快速掌握mongodb入门手册
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。关于它要想了解更多,请参阅《三分钟了解mongodb》
目录
1.NOSQL分类
2.特点
3.数据模型
4.演示数据
5.基本概念
5.1 ACID VS BASE
5.2 SQL到Mongo映射
5.3文档
5.4 集合
5.5 固定集合
5.6 数据库
5.7 元数据
5.8 管道
5.9 数据类型
6. mongo维护
6.1 安装
6.2 启动/关闭
6.3 导入/导出
6.4 备份/恢复
6.5 数据修复/Fsnc锁
6.6 用户管理
6.7 常见命令
7. 数据库操作
7.1 服务端脚本
7.2 新建
7.3 删除
7.4 runCommand
7.5 findAndModify
8. 文档操作
8.1 文档插入
8.1.1 插入
8.1.2 批量插入
8.1.3 save
8.2 文档删除
8.3 文档更新
8.4 固定集合
8.5 数据模型校验器
9. 数据检索
10. 索引
10.1 索引详解
10.1.1 Hint
10.1.2 Explain
10.2 联合索引
10.3 索引数组
10.4 空间索引
11. Map-Reduce
12. GridFS
13.1 复制
13.1.1 主从复制
13.1.2 副本集
13.2 分片
14 管理工具
14.1 MongoVUE
14.2 RockMongo
14.3 Robo 3T
15. java-driver
1.NOSQL分类
具体参考《一览NoSQL各种分类 》
2.特点
| MongoDB特征 |
|
| 核心优势 |
灵活文档模型、高可用复制集、可拓展分片集群 |
| 功能特点 |
二级索引、地理位置索引、全文索引、aggregate、map-reduce、GridFs |
| 不足之处 |
不支持事务、不支持表链接 |
3.数据模型
一个MongoDB 实例可以包含一组数据库,一个DataBase 可以包含一组Collection(集合),一个集合可以包含一组Document(文档)。一个Document包含一组field(字段),每一个字段都是一个key/value pair。
key: 必须为字符串类型。
value:可以包含如下类型。
4.演示数据
var persons =[{
name: "tom",
age: 25,
email: "[email protected]",
c: 75,
m: 66,
e: 97,
country: "USA",
books: ["PHP", "JAVA", "EXTJS", "C++"]
}, {
name: "lili",
age: 26,
email: "[email protected]",
c: 75,
m: 63,
e: 97,
country: "USA",
books: ["JS", "JAVA", "C#", "MONGODB"]
}, {
name: "zhangsan",
age: 27,
email: "[email protected]",
c: 89,
m: 86,
e: 67,
country: "China",
books: ["JS", "JAVA", "EXTJS", "MONGODB"]
}, {
name: "lisi",
age: 26,
email: "[email protected]",
c: 53,
m: 96,
e: 83,
country: "China",
books: ["JS", "C#", "PHP", "MONGODB"]
}, {
name: "zhaoliu",
age: 27,
email: "[email protected]",
c: 99,
m: 96,
e: 97,
country: "China",
books: ["JS", "JAVA", "EXTJS", "PHP"]
}, {
name: "lizhenxian",
age: 27,
email: "[email protected]",
c: 35,
m: 56,
e: 47,
country: "Korea",
books: ["JS", "JAVA", "EXTJS", "MONGODB"]
}, {
name: "lixiaoli",
age: 21,
email: "[email protected]",
c: 36,
m: 86,
e: 32,
country: "Korea",
books: ["JS", "JAVA", "PHP", "MONGODB"]
}, {
name: "zhangsuying",
age: 22,
email: "[email protected]",
c: 45,
m: 63,
e: 77,
country: "Korea",
books: ["JS", "JAVA", "C#", "MONGODB"]
}, {
name: "liuxiang",
age: 31,
email: "[email protected]",
c: 99,
m: 96,
e: 97,
country: "China",
books: ["JS", "JAVA", "EXTJS", "VS"],
address: {
city: "上海",
area: "普陀区XX路"
}
}, {
name: "chenlong",
age: 55,
email: "[email protected]",
