简介
pgpool-II 是一个位于 PostgreSQL 服务器和 PostgreSQL 数据库客户端之间的中间件,它提供以下功能:
- 连接池
pgpool-II 保持已经连接到 PostgreSQL 服务器的连接,并在使用相同参数(例如:用户名,数据库, 协议版本)连接进来时重用它们。它减少了连接开销,并增加了系统的总体吞吐量。
- 复制
pgpool-II 可以管理多个 PostgreSQL 服务器。激活复制功能并使在2台或者更多 PostgreSQL 节点中 建立一个实时备份成为可能,这样,如果其中一台节点失效,服务可以不被中断继续运行。
- 负载均衡
如果数据库进行了复制,则在任何一台服务器中执行一个 SELECT 查询将返回相同的结果。pgpool-II 利用了复制的功能以降低每台 PostgreSQL 服务器的负载。它通过分发 SELECT 查询到所有可用的服务 器中,增强了系统的整体吞吐量。在理想的情况下,读性能应该和 PostgreSQL 服务器的数量成正比。 负载均很功能在有大量用户同时执行很多只读查询的场景中工作的效果最好。
- 限制超过限度的连接
PostgreSQL 会限制当前的最大连接数,当到达这个数量时,新的连接将被拒绝。增加这个最大连接数 会增加资源消耗并且对系统的全局性能有一定的负面影响。pgpoo-II 也支持限制最大连接数,但它的 做法是将连接放入队列,而不是立即返回一个错误。
- 并行查询
使用并行查询时,数据可以被分割到多台服务器上,所以一个查询可以在多台服务器上同时执行,以减 少总体执行时间。并行查询在查询大规模数据的时候非常有效。
pgpool-II 使用 PostgreSQL 的前后台程序之间的协议,并且在前后台之间传递消息。因此,一个(前端的)数据库应用程序认为 pgpool-II 就是实际的 PostgreSQL 数据库,而后端的服务进程则认为 pgpool-II 是它的一个客户端。因为 pgpool-II 对于服务器和客户端来说是透明的,现有的数据库应用程序基本上可以不需要修改就可以使用 pgpool-II 了。
架构图
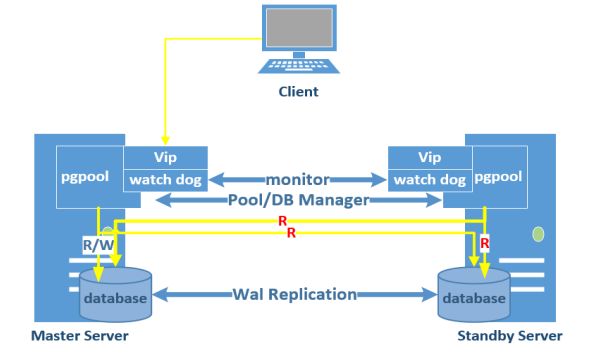
下面进行实验。
实验开始前,关闭所有服务器的防火墙以及selinux。
数据库配置
1.配置master端
1)配置pg_hba.conf文件
local all all trust
host all all 127.0.0.1/32 trust
host all all 192.168.0.0/16 trust
host all all ::1/128 trust
host replication all 192.168.100.0/24 trust2)配置postgresql.conf文件
log_destination = 'stderr'
logging_collector = on
log_directory = 'pg_log'
log_filename = 'postgresql-%Y-%m-%d.log'
log_duration = on
log_error_verbosity = default
log_line_prefix = '%m'
log_statement = 'all'
wal_level = hot_standby
archive_mode = on
archive_command = 'cp %p /usr/local/pgsql/archive/%f'
max_wal_senders = 3
hot_standby = on2.进行一次基础备份
1)重启数据库服务
2)开启热备
psql -c "select pg_start_backup('backup');"3)基础备份
[root@master pgsql]# tar zcf data.tgz data 4)关闭热备
[postgres@master bin]$ psql -c "select pg_stop_backup()"5)复制数据至standby
[root@master pgsql]# scp data.tgz 192.168.100.140:/usr/local/pgsql2.配置standby端
1)停止数据库
[postgres@slave bin]$ ./pg_ctl -D ../data stop2)删除data目录,解压从master端拷贝过来的data.tgz
[root@slave pgsql]# rm -rf data
[root@slave pgsql]# tar -zxvf data.tgz
3)设置recovery.conf
standby_mode = on
recovery_target_timeline = 'latest'
primary_conninfo = 'host=192.168.100.140 port=5432 user=postgres password=####'
trigger_file = '/usr/local/pgsql/trigger_file'4)启动standby
[postgres@slave bin]$ ./pg_ctl -D ../data startpgpool-II安装配置
所有数据库服务,均需安装、配置pgpool-II。
安装前准备:
[root@master ~]#chmod +s /bin/ping
[root@master ~]#chmod +s /sbin/ifup
[root@master ~]#chmod +s /sbin/ip
[root@master ~]#chmod +s /sbin/ifconfig
[root@master ~]#chmod +s /sbin/arping1.安装
1)以root用户创建数据库目录,并配置目录权限
[root@master ~]# mkdir -p /usr/local/pgpool
[root@master ~]# chown -R postgres:postgres /usr/local/pgpool2)配置root用户环境变量(/root/.bashrc文件)
export PATH=$PATH:$HOME/bin:/usr/local/pgpool/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgpool/lib
3)安装
用postgres用户进行安装:
[postgres@master ~]$ cd pgpool-II-3.2.9/
[postgres@master pgpool-II-3.2.9]$ ./configure --prefix=/usr/local/pgpool
[postgres@master pgpool-II-3.2.9]$ make
