件分布建模
- 生成模型:对输入和输出的联合分布建模
-
-
传统机器学习和深度学习的区别:深度学习只需要挑选结果深度模型和几组模型超参数剩下的交给机器来优化权重参数,无需人工挑选特征
-
深度学习的不能: 解释性
- 1.算法输出不稳定,容易被“攻击”
- 2.模型复杂度高,难以纠错和调试 出了问题准确快速纠错
- 3.模型层级复合程度高,参数不透明
- 4.端到端训练方式对数据依赖性强,模型增量性差 双向:算法能被人理解,利用结合人类知识
- 5.专注直观感知类问题,对开放性推理问题无能为力
- 6.人类知识无法有效引入监督,机器偏见难以避免 知识得到积累和复用
深度学习概述
-
生物神经元特点
- 多输入单输出
- 空间整合和时间整合
- 区分兴奋性输入和抑制性输入
- 具有阈值特性
-
M-P神经元
- 多输入信号累加
- 权值正负模拟兴奋\抑制,大小模拟强度
- 输入和超过阈值,被激活
-
激活函数f:非线性
- 线性函数
- 斜面函数
- 阈值函数
- 符号函数
- S性函数 逻辑回归
- 双极S性函数
- ReLU修正线性单元
- Leaky ReLU
-
单层感知器:首个可以学习的人工神经网络
- 非线性激活函数
- 逻辑与或非
- 非线性激活函数
-
多层感知器
- 异或问题 数字逻辑组合
- 三层感知器实现同或门
-
万有逼近定理:
- 如果一个隐层包含足够多的神经元,三层前馈神经网络(输入-隐层-输出)能以任意精度逼近任意预定的连续函数。
- 双隐层感知器逼近非连续函数:当隐层足够宽时,双隐层感知器(输入-隐层1-隐层2-输出)可以逼近任意非连续函数:可以解决任何复杂的分类问题
-
神经网络每一层作用,输入->输出空间变换
- 升维/降维
- 放大/缩小
- 旋转
- 平移
- 弯曲
- 神经网络学习如何利用矩阵的线性变换加激活函数的非线性变换,将原视输入空间投影到线性可分的空间去分类/回归。
- 增加节点数:增加维度,及增加线性转换能力
- 增加层数:增加激活函数的次数,即增加非线性转换次数
- 在神经元总数相当的情况下,增加网络深度比增加宽度带来更强的网络表示能力:更多的线性区域
- 深度贡献指数增长,宽度的贡献是线性的。
-
多层神经网络的梯度消失——反向传播,误差无法传播——三层神经网络是主流
- 多层神经网络可以看成一个复合的非线性多元函数
- 给定训练数据,希望损失尽可能小
-
神经网络的参数学习:误差反向传播
- 复合函数的链式求导
- 三层前馈神经网络的BP算法
-
神经网络基础
- 逐层预训练 :权重初始化——逐层预训练
- 局部极小值
- 梯度消失
- 受限玻尔兹曼机:两层:可见层,隐藏层
- 自编码器:三层,先编码再解码
- 输入与输出相同,浮现输入信号
- 没有额外监督信息
- 逐层预训练 :权重初始化——逐层预训练
pyTorch
- torch.Tensor 张量,用来存储数据
data:存数据
grad:存梯度
grad_fn:指向创造自己的Function
-
torch.autograd.Function 函数类,定义在Tensor类上的操作
-
pyTorch的加减乘除等基本运算
-
常见的代码实现流程
【第二部分】代码练习
2.1 图像处理基本练习
colony = io.imread('yeast_colony_array.jpg')
print(type(colony))
print(colony.shape)
(406, 604, 3)
# Plot all channels of a real image
plt.subplot(121)
plt.imshow(colony[:,:,:])
plt.title('3-channel image')
plt.axis('off')
# Plot one channel only
plt.subplot(122)
plt.imshow(colony[:,:,0])
plt.title('1-channel image')
plt.axis('off');

# 获取某一点像素值
camera = data.camera()
print(camera[10, 20])
# 将某一区域像素设为黑色
camera[30:100, 10:100] = 0
plt.imshow(camera, 'gray')

# 改变满足条件像素点的像素值
camera = data.camera()
mask = camera < 80
camera[mask] = 255
plt.imshow(camera, 'gray')

red_cat = cat.copy()
reddish = cat[:, :, 0] > 160
red_cat[reddish] = [255, 0, 0]
plt.imshow(red_cat)

# 改变RGB为BGR
BGR_cat = cat[:, :, ::-1]
plt.imshow(BGR_cat)

#转换图像数据类型
from skimage import img_as_float, img_as_ubyte
float_cat = img_as_float(cat)
uint_cat = img_as_ubyte(float_cat)
#显示图像直方图
img = data.camera()
plt.hist(img.ravel(), bins=256, histtype='step', color='black');
colony = io.imread('yeast_colony_array.jpg')
img = skimage.color.rgb2gray(colony)
plt.hist(img.ravel(), bins=256, histtype='step', color='black');
plt.imshow(img>0.5)