c: 99,
m: 96,
e: 97,
country: "China",
books: ["JAVA", "EXTJS", "VS"],
address: {
city: "香港",
area: "中环XX路"
}
}
]
for(var i = 0;i5.基本概念
5.1 ACID VS BASE
在计算机科学中, CAP定理(CAP theorem), 又被称作 布鲁尔定理(Brewer's theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) (所有节点在同一时间具有相同的数据)
- 可用性(Availability) (保证每个请求不管成功或者失败都有响应)
- 分区隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些
BASE:Basically Available, Soft-state, Eventually Consistent。由 Eric Brewer 定义。BASE是NoSQL数据库通常对可用性及一致性的弱要求原则:
- Basically Availble --基本可用
- Soft-state --软状态/柔性事务。 "Soft state" 可以理解为"无连接"的, 而 "Hard state" 是"面向连接"的
- Eventual Consistency --最终一致性 最终一致性, 也是是 ACID 的最终目的。
| ACID |
BASE |
| 原子性(Atomicity) |
基本可用(Basically Available) |
| 一致性(Consistency) |
软状态/柔性事务(Soft state) |
| 隔离性(Isolation) |
最终一致性 (Eventual consistency) |
| 持久性 (Durable) |
|
5.2 SQL到Mongo映射
| SQL术语/概念 |
MongoDB术语/概念 |
解释/说明 |
| database |
database |
数据库 |
| table |
collection |
数据库表/集合 |
| row |
document |
数据记录行/文档 |
| column |
field |
数据字段/域 |
| index |
index |
索引 |
| table joins |
|
表连接,MongoDB不支持(内嵌文档和链接) |
| primary key |
primary key |
主键,MongoDB自动将_id字段设置为主键 |
| aggregation |
|
Mongodb内置大量聚合管道 |
5.3文档
文档是 MongoDB 中数据的基本单位,类似于关系数据库中的行(但是比行复杂)
注意:
- 文档中的键/值对是有序的
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
- MongoDB区分类型和大小写。
- MongoDB的文档不能有重复的键。
- 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
文档键命名规范:
- 键不能含有\0 (空字符)。这个字符用来表示键的结尾。
- .和$有特别的意义,只有在特定环境下才能使用。
- 以下划线"_"开头的键是保留的(不是严格要求的)。
5.4 集合
集合就是一组文档,类似于关系数据库中的表。集合是无模式的,集合中的文档可以是各式各样的。
注意:
- 集合名不能是空字符串""。
- 集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。
- 集合名不能以"system."开头,这是为系统集合保留的前缀。
- 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
5.5 固定集合
Capped collections 就是固定大小的collection。它有很高的性能以及队列过期的特性,collection的数据存储空间值提前分配的。
db.createCollection("mycoll", {capped:true, size:100000})
db.cappedLogCollection.isCapped() --是否为固定集合
- 插入速度极快
- 插入顺序的查询输出速度极快
- 能够在插入最新数据时,淘汰最早的数据
- 能进行更新,但更新不能超出collection的大小,否则更新就会失败 。
- 数据库不允许进行删除。使用drop()方法删除collection所有的行。删除之后,你必须显式的重新创建这个collection。
- 在32位机子上一个cappped collection的最大值约为482.5M,64位上只受系统文件大小的限制
适用场景:
- 存储日志信息
- 缓存一些少量的文档
5.6 数据库
一个MongoDB 实例可以承载多个数据库。它们之间可以看作相互独立,每个数据库都有独立的权限控制。在磁盘上,不同的数据库存放在不同的文件中。MongoDB 中存在以下系统数据库。
- Admin 数据库:一个权限数据库,如果创建用户的时候将该用户添加到admin 数据库中,那么该用户就自动继承了所有数据库的权限。
- Local 数据库:这个数据库永远不会被负责,可以用来存储本地单台服务器的任意集合。
