版权申明:本文为博主窗户(Colin Cai)原创,欢迎转帖。如要转贴,必须注明原文网址 http://www.cnblogs.com/Colin-Cai/p/11900470.html 作者:窗户 QQ/微信:6679072 E-mail:[email protected]
人工智能(AI)是目前IT最前沿的领域之一,而深度学习(Deep Learning)则是AI中最火热的方向。深度学习是指深度的神经网络,这主要是因为网络深了之后才可以表现更广阔的意思,而神经网络最基本的问题是分类问题。本文从神经网络开始起,讲讲深度学习分类网络的发展历史以及其中用到的技术。
人工智能很早就有研究,一度分为三大学派——符号派,行为派,连接派。符号派,认为符号演绎是AI的本质,Lisp/prolog这些都是符号派的杰作;而行为派更加偏向于对行为的分析,像遗传进化模型、人工蚁群、粒子群、强化学习(人工蚁群实际上是强化学习的特例)等。而本文既然讲深度学习,自然是连接派的研究成果。目前,也的确是连接派发展的最好,但未来的AI个人怀疑是三大学派的合流。
神经网络
上世纪初,人们发现并研究大脑神经元,

知道了神经元是用树突的信号传递信息,并构成如下网状的环境。

神经网络的历史很早,早在1943年就由McCulloch和Pitts根据大脑神经元的生物现实提出了神经网络的概念,这是仿生学的开始。
神经网络的单个神经元看成几个输入量的函数,这里所有的单个输入量、输出量都是标量,考虑到通用性以及计算的方便,主流上基本只考虑以下这样的模型的神经元:
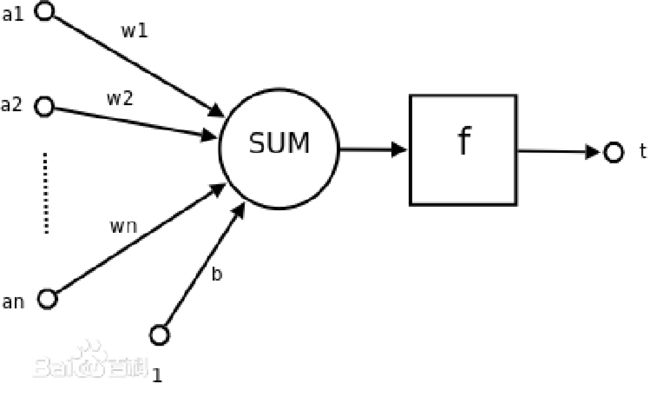
$t=f(b+\sum_{i=1}^{n}a_{n}*b_{n})$
这里的SUM是各个输入的加权和(weighted sum),而f称之为激励函数(activation function)。此函数相当于用各个权值(weight)表示各个输入信号参与的程度,而b是先天加上的一个偏置(bias),了解一些神经网络的朋友会马上明白神经网络的训练连实际上就是训练各个神经元的权值和偏置。
而这里的激励函数,也很重要。前面加权值是线性的,如果所有的神经元都表现的是线性关系,那么所有信号的渐变只会导致最终输出信号的渐变,这种平稳的渐变不符合我们实际的需要,我们一般需要的并非是这种非渐进的东西,而更加需要突变的东西,比如这样的跃迁函数
