Hadoop知识点归纳1
1. * 什么是Hadoop?*
Hadoop 帮助用户在不了解分布式底层细节的情况下,开发分布式程序。
应用领域:
农业、地震台监测、医疗、可穿戴设备、无人驾驶汽车
2. 课程目标
• 了解YARN的基本工作原理
• 了解Hadoop2.0的两大核心模块的工作原理
• 熟悉Hadoop2.0环境搭建、配置与管理
• 熟练向Hadoop提交作业以及查询作业运行情况
• 能书写Map-Reduce程序
• 能熟练地对HDFS中的文件进行管理
一.Hadoop简介
1.为什么需要Hadoop?
·面临的问题:
数据大,读写瓶颈;
用户需求,响应时间;
计算量大。
·解决方案
解决性能瓶颈,SQL;
转移成本。
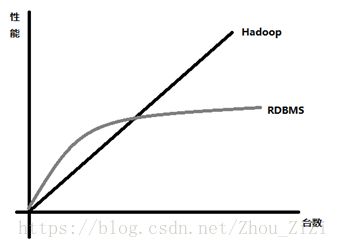
2.关系型数据库和Hadoop的比较

3.集群
定义:
– 集群是一组相互独立的、通过高速网络互联的计算机,它们构成了一个组,并以单一系统的模式加以管理。
– 一个客户与集群相互作用时,集群像是一个独立的服务器
作用:
– 在付出较低成本的情况下获得在性能、可靠性、 灵活性方面的相对较高的收益
目的:
– 提高性能
– 降低成本
– 提高可扩展性
– 增强可靠性
场景:
– 科学集群
– 负载均衡集群
– 高可用性集群(银行常用)
集群的构建:
– 硬件角度:节点机系统、通讯系统、存储系统等
– 软件角度:操作系统、集群操作系统 (COS)、并行环境、编译环境和用户应用软件等
关键技术
– 任务调度——进程迁移
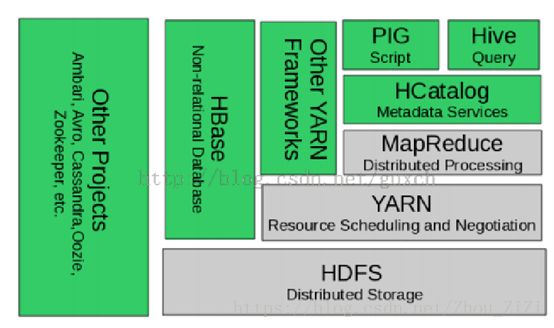
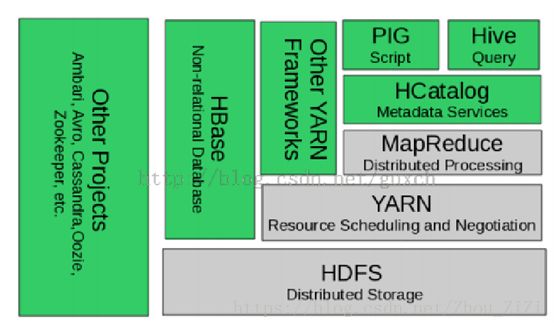
4. * Hadoop2.0生态系统 *
Hadoop自身包括:
• Hadoop Common: hadoop的基础
• Hadoop Distributed FileSystem (HDFS): 分布式文件系统
• Hadoop YARN: 集群任务资源管理及任务调度的框架
• Hadoop MapReduce: 基于YARN的分布式计算
与hadoop相关的产品大致上分为两大部分:
• 数据服务(Data Services)
– HBase: 将文件建于HDFS上的分布式KeyValue数据库
– Hive: 有比较友好接口(相对来讲)的数据仓库,它实际上是基于MapReduce的一个应用。
– Pig:它使用一个叫做“Pig Latin”的东西来作为 用户交互语言,底层依然是MapReduce。它与 Hive有类似之处,都是用来做大数据处理,但它似乎比Hive要简单一些,没有“存储”的概念(metadata,“表”等), 接口也少。
– HCatalog:这是一个hadoop数据管理层,你 可以用Hive, Pig , MapReduce等来存取 hadoop的数据,而不用关心这些数据是如何存 储的。
