配合scrapy,用请求方式抓取一些网站内容。例如抓取360手机应用APP信息。
并不是一想到抓取网页就开始写scrapy爬虫,其实根据需求选择适当的方式来抓取反而效率更高。
例如抓取360手机应用各种分类的前5页的信息。我们不写scrapy,而直接去分析请求消息的样式,模拟发送这个消息,然后分析返回的内容,同样可以获取想要的信息。更重要的是,在对于一些JS动态加载内容(例如抓取Googleplay上的应用)抓取时,这种方式去获取重要信息后再配合scrapy抓取,就能获得更好的效果。在这里仅仅使用发送请求的方式去抓取。
需求:抓取360手机应用搜索种类的前五页的内容。例如:
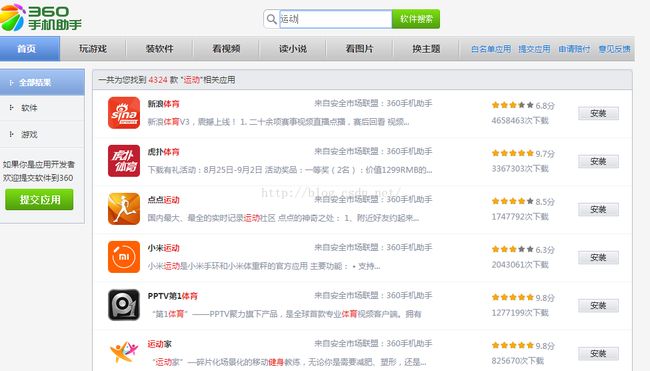
在搜索栏输入游戏,会出现这些应用(按种类搜索,都是一样的)。我们去抓取这些游戏的信息。这里作为例子,只抓取应用的包名。
如何查看浏览器请求消息,这里就不多赘述,F12打开浏览器,去查找返回所需请求的信息,一般从前面开始看Network中的信息,再查看response,有返回所需信息的内容即可:
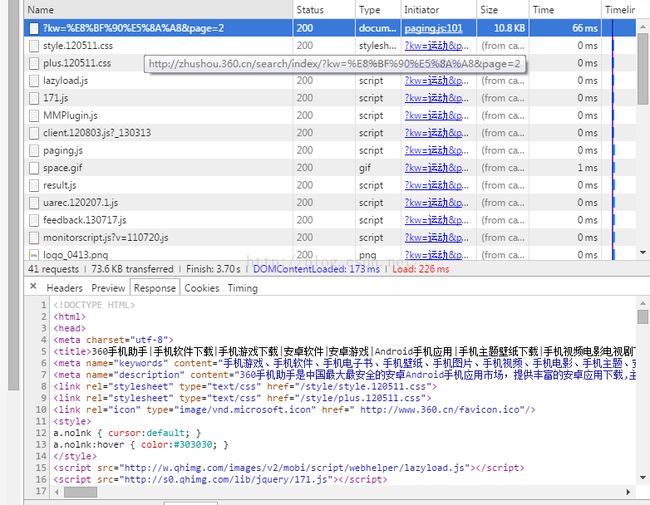
这即是我们要的信息,查看Headers去寻找模拟发送请求所需的信息,这里就不再赘述。360网站发送请求的头URL其实就是URL,例如点击下一页之后,URL为:
![]()
这就是发送请求的格式。只要构造好这个URL,则随便取数据,例如取体育类的第三页的内容,则组成的连接为 http://zhushou.360.cn/search/index/?kw=体育&page=3
以此类推。可以使用Chrome的插件Postman去验证返回的结果,也可以请求完毕后直接打印出结果。便知道是否正确了。还是直接上程序吧:
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
import scrapy
from scrapy.crawler import CrawlerProcess
#from scrapy.utils.project import get_project_settings
#from databases import TSFDataBase
import urllib
import urllib2
from lxml import etree
appkind=['阅读','商务','漫画','通讯','教育','娱乐','金融','游戏','健康','图书','生活','动态壁纸','影音','医疗','音乐','新闻','个性化','摄影','效率','购物','社交','体育','工具','旅游','交通','天气']
fileWriteObj = open('360app.txt', 'w')
print len(appkind)
for ikind in range(len(appkind)):
for ipage in range(5):
print ipage
data={}
data['page']=ipage+1
test_data_urlencode=urllib.urlencode(data)
url="http://zhushou.360.cn/search/index/?kw="+appkind[ikind]+"&page="+str(ipage+1)
data1 = urllib.urlencode(data)
req = urllib2.Request(url, data1)
response = urllib2.urlopen(req)
result = response.read()
#print result
if isinstance(result, unicode):
pass
else:
result = result.decode('utf-8')
tree = etree.HTML(result)
ranks=tree.xpath('//div[@class="download comdown"]/a/@href')
print len(ranks)
#ids=tree.xpath('//div[@class="card no-rationale square-cover apps small"]/div/div[2]/a[2]/@href')
for i in range(len(ranks)):
apppack=ranks[i]
apppack=apppack[apppack.rfind('/')+1:apppack.rfind('_')]
onedata=apppack+','+str(ikind+1)
print onedata
fileWriteObj.write(onedata+'\n')
print '-------------------'
fileWriteObj.close()
if __name__=='__main__':
pass
结果:包名后面跟着的是分类的编号,例如阅读为1
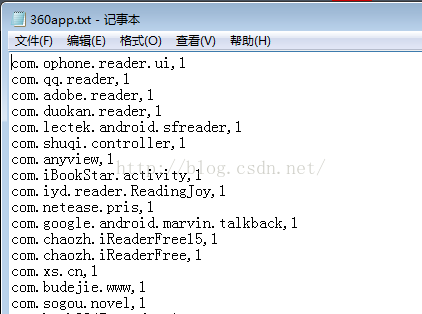
该程序搜索了26中关键词的应用,每种应用抓取前五页,为了方便展示,直接存入文本。至于xpath等知识就不再赘述。以后有时间会整理如何处理页面JS加载内容的抓取。