给定传输中的数字总和以某个数为模。最简单形式的校验和是在7位数字(例如,ASCII字符)上附加的奇偶校验位,使得1的总数始终是偶数(“偶校验”)或奇数(“奇校验”)。一个明显更复杂的校验和是循环冗余校验(或CRC),它基于整数上的多项式代数(mod 2)。它在检测传输错误方面基本上更可靠,并且是调制解调器中使用的一种常见的错误检查协议。
循环冗余校验
复杂的校验和(通常缩写为CRC),它基于整数上的多项式代数(mod 2)。它在检测传输错误方面基本上更可靠,并且是调制解调器中使用的一种常见的错误检查协议。CRC是散列函数的一种形式。
要使用CRC比较大数据块,首先要为每个块预先计算CRC。然后可以通过查看它们的CRC是否相等来快速比较两个块,在大多数情况下节省了大量的计算时间。该方法不是绝对可靠的,因为对于![]() 比特校验和,
比特校验和,![]() 随机块将对不等价数据块具有相同的校验和。但是,如果
随机块将对不等价数据块具有相同的校验和。但是,如果![]() 很大,则可以使两个不等效块具有相同CRC的概率非常小。
很大,则可以使两个不等效块具有相同CRC的概率非常小。
纠错码
纠错码是用于表示数字序列的算法,使得可以基于剩余数量来检测和校正(在某些限制内)引入的任何错误。纠错码和相关数学的研究称为编码理论。
错误检测比错误纠正简单得多,并且一个或多个“检查”数字通常嵌入在信用卡号中以便检测错误。像Mariner这样的早期太空探测器使用了一种称为分组码的纠错码,而最近的太空探测器使用了卷积码。纠错码也用于CD播放器,高速调制解调器和蜂窝电话。调制解调器在计算校验和时使用错误检测,校验和是给定传输中的数字的总和,模数为某个数字。 用于识别书籍的ISBN还包含校验位。
对13 位数字的强大检查包括以下内容。将数字写为一串数字 ![]() 。拿走
。拿走![]() 并加倍。现在添加的数量数字在奇数 它们的位置
并加倍。现在添加的数量数字在奇数 它们的位置![]() 到这个号码。现在添加
到这个号码。现在添加![]() 。然后,校验码是使最后一位数字为0 所需的数字。该方案检测所有单个数字错误和 除0和9之外的相邻数字的所有 转置。
。然后,校验码是使最后一位数字为0 所需的数字。该方案检测所有单个数字错误和 除0和9之外的相邻数字的所有 转置。
设![]() 表示
表示![]() 具有任意两个集合在至少
具有任意两个集合在至少![]() 位置上不同的属性的(0,1) - 向量的最大数量。相应的矢量可以纠正
位置上不同的属性的(0,1) - 向量的最大数量。相应的矢量可以纠正![]() 错误。
错误。 ![]() 是
是![]() 精确
精确![]() 1 秒的s 数(Sloane和Plouffe 1995)。因为
1 秒的s 数(Sloane和Plouffe 1995)。因为![]() -vectors不可能在不同的
-vectors不可能在不同的![]() 地方有所不同,因为
地方有所不同,因为![]() 在所有
在所有![]() 地方都有不同的-vectors 分成不同的两个集合,
地方都有不同的-vectors 分成不同的两个集合,
|
(1)
|
的值![]() 可以通过标记的发现
可以通过标记的发现![]() - (0,1)
- (0,1)![]() -载体,发现所有无序对
-载体,发现所有无序对![]() 的
的![]() -载体,其中彼此在至少不同
-载体,其中彼此在至少不同 ![]() 的地方,形成了一个曲线图 ,从这些无序对,然后找到团数的这个图形。不幸的是,找到给定图形的团的大小 是NP完全问题。
的地方,形成了一个曲线图 ,从这些无序对,然后找到团数的这个图形。不幸的是,找到给定图形的团的大小 是NP完全问题。
| OEIS | ||
| 1 | A000079 | 2,4,8,16,32,64,128 ...... |
| 2 | 1,2,4,8 ...... | |
| 3 | 1,1,2,2 ...... | |
| 4 | A005864 | 1,1,1,2,4,8,16,20,40 ...... |
| 5 | 1,1,1,1,2 ...... | |
| 6 | A005865 | 1,1,1,1,1,2,2,2,4,6,12 ...... |
| 7 | 1,1,1,1,1,1,2 ...... | |
| 8 | A005866 | 1,1,1,1,1,1,1,2,2,2,2,4 ...... |
