大数据hadoop工具
导入文件 :
yum install -y lrzsz
导出文件 :sz 文件
杀掉所有的进程
jps -q | xargs kill
rpm -qa|grep ntp
sudo service ntpd status
chkconfig
yum install ntp ntpdate
hadoop -dfs -appendToFIle - /test/a 1234 标准追加
hdfs配置文件 先以
1:java代码配置为主
2:寻找resource下面的hdfs.xml
3:寻找maven包下的
filesystem .for
.sout
无法迭代删除

是因为名称要写成fs -rmdir -R /hello
为什么要序列化?
是因为数据需要网络传输
Java 序列化: 完整 序列化结构和数据
Hadoop序列化:

制表符和空格区别
mapper到reducer
1:根据传入的反射对象进行创建一个空的对象
2:再调用readfiled方法
ctrl+H:可以查看抽象类的实现类
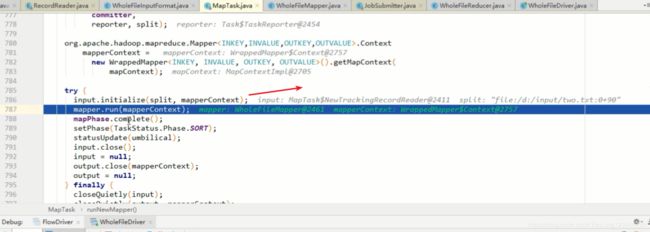
initialize 会调用fileInputstream中的WholeFilerecorderader 中的intialize方法

调用wholeFilerecordreader 中的 nextKeyValue 和getcurrentkey 和current value
Inputformat 默认实现TextFInputFormat 所以要用Longwritable
快速排序算法
冒泡排序
归并排序
时间复杂度
空间复杂度
& | 运算符
MapTask 714
溢出之后进行分区 排序
二次排序 分区排序 key排序
相同key 会进入同一个区
如果设置分区数量为1 会返回0 不会设置分区

default
Long
equals: return false;永远不相等
为什么是nullwritable ?
combiner合并: 一边合并 一边排序
在环形缓冲区中:分区和排序是同时进行的
先compare 分组 然后再进行 reducetask
环形缓冲区: key和value一起写的
定义变量的时候到底是定义什么比较好 
\r\n


因为需要用orderBean排序所以要将orderbean放到key 里面
如果实体类中的属性已经做了排序 那么就不要放到

包装流意义:
集群中的数据 要么一起成功 一起失败
 如果三台成功也是成功?
如果三台成功也是成功?
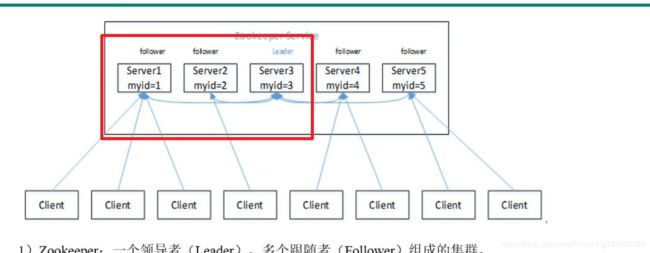
zookeeper的节点既是文件也是文件夹
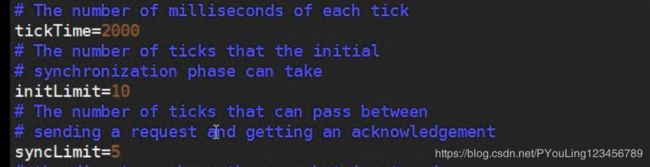
tickets time 时间 单位
看视频了解这几个参数的意思