- Config 数据库:当MongoDB 使用分片模式时,config 数据库在内部使用,用于保存分片的信息。
数据库名可以是满足以下条件的任意UTF-8字符串:
- 不能是空字符串("")。
- 不得含有' '(空格)、.、$、/、\和\0 (空宇符)。
- 应全部小写。
- 最多64字节
5.7 元数据
数据库的信息是存储在集合中。它们使用了系统的命名空间:已废弃
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
对于修改系统集合有如下限制。
{{system.indexes}}插入数据,可以创建索引。但除此之外该表信息是不可变的(特殊的drop index命令将自动更新相关信息)。{{system.users}}是可修改的。{{system.profile}}是可删除的。
5.8 管道
管道在Linux中一般用于将当前命令的输出结果作为下一个命令的参数。MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
聚合框架中常用操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
5.9 数据类型
| 数据类型 |
描述 |
| String |
字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer |
整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean |
布尔值。用于存储布尔值(真/假)。 |
| Double |
双精度浮点值。用于存储浮点值。 |
| Min/Max keys |
将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Arrays |
用于将数组或列表或多个值存储为一个键。 |
| Timestamp |
时间戳。记录文档修改或添加的具体时间。 |
| Object |
用于内嵌文档。 |
| Null |
用于创建空值。 |
| Symbol |
符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 |
| Date |
日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID |
对象 ID。用于创建文档的 ID。 |
| Binary Data |
二进制数据。用于存储二进制数据。 |
| Code |
代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression |
正则表达式类型。用于存储正则表达式。 |
6. mongo维护
| 数据库服务和客户端 |
|
| mongod |
类似mysqld |
| mongo |
类似mysql/sqlplus 其实是个javascript引擎 |
| mongoexport |
导出命令 |
| mongoimport |
导入命令 |
| mongotop |
监控工具,跟踪数据库执行每个集合读写操作耗时 |
| mongostat |
监控工具,类似linux vmstat |
| mongos |
路由工具(分片) |
| mongodump |
数据备份 |
| mongorestore |
数据恢复 |
| mongofiles |
GridFS(添加文件) |
| mongoperf |
独立检查mongoDB的I/O性能的工具,类似linux iostat |
| mongooplog |
用于从运行的mongod服务中拷贝运行日志到指定的服务器,主要用于增量备份 |
| bsondump |
用于将导出的BSON文件格式转换为JSON格式 |
| mongosniff |
(linux及unix有此工具)用于监控连接到mongodb的TCP/IP连接,类似于tcpdump |
6.1 安装
- 下载http://www.mongodb.org/downloads
- 设置环境变量path
6.2 启动/关闭
启动服务端:
- mongod
| 参数 |
描述 |
| --help |
帮助 |
| --bind_ip |
绑定服务IP,若绑定127.0.0.1,则只能本机访问,不指定默认本地所有IP |
| --logpath |
定MongoDB日志文件,注意是指定文件不是目录 |
| --logappend |
使用追加的方式写日志 |
| --dbpath |
指定数据库路径 |
| --port |
指定服务端口号,默认端口27017 |
| --serviceName |
指定服务名称 |
| --serviceDisplayName |
指定服务名称,有多个mongodb服务时执行。 |
| --install |
指定作为一个Windows服务安装。 |
| --auth |
用安全认证方式启动 |
停止服务端:
- ctrl+c 组合键可以关闭数据库
- 进入admin数据库命令关闭数据 :db.shutdownServer()
启动客户端:
- mongo
#window shell
Cd C:\
mkdir mongodbdata
mongod -dbpath C:\mongodbdata
mongo --help
mongo localhost:27017