发电机矩阵
给定一个线性码 ![]() ,生成矩阵
,生成矩阵 ![]() 的
的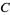 是一个矩阵,它的行产生的所有元件
是一个矩阵,它的行产生的所有元件![]() ,即,如果
,即,如果![]() ,那么每一个码字
,那么每一个码字 ![]() 的
的![]() 可表示为
可表示为
以独特的方式,在哪里![]() 。
。
生成矩阵的一个例子是Golay码,它由![]() 11行的所有可能的二进制和组成。
11行的所有可能的二进制和组成。
Golay代码
Golay代码是一个完美的 线性 纠错码。Golay代码有两个本质上不同的版本:二进制版本和三元版本。
的二进制版本![]() 是一个
是一个![]() 二进制线性代码组成的
二进制线性代码组成的![]() 码字长度23和最小距离7.第三元版本是一个
码字长度23和最小距离7.第三元版本是一个 三元线性码,由
三元线性码,由![]() 码字长度11的s的最小距离5。
码字长度11的s的最小距离5。
甲奇偶校验矩阵的二进制Golay码由给定的矩阵![]() ,其中
,其中![]() 是
是![]() 单位矩阵 并且
单位矩阵 并且![]() 是
是![]() 矩阵
矩阵
 |
通过添加奇偶校验位到每个码字中![]() ,该扩展的格雷码
,该扩展的格雷码![]() ,这是一种几乎完美的
,这是一种几乎完美的![]() 二进制线性码,获得。该构群的
二进制线性码,获得。该构群的![]() 是马修组
是马修组 ![]() 。
。
第二个![]() 发生器是邻接矩阵的二十面体,具有
发生器是邻接矩阵的二十面体,具有![]() 所附,其中
所附,其中![]() 是单位矩阵 并且
是单位矩阵 并且![]() 是一个单位矩阵。
是一个单位矩阵。
第三个![]() 生成器以24位0字(000 ... 000)开始列表,并重复附加第一个24位字,该字与列表中的所有字有八个或更多差异。Conway和Sloane列出了许多其他方法。
生成器以24位0字(000 ... 000)开始列表,并重复附加第一个24位字,该字与列表中的所有字有八个或更多差异。Conway和Sloane列出了许多其他方法。
令人惊讶的是,Golay的原始论文只有半页长,但已被证明与群论,图论,数论,组合学, 博弈论,多维几何,甚至粒子物理学有着深刻的联系。
格雷码
格雷码是数字的编码,使得相邻数字具有相差1的单个数字。术语格雷码通常用于表示“反射”代码,或者更具体地,二进制反射格雷码。
要将二进制数![]() 转换为其对应的二进制反射格雷码,请从右侧开始使用数字
转换为其对应的二进制反射格雷码,请从右侧开始使用数字 ![]() (
(![]() th或最后一位)。如果
th或最后一位)。如果![]() 是1,则替换
是1,则替换 ![]() 为
为![]() ; 否则,保持不变。然后继续
; 否则,保持不变。然后继续![]() 。继续到第一个数字
。继续到第一个数字 ![]() ,保持相同,因为
,保持相同,因为![]() 假定为0.结果数字
假定为0.结果数字![]() 是反射的二进制格雷码。
是反射的二进制格雷码。
要将二进制反射格雷码![]() 转换为二进制数,请从
转换为二进制数,请从![]() 第二位开始,然后计算
第二位开始,然后计算
如果![]() 是1,则替换
是1,则替换![]() 为
为![]() ; 否则,保持不变。下次计算
; 否则,保持不变。下次计算
等等。得到的数字![]() 是对应于初始二进制反射格雷码的二进制数。
是对应于初始二进制反射格雷码的二进制数。
代码被反映,因为它可以按以下方式生成。取灰色代码0,1。向前写入,然后向后写入:0,1,1,0。然后将0添加到前半部分,将1s添加到后半部分:00,01,11,10。继续,写入00,01,11,10,10,11,01,00获得:000,001,011,010,110,111,101,100 ......(OEIS A014550)。因此,每次迭代使代码数量翻倍。
上图显示了前255(上图)和前511(下图)格雷码的二进制表示。对应于前几个非负整数的格雷码在下表中给出。
| 0 | 0 | 20 | 11110 | 40 | 111100 |
| 1 | 1 | 21 | 11111 | 41 | 111101 |