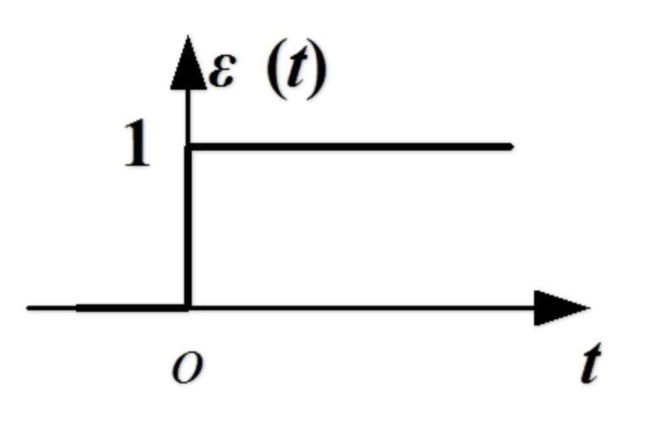
但是这里就有一个一类间断点,而连续对于神经网络很重要(后面会说明),一类间断点和二类间断点很多时候是灾难,于是一般我们采用别的函数来模拟跃迁函数这样的“瞬变”。比如sigmoid函数和tanh函数,他们有着类似于下面的图像:
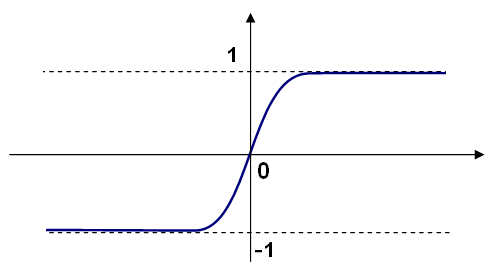
中间过渡带的宽度可以由权值来调节。
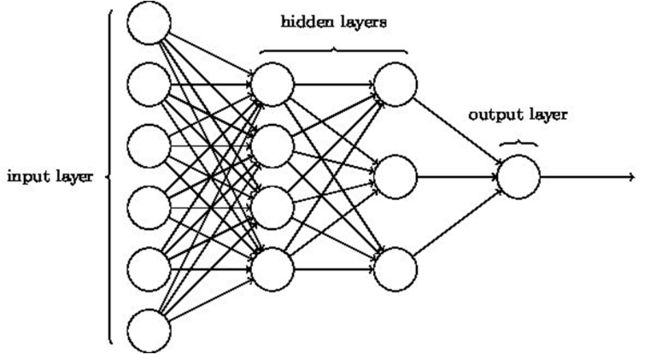
神经网络由多个神经元构成,以下为单层神经网络:
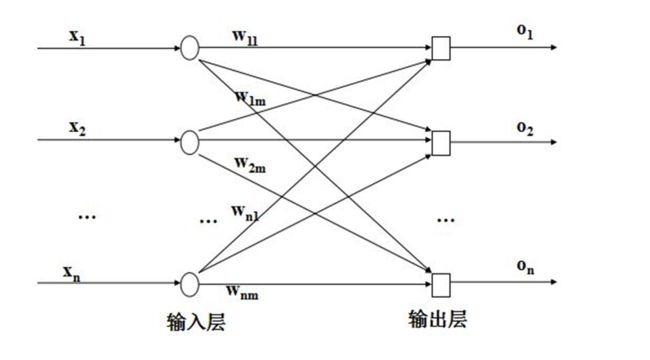
有单层自然有多层,以下为多层:
乃至各种各样的经典神经网络
神经网络的学习
既然神经网络要拿来使用,就得学习,在这里,我们只考虑监督学习。
所谓监督学习,就仿佛是“填鸭式教学”,目的是希望举一反三。作为监督导师,事先准备了n个问题,给出了n个标准答案,把这n个问题和n个标准答案教给AI模型(至于怎么教随意),然后不再教学,希望AI模型可以解决这n个问题之外的问题。
神经网络为了可学习,对于每次学习的问题,定义了自己推理结果和标准答案之间的距离,称之为损失(loss),这和其他的一些AI模型有着很大的差别(比如KNN、DT等)。
常用的有MSE损失函数,这个是从曲线拟合的最小二乘法就开始使用了,为神经网络实际推理结果和标准答案各维度之差的平方值的平均。
$MSE(Y,y)=\frac{1}{2n}\sum_{i=1}^{n}(Y_{i}-y_{i})^2$
其中1/2n是取平均,因为对于具体网络这个是一个常数,从而可以忽略。
另外,交叉熵也很常用,
$C(Y,y)=\sum_{i=1}^{n}Y_{i}*log(y_{i})+(1-Y_{i})log(1-y_{i})$
而我们训练的目的是为了loss尽可能的小,从而推理结果更接近于实际预期结果。
于是我们把loss看成是所有要训练参数的函数,
$loss=F(w_{0},w_{1},...,w_{n})$
于是,我们希望loss最小,实际上发生的时候,所有的
$\frac{\partial F}{\partial w_{m}}=0$
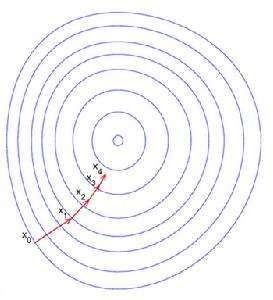