[postgres@master pgpool-II-3.2.9]$ make install
4)pgpool-II提供了pgpool_recovery、pgpool_remote_start、pgpool_switch_xlog用于在线恢复和启动管理,需要单独编译安装,并在数据库中创建
[postgres@master pgpool-II-3.2.9]$ cd sql/pgpool-recovery/
[postgres@master pgpool-recovery]$ make && make install
[postgres@master pgpool-II-3.2.9]$ cd sql/pgpool-regclass/
[postgres@master pgpool-regclass]$ make && make install
以下在数据库中执行sql的步骤只需在节点master server执行即可,通过流复制会在standby server上同步:
[postgres@master pgpool-regclass]$ cd /usr/local/pgsql/share/contrib/
[postgres@master contrib]$ psql -f pgpool-recovery.sql -U postgres template1
[postgres@master contrib]$ psql -f pgpool-recovery.sql -U postgres postgres
[postgres@master contrib]$ psql -f pgpool-regclass.sql -U postgres template1
[postgres@master contrib]$ psql -f pgpool-regclass.sql -U postgres postgres至此pgpool-II 安装完成。
2.配置
1)启动配置文件pgpool.conf
[postgres@master etc]$ cp pgpool.conf.sample pgpool.conf
修改pgpool.conf文件中的内容:
# - pgpool Connection Settings -
listen_addresses = '*'
port = 9999
socket_dir = '/tmp'
pcp_port = 9898
pcp_socket_dir = '/tmp'
# - Backend Connection Settings -配置后台连接的数据库
backend_hostname0 = '192.168.100.140'
backend_port0 = 5432
backend_weight0 = 1
backend_data_directory0 = '/usr/local/pgsql/data'
backend_flag0 = 'ALLOW_TO_FAILOVER'
backend_hostname1 = '192.168.100.142'
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 = '/usr/local/pgsql/data'
backend_flag1 = 'ALLOW_TO_FAILOVER'
# - Authentication -对连接认证进行配置
enable_pool_hba = on
pool_passwd = 'pool_passwd'
authentication_timeout = 60
# FILE LOCATIONS
pid_file_name = '/usr/local/pgpool/pgpool.pid'
# CONNECTION POOLING 连接池配置
connection_cache = on
# REPLICATION MODE 不起用复制模式
replication_mode = off
# LOAD BALANCING MODE 启用负载均衡模式
load_balance_mode = on
# MASTER/SLAVE MODE 启用主从模式
master_slave_mode = on
master_slave_sub_mode = 'stream' #以流复制模式配置主从
# - Streaming -
sr_check_period = 10 #检查流复制状态周期
sr_check_user = 'postgres' #数据库用户
sr_check_password = '####' #数据库用户密码
delay_threshold = 10000000 #默认值
# - Special commands -
follow_master_command = '' #只有两节点,所以不需要配置该命令
# PARALLEL MODE 不起用并行模式
parallel_mode = off
# HEALTH CHECK 健康状况检查相关参数
health_check_period = 20
health_check_timeout = 10
health_check_user = 'postgres'
health_check_password = '####' #数据库用户密码
health_check_max_retries = 0
health_check_retry_delay = 1
# FAILOVER AND FAILBACK 执行failover脚本
failover_command = '/usr/local/pgpool/etc/failover.sh %d %H /usr/local/hgdb/trigger_file'
failback_command = ''
fail_over_on_backend_error = on
# ONLINE RECOVERY online recovery相关参数
recovery_user = 'postgres' #数据库用户
recovery_password = '####' #数据库用户密码
recovery_1st_stage_command = 'basebackup.sh' #放在脚本$PGDATA目录
recovery_2nd_stage_command = ''
recovery_timeout = 90
client_idle_limit_in_recovery = 0
# WATCHDOG watchdog配置
use_watchdog = on
trusted_servers = '192.168.100.254 #网关,用来判断网络可用性,可以为空
delegate_IP = '192.168.100.160' #虚拟地址,对外提供服务