show dbs
exit
mongo 127.0.0.1:27017/admin #admin身份进入利用config配置文件来启动数据库改变端口为8888
mongodb.conf文件:
dbpath = D:\sortware\mongod\db
port = 8888
启动:
mongod.exe --config ../mongodb.conf
6.3 导入/导出
1.导出数据(中断其他操作)
-d 指明使用的库
-c 指明要导出的表
-o 指明要导出的文件名
-csv 制定导出的csv格式
-q 过滤导出
--type
mongoexport -d foobar -c persons -o D:/persons.json
mongoexport --host 192.168.0.16 --port 37017
2.导入数据(中断其他操作)
mongoimport --db foobar --collection persons --file d:/persons.json
6.4 备份/恢复
1.运行时备份mongodump
mongodump --host 127.0.0.1:27017 -d foobar -o d:/foobar
2.运行时恢复mongorestore
db.dropDatabase() --删除原本的数据库
mongorestore --host 127.0.0.1:27017 -d foobar -directoryperdb d:/foobar/foobar
3.懒人备份
mongoDB是文件数据库这其实就可以用拷贝文件的方式进行备份
6.5 数据修复/Fsnc锁
1.Fsync的使用
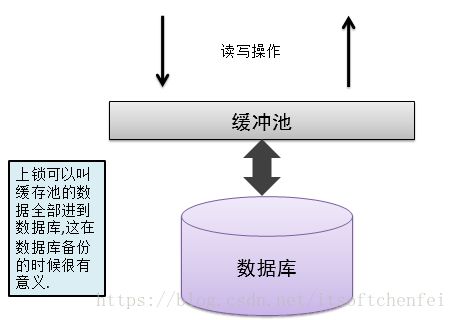
2.上锁和解锁
db.runCommand({fsync:1,lock:1}) --上锁
db.currentOp() --解锁
3.数据修复
当停电等不可逆转灾难来临的时候,由于mongodb的存储结构导致会产生垃圾数据,在数据恢复以后这垃圾数据依然存在,这是数据库提供一个自我修复的能力.使用起来很简单
db.repairDatabase()
6.6 用户管理
#shell
mongo localhost:27017/admin
show roles
use test
db.createUser({
user: "alex",
pwd: "123",
roles: [ { role: "__system", db: "admin" } ]
}
)
mongod -dbpath C:\mongodbdata --rest –auth --cmd
db.auth("alex","123")
db.dropUser(“alex”)
db.runCommand({usersInfo:1}) #all users
db.system.users.find().pretty() #use admin
#远程连接
mongo 192.168.2.203:27017/gesb -ureaduser -pJcizexRo46.7 常见命令
- show dbs/show tables/show users
- db.getCollectionNames()
- db.version()
- db.hostInfo()
- db.stats() -- db 的元数据信息
- db.serverStatus()
- rs.conf() --副本集
- rs.status() --副本集
- rs.reconfig() --副本
7. 数据库操作
7.1 服务端脚本
1.Eval
db.eval("function(name){ return name}","uspcat")
2.Javascript的存储(服务上保存js变量活着函数共全局调用)
db.system.js.insert({_id:name,value:”uspcat”}) --加载到特殊集合system.js
db.eval("return name;")
System.js相当于Oracle中的存储过程,因为value不单单可以写变量还可以写函数体也就是javascript代码
7.2 新建
use test #新建test db(若不执行insert,数据库不会被创建)
db.person.insert({name:"mongodb"})
db.person.find()
db
show dbs7.3 删除
use test
db.dropDatabase()
show dbs7.4 runCommand
runCommand可以执行mongoDB中的特殊函数,
#用命令执行完成一次删除表的操作
db.runCommand({drop:"map"})
{
"nIndexesWas" : 2,
"msg" : "indexes dropped for collection",
"ns" : "foobar.map",
"ok" : 1
}
# 查询服务器版本号和主机操作系统
db.runCommand({buildInfo:1})
#查询执行集合的详细信息,大小,空间,索引等……
db.runCommand({collStats:"persons"})
#查看操作本集合最后一次错误信息
db.runCommand({getLastError:"persons"})7.5 findAndModify