很早的时候,人们就创造了一个梯度下降算法,也就是按照梯度
$(\frac{\partial F}{\partial w_{0}},\frac{\partial F}{\partial w_{1}},...\frac{\partial F}{\partial w_{n}})$
的反方向依次下降到梯度为零的地方附近,这样的方向调整参数最快达到目标。
又因为神经网络是一级一级的,所有loss表示为各个weight的函数其实是一堆函数的符合函数,求导满足链式规则,各个weight的梯度分量可以根据链式规则从后往前计算,于是人们给了它一个名字叫反向传播(Backpropagation)。
卷积神经网络
我们再来看看上面这个多层感知器,每一层所有输入和输出之间都存在连接,这叫全连接。
(1)全连接参数过于多,网络很容易变的非常重,不利于让网络往深度方面去发展。
(2)再者,全连接直接是一种图像整体关系的处理。而生活的经验和基于信号处理的传统图像处理告诉我们,对图像的识别往往取决于局部。也就是说,图像的识别、处理等往往依据的是图像局部的逻辑性,而不是一堆杂乱无章的像素点。
(3)同样的理由,全连接对于图像的平移、旋转等变换完全没有任何感觉,也就是不具备平移不变性、旋转不变性。
于是我们得找一种新的方法,那就是卷积(convolution)。
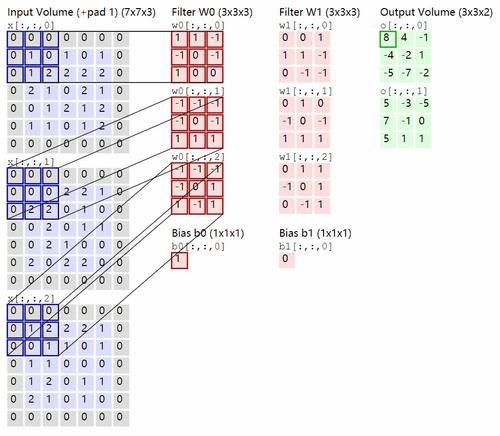
引用了卷积之后,神经网络的连接比全连接要少的多,并且带上了平移不变性,但不带有旋转不变性,从此卷积神经网络(CNN)成为了神经网络主流。
而网络各层求导的链式规则,乘积项随着层数的增加而增加,使用传统的激励函数,因为激励函数的导数大多情况接近于0,很容易陷入梯度消失,过渡带的导数很大会导致可能存在另外一个极端梯度爆炸。这些对于参数训练都是很不利的,要么学习缓慢,要么跳跃过大。
于是,我们用以下称为Relu的激励函数来代替
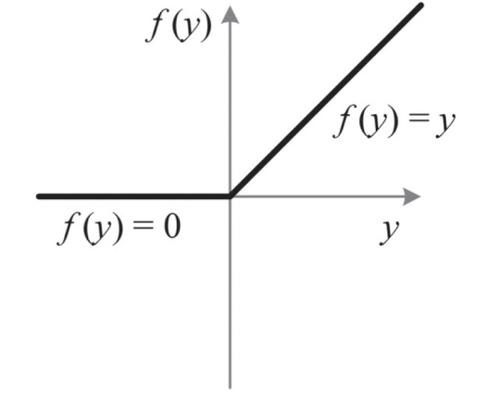
乃至还有一些别的变种,比如PRelu、LRelu等。
另外,引入了池化这样的降维操作,这在降维的同时多少为网络带来了一定的旋转不变性。
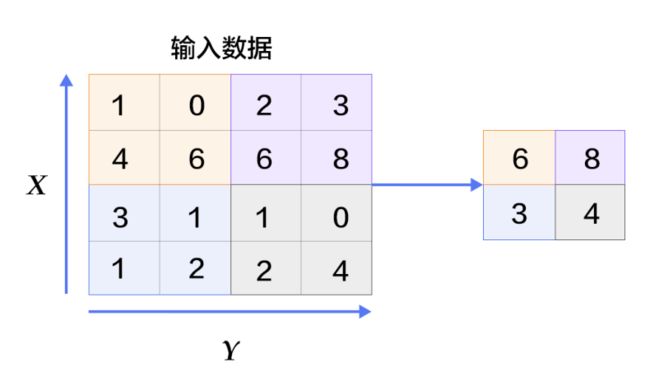
上面就是一个最大池化,有的时候也会用到平均池化,但要注意,最大池话是非线性操作,使用的场合可能会多一些。