wd_hostname = '192.168.100.140' #master服务器中,此处填192.168.100.140;slave服务器中,此处填192.168.100.142
wd_port = 9000
wd_interval = 10
ping_path = '/bin'
ifconfig_path = '/sbin'
if_up_cmd = 'ifconfig eth0:0 inet $_IP_$ netmask 255.255.255.0'
if_down_cmd = 'ifconfig eth0:0 down'
arping_path = '/usr/sbin'
arping_cmd = 'arping -U $_IP_$ -w 1'
wd_life_point = 3
wd_lifecheck_query = 'SELECT 1'
# Other pgpool Connection Settings
other_pgpool_hostname0 = '192.168.100.142'#需要监控的对方IP,即master服务器中,此处填192.168.100.142;slave服务器中,此处填192.168.100.140
other_pgpool_port0 = 9999
other_wd_port0 = 90002)启动并修改配置文件pcp.conf:
创建md5密钥:
postgres@master ~]$ cd /usr/local/pgpool/bin
[postgres@master bin]$ ./pg_md5 -p postgres
启用pcp.conf:
[postgres@master etc]$ cp pcp.conf.sample pcp.conf修改pcp.conf文件中的内容:
# USERID:MD5PASSWD
postgres:e8a48653851e28c69d0506508fb27fc5 -->该串字符,即为刚刚生成的md5密钥
3)启用配置文件pool_hba.conf
[postgres@master etc]$ cp pool_hba.conf.sample pool_hba.conf
向文件添加内容如下:
host all all 192.168.100.0/16 trust
设置主机互信
1.root用户互信
[root@master ~]# ssh-keygen -t rsa -P ''
[root@master ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
[root@master ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]2.postgres用户互信
[postgres@master ~]$ ssh-keygen -t rsa -P ''
[postgres@master ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
[postgres@master ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]3.root用户与postgres用户互信
[root@master ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
[root@master ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
[postgres@master ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
[postgres@master ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]pgpool-II管理
1.启动及关闭(root用户)
启动命令:
[root@master ~]# pgpool可以直接启动,不输出调试信息:
[root@master ~]# pgpool -n -d > /tmp/pgpool.log 2>&1 &pgpool在后台,开启debug模式,debug 日志输出到/tmp/pgpool.log 。
关闭命令:
pgpool stop [-m {s[mart]|f[ast]|i[mmediate]}]stop有三个模式:"smart", "fast", "immediate":
smart--等待客户端断开后关闭
fast--不等待客户端断开,立刻关闭
immediate--等同于fast模式
2.任一节点连接pgpool(postgres用户)
[postgres@master etc]$ psql -p 9999查看节点状态:
postgres=# show pool_nodes;
node_id | hostname | port | status | lb_weight | role
---------+-----------------+------+--------+-----------+---------
0 | 192.168.100.140 | 5432 | 2 | 0.500000 | primary
1 | 192.168.100.142 | 5432 | 2 | 0.500000 | standby
(2 rows)
注: status 为 2 ,表示正常连接; 关于 status 状态,如下
0 - show命令不会显示这个状态,因为这个状态仅仅在初始化的过程中使用。
1 - 节点已启动,但没有连接。
2 - 节点已启动,有连接。
3 - 节点down。
3.PCP命令
1)获取节点数(root用户)
[root@master etc]# pcp_node_count 10 127.0.0.1 9898 postgres postgres其中:
- 10为timeout
- 127.0.0.1是pgpool-II所在主机ip,由于时在服务器上执行,所以这里用127.0.0.1。也可以用192.168.100.140或192.168.100.142
- 9898为pcp端口号,在pgpool.conf中配置
- postgres为pcp用户名
- postgres为用户的密码,以上都在pcp.conf中配置。
2)获取节点信息(root用户)
[root@master etc]# pcp_node_info 10 127.0.0.1 9898 postgres postgres 03)从pgpool-II中脱离一个节点(root用户)
[root@master ~]# pcp_detach_node 10 127.0.0.1 9898 postgres postgres 1该命令将节点slave从pgpool-II中脱离。一般如果需要维护某个数据库节点、或不希望pgpool-II将连接分发到该节点时,需要将该节点从pgpool-II中用该命令脱离。
