虽然切片数越多,启动的maptask就越多,并行运行执行效率越高。但凡事都有个度,万一切片过多,也会影响执行效率
@目录
- 执行流程
- CombineTextInputFormat
- 切片流程
- 案例
执行流程
Job-->MRAppMaster-->RM-->调度队列-->NM-->Container-->MapTask
可以看见,从job提交到执行maptask,中间还会经历很多过程。这时候需要将很多小文件合并切片,提高执行效率。
CombineTextInputFormat
- 作用: 改变了传统的切片方式,将多个小文件,划分到一个切片中,适合小文件过多的场景。
RecordReader:LineRecordReader,一次处理一行,将一行内容的偏移量作为key,一行内容作为value
数据类型
LongWritable key
Text value
切片流程
- 先确定片的最大值
maxSize,maxSize通过参数mapreduce.input.fileinputformat.split.maxsize设置,单位是byte - 以文件为单位,将每个文件划分为若干
part
①若文件的待切部分的大小 <=maxSize,整个待切部分作为一个part
②若maxsize<文件的 待切部分的大小 <=2* maxSize,将整个待切部分均分为两个part
③若文件的待切部分的大小 >2* maxSize,先切去maxSize大小,作为一个part,剩余待切部分继续从①开始判断
④分完part后,将之前切分的若干part进行累加,累加后的大小超过maxSize,则作为1片
案例
有四个小文件

它们的总大小为
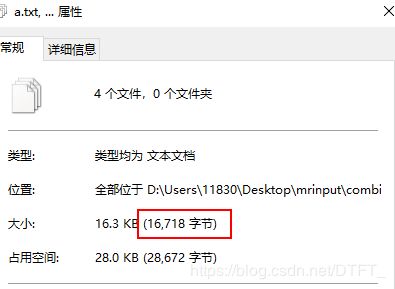
如果将maxSize设置为2048byte,那么
a.txt 4,486 字节
part1(a.txt,0,2048) ------part1刚好2048byte,则切为第一片
part2(a.txt,2048,1219)
part3(a.txt.3xxx,1219)-------1219+1219超过2048,则把part2和part3切为第二片
b.txt 4,287 字节
part4(b.txt,0,2048)-----第三片
part5(b.txt,2048,1116)
part6(b.txt,3267,1116)-------part5+part6第四片
c.txt 2779 字节
part7(c.txt,0 ,1389.5)
part8(c.txt,1389.5 ,2779)-------part7+part8第五片
d.txt 5,166 字节
part9(d.txt,0,2048)-------第六片
part10(d.txt,2048,1559)
part11(a.txt.3607,1559)-------part10+part11第七片
WCMapper.java
public class WCMapper extends Mapper{
private IntWritable out_value=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
System.out.println("keyin:"+key+"----keyout:"+value);
//context.write(key, out_value);
}
}
WCReducer.java
public class WCReducer extends Reducer{
private IntWritable out_value=new IntWritable();
// reduce一次处理一组数据,key相同的视为一组
@Override
protected void reduce(Text key, Iterable values,
Reducer.Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable intWritable : values) {
sum+=intWritable.get();
}
out_value.set(sum);
//将累加的值写出
context.write(key, out_value);
}
}
WCDriver.java
public class WCDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("e:/mrinput/combine");
Path outputPath=new Path("e:/mroutput/combine");
//作为整个Job的配置
Configuration conf = new Configuration();
// 设置maxsize为2048byte
conf.set("mapreduce.input.fileinputformat.split.maxsize", "2048");
// 设置输入格式
conf.set("mapreduce.job.inputformat.class", "org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat");
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①创建Job
Job job = Job.getInstance(conf);
job.setJarByClass(WCDriver.class);
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
// Job需要根据Mapper和Reducer输出的Key-value类型准备序列化器,通过序列化器对输出的key-value进行序列化和反序列化
// 如果Mapper和Reducer输出的Key-value类型一致,直接设置Job最终的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 声明使用NLineInputFormat
//job.setInputFormatClass(NLineInputFormat.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// ③运行Job
job.waitForCompletion(true);
}
}
切片结果:

果真是七片!