findAndModify就是特殊函数之一他的用于是返回update或remove后的文档
runCommand({“findAndModify”:”processes”,
query:{查询器},
sort{排序},
new:true
update:{更新器},
remove:true
).value
ps = db.runCommand({
"findAndModify":"persons",
"query":{"name":"text"},
"update":{"$set":{"email":"1221"}},
"new":true
}).value
do_something(ps)8. 文档操作
show tables
8.1 文档插入
8.1.1 插入
db.[documentName].insert(document)
8.1.2 批量插入
shell 这样执行是错误的 db.[documentName].insert([{},{},{},……..]),shell 不支持批量插入
想完成批量插入可以用mongo的应用驱动或是shell的for循环
> function batch(){
... for(var i=0;i<5;i++){
... db.persons.insert({name:"person"+i})
... }}
> batch()
8.1.3 save
save操作和insert操作区别在于当遇到_id相同的情况下,save完成保存操作, insert则会报错
8.2 文档删除
db.[documentName].remove(
,
{
justOne: ,
writeConcern:
}
) - query :(可选)删除的文档的条件。
- justOne : (可选)如果设为 true 或 1,则只删除一个文档。
- writeConcern :(可选)抛出异常的级别。
小技巧:
- 集合的本身和索引不会被删除
- 如果你想清楚一个数据量十分庞大的集合,直接删除该集合并且重新建立索引的办法,比直接用remove的效率和高很多
8.3 文档更新
db.[documentName].update(
,
,
{
upsert: ,
multi: ,
writeConcern:
}
) - query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。--insertOrUpdate
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。--批量更新操作
- writeConcern :可选,抛出异常的级别。
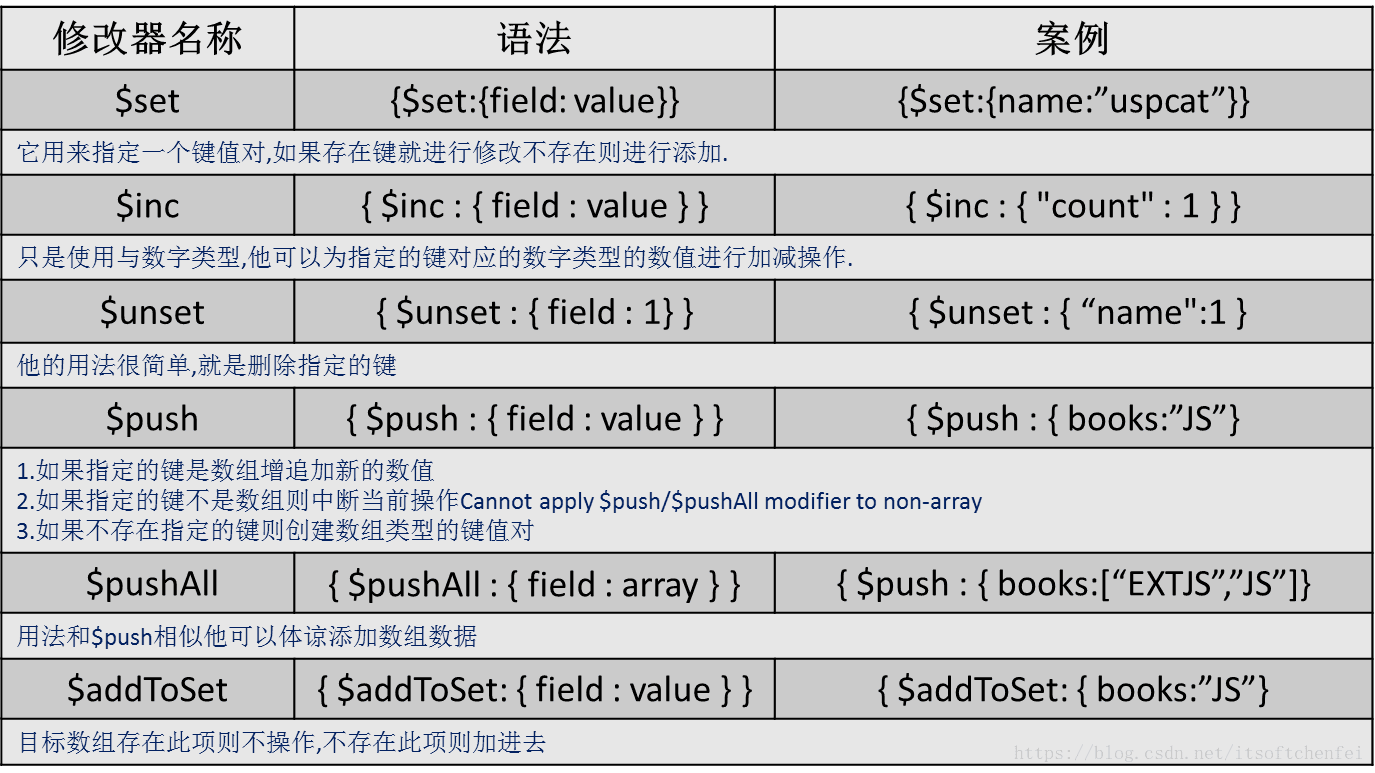

$addToSet与$each结合完成批量数组更新
db.text.update({_id:1000},{$addToSet:{books:{$each:[“JS”,”DB”]}}})
注意:存在分配与查询效率
当document被创建的时候DB为其分配没存和预留内存当修改操作,不超过预留内层的时候则速度非常快反而超过了就要分配新的内存则会消耗时间

db.persons.update({name:"person1"},{$set:{name:"pp"}})
db.[documentName].update({查询器},{修改器},true)
db.[documentName].update({查询器},{修改器},false, true)8.4 固定集合
- 创建一个新的固定集合要求大小是100个字节,可以存储文档10个
db.createCollection("mycoll",{size:100,capped:true,max:10})
- 把一个普通集合转换成固定集合
db.runCommand({convertToCapped:”persons”,size:100000})
- 查询固定集合mycoll并且反向排序(默认是插入顺序排序)
db.mycoll.find().sort({$natural:-1})
- 尾部游标概念(可惜shell不支持java和php等驱动是支持的)
这是个特殊的只能用到固定级和身上的游标,他在没有结果的时候,也不回自动销毁他是一直等待结果的到来
8.5 数据模型校验器
文档格式太灵活也会有问题的,不便于维护
db.createCollection( "contacts",
{
validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
],
validationAction: "warn"
}
}
)
db.contacts.insert( { name: "Amanda", status: "Updated" } )
//添加一个验证器
db.runCommand( {
collMod: "contacts",
validator: { $or: [ { phone: { $exists: true } }, { email: { $exists: true } } ] },
validationLevel: "moderate"
} )9. 数据检索
参考我另一篇《数据检索》
10. 索引
10.1 索引详解
for(var i = 0 ; i<20000 ;i++){
db.books.insert({number:i,name:i+"book"})
}
db.books.ensureIndex({number:1})