• 运行维护(Operational Services)
– ZooKeeper:分布式应用协调器。
• 其他相关产品/项目:
– Mahout: 机器学习和数据挖掘
– Spark:内存计算
– Storm:实时计算
• Hadoop2.0中各种产品的相互关系
5. Hadoop基础知识
1)Hadoop 1.0
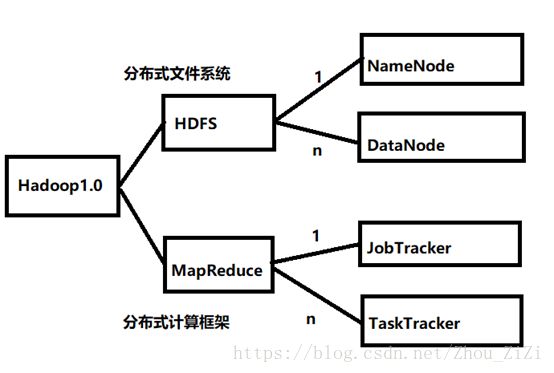
NameNode:
HDFS的守护程序
① 记录文件如何分割;
② 记录数据块被存储到哪些节点之上;
③ 对内存和I/O集中管理
JobTracker:
① 具体计算
决定哪些文件参与
② 资源调度
任务分配(对TT作业的分配)
监控TT(重启,另分配)
TaskTracker:
启动多个JVM虚拟机执行MapReduce
DataNode:
负责把HDFS中的数据读取到本地系统文件中

2)Hadoop 2.0
①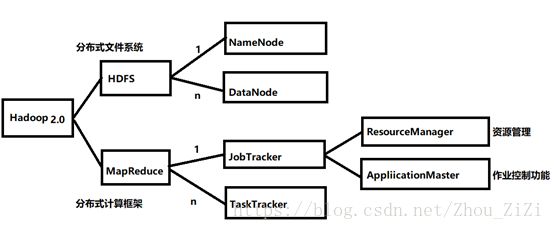
② 1.0中NameNode制约HDFS的扩展性,导致单点故障
2.0引入了HDFS Federation
*(1.0到2.0的飞跃)
③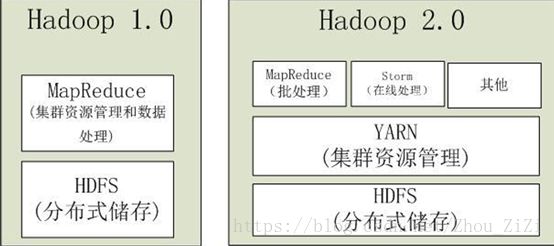
·Spark 不是分布式处理框架,除了搭载Hadoop使用;
·通用资源管理器:YARN、Mesos;
·若用1.0搭载Storm、Spark,缺点(YARN的优点):①数据不好交换;②资源浪费;③人力资源成本高。
6.
1)MapReduce1.0或MRv1
MRv1中计算框架为三个部分:
• 编程模型——Map和Reduce函数组成
• 数据处理引擎——Map Task和Reduce Task组成
• 运行环境——一个JobTracker和多个 TaskTracker组成
2)MRv2
• 与MRv1相同的编程模型和数据处理引擎,不同的是运行环境
• MRv2是在MRv1基础上经过加工后,运行于资源管理框架YARN之上的计算框架 MapReduce
• 由通用资源管理系统YARN和作业控制进程 ApplicationMaster来完成相应工作
7. YARN
• Hadoop2.0中的资源管理系统,是一个通用资源管理模块,可为各类应用程序进行资源管理和调度
• YARN不仅限于MapReduce一种计算框架, 也可供其他框架使用,如Spark、Storm
• 由于YARN的通用性,下一代MapReduce的核心已从简单的支持单一应用的计算框架转移到通用资源管理系统上
8. HDFSFederation
• Hadoop2.0对HDFS进行了改进,使 NameNode可以横向扩展成多个,每个 NameNode分管一部分目录,进而产生了 HDFS Federation
• 该机制的引入不仅增强了HDFS的扩展性, 也使HDFS具备了隔离性
(Hadoop适合处理少量大数据,不适合处理大量小数据)