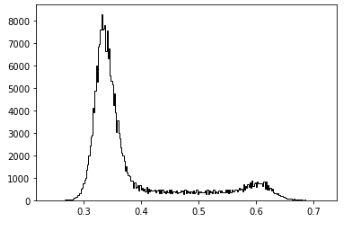

from skimage.feature import canny
from scipy import ndimage as ndi
img_edges = canny(img)
img_filled = ndi.binary_fill_holes(img_edges)
# Plot
plt.figure(figsize=(18, 12))
plt.subplot(121)
plt.imshow(img_edges, 'gray')
plt.subplot(122)
plt.imshow(img_filled, 'gray')

#改变图像对比度并展示直方图,累计直方图
# 显示累计直方图
img_cdf, bins = skimage.exposure.cumulative_distribution(img, bins)
#运行报错,“name ‘exposure’ is not defined”添加skimage
ax_cdf.plot(bins, img_cdf, 'r')
ax_cdf.set_yticks([])
2.2 pytorch基础练习

报错,第三个参数‘v’格式不正确,将‘v’创建时,直接赋予float类型,运行正确

from matplotlib import pyplot as plt
# 生成 1000 个随机数,并按照 100 个 bin 统计直方图
plt.hist(torch.randn(1000).numpy(), 100);

plt.hist(torch.randn(10**6).numpy(), 100);

2.3 螺线数据分类
# 初始化随机数种子,神经网络的参数都是随机初始化的
seed = 12345
random.seed(seed)
torch.manual_seed(seed)
N = 1000 # 每类样本的数量
D = 2 # 每个样本的特征维度
C = 3 # 样本的类别
H = 100 # 神经网络里隐层单元的数量
X = torch.zeros(N * C, D).to(device) #特征矩阵,NxC行,D列
Y = torch.zeros(N * C, dtype=torch.long).to(device) #样本标签
for c in range(C):
index = 0
t = torch.linspace(0, 1, N) # 在[0,1]间均匀的取10000个数,赋给t
# torch.randn(N) 是得到 N 个均值为0,方差为 1 的一组随机数,注意要和 rand 区分开
inner_var = torch.linspace( (2*math.pi/C)*c, (2*math.pi/C)*(2+c), N) + torch.randn(N) * 0.2
# 每个样本的(x,y)坐标都保存在 X 里
# Y 里存储的是样本的类别,分别为 [0, 1, 2]
for ix in range(N * c, N * (c + 1)):
X[ix] = t[index] * torch.FloatTensor((math.sin(inner_var[index]), math.cos(inner_var[index])))
Y[ix] = c
index += 1
plot_data(X, Y)

1.构建线性模型分类
learning_rate = 1e-3
lambda_l2 = 1e-5
# nn 包用来创建线性模型
# 每一个线性模型都包含 weight 和 bias
model = nn.Sequential(
nn.Linear(D, H),
nn.Linear(H, C)
)
model.to(device) # 把模型放到GPU上
# nn 包含多种不同的损失函数,这里使用的是交叉熵(cross entropy loss)损失函数
criterion = torch.nn.CrossEntropyLoss()
# 这里使用 optim 包进行随机梯度下降(stochastic gradient descent)优化
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
# 开始训练
for t in range(1000):
# 把数据输入模型,得到预测结果
y_pred = model(X)
# 计算损失和准确率
loss = criterion(y_pred, Y)
#沿着第二个方向(即X方向)提取最大值。最大的那个值存在 score 中,所在的位置(即第几列的最大)保存在 predicted 中
score, predicted = torch.max(y_pred, 1)
acc = (Y == predicted).sum().float() / len(Y)
print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc))
display.clear_output(wait=True)
# 反向传播前把梯度置 0
optimizer.zero_grad()
# 反向传播优化
loss.backward()
# 更新全部参数
optimizer.step()
[EPOCH]: 999, [LOSS]: 0.861541, [ACCURACY]: 0.504
print(y_pred.shape)#模型的预测结果
print(y_pred[10, :])
print(score[10])
print(predicted[10])
#模型输出
print(model)
plot_model(X, Y, model)
torch.Size([3000, 3])
tensor([-0.2245, -0.2594, -0.2080], device='cuda:0', grad_fn=)
tensor(-0.2080, device='cuda:0', grad_fn=)
tensor(2, device='cuda:0')

