python 3.x爬虫 晋江小说下载(使用requests和xpath获取内容,使用cookie获取VIP章节)
前言
在下作为一个女生,当然喜欢在晋江上看小说,奈何晋江这个网站十分神奇,文章说锁就锁,不得已之下,只能自己写一个爬虫程序,用来保存小说……
我一开始是选择txt格式保存小说的,后来决定以epub格式保存小说了。因为我发现,同样是一本小说,epub格式不仅功能丰富、界面美观,还比txt格式的文件小很多……如果把小说以ASCII编码保存,大小是小了不少……又会丢失一部分字符……
我也同样会把下载txt格式文件的源码放出来,不过那个版本很久没更新了,bug什么的自然多。
该项目存放在github里,最近计划用c#把程序重新写一遍。
(这个程序是我东拼西凑搞出来的,本来是写给自己用的,根本没想到写博客。虽然能跑起来,跑的还挺不错,但是命名非常不规范,大家不要学我。)
https://github.com/7325156/jjdown
python库
需要安装以下的库
- pip install requests
- pip install lxml
- pip install selenium #用来获取cookie,可以不安装
- pip install opencc-python-reimplemented #繁简转换,可以不安装
获取cookie
cookie中存放用户登录信息,如果要爬取已购买的vip章节,必须把cookie添加到头部。
获取cookie的方法有很多种,这里建议登录晋江网站后,按F12进入开发者模式后,在console(控制台)界面输入document.cookie,按回车,获取cookie。
注意事项:晋江的cookie有时会失效,如果失效,建议使用IE浏览器或者Edge浏览器重新获取cookie,如果还不行,把cookie里"timeOffset_o"一项删除。
以下是获取cookie的程序,我觉得没什么用,用起来麻烦,优化的还不够,大家看看就好,想用也可以将就着用。
用之前要下载chormedriver,放在python路径下。
from selenium import webdriver
import time
#此处需要安装chormedriver ,并存放到python路径下
driver=webdriver.Chrome()
driver.delete_all_cookies()
driver.get("http://my.jjwxc.net/login.php")
username=input("请输入用户名:")
passwd=input("请输入密码:")
driver.find_element_by_id("loginname").send_keys(username)
driver.find_element_by_id("loginpassword").send_keys(passwd)
driver.find_element_by_xpath("//*[@id='login_submit_tr']/input").click()
cookies = driver.get_cookies()
cookies_list= []
for cookie_dict in cookies:
cookie =cookie_dict['name']+'='+cookie_dict['value']
cookies_list.append(cookie)
header_cookie = ';'.join(cookies_list)
headers = {
'cookie':header_cookie,
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
print(headers)
driver.quit()将cookie添加到头部,获取所有章节和卷标
cookie后面的冒号中直接粘贴获取到的cookie
headerss={'cookie': ' ',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}txt_id为文章编号。晋江的每一篇小说都有编号,编号就是网址最后面跟着的数字。我随便举个例子,若小说网址为http://www.jjwxc.net/onebook.php?novelid=2710871,那么2710871就是小说编号。
使用requests添加头部向网址发送请求,再对文章重新编码,如果不编码,会输出一堆乱码。
#获取文章网址
req_url=req_url_base+ids
#通过cookie获取文章信息
res=requests.get(req_url,headers=headerss).content
#对文章进行编码
ress=etree.HTML(res.decode("GB18030","ignore").encode("utf-8","ignore").decode('utf-8'))
接下来使用xpath获取文章信息。xpath的规则大家有兴趣可以了解一下,不过我这里用了最简单粗暴的办法。
使用谷歌浏览器-->把鼠标移到需要获取的元素的位置上,右键-->检查-->把鼠标移动到要获取的标签上,右键-->Copy-->Copy xpath。搞定。
只需要把获取到的xpath粘贴到指定位置上,把双引号换成单引号,就可以了。
注意事项:谷歌浏览器要把tbody标签删除。
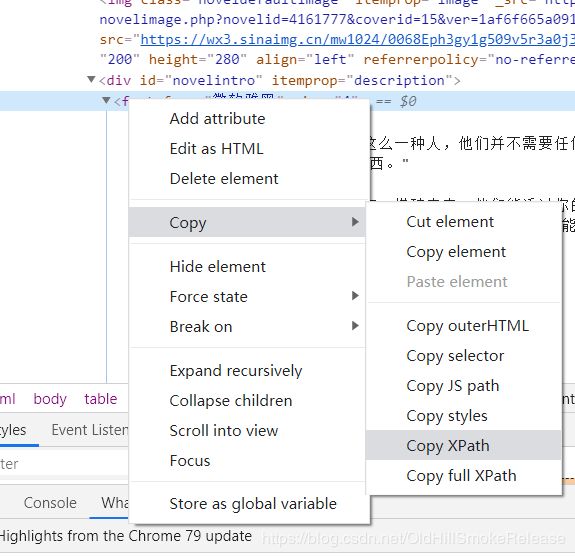
这里使用xpath获取信息,如果想多获取一点,也可以适量修改。非vip章节和vip章节要分开获取。
#获取文案
intro=ress.xpath("//html/body/table/tr/td[1]/div[2]/div[@id='novelintro']//text()")
#获取标签
info=ress.xpath("string(/html/body/table[1]/tr/td[1]/div[3])")
#获取文章信息
infox=[]
for i in range(1,7):
infox.append(ress.xpath("string(/html/body/table[1]/tr/td[3]/div[2]/ul/li["+str(i)+"])"))
#获取封面
cover=ress.xpath("string(/html/body/table[1]/tr/td[1]/div[2]/img/@src)")
#获取标题
titlem=ress.xpath("//html/head/title/text()")
#获取所有章节链接
#非vip
href_list=ress.xpath("//html/body/table[@id='oneboolt']//tr/td[2]/span/div[1]/a/@href")
#vip
hhr=ress.xpath("//html/body/table[@id='oneboolt']//tr/td[2]/span/div[1]/a[1]/@rel")
由于晋江经常出现章节被锁等现象,所以获取内容提要和卷标后需要操作一番。我个人认为这个地方处理的还不够,以后接着优化。