于是,以上卷积神经网络的基本零件已经有了,由卷积、激励函数、池化等构成了特征提取层,用于产生必要的特征信息,而使用一层或多层的全连接用于逻辑输出,称为逻辑层。

而作为分类系统,一般来说,最终输出采用one-hot编码,这样比较对称。也就是,如果是n分类,网络最终输出就是一个n维向量。
LeNet
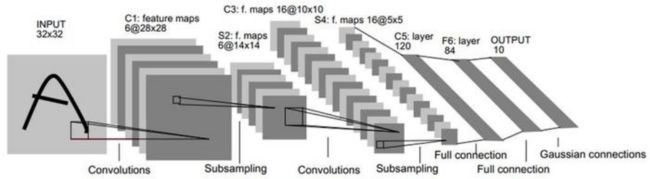
卷积网络早期的经典,用于处理手写识别。 LeNet用的都是5x5的卷积核,每个卷积后面跟一个2x2的不重叠的最大池化。
另外,C3层是对16个14x14的featuremap分批卷积的。论文描述了这样做的好处:
(1)参数减少
(2)非对称结构有利于提供多种组合特征
顺便提一下,著名的minist数据集就是一个手写识别0-9这10个数字的数据集,一般用于入门。
虽然对于英文手写识别系统可以很好的应用,但是该网络并不太适用于不断出现的新的应用。
对于LeNet的扩展也未必那么容易,从而迫切需要新的改良出现,以便适用于不断出现的引用。
ImageNet从2010年开始的ILSVRC竞赛也为所有团队提供了动力。
于是,DL技术就这样开始不断进步了。
AlexNet
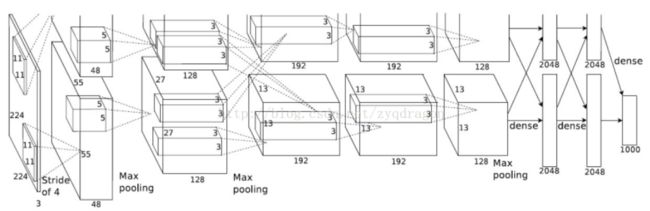
AlexNet是2012年ILSVRC的冠军,这是一个参数很多的网络,第一个卷积层的卷积核是11x11,后面的全连接很大,它有很多创新点:
(1)这是经典里第一个引入Relu作为激励函数以对抗梯度消失的网络。
(2)特征提取层理有上下两个独立的group,从而可以并行,作者就是在特征提取里使用两个GPU来并行工作。
(3)采用局部相应归一化LRN(Local Response Normalization),这是受真实的神经网络启发之后产生归一化的思想。归一化的思想说白了就是用多个输入张量统一调整调整当前输入张量,归一化之前,整体的BP学习算法对于稍微深一点的网络甚至不太现实,最开始的深度学习模型都是一层一层学习的,归一化思想让整体的BP学习成为了现实。
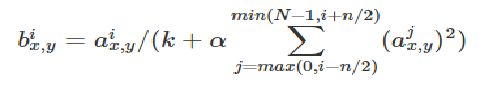
虽然后面出现的网络VGG的作者就发现LRN似乎对VGG没有什么作用,现在LRN作为一种技术已经很少使用甚至淘汰,但是归一化的思想却一直都在。