db.books.ensureIndex({name:-1},{name:”bookname”}) //指定索引名称
db.books.ensureIndex({name:-1},{unique:true})
db.books.ensureIndex({name:-1},{unique:true,dropDups:true}) //踢出重复值
db.books.ensureIndex({name:-1},{background:true})
db.system.indexes.find() //已废弃
db.persons.getIndexes()
db.persons.reIndex()
db.persons.dropIndex(“bookname”)
db.persons.dropIndexes()注意:
- 创建索引的时候注意1是正序创建索引-1是倒序创建索引
- 索引的创建在提高查询性能的同事会影响插入的性能
- 对于经常查询少插入的文档可以考虑用索引
- 索引不是万能的,每个键全建立索引不一定就能提高性能
- 在做排序工作的时候如果是超大数据量也可以考虑加上索引
- 执行创建索引的过程会暂时锁表问题
索引限制:
索引不能被以下的查询使用:
- 正则表达式及非操作符,如 $nin, $not, 等。
- 算术运算符,如 $mod, 等。
- $where 子句
所以,检测你的语句是否使用索引是一个好的习惯,可以用explain来查看。
最大范围
- 集合中索引不能超过64个
- 索引名的长度不能超过125个字符
- 一个复合索引最多可以有31个字段
- 从2.6版本开始,如果现有的索引字段的值超过索引键的限制,MongoDB中不会创建索引。
| Parameter |
Type |
Description |
| background |
Boolean |
建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 "background" 可选参数。 "background" 默认值为false。 |
| unique |
Boolean |
建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name |
string |
索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups |
Boolean |
在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse |
Boolean |
对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds |
integer |
指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v |
index version |
索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights |
document |
索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language |
string |
对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override |
string |
对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
10.1.1 Hint
强制查询使用指定的索引,但是必须已经创建了的索引
db.books.find({name:"1book",number:1}).hint({name:-1})
10.1.2 Explain
db.books.find({name:"1book"}).explain()
- indexOnly: 字段为 true ,表示我们使用了索引
- cursor:索引的名称,因为这个查询使用了索引,所以这是也使用了BtreeCursor类型的游标。如果没有使用索引,游标的类型是BasicCursor
- indexBounds:当前查询具体使用的索引。
- nscanned/nscannedObjects:表明当前这次查询一共扫描了集合中多少个文档
- millis: 当前查询所需时间,毫秒数。
- n:当前查询返回的文档数量
10.2 联合索引
更多
10.3 索引数组
更多
10.4 空间索引
mongoDB提供强大的空间索引可以查询出一定范围的地理坐标.看例子

//添加2D索引,默认会建立一个[-180,180]之间的2D索引
db.map.ensureIndex({"gis":"2d"},{min:-1,max:201})
//测试数据
var map=[{"gis":{"x":185,"y":150}},{"gis":{"x":70,"y":180}},{"gis":{"x":75,"y":180}},{"gis":{"x":185,"y":185}},{"gis":{"x":65,"y":185}},{"gis":{"x":50,"y":50}},{"gis":{"x":50,"y":50}},{"gis":{"x":60,"y":55}},{"gis":{"x":65,"y":80}},{"gis":{"x":55,"y":80}},{"gis":{"x":0,"y":0}},{"gis":{"x":0,"y":200}},{"gis":{"x":200,"y":0}},{"gis":{"x":200,"y":200}}]