| 2 | 11 | 22 | 11101 | 42 | 111111 |
| 3 | 10 | 23 | 11100 | 43 | 111110 |
| 4 | 110 | 24 | 10100 | 44 | 111010 |
| 5 | 111 | 25 | 10101 | 45 | 111011 |
| 6 | 101 | 26 | 10111 | 46 | 111001 |
| 7 | 100 | 27 | 10110 | 47 | 111000 |
| 8 | 1100 | 28 | 10010 | 48 | 101000 |
| 9 | 1101 | 29 | 10011 | 49 | 101001 |
| 10 | 1111 | 30 | 10001 | 50 | 101011 |
| 11 | 1110 | 31 | 10000 | 51 | 101010 |
| 12 | 1010 | 32 | 110000 | 52 | 101110 |
| 13 | 1011 | 33 | 110001 | 53 | 101111 |
| 14 | 1001 | 34 | 110011 | 54 | 101101 |
| 15 | 1000 | 35 | 110010 | 55 | 101100 |
| 16 | 11000 | 36 | 110110 | 56 | 100100 |
| 17 | 11001 | 37 | 110111 | 57 | 100101 |
| 18 | 11011 | 38 | 110101 | 58 | 100111 |
| 19 | 11010 | 39 | 110100 | 59 | 100110 |
二进制反射格雷码密切相关的解决方案河内的塔和九连环,以及到哈密顿周期的超立方体图表 S(包括方向反转; 1990 Skiena,第149页)。
Hadamard矩阵

Hadamard矩阵是由西尔维斯特(Sylvester,1867)以剖析路面的名义发明的一种正方形 (-1,1)矩阵,在Hadamard(1893)认为它们之前26年。在Hadamard矩阵中,并排放置任意两列或多行,使相邻单元格的一半与相同的符号相同 ,另一半符号。当被视为路面时,具有1s的单元格被涂成黑色而具有![]() s的单元格被涂成白色。因此,
s的单元格被涂成白色。因此,![]() Hadamard矩阵
Hadamard矩阵![]() 必须具有
必须具有![]() 白色方块
白色方块![]() 和
和![]() 黑色方块(1s)。
黑色方块(1s)。
Hadamard有序矩阵![]() 是 Hadamard最大行列式问题的解,即具有元素 的任何复矩阵(Brenner和Cummings 1972)的最大可能行列式(绝对值),即。Hadamard矩阵的等价定义由下式给出
是 Hadamard最大行列式问题的解,即具有元素 的任何复矩阵(Brenner和Cummings 1972)的最大可能行列式(绝对值),即。Hadamard矩阵的等价定义由下式给出 ![]()
![]()
![]()
 |
(1)
|
其中![]() 是
是 单位矩阵。
单位矩阵。
的顺序的Hadamard矩阵![]() 对应于阿达玛设计(
对应于阿达玛设计(![]() ,
,![]() ,
,![]() ),和Hadamard矩阵
),和Hadamard矩阵![]() 给出的曲线
给出的曲线![]() 被称为顶点哈达玛图表
被称为顶点哈达玛图表

一组完整的![]() 沃尔什函数有序
沃尔什函数有序![]() 给出了Hadamard矩阵
给出了Hadamard矩阵![]() (Thompson 等, 1986,第204页; Wolfram,2002,第1073页 )。Hadamard矩阵可用于产生纠错码,特别是Reed-Muller纠错码。
(Thompson 等, 1986,第204页; Wolfram,2002,第1073页 )。Hadamard矩阵可用于产生纠错码,特别是Reed-Muller纠错码。
如果![]() 并且
并且![]() 已知,则
已知,则 ![]() 可以通过替换
可以通过替换![]() by
by ![]() 和all
和all  s中的所有1来获得
s中的所有1来获得![]() 。因为
。因为![]() ,具有20,28,36,44,52,60,68,76,84,92