4)为pgpool-II关联一个节点(root用户)
[root@master ~]# pcp_attach_node 10 127.0.0.1 9898 postgres postgres 1该命令将节点slave关联到pgpool-II中。当维护结束,或新添加一个节点后,可以将节点添加到pgpool-II。
另外,如果该节点由于主机或数据库故障导致检测到数据库为启动时,即使后期服务器重新修复、数据库手工启动,也需要执行attach操作。同时需要注意从两个节点上观察是否节点都已经attach。
5)在线恢复一个节点(root用户)
[root@master ~]# pcp_recovery_node 10 127.0.0.1 9898 postgres postgres 1
当某个数据库损坏、新添加一个节点需要同步等情况时,需要对该节点进行recovery。
主节点如果停机,pgpool-II会根据参数failover_command执行failover,将slave触发为主节点。
这时,所有session将重新连接到主节点上。如果需要恢复master,那么可以利用命令:
[root@master ~]# pcp_recovery_node 10 127.0.0.1 9898 postgres postgres 0执行成功后master将做为从节点,而slave是新的主节点。
负载均衡
1.连接到pgpool上,创建一张表,插入两条记录,如下:
postgres=# create table test01(id int,note text);
CREATE TABLE
postgres=# insert into test01 values(1,'11111');
INSERT 0 1
postgres=# insert into test01 values(2,'22222');
INSERT 0 1
2.在两台服务器连接pgpool分别查询前面建的表“test01”,为了区别这个数据是哪个节点返回的,加函数“pg_postmaster_start_time”。
在192.168.100.140运行如下命令:
postgres=# select pg_postmaster_start_time(), * from test01;
pg_postmaster_start_time | id | note
-------------------------------+----+-------
2017-05-08 13:17:32.135454+08 | 1 | 11111
2017-05-08 13:17:32.135454+08 | 2 | 22222
(2 rows)
在192.168.100.142运行如下命令:
postgres=# select pg_postmaster_start_time(), * from test01;
pg_postmaster_start_time | id | note
-------------------------------+----+-------
2017-05-08 13:16:39.570439+08 | 1 | 11111
2017-05-08 13:16:39.570439+08 | 2 | 22222
(2 rows)
可以看到,负载均衡能正常工作了。
故障切换
故障切换的主要工作在于当首要服务器发生故障时能够快速在备用服务器中创建一个触发文件,备库一旦检测到该触发文件将会由只读模式提升为读写模式,从而继续为前台应用提供正常的服务。
根据配置文件pgpool.conf中的failover_command配置项,在/usr/local/pgpool/etc目录下写脚本failover.sh,内容如下:
failed_node=$1
new_master=$2
trigger_file=$3
# Do nothing if standby goes down.
if [ $failed_node = 1 ]; then
exit 0;
fi
# Create the trigger file.
/usr/bin/ssh -T $new_master /bin/touch $trigger_file
exit 0给脚本可执行权限:
[postgres@master etc]$ chmod 755 failover.sh检验主从数据库切换的脚本是否可以正常运行,在master服务器执行命令,检测在slave服务器是否生成了trigger_file文件
shell脚本在master执行:
[postgres@master etc]$ ./failover.sh 0 192.168.100.142 /usr/local/pgsql/trigger_file
切换到slave检查,/usr/local/pgsql下生成了文件trigger_file
现在我们模拟primary server停掉的情况,在master上面执行:
[postgres@master etc]$ pg_ctl stop在slave连接pgpool查看节点信息:
postgres=# show pool_nodes;
node_id | hostname | port | status | lb_weight | role
---------+-----------------+------+--------+-----------+---------
0 | 192.168.100.140 | 5432 | 3 | 0.500000 | standby
1 | 192.168.100.142 | 5432 | 2 | 0.500000 | primary
(2 rows)
可以看到主备已经切换完成。
此时原主库切换为备库,状态为3。需要在新的主库执行一条关联节点的语句:
[root@slave ~]# pcp_attach_node 10 127.0.0.1 9898 postgres postgres 0
查看节点信息:
postgres=# show pool_nodes;
node_id | hostname | port | status | lb_weight | role
---------+-----------------+------+--------+-----------+---------
0 | 192.168.100.140 | 5432 | 1 | 0.500000 | standby
1 | 192.168.100.142 | 5432 | 2 | 0.500000 | primary
(2 rows)