(4)不同于LeNet的最大池化尺寸2x2步长2,引入重叠池化,最大池化尺寸3x3步长2,虽然产生了基本一样尺寸的输出,但实验表示,这样的效果会好一些。
(5)引入dropout学习机制,在学习过程中随机抛弃全连接层(逻辑层)的部分神经连接,以减少过拟合(overfitting)。
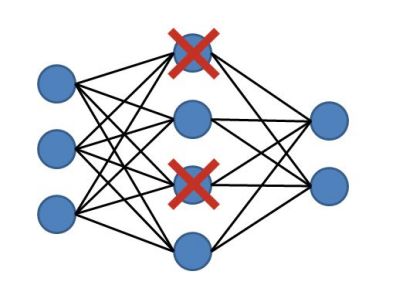
以上基本上都是AlexNet独立的开创,为后面网络产生了很大的影响。
GoolgLeNet
你没有想错,这个网络是Google设计的,作为AI的先驱,Google是必然有份的。另外,里面有个L大写,我也没有写错,那是Google为了向经典网络LeNet致敬。
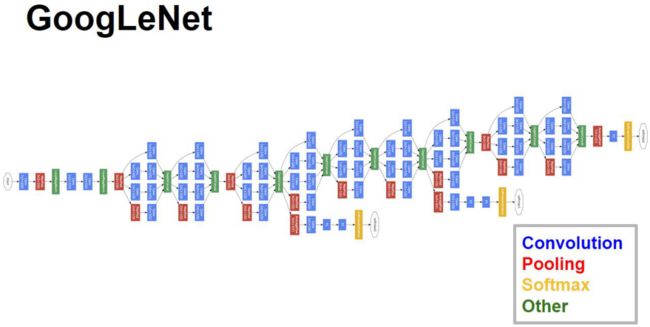
GoogLeNet作为2014年ILSVRC的冠军,是模块化设计的经典之作。
模块化在于它创造了以下这样称为Inception的模块
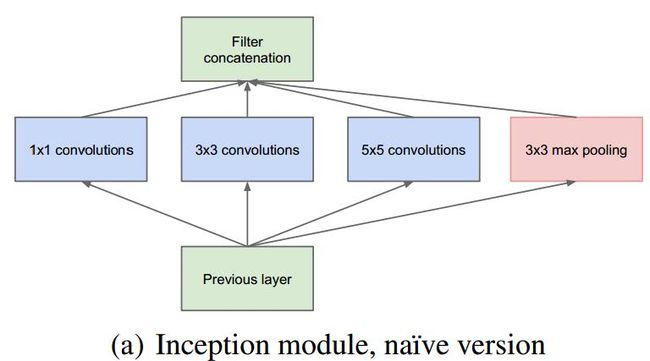
图像的识别有个视野问题,于是Inception采用1x1、3x3、5x5卷积乃至3x3最大池化是对于型相同的feature map不同的视野,不同尺度的特征提取。再拼接在一起,这样,不同尺度的特征提取就放在一起了,这样的思想的确很赞。
之后,为了降低参数数量,采用1x1卷积来降维,从而模块变成了这样:
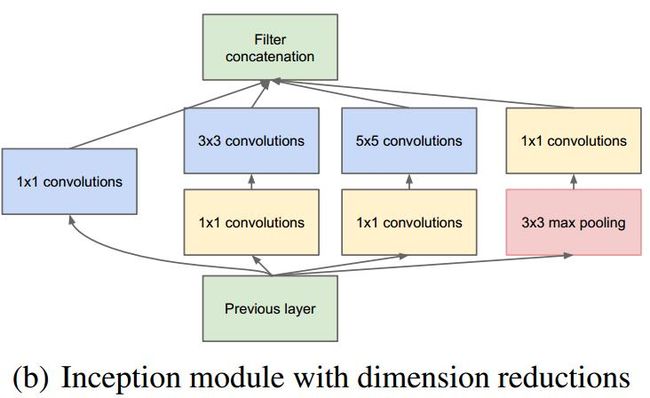
模块化的设计思想,便于网络修改。GooLeNet用平均池化代替了全连接,但为了方便大家fine-tune,最终还是提供了一个全连接层。dropput依然在此网络中使用。为了对抗梯度消失,网络中间引入了两个辅助的softmax输出用于观察,所以我们看到整个网络上面还有两个输出。
归一化的思想依旧得到延续,Inception V2里创造了Batch Normalization,用于替代之前的LRN。

将n张输入张量(图片)组成一个称之为mini-batch的东西,用每个张量相同位置的值来统一归一化每个张量在这个位置的值。
BN成了后来神经网络的标配,一直延续了下来。
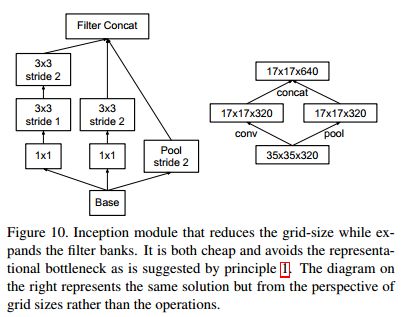
在接下来的版本Inception V3里,继续想办法减少参数,缩小网络规模。
