seaborn系列 (3) | 折线图lineplot()
折线图
- 折线图
- 函数原型
- 参数解读
- 案例教程
- 案例地址
折线图
注意:数据一定是通过DataFrame中传送的
函数原型
seaborn.lineplot(x=None, y=None, hue=None,
size=None, style=None, data=None,
palette=None, hue_order=None, hue_norm=None,
sizes=None, size_order=None, size_norm=None,
dashes=True, markers=None, style_order=None,
units=None, estimator='mean', ci=95, n_boot=1000,
sort=True, err_style='band', err_kws=None,
legend='brief', ax=None, **kwargs)
参数解读
data:是DataFrame类型的;
可选:下面均为可选
x,y:数据中变量的名称;
hue:数据中变量名称(比如:二维数据中的列名)
作用:对将要生成不同颜色的线进行分组,可以是分类或数据。
size:数据中变量名称(比如:二维数据中的列名)
作用:对将要生成不同宽度的线进行分组,可以是分类或数据。
style:数据中变量名称(比如:二维数据中的列名)
作用:对将生成具有不同破折号、或其他标记的变量进行分组。
palette:调试板名称,列表或字典类型
作用:设置hue指定的变量的不同级别颜色。
hue_order:列表(list)类型
作用:指定hue变量出现的指定顺序,否则他们是根据数据确定的。
hue_norm:tuple或Normalize对象
sizes:list dict或tuple类型
作用:设置线宽度,当其为数字时,它也可以是一个元组,指定要使用的最大和最小值,会自动在该范围内对其他值进行规范化。
units:对变量识别抽样单位进行分组,使用时,将为每个单元绘制一个单独的行。
estimator:pandas方法的名称或回调函数或者None
作用:用于在同一x水平上聚合y变量的多个观察值的方法,如果为None,则将绘制所有观察结果。
案例教程
案例代码已上传:Github地址
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_diabetes
def fun(x):
if x >0:
return 1
else:
return 0
# sklearn自带数据 diabetes 糖尿病数据集
diabetes=load_diabetes()
data = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
#只抽取前80个数据
df=data[:80]
#由于diabetes中的数据均已归一化处理过,sex列中的值也归一化,现将其划分一下,大于0的设置为1,小于等于0的设置为0
df['sex']=df['sex'].apply(lambda x: fun(x))
#展示前5条数据
df[:5]

import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
%matplotlib inline
from sklearn.datasets import load_diabetes
def fun(x):
if x >0:
return 1
else:
return 0
# sklearn自带数据 diabetes 糖尿病数据集
diabetes=load_diabetes()
data = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
#只抽取前80个数据
df=data[:80]
#由于diabetes中的数据均已归一化处理过,sex列中的值也归一化,现将其划分一下,大于0的设置为1,小于等于0的设置为0
df['sex']=df['sex'].apply(lambda x: fun(x))
"""
案例1:绘制带有误差带的单线图,显示置信区间
"""
ax = sns.lineplot(x="age", y="s4",data=df)
plt.show()

import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
%matplotlib inline
from sklearn.datasets import load_diabetes
def fun(x):
if x >0:
return 1
else:
return 0
# sklearn自带数据 diabetes 糖尿病数据集
diabetes=load_diabetes()
data = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
#只抽取前80个数据
df=data[:80]
#由于diabetes中的数据均已归一化处理过,sex列中的值也归一化,现将其划分一下,大于0的设置为1,小于等于0的设置为0
df['sex']=df['sex'].apply(lambda x: fun(x))
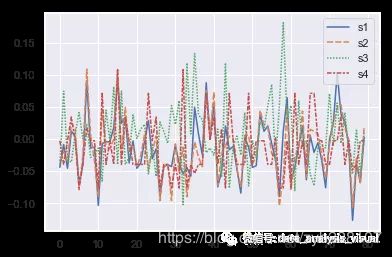
"""
案例2:绘制带有误差带的单线图,显示置信区间
"""
dd=[df['s1'],df['s2'],df['s3'],df['s4']]
ax = sns.lineplot(data=dd)
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
%matplotlib inline
from sklearn.datasets import load_diabetes
def fun(x):
if x >0:
return 1
else:
return 0
# sklearn自带数据 diabetes 糖尿病数据集
diabetes=load_diabetes()
data = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
#只抽取前80个数据
df=data[:80]
#由于diabetes中的数据均已归一化处理过,sex列中的值也归一化,现将其划分一下,大于0的设置为1,小于等于0的设置为0
df['sex']=df['sex'].apply(lambda x: fun(x))
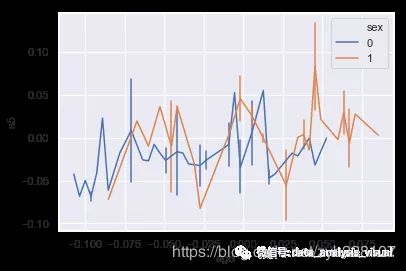
"""
案例3:设置hue为sex,按照sex分组,并显示不同颜色
"""
sns.lineplot(x="age", y="s4", hue="sex",data=df)
plt.show()