当使用线性的决策边界来分隔螺旋的数据,只使用nn.linear()模组,而不在之间加上非线性,只能达到 50% 的正确度
2.构建两层神经网络分类
learning_rate = 1e-3
lambda_l2 = 1e-5
# 这里可以看到,和上面模型不同的是,在两层之间加入了一个 ReLU 激活函数
model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, C)
)
model.to(device)
# 下面的代码和之前是完全一样的,这里不过多叙述
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=lambda_l2) # built-in L2
# 训练模型,和之前的代码是完全一样的
for t in range(1000):
y_pred = model(X)
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = ((Y == predicted).sum().float() / len(Y))
print("[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f" % (t, loss.item(), acc))
display.clear_output(wait=True)
# 反向传播把梯度置零
optimizer.zero_grad()
# 反向传播优化
loss.backward()
# 更新全部参数
optimizer.step()
[EPOCH]: 999, [LOSS]: 0.178408, [ACCURACY]: 0.949
print(model)#模型输出
plot_model(X, Y, model)
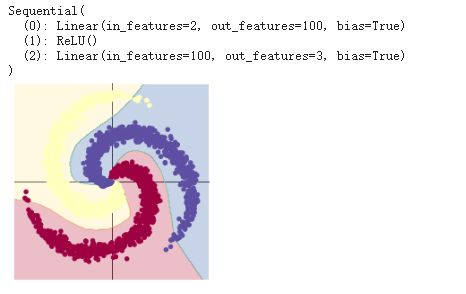
从线性模型换成在两个 nn.linear() 模组再经过一个 nn.ReLU() 的模型,正确度增加到了接近 95%。这是因为边界变成非线性的并且更好的顺应资料的螺旋。
2.4 回归分析
import random
import torch
from torch import nn, optim
import math
from IPython import display
from plot_lib import plot_data, plot_model, set_default
from matplotlib import pyplot as plt
set_default()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
seed = 1
random.seed(seed)
torch.manual_seed(seed)
N = 1000 # 每类样本的数量
D = 1 # 每个样本的特征维度
C = 1 # 类别数
H = 100 # 隐层的神经元数量
X = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1).to(device)
y = X.pow(3) + 0.3 * torch.rand(X.size()).to(device)
# 在坐标系上显示数据
plt.figure(figsize=(6, 6))
plt.scatter(X.cpu().numpy(), y.cpu().numpy())
plt.axis('equal');

1.建立线性模型(两层网络间没有激活函数)
learning_rate = 1e-3
lambda_l2 = 1e-5
# 建立神经网络模型
model = nn.Sequential(
nn.Linear(D, H),
nn.Linear(H, C)
)
model.to(device) # 模型转到 GPU
# 对于回归问题,使用MSE损失函数
criterion = torch.nn.MSELoss()
# 定义优化器,使用SGD
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2) # built-in L2
# 开始训练
for t in range(1000):
# 数据输入模型得到预测结果
y_pred = model(X)
# 计算 MSE 损失
loss = criterion(y_pred, y)
print("[EPOCH]: %i, [LOSS or MSE]: %.6f" % (t, loss.item()))
display.clear_output(wait=True)
# 反向传播前,梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
[EPOCH]: 999, [LOSS or MSE]: 0.029701
# 展示模型与结果
print(model)
plt.figure(figsize=(6,6))
plt.scatter(X.data.cpu().numpy(), y.data.cpu().numpy())
plt.plot(X.data.cpu().numpy(), y_pred.data.cpu().numpy(), 'r-', lw=5)
plt.axis('equal');

2.两层神经网络
# 这里定义了2个网络,一个 relu_model,一个 tanh_model,
# 使用了不同的激活函数
relu_model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, C)
)
relu_model.to(device)
tanh_model = nn.Sequential(
nn.Linear(D, H),
nn.Tanh(),
nn.Linear(H, C)
)
tanh_model.to(device)
# MSE损失函数
criterion = torch.nn.MSELoss()
# 定义优化器,使用 Adam,这里仍使用 SGD 优化器的化效果会比较差,具体原因请自行百度
optimizer_relumodel = torch.optim.Adam(relu_model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
optimizer_tanhmodel = torch.optim.Adam(tanh_model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
# 开始训练
for t in range(1000):
y_pred_relumodel = relu_model(X)
y_pred_tanhmodel = tanh_model(X)
# 计算损失与准确率
loss_relumodel = criterion(y_pred_relumodel, y)
loss_tanhmodel = criterion(y_pred_tanhmodel, y)
print(f"[MODEL]: relu_model, [EPOCH]: {t}, [LOSS]: {loss_relumodel.item():.6f}")
print(f"[MODEL]: tanh_model, [EPOCH]: {t}, [LOSS]: {loss_tanhmodel.item():.6f}")
display.clear_output(wait=True)
optimizer_relumodel.zero_grad()
optimizer_tanhmodel.zero_grad()
loss_relumodel.backward()
loss_tanhmodel.backward()
optimizer_relumodel.step()
optimizer_tanhmodel.step()
[MODEL]: relu_model, [EPOCH]: 999, [LOSS]: 0.006479
[MODEL]: tanh_model, [EPOCH]: 999, [LOSS]: 0.007934
plt.figure(figsize=(12, 6))
def dense_prediction(model, non_linearity):
plt.subplot(1, 2, 1 if non_linearity == 'ReLU' else 2)
X_new = torch.unsqueeze(torch.linspace(-1, 1, 1001), dim=1).to(device)
with torch.no_grad():
y_pred = model(X_new)
plt.plot(X_new.cpu().numpy(), y_pred.cpu().numpy(), 'r-', lw=1)
plt.scatter(X.cpu().numpy(), y.cpu().numpy(), label='data')
plt.axis('square')
plt.title(non_linearity + ' models')
dense_prediction(relu_model, 'ReLU')
dense_prediction(tanh_model, 'Tanh')

使用ReLU激活函数得到一个分段的线性函数,而Tanh激活函数则得到连续、平滑的回归曲线