for(var i = 0;i11. Map-Reduce
Map-Reduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。
db.collection.mapReduce(
function() {emit(key,value);}, //map 函数
function(key,values) {return reduceFunction}, //reduce 函数
{
out: collection,
query: document,
sort: document,
limit: number
}
)Map 函数必须调用 emit(key, value) 返回键值对。
参数说明:
- map :映射函数 (生成键值对序列,作为 reduce 函数参数)。
- reduce 统计函数,reduce函数的任务就是将key-values变成key-value,也就是把values数组变成一个单一的值value。。
- out 统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。
- query 一个筛选条件,只有满足条件的文档才会调用map函数。(query。limit,sort可以随意组合)
- sort 和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制
- limit 发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)
12. GridFS
GridFS 用于存储和恢复那些超过16M(BSON文件限制)的文件(如:图片、音频、视频等)。
GridFS 会将大文件对象分割成多个小的chunk(文件片段),一般为256k/个,每个chunk将作为MongoDB的一个文档。
GridFS 用两个集合来存储一个文件:fs.files与fs.chunks。每个文件的实际内容被存在chunks(二进制数据)中,和文件有关的meta数据(filename,content_type,还有用户自定义的属性)将会被存在files集合中。
- 利用mongoVUE
- 利用后台命令
mongofiles.exe -d gridfs put c:\a.txt #cmd
mongofiles -d gridfs list #cmd
mongofiles -d gridfs delete "a.txt" #cmd
use gridfs
db.fs.files.find().pretty()
db.fs.chunks.find({files_id:ObjectId("583e8e25858ded1b343034cc")}).pretty()13. 集群
13.1 复制
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。常见的搭配方式为:一主一从、一主多从,主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
特征:
- N个节点的集群
- 任何节点可作为主节点
- 所有写入操作都在主节点上
- 自动故障转移
- 自动恢复
db.isMaster()
13.1.1 主从复制
#8888.conf:
dbpath = D:\software\MongoDBDATA\07\8888 #主数据库地址
port = 8888 #主数据库端口号
bind_ip = 127.0.0.1 #主数据库所在服务器
master = true #确定我是主服务器
#7777.conf:
dbpath = D:\software\MongoDBDATA\07\7777 #从数据库地址
port = 7777 #从数据库端口号
bind_ip = 127.0.0.1 #从数据库所在服务器
source = 127.0.0.1:8888 #确定我数据库端口,这个配置项(source)可以用shell动态添加
slave = true #确定自己是从服务器
# 1.启动配置
mongod --config 7777.conf
mongod --config 8888.conf
# 客户端连接
mongo 127.0.0.1:7777
mongo 127.0.0.1:88882.主从复制的其他设置项
--only 从节点指定复制某个数据库,默认是复制全部数据库
--slavedelay 从节点设置主数据库同步数据的延迟(单位是秒)
--fastsync 从节点以主数据库的节点快照为节点启动从数据库
--autoresync 从节点如果不同步则从新同步数据库
--oplogSize 主节点设置oplog的大小(主节点操作记录存储到local的oplog中)
3.利用shell动态添加和删除从节点
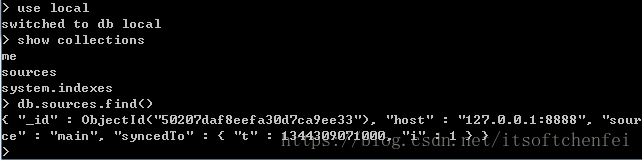
不难看出从节点中关于主节点的信息全部存到local的sources的集合中
我们只要对集合进行操作就可以动态操作主从关系
挂接主节点:操作之前只留下从数据库服务
