【机器学习的Tricks】随机权值平均优化器swa与pseudo-label伪标签
文章来自公众号【机器学习炼丹术】
1 stochastic weight averaging(swa)
- 随机权值平均
- 这是一种全新的优化器,目前常见的有SGB,ADAM,
【概述】:这是一种通过梯度下降改善深度学习泛化能力的方法,而且不会要求额外的计算量,可以用到Pytorch的优化器中。
随机权重平均和随机梯度下降SGD相似,所以我一般吧SWa看成SGD的进阶版本。
1.1 原理与算法
swa算法流程:

【怎么理解】:
- 对 w s w a w_{swa} wswa做了一个周期为c的滑动平均。每迭代c次,就会对这个 w s w a w_{swa} wswa做一次滑动平均。其他的时间使用SGD进行更新。
- 简单的说,整个流程是模型初始化参数之后,使用SGD进行梯度下降,迭代了c个epoch之后,将模型的参数用加权平均,得到 w S W A w_{SWA} wSWA,然后现在模型的参数就是 w S W A w_{SWA} wSWA,然后再用SGD去梯度下降c个epoch,然后再加权平均出来一个新的 w S W A w_{SWA} wSWA.
SWA加入了周期性滑动平均来限制权重的变化,解决了传统SGD在反向过程中的权重震荡问题。SGD是依靠当前的batch数据进行更新,寻找随机梯度下降随机寻找的样本的梯度下降方向很可能并不是我们想要的方向。
论文中给出了一个图片:
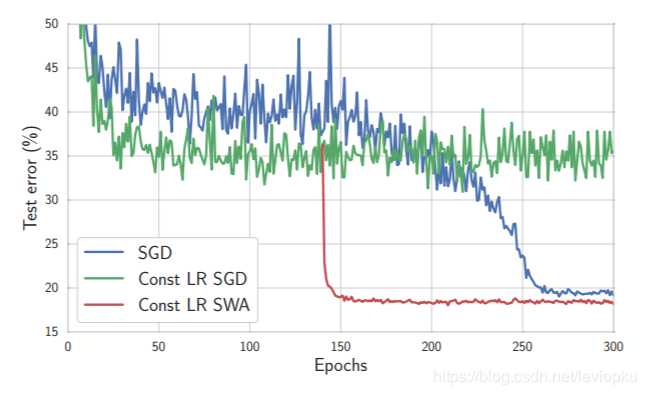
- 绿线是恒定学