电商项目日总结(第十天搜索实现SpringDataSolr)
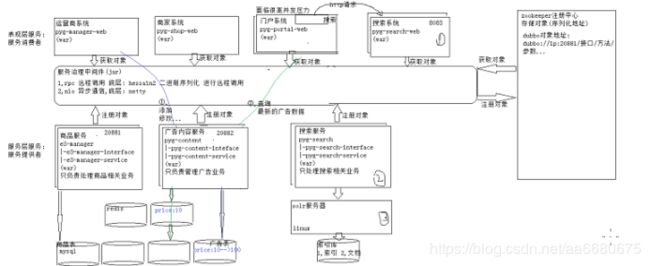
1.在pyg_parent父模块下新建了3个与搜索相关的子模块

满足了项目分布式的开发
pyg_search_web模块的pom文件中:
war
com.fighting
pyg_search_interface
1.0-SNAPSHOT
com.fighting
pyg_pojo
1.0-SNAPSHOT
org.apache.tomcat.maven
tomcat7-maven-plugin
2.2
9104
/
在resources的spring目录下导入springmvc.xml配置文件,并在webapp下引入静态資源

pyg_search_service的pom文件中:
war
com.fighting
pyg_search_interface
1.0-SNAPSHOT
com.fighting
pyg_pojo
1.0-SNAPSHOT
org.apache.tomcat.maven
tomcat7-maven-plugin
2.2
9004
/
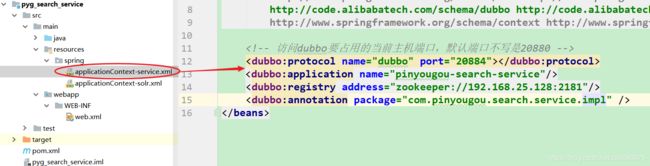
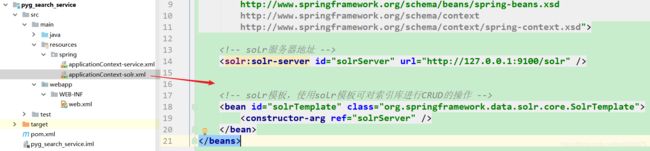
在resources目录下的spring目录下导入配置文件applicationContext-service.xml和applicationContext-solr.xml
2.在本机的Tomcat上部署了solr
首先要将Tomcat的端口号改为9100
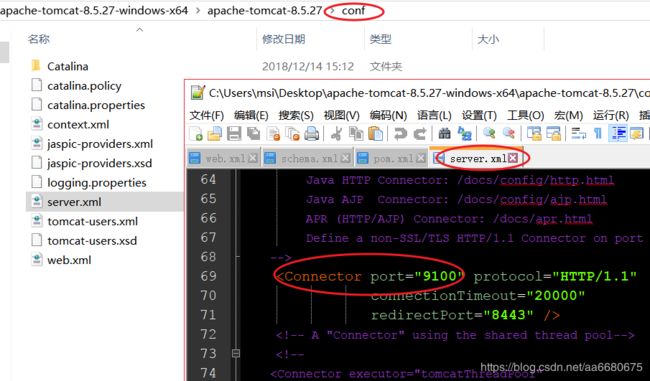
在本机的windows系统上的Tomcat上部署了solr-4.10.3.war,然后改名为solr.war
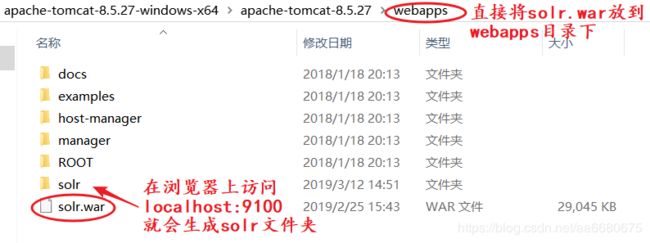
将这些jar包到tomcat中的solr的\WEB-INF\lib目录下