db.sources.insert({“host”:”127.0.0.1:8888”})
删除已经挂接的主节点:操作之前只留下从数据库服务
db.sources.remove({“host”:”127.0.0.1:8888”})
13.1.2 副本集
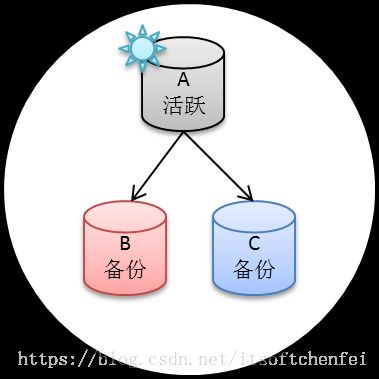
1.副本集概念
当A出现了故障,这时候集群根据权重算法推选出B为活跃的数据库,当A恢复后他自动又会变为备份数据库
#A.conf:
dbpath = D:\sortware\mongod\02\A
port = 1111 #端口
bind_ip = 127.0.0.1 #服务地址
replSet = child/127.0.0.1:2222 #设定同伴
#B.conf:
dbpath = D:\sortware\mongod\02\B
port = 2222
bind_ip = 127.0.0.1
replSet = child/127.0.0.1:3333
#C.conf:
dbpath = D:\sortware\mongod\02\C
port = 3333
bind_ip = 127.0.0.1
replSet = child/127.0.0.1:11112.初始化副本集
use admin
db.runCommand({"replSetInitiate":
{
"_id":'child',
"members":[{
"_id":1,
"host":"127.0.0.1:1111"
},{
"_id":2,
"host":"127.0.0.1:2222"
},{
"_id":3,
"host":"127.0.0.1:3333"
}]
}
})3.查看副本集状态
rs.status()
4.节点和初始化高级参数
- standard常规节点:参与投票有可能成为活跃节点
- arbiter仲裁节点:只是参与投票不复制节点也不能成为活跃节点
- passive副本节点:参与投票,但是不能成为活跃节点
高级参数:Priority 0到1000之间 ,0代表是副本节点 ,1到1000是常规节点,arbiterOnly : true 仲裁节点
//用法,参考初始化副本集命令
members:[{
"_id":1,
"host":"127.0.0.1:1111“,
"arbiterOnly": true
}]
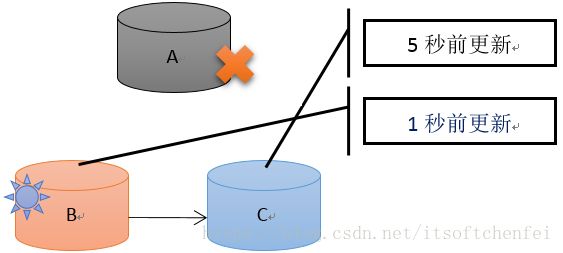
5.优先级相同时候仲裁组建的规则(B优先)
6.读写分离操作扩展读
- 一般情况下作为副本的节点是不能进行数据库读操作的,但是在读取密集型的系统中读写分离是十分必要的
- 设置读写分离(slaveOkay : true),很遗憾他在shell中无法演示,这个特性是被写到mongoDB的驱动程序中的,在java和node等其他语言中可以完成
7.Oplog
- 他是被存储在本地数据库local中的,他的每一个文档保证这一个节点操作
如果想故障恢复可以更彻底oplog可已经尽量设置大一些用来保存更多的操作信息
改变oplog大小
主库 --master --oplogSize size
13.2 分片
1.插入负载技术
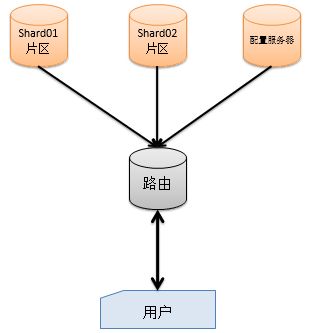
2.片键的概念和用处(利用key为片键进行自动分片)

3.什么时候用到分片呢?
- 机器的磁盘空间不足
- 单个的mongoDB服务器已经不能满足大量的插入操作
- 想通过把大数据放到内存中来提高性能
4.分片步骤
- 4.1创建一个配置服务器
- 4.2创建路由服务器,并且连接配置服务器,路由器是调用mongos命令
- 4.3添加2个分片数据库,8081和8082
- 4.5利用路由为集群添加分片(允许本地访问),切记之前不能使用任何数据库语句
db.runCommand({addshard:"127.0.0.1:8081",allowLocal:true})
db.runCommand({addshard:"127.0.0.1:8081",allowLocal:true})
- 4.6打开数据分片功能,为数据库foobar打开分片功能
db.runCommand({"enablesharding":"foobar"})
- 4.7对集合进行分片
db.runCommand({"shardcollection":"foobar.bar","key":{"_id":1}})
- 4.8利用大数据量进行测试 (800000条)
5.查看配置库对于分片服务器的配置存储
db.printShardingStatus()
6.查看集群对bar的自动分片机制配置信息
mongos> db.shards.find()
{ "_id" : "shard0000", "host" : "127.0.0.1:8081" }
{ "_id" : "shard0001", "host" : "127.0.0.1:8082" }
7.保险起见的通常配置服务器做集群
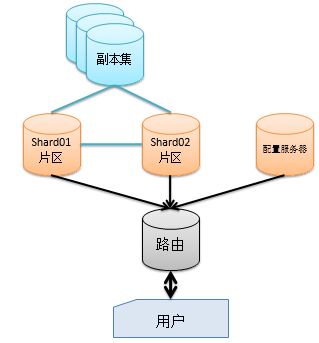
8.分片与副本集一起使用
14 管理工具
14.1 MongoVUE
略
14.2 RockMongo
略
14.3 Robo 3T
推荐
15. java-driver
可参阅另一篇《jpa-mongo》
总结,如果想了解更多有关mongdb的常见问题,请参考见另一篇《mongodb常见疑问》