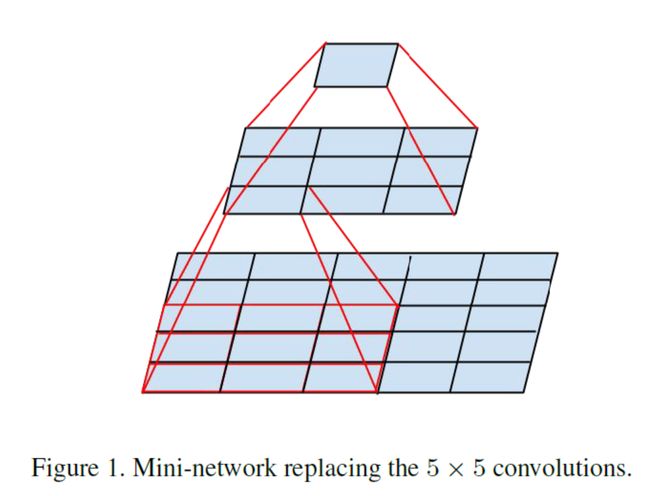
上面就是用两个3x3卷积核来替代一个5x5的原理,两个3x3的视野和5x5的视野一致。
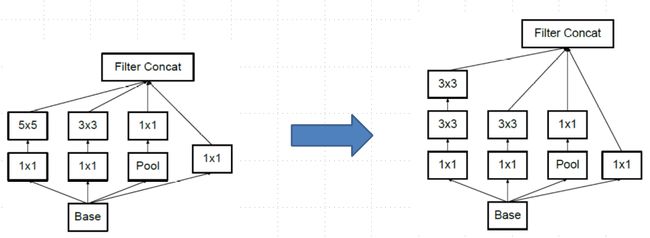
有了这样的尝试,后面的卷积神经网络基本都是3x3的小核,不再使用大核。
这样,仍然不满足,进一步降低参数。
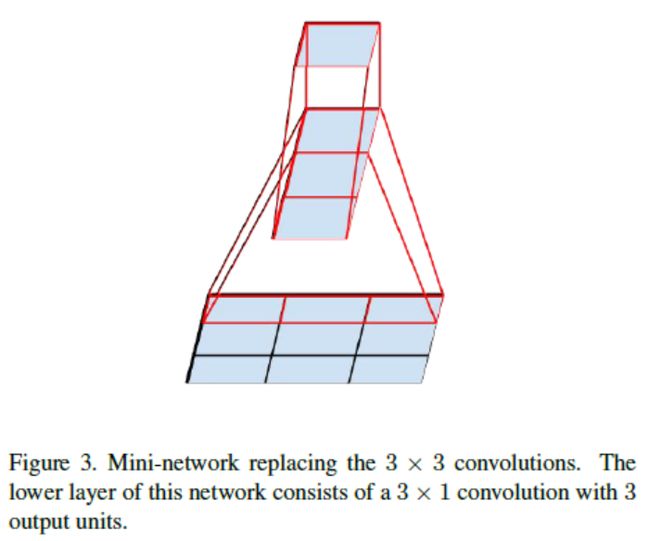
以上用1x3和3x1两个卷积核串联出3x3的视野,进一步降低参数数量。
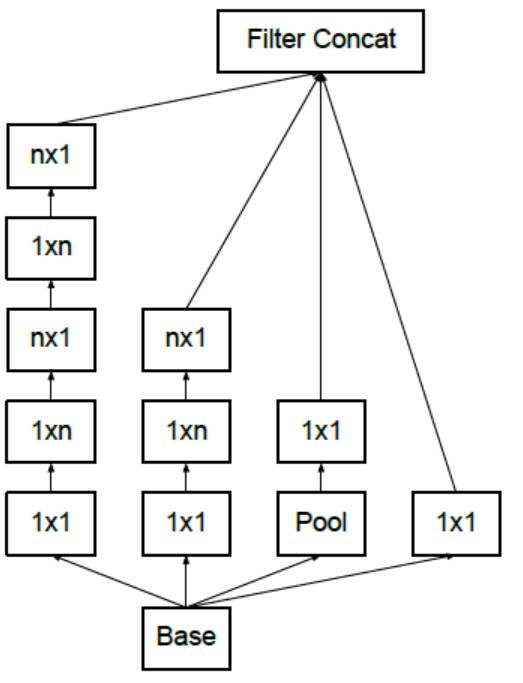
为减少feature map尺寸提供一种双缝结构

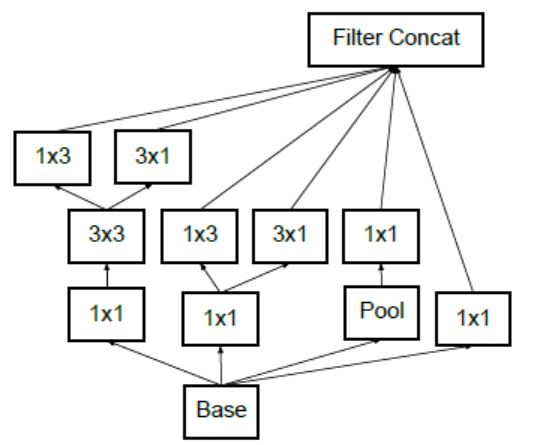
一边卷积过去,另外一侧池化过去,再拼接。
后来,Inception给出了第四个版本,虽然这个版本对模块做了一些固化,但可圈可点的地方不像前三个版本这么多。
ResNet
既然是Deep Learning,自然网络还是奔着深度的方向去的,也只有网络变的更深才可以有更灵活的模拟能力。之前的很多措施,Relu也好,归一化也罢,dropout,切成小核等等,要么是为了防止梯度异常,要么就是为了对抗过拟合,参数过多,然后最终都是想把网络做深以期望更好的效果。
ResNet是第一个真正意义上让Deep Learning名符其实的网络。
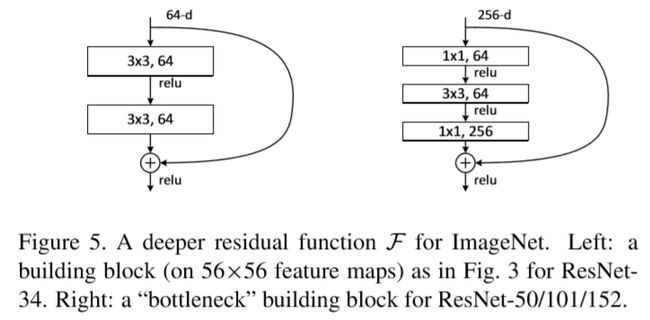
ResNet从残差分析(Residual Analysis)中受到启发,引入残差概念,也就是几层之后的feature map和之前的feature map作和,如图:
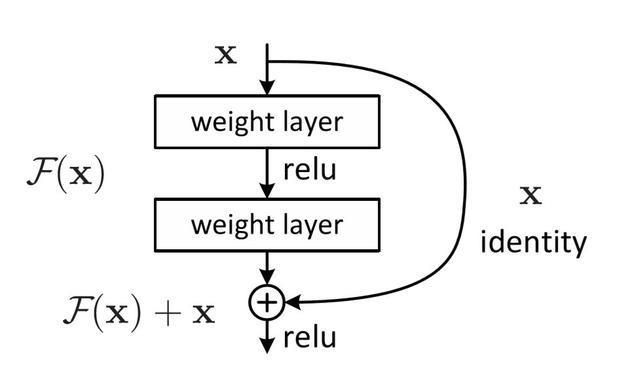
ResNet依然是模块化设计,上面weight layer是卷积层,引入Relu,是为了让F(x)引入非线性因素。单个卷积层做残差没有意义,因为它与单个卷积是等价的。
当然,也可以适用更深层次的残差模块,加法跨越的层次可以更多一点。
为什么可以实现真正意义上的深度学习呢?说白了,我们最根源的需求是为了对抗梯度消失才可以使得网络变深而可学习
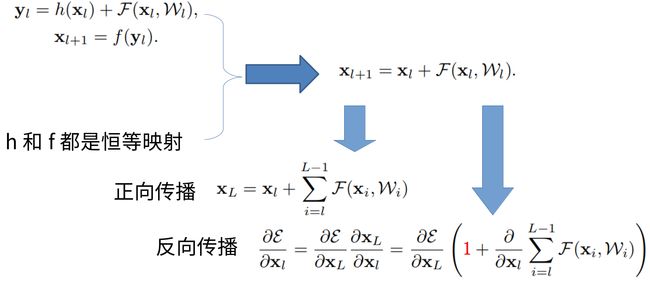
而上面链式求导规则里的这个后面的红色的1,就是防止梯度消失秘密武器的原理。
