如何让服务可用性高达99.9999%?异地灾备是关键!

为了保障业务系统在遭受意外的情况下依然能够正常运转,企业往往会在异地部署一套与现有的业务系统一样的生产环境,即异地灾备系统。它可以保障业务安全和稳定,有效提高业务系统抵抗外界因素的容灾能力。
(文末附视频版讲解及完整资料下载)
01
概念和方案
Share78容灾国际标准定义了7个灾备层级。
0级:没有异地可恢复数据
1级:介质异地备份
2级:介质异地存储加热备份站点
3级:用电子链路实现数据备份
4级:定时数据备份
5级:备份站点保持运转
6级:零数据丢失
RPO和RTO
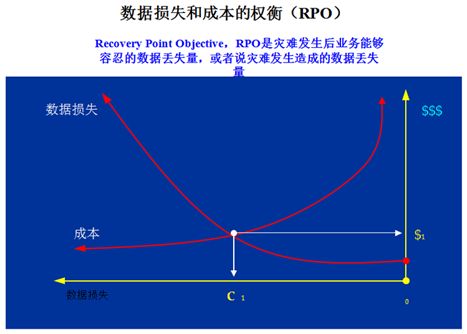
RPO和RTO是衡量容灾系统的两个主要指标。RPO是Recovery Point Objective,恢复点目标,是指灾难发生后业务能允许的数据丢失量。下图所示是关于数据损失和成本的权衡。显然,数据损失这条线和成本这条线是反相关的:想将数据损失降到越低,付出的成本也会越高。图中的相交点代表合理折中的实现度的所在位置。实现一个简单的备份成本很低,效果可能也不是很理想,但也比没有好。另外,我们也不宜为了减少数据损失而付出过大的成本支出,所以找到图中这个相交的点是贯穿所有方案的中心思考。
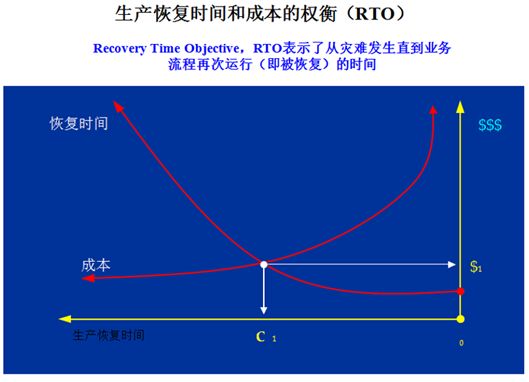
RTO是Recovery Time Objective,恢复时间目标,是指从灾难发生到业务恢复的时间。比如,当电脑系统死机时,而我们急着用电脑,那么无论数据是否需要恢复,可以暂时先换一台备用电脑,这种情况下的RTO为零。但是,如果我们不着急用,接着花了一小时来恢复数据,那么RTO为一小时。RTO和成本的关系如图所示,和RPO一样也是反相关的。要求数据恢复时间越短,实现的成本代价就越高。我们设计方案同样也要寻找恢复时间和成本的折中点。
容灾技术方案类型
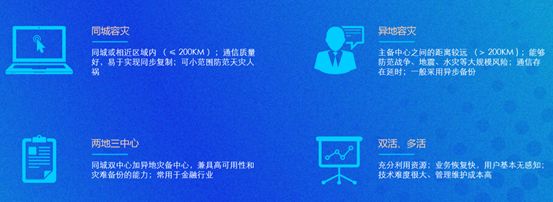
容灾技术方案一般有四类。第一类是同城容灾,指在较近的距离建设同城机房,一般距离在200km内,这样通信的质量好、时延小。如果网络足够好甚至可以视为一个本地机房使用,此时数据的备份方案更加简单、易实现,比如采用同步方式,在一定程度上能够防范损失。
第二类是异地容灾,这是相对同城而言的。面对范围较大的灾害,比如地震、水灾或者大规模网络故障等,同城机房可能遭遇同时不可用的状态。反之异地容灾的缺点也很明显,时延更高,不适用同步备份。
第三类是两地三中心模式。两地是指同城、异地;三中心是指生产中心、同城容灾中心、异地容灾中心。这是前面两种容灾技术方案的结合,具备前两者的优点,但成本也会更高,一般应用于金融行业。
第四类是“双活”或 “多活”模式,区别于传统数据中心和灾备中心的模式。传统模式下,生产数据中心投入运行,灾备数据中心处在不工作状态,只有当灾难发生时,生产数据中心瘫痪,灾备中心才启动。而在“双活”和“多活”模式下,存在两个甚至多个数据中心同时处于运行的情况。在这两种模式下,它们运行相同的应用、具备同样的数据,能够提供跨中心业务负载均衡运行,具备持续的应用可用性和灾难备份能力。
02
异地灾备建设历程
v1.0
个推的灾备建设始于2015年。其最初原因是业务壮大后导致原机房资源接近饱和。当初我们使用的是运营商机房,由于机房容量限制和内部网络压力,我们开始准备再建一个机房,在方案设计上考虑一定程度的灾备。