在E盘上创建solrhome(solr的数据存储位置,相当于solr的数据库)文件夹
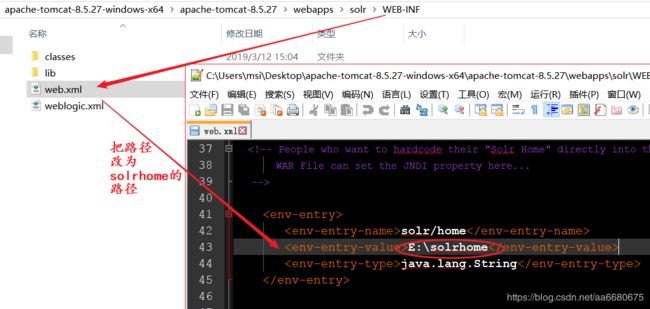
注意,以上配置改完之后,需要重启Tomcat服务器
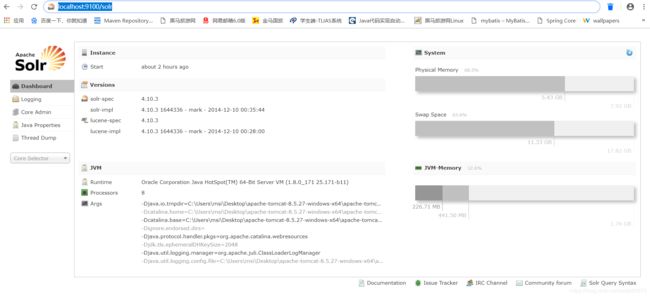
在浏览器上访问http://localhost:9100/solr,若成功,则出现一下界面:
3.中文分析器IK Analyzer的安装
将中文分词器IKAnalyzer.jar的jar包拷贝到\WEB-INF\lib目录下
\WEB-INF创建classes目录,并拷贝mydict.dic、IKAnalyzer.cfg.xml、ext_stopword.dic
在solrhome\collection1\conf修改schema.xml(在配置文件的最下方)加入配置
测试http://localhost:9090/solr/#/collection1/analysis将FieldType改成text_ik查看效果
4.域配置
在本地solrhome目录的collection1的conf下的schema.xml中增加3种域
普通域:这种域一般用来去solr库中存储数据
//name:字段名称 type:字段类型 stored:是否存储分词前内容(复制域选择false) required:是否必填 indexed:索引(是否进行查询)
复制域:不占用存储空间,只是逻辑上等于其他几个域的总和(复制域一般用来做搜索查询)
//multiValued 是否有多值 stored="false" 不需要存储
动态域:
//因为数据中的item_spec_后面的内容不固定所以用*号代替
5.向solr种批量导入数据
在pyg_parent父模块下新建一个子模块pyg_solr_util
pyg_solr_util的pom文件:
com.fighting
pyg_dao
1.0-SNAPSHOT
applicationContext-solr.xml中配置:
SolrUtil.java工具类:
@Component
public class SolrUtil {
@Autowired
private SolrTemplate solrTemplate;
@Autowired
private TbItemMapper itemMapper;
@Test
public void importItemData(){
//获取所有SKU列表的信息
List itemList = itemMapper.selectByExample(null);
for (TbItem item : itemList) {
System.out.println(item.getTitle());
}
//将所有的SKU列表信息保存到solr的域中
solrTemplate.saveBeans(itemList);
//提交
solrTemplate.commit();
}
public static void main(String[] args) {
//加载所有配置文件
ApplicationContext ac = new ClassPathXmlApplicationContext("classpath*:spring/applicationContext*.xml");
SolrUtil solrUtil = ac.getBean(SolrUtil.class);
solrUtil.importItemData();
}
}
运行main方法就可以将查询到的所有SKU表的数据信息存到solr的数据库中
6.完成pyg_search_web模块中的search.html页面的展示以及搜索
search.html页面效果展示

search.html中:
引入js文件
body标签
搜索栏部分
SKU商品展示数据绑定
searchController.js中
//初始化searchMap
$scope.searchMap={keyWords:'三星'};
//查询SKU商品
$scope.itemSearch=function () {
searchService.itemSearch($scope.searchMap).success(
function (response) {
$scope.itemList=response.content;
}
)
}searchService.js中
//查询SKU商品
this.itemSearch=function (searchMap) {
return $http.post('itemSearch/search.do',searchMap);
}ItemSearchController.java中
@RestController
@RequestMapping("/itemSearch")
public class ItemSearchController {
@Reference
private ItemSearchService itemSearchService;
//因为要把页面传递过来的json格式的转成对象,用RequestBody
@RequestMapping("/search")
public Map search(@RequestBody Map searchMap){
return itemSearchService.itemSearch(searchMap);
}
}ItemSearchServiceImpl.java中
@Service//注意这个Service是dubbo这个jar里的
public class ItemSearchServiceImpl implements ItemSearchService {
@Autowired
private SolrTemplate solrTemplate;
@Override
public Map itemSearch(Map searchMap) {
//先接收页面穿过来的关键字
String keyWords = (String) searchMap.get("keyWords");
System.out.println(keyWords);
Map map=new HashMap();
//如果页面的关键字不为空,就去solr库中进行查询
if (keyWords != null) {
SimpleHighlightQuery simpleHighlightQuery = new SimpleHighlightQuery();
//参数需要传域的名字(从solr库中查的时候需要从复制域中查)
Criteria criteria = new Criteria("item_keywords");
//前面需要加上criteria
criteria=criteria.contains(keyWords);
simpleHighlightQuery.addCriteria(criteria);
//高亮查询
HighlightPage highlightPage = solrTemplate.queryForHighlightPage(simpleHighlightQuery,TbItem.class);
List itemList = highlightPage.getContent();
//content需要和searchController.js中的返回值相对应
map.put("content",itemList);
}
return map;
}
}