引入上述结构极大程度减缓了梯度消失的发生,从而可以把网络做的更深。从此,开启了爆走模式。
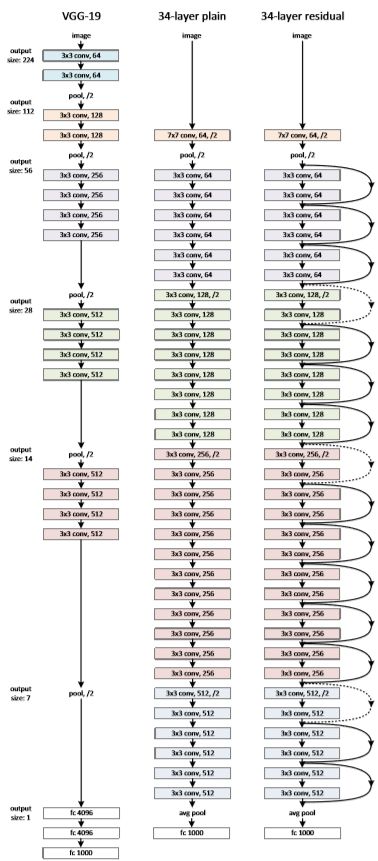
由此,百层网络也不再是大问题。
ResNet V2相比V1有了一些模块上的改动
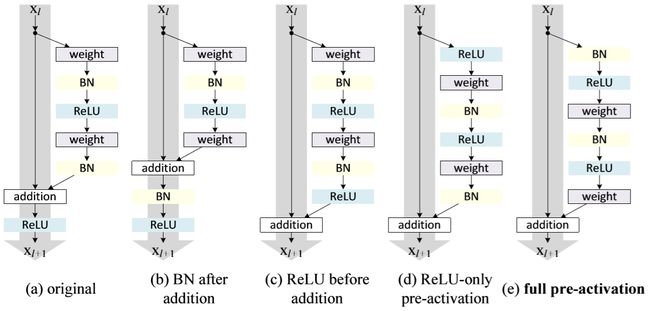
但这些都不是大的本质变化,而ResNet的参差方法却一直被后世的网络引入,从此神经网络真正意义上进入了Deep Learning时代。
网络发展方向
随着嵌入式的发展,很多AI的应用可以放到嵌入式设备上面来,因为嵌入式设备的资源限制,这就迫切的使得网络要往计算量、数据量轻量级的方向发展。
实际上,硬件资源是有限的,运算速度也是追求的方向,我们在GoogLeNet上就看到了为参数缩减所做的努力。
后面的出现的一些轻量级网络某些程度上是希望“掏空”神经元,从而往着参数更加少的方向进行,但同时而网络graph更加复杂意味着网络的表达能力更加强大。
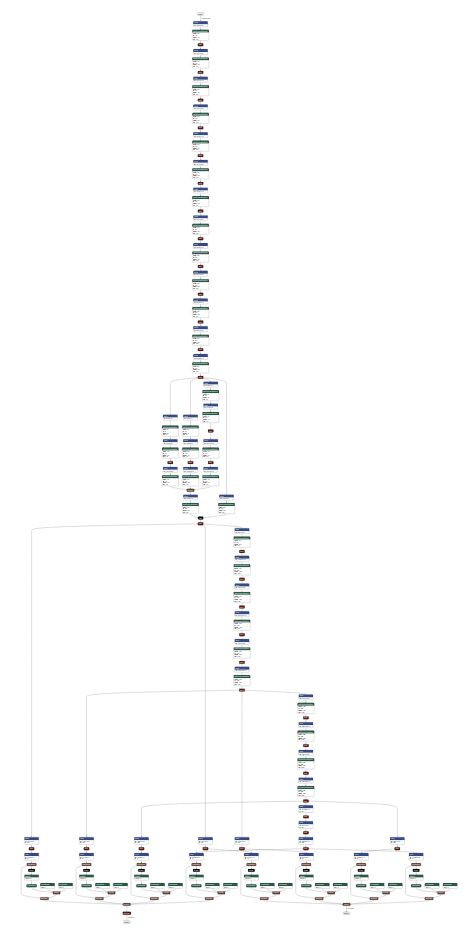
以上是一个目标检测(Object Detection)的小型网络,可以看出其网络的连接比直线型的要怪异很多,参数虽少,但网络更为复杂。
DenseNet
受Resnet的启发,提出了dense block模块,每个dense block里的任何两层之间都有连接,从而有着比ResNet更加密集的残差,
以下是一个dense block
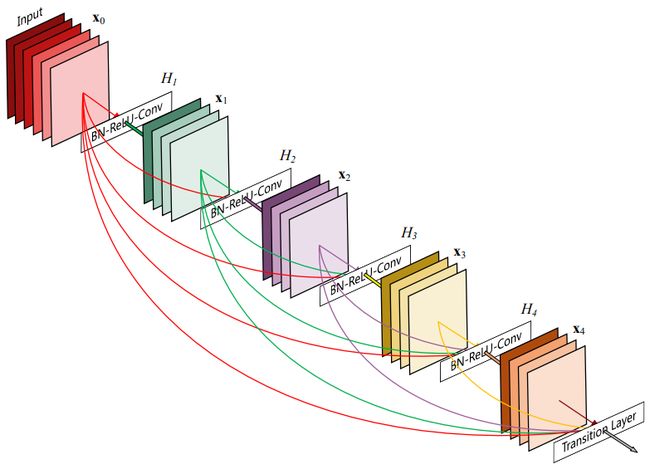
整个网络是由数个dense block以及其他的卷积、池化、全连接等层拼接而成:

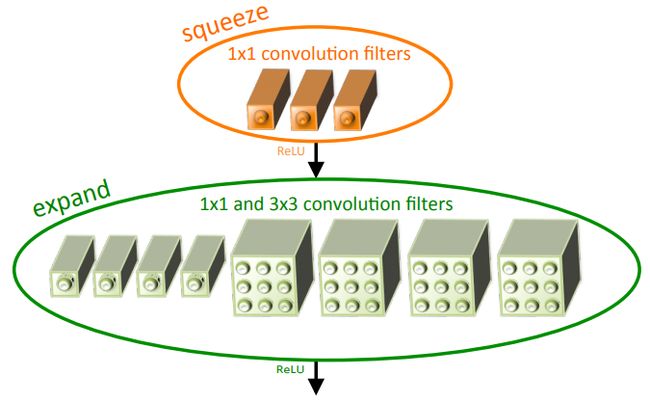
SqueezeNet
SqueezeNet引入了一个叫Fire Module的模块,用的都是小尺寸卷积,甚至1x1卷积。
同样受ResNet启发,引入bypass结构,本质上就是ResNet的Residual block
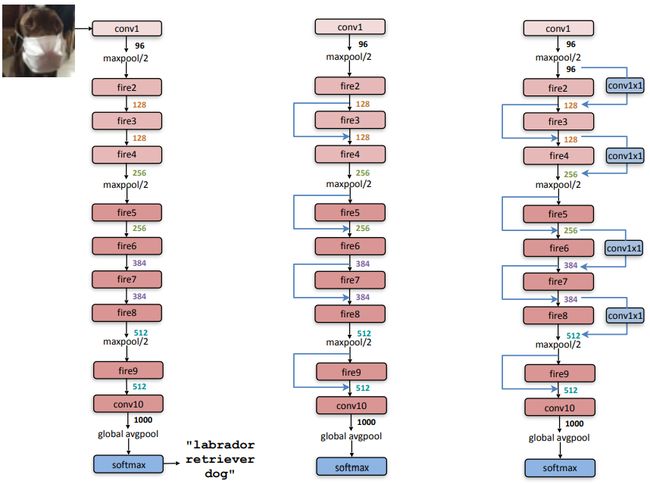
MobileNet
MobileNet改造了卷积,引入了Depthwise Convolution。
普通卷积为大家所熟悉,对于每个卷积核,所有的源feature map都参与卷积,计算量较大。