,具有20,28,36,44,52,60,68,76,84,92 ![]() 和100的Hadamard矩阵不能由低阶Hadamard矩阵构建。
和100的Hadamard矩阵不能由低阶Hadamard矩阵构建。
|
(2)
|
|||
|
(3)
|
|||
![[[1 1; -1 1] [1 1; -1 1]; - [1 1; -1 1] [1 1; -1 1]]](http://img.e-com-net.com/image/info8/e082bb95ead74701a92f7ba79364f4e7.gif) |
(4)
|
||
![[1 1 1 1; -1 1 -1 1; -1 -1 1 1; 1 -1 -1 1]。](http://img.e-com-net.com/image/info8/17804f8ab33949bebee11d43b6303a05.gif) |
(5)
|
![]() 可以类似地从中生成
可以类似地从中生成![]() 。
。

Hadamard(1893)指出,Hadamard矩阵存在的必要条件是![]() 2,或4的正数倍(Brenner和Cummings 1972)。佩利定理保证总是存在哈马德矩阵
2,或4的正数倍(Brenner和Cummings 1972)。佩利定理保证总是存在哈马德矩阵![]() 时,
时,![]() 由4整除的形式
由4整除的形式 ![]() 对一些正整数
对一些正整数![]() ,非负整数
,非负整数![]() ,和
,和![]() 一个奇素数。在这种情况下,矩阵可以使用Paley结构构建,如上所述(Wolfram 2002,第1073页 )。Paley类的数量为
一个奇素数。在这种情况下,矩阵可以使用Paley结构构建,如上所述(Wolfram 2002,第1073页 )。Paley类的数量为![]() 8,...,分别为2,3,2,3,2,3,2,4,1 ......(OEIS A074070))。的值
8,...,分别为2,3,2,3,2,3,2,4,1 ......(OEIS A074070))。的值![]() 对于其中没有佩利类(和因此不能使用佩利结构来构造)是92,116,156,172,184,188,232,236,260,268,...(OEIS A046116)。
对于其中没有佩利类(和因此不能使用佩利结构来构造)是92,116,156,172,184,188,232,236,260,268,...(OEIS A046116)。

据推测,![]() 存在于所有
存在于所有![]() 可 被4 整除的人.Sawade(1985)构建
可 被4 整除的人.Sawade(1985)构建![]() 。截至1993年,Hadamard矩阵因所有
。截至1993年,Hadamard矩阵因所有![]() 可被4整除而闻名
可被4整除而闻名![]() (Brouwer 等, 1989,第20页; van Lint和Wilson,1993)。
(Brouwer 等, 1989,第20页; van Lint和Wilson,1993)。![]() 随后构建了A (Kharaghani和Tayfeh-Rezaie 2004),如上所示,将最小的未知顺序保留为668.然而,一般猜想的证明 仍然是编码理论中的一个重要问题。订单的不同的Hadamard矩阵的数量
随后构建了A (Kharaghani和Tayfeh-Rezaie 2004),如上所示,将最小的未知顺序保留为668.然而,一般猜想的证明 仍然是编码理论中的一个重要问题。订单的不同的Hadamard矩阵的数量![]() 为
为![]() ,2,...是1,1,1,5,3,60,487,...(OEIS A007299 ;钨2002年,第 1073)。Djoković(2009)修正了Colbourn和Dinitz(2007)中的列表,发现了4个以前未知的
,2,...是1,1,1,5,3,60,487,...(OEIS A007299 ;钨2002年,第 1073)。Djoković(2009)修正了Colbourn和Dinitz(2007)中的列表,发现了4个以前未知的![]() 可被4整除,可以构造Hadamard矩阵:764,23068,28324,32996。
可被4整除,可以构造Hadamard矩阵:764,23068,28324,32996。