为什么需要在env.sh 中添加JAVA_HOME ?
是为了方便与之后群启动时候能获取读到JAVA_HOME参数

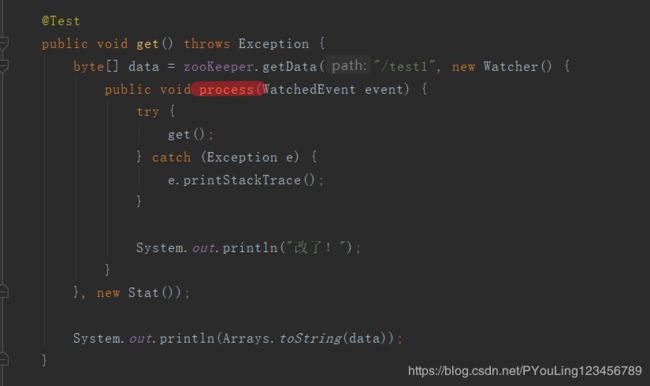
上图表示 在执行process时候是在监听 ,如果监听到数据变化才会调用 。
选举机制 :先比较zxid 再比较myid zxid 从 get中可以获取
写数据流程需要重新听
shuffle流程 重新
split brain 脑裂 两个集群都可以读写数据 非常严重的问题 要避免
在zookeeper写数据时 如果其中一台服务器挂掉了 写数据没有超过半数会发生什么?
会将写数据从队列中
HA缺陷: 手动设置active 和standby
如果active挂掉 standby不知道active有没有挂掉 .
解决方案: zookeeper
为什么两个namnode 通信不靠谱?
zkfc Failover controller zookeeper客户端 :
不能破坏 原有Namenode的健壮性 robust 性
作用
1:负责和zookeeper进行沟通
2: 监控namenode
3:
如果一台挂掉了 zookeeper 服务端通知zkfc 然后zkfc 通知另外一个namenode上位
将状态修改为active
zkfc client 如果挂掉了
那么另外一个zkfc 会检测另外一个namnode 的状态
然后将状态修改为standby 然后将自己的namnode修改为active
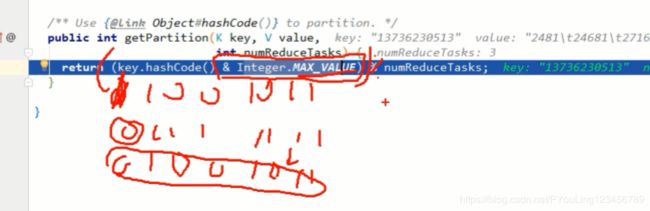
二次排序:分区排序 key排序
分区: 相同的key会进入同一个分区
分组不会按照equals分组 只会按照
combiner:
比如文件
一个maptask : A1 1 A1 1 A1 1 A2 1 A2 1
第二个maptask:A1 1 A1 1 A2 1 A2 1 A2 1
那么maptask1 合并后的结果 :A1 3 A2 2 -------》 局部汇总
maptask2 合并后的结果 :A1 2 A2 3 ----------》》 局部汇总
最后reduce的结果 A1 5 A2 5
map:将数据转换为我们想要的形式
所以重点的面试题一定要背!就和考试一样对待 !
开发为辅助!
配置隔离方式:
hadoop lib:本地库
shell: jar包
sbin
bin
rpm -qa | grep mysql qa query all
sudo rpm -e --nodeps + 数据库名字 : 强制卸载
sudo rpm
external:额外的
clustered:分统表
truncate table student;没有删除表 只是删除了数据 ;
正则表达式:
A&B A和B按位取与
A|B A和B按位取或
A^B A和B按位取异或
~A A按位取反
分区是不指定分区进行插入? 不可以
分区查询可以不指定分区名称么? 不可以
外部表使用场景是共享数据
是否修改分区名?
如果删除分区名称是否会删除库数据?
重看:10:00 - 10:20
shell 企业试题:
hadoop企业试题:
shuffle
hdfs上传下载
11:40-11:46
distribute by sorts by 区别?
create table stu_buck(id int, name string)
clustered by(id) 为什么要用clustered by
into 4 buckets
row format delimited fields terminated by ‘\t’;
如何在beeline 中查看metastore数据库 ?无法查看metastore的表结构