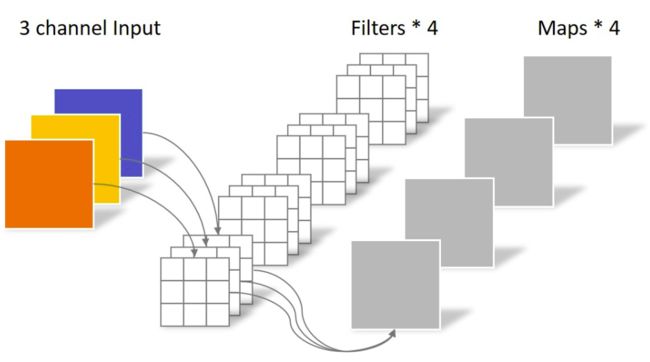
而depthwise卷积长这样
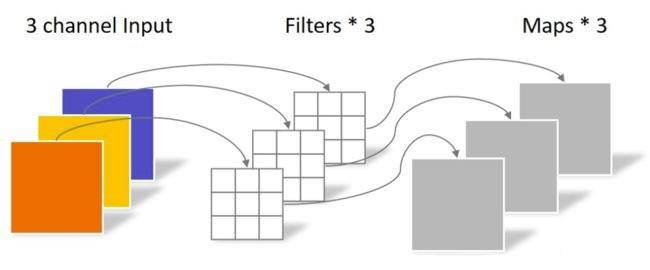
卷积核就这么被降维了,一个featuremap单独产生一个featuremap,卷积不改变featuremap个数,不同featuremap之间在卷积中不产生直接作用。
如果想改变featuremap个数,可以在后面接上Pointwise Convolution,说白了就是1x1卷积核的卷积。
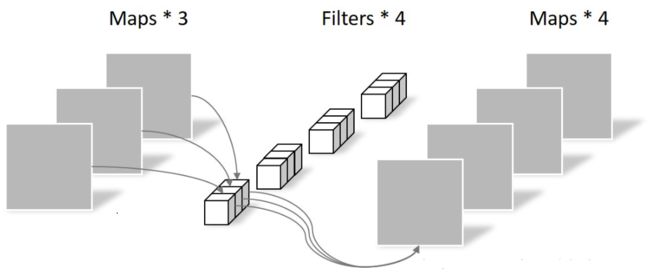
因为Depthwise Convolution的参与,MobileNet做到了更少的参数。而Depthwise Convolution本质上是Group Convolution的极端形式,所谓Group Convolution就是把传入的featuremap分组,然后每一组以普通卷积的形式计算,然后整体输出。然而,Group Convolution此时也并非新概念,早在AlexNet时,我们回忆一下这两个并行,实际上就是Group Convolution。
甚至在LeNet中的C3层里,Group Convolution就已经在使用。
MobileNet这是一种在嵌入式上使用较多的网络,被使用在了各种场合,所以叫MobileNet。
ShuffleNet
ShuffleNet也一样,引入DepthWise Convolution和Group Convolution。
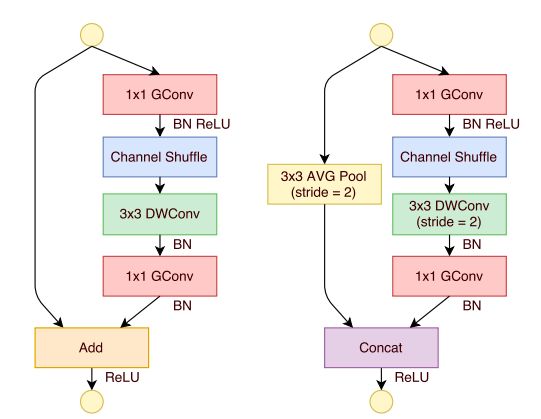
之所以叫ShuffleNet,在于网络从中间引入shuffle,将各组feature map重新分组送入下一轮分组卷积
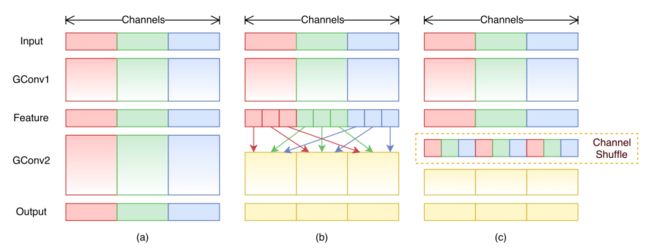
之前MobileNet采用1x1卷积将不同的featuremap关联在一起,而这里只是简单的用shuffle来进行信息渗透,不产生计算量,以之达到类似的效果。
结尾
一些前期网络开发的技术会被后期的网络继续传承,而效率不高的技术会导致淘汰或被修改。
目前DL很火热,未来的AI技术会是什么样子?神经网络是我们终极的AI模型吗?符号主义、行为主义、连接主义最终会彻底的互相渗透吗?让我们拭目以待。