结合当时的业务状况和难点进行分析,主要存在三点问题:
一、由于推送的⻓连接特性,切换服务时会断开连接,下发效果易受到影响;
二、数据源多样,比如REDIS、CODIS、ELASTICSEARCH、MYSQL,每种组件都需要数据同步并保证一致性;
三、服务依赖多,各服务模块互相之间依赖、服务模块与中间件相依赖。
个推异地灾备1.0架构方案是数据按账号维度分机房存储,主要业务仍然在各自归属机房内完成,这样资源压力就得到了分摊。有需要的情况下,各业务模块可根据账号路由请求到其它机房,中间通过一个转发模块,将各模块业务中需要跨机房的请求进行包装加密,通过公网和专线两种路径进行请求转发。
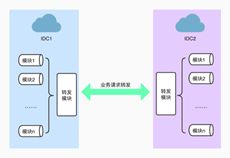
架构v1.0存在以下问题:
一、 业务模块耦合了大量跨机房转发逻辑,甚至各模块已经内含不同的跨机房业务逻辑,负责接手的开发人员需要熟悉相应的逻辑,增加了修改维护的人力成本。
二、扩展性有待提升。现有架构并未设计数据热迁移的方案,如果再建机房则需要做修改。
v1.5
新的架构需求的出发点在于,个推计划建设一个新的机房做数据热备,支持账号机房归属的快速切换,以及过大的数据集群(Redis、ElasticSearch)也需要拆分管理。出于业务需要,我们产出了一个过渡的1.5架构。
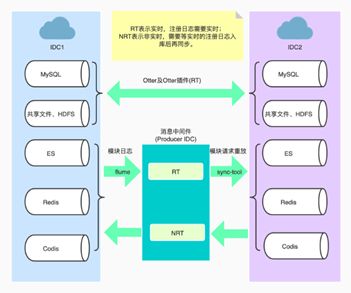
在该架构中,MySQL和文件直接使用Otter来做数据同步。它支持一些插件进行任务处理,比如协助与表字段相关的文件传输。其余组件,如ElasticSearch、Redis、Codis里面的数据结构,暂时还是通过模块的业务请求记录日志,通过Flume写到RocketMQ,然后由另一个IDC的同步工具消费回放请求。mq会部署在日志生成的当前机房,这样数据的可靠性更有保障,不会因网络问题堵住生产者。为了保障数据的顺序,我们根据业务将注册请求优先实时同步,其它请求滞后非实时同步,一定程度上保障了业务数据的顺序性。
我们经过深入调研,最终选用了Otter。它的主要结构包括Node和Manager两大块,Manager负责配置管理,有 Web⻚面支持;Node是实际工作节点,并且内嵌有一个Cannal,也支持接入独立部署的Cannal实例。
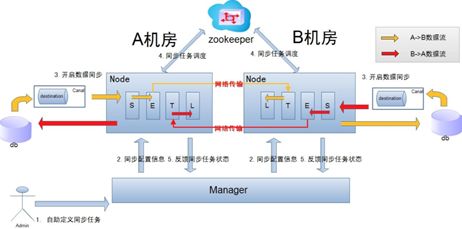
整个同步流程抽象为Select、Extract、Transform、Load4个阶段。
在本地机房进行两个阶段(S、E)
● Select阶段: 为解决数据来源的差异性,比如接入canal获取增量数据,也可以接入其他系统获取其他数据等。
● Extract阶段: 组装数据,针对多种数据来源,比如mysql、oracle、store、file等,进行数据组装和过滤,这里可以加入自定义的解析代码,包括文件处理FileRElasticSearcholver。
在异地机房进行两个阶段(T、L)
● Transform阶段: 数据提取转换过程,把数据转换成目标数据源要求的类型。
● Load阶段: 数据载入,将数据载入到目标端。
这个方案存在以下优点:
一、数据同步上业务的耦合度也下降了很多,数据层面改动较少,除少量配合otter同步对不同机房db中主键ID的唯一性进行了修复,其它的组件都是外部增加的;
二、⻛险更可控,业务开发更容易理解和维护,以后想增加机房或者数据同步种类都比较方便。
架构v1.5的不足在于:
数据清理、维护分开处理,这过程中可能会产生不一致性。
v2.0
在1.5投入运行后,我们继续规划实现了2.0架构。该架构主要变更了数据同步形式,从通过日志传输请求回放,替换为全部通过数据组件底层工具进行同步,主要通过业务和数据中间的网关代理实现负载路由以及同步管理。除了1.5已经处理的MySQL同步外,其它的如ElasticSearch、Redis、Codis都用了这套代理模式。

ElasticSearch的数据同步是个推自己构建的方案。这个方案中,所有的请求在经过Proxy时都会根据一定策略路由到目标集群,实现了多集群的拆分和管理。进行备份或者迁移的步骤为:首先,准备好备份或者迁移的目标集群(同机房或异地机房),更新配置注册到Proxy上;第二步,对老集群的源数据全量导出到kafka,同时开启增量双写,进入Proxy的请求,如果是要备份的部分,也同时写入kafka中。这样数据在两个集群就形成了热备。故只需要切换路由,就能够实现切换到另一个机房的集群,备份的集群就完全可以提供服务了。
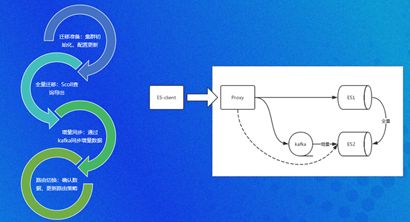
关于Redis和Codis的数据同步,我们调研了两种开源方案,携程的XPipe和Redis-replicator,两者都不能完全满足需求,但其部分理念可被参考,为此,我们最终设计了如下的总体结构图。

我们利用了Redis的主从同步机制,Keeper作为一个从⻆色将主节点同步过来的数据,通过传输通道写到备份集群。
其中,Keeper是数据同步组件,有两种⻆色,一是作为Redis的从节点,二是将数据写入备份的IDC,Keeper的组件由manager管理,传输通道可以直接tcp传输,或者依赖消息队列。IDC故障需要切换时,故障机房的数据层本身不需要做什么操作,只要机房归属的路由切换过来即可。
这个方案的优点在于,在处理业务逻辑时不用考虑多机房同步的相关问题。网关层可以集中实现所有需要的功能,如备份策略、负载策略、调度策略、监控、隔离、权限等等。美中不足的是一定程度上增加了网关层的开发和维护成本。
03
总结和展望
企业要想为用户提供稳定的保障服务,容灾工作一定要做到位。我们无法预见线上环境什么时候会出现问题,一般来讲,尤其是当集群规模比较大的情况下,小事故是非常高频的。当然容灾也要结合成本的考量,选择适合业务发展情况的架构方案,想要一开始就设计出非常完美但费钱的方案只会拖垮业务。因此,个推的容灾方案就是根据业务发展一步步迭代进行的。
除考虑自身业务外,企业在进行异地灾备建设时还应深刻洞悉行业发展趋势:
采用多地多活,加快业务恢复速度;将服务虚拟化,使灾备可以更灵活地调配资源;实现业务连续性管理。
个推作为异地灾备领域的长期实践者,也将持续探索灾备理念,不断打磨技术,与开发者一同分享异地灾备系统建设的最新思路及方法。
完整版分享材料获取
关注【个推技术学院】微信公众号
(微信号:getuitech)
回复关键词“推送”
即可领取异地灾备完整版分享材料!
此外,通过视频链接还可观看本文配套解析:
http://live.vhall.com/649915969