import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
%matplotlib inline
from sklearn.datasets import load_diabetes
def fun(x):
if x >0:
return 1
else:
return 0
# sklearn自带数据 diabetes 糖尿病数据集
diabetes=load_diabetes()
data = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
#只抽取前80个数据
df=data[:80]
#由于diabetes中的数据均已归一化处理过,sex列中的值也归一化,现将其划分一下,大于0的设置为1,小于等于0的设置为0
df['sex']=df['sex'].apply(lambda x: fun(x))
"""
案例4:使用颜色和线型显示分组变量
"""
sns.lineplot(x="age", y="s1",hue="sex", style="sex", data=df)
plt.show()

import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
%matplotlib inline
from sklearn.datasets import load_diabetes
def fun(x):
if x >0:
return 1
else:
return 0
# sklearn自带数据 diabetes 糖尿病数据集
diabetes=load_diabetes()
data = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
#只抽取前80个数据
df=data[:80]
#由于diabetes中的数据均已归一化处理过,sex列中的值也归一化,现将其划分一下,大于0的设置为1,小于等于0的设置为0
df['sex']=df['sex'].apply(lambda x: fun(x))
"""
案例5:使用标记来标识组,而不用破折号来标识组:设置markers为True,设置dashes为False
"""
sns.lineplot(x="age", y="s1",hue="sex", style="sex", markers=True, dashes=False, data=df)
plt.show()

import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
%matplotlib inline
from sklearn.datasets import load_diabetes
def fun(x):
if x >0:
return 1
else:
return 0
# sklearn自带数据 diabetes 糖尿病数据集
diabetes=load_diabetes()
data = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
#只抽取前80个数据
df=data[:80]
#由于diabetes中的数据均已归一化处理过,sex列中的值也归一化,现将其划分一下,大于0的设置为1,小于等于0的设置为0
df['sex']=df['sex'].apply(lambda x: fun(x))
"""
案例6:显示错误条,而不显示错误带
"""
sns.lineplot(x="age", y="s5",hue="sex",err_style="bars", ci=68, data=df)
plt.show()
import numpy as np
import pandas as pd;
import matplotlib.pyplot as plt
# 构建 时间序列数据 从2000-1-31开始,以月份为间隔,构建100条记录
index = pd.date_range("1 1 2000", periods=100,freq="m", name="date")
data = np.random.randn(100, 4).cumsum(axis=0)
# 构建5列数据,列名分别为data a b c d
wide_df = pd.DataFrame(data, index, ["a", "b", "c", "d"])
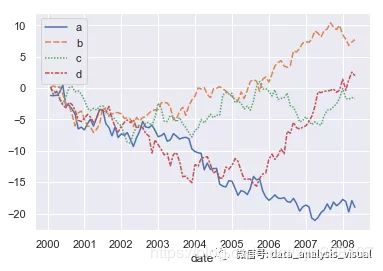
"""
案例7:绘制时间序列数据
"""
sns.lineplot(data=wide_df)
plt.show()
案例地址
上述案例代码已上传:Github地址
Github地址https://github.com/Vambooo/SeabornCN
更多技术干货在公众号:数据分析与可视化学研社