#每章内容提要
#loc:被锁章节
loc=ress.xpath("//*[@id='oneboolt']//tr/td[2]/span/div[1]/span/ancestor-or-self::tr/td[3]/text()")
Summary=ress.xpath("//*[@id='oneboolt']//tr/td[3]/text()")
for i in Summary:
if i.strip()=='[此章节已锁]':
del Summary[Summary.index(i)]
for i in Summary:
if i.strip()=='[此章节已锁]':
del Summary[Summary.index(i)]
for i in Summary:
if i in loc:
del Summary[Summary.index(i)]
for i in Summary:
if i in loc:
del Summary[Summary.index(i)]
for i in Summary:
if i in loc:
del Summary[Summary.index(i)]
#获取卷标名称
rollSign=ress.xpath("//*[@id='oneboolt']//tr/td/b[@class='volumnfont']/text()")
#获取卷标位置
rollSignPlace=ress.xpath("//*[@id='oneboolt']//tr/td/b/ancestor-or-self::tr/following-sibling::tr[1]/td[2]/span/div[1]/a[1]/@href")
rollSignPlace+=ress.xpath("//*[@id='oneboolt']//tr/td/b/ancestor-or-self::tr/following-sibling::tr[1]/td[2]/span/div[1]/a[1]/@rel")
保存文章信息
接下来对获取的信息进行处理,并存储。
#对标题进行操作,删除违规字符等
ti=str(titlem[0]).split('_')
ti=ti[0]
ti=re.sub('/', '_', ti)
ti=re.sub(r'\\', '_', ti)
ti=re.sub('\|', '_', ti)
ti=re.sub('\*','',ti)
xxx=ti.split('》')
xaut=xxx[1].strip()#文章名
xtitle=re.sub('《','',xxx[0]).strip()#作者名
v=""
#打开文件夹,以便进行epub打包
path=os.getcwd()
if os.path.exists(ti):
os.chdir(ti)
else:
os.mkdir(ti)
os.chdir(ti)
index=[]
#如果文案未被审核,保存封面图片
if img!="0":
pic=open("p.jpg",'wb')
pic.write(img)
pic.close()
#写入封面xhtml页
f=open("C.xhtml",'w',encoding='utf-8')
f.write('''
cover  ''')
f.close()
#写入文章信息页
fo=open("TOC.xhtml",'w',encoding='utf-8')
fo.write('''
''')
f.close()
#写入文章信息页
fo=open("TOC.xhtml",'w',encoding='utf-8')
fo.write('''
'''+ti+''' ''')
fo.write(""+titlem[0]+"
")
index.append(titlem[0])
for ix in infox:
ix=ix.strip()
ix=re.sub('\r\n','',ix)
ix=re.sub(' +','',ix)
fo.write(""+ix+"
")
fo.write("文案:
")
for nx in intro:
v=re.sub(' +', ' ', str(nx)).rstrip()
if state=='s':
v=OpenCC('t2s').convert(v)
elif state=='t':
v=OpenCC('s2t').convert(v)
if v!="":
fo.write(""+v+"
")
info=re.sub(' +', ' ',info).strip()
if state=='s':
info=OpenCC('t2s').convert(info)
elif state=='t':
info=OpenCC('s2t').convert(info)
info=re.sub('搜索关键字','搜索关键字',info)
fo.write("
"+info+"
")
fo.write("")接下来保存每一章的内容,初始化数据,调用以下函数,函数实现以后再写。
count=0
#获取每一章内容href_list保存所有章节链接,Summary保存每一章的内容提要
for i,sum in zip(href_list,self.Summary):
self.get_sin(i,self.headerss,sum,fillNum,rollSign,rollSignPlace,index,state)
fo.close()下载完毕后打包成epub
input("\r\n请按回车键打包epub:")
#保存为epub
os.chdir(path)
epub_name = ti+".epub"
epub = zipfile.ZipFile(epub_name, 'w')
EPUB.epubfile.create_mimetype(epub)
EPUB.epubfile.create_container(epub)
os.chdir(ti)
ppp=os.getcwd()
EPUB.epubfile.create_content(epub,ppp,xtitle,xaut)
EPUB.epubfile.create_tox(epub,ppp,index,rollSign)
EPUB.epubfile.create_stylesheet(epub)
for html in os.listdir('.'):
basename = os.path.basename(html)
if basename.endswith('jpg'):
epub.write(html, "OEBPS/"+basename, compress_type=zipfile.ZIP_DEFLATED)
if basename.endswith('html'):
epub.write(html, "OEBPS/"+basename, compress_type=zipfile.ZIP_DEFLATED)
epub.close()
os.chdir(path)
shutil.rmtree(ppp)
print("\r\n所有章节下载完成")获取并保存单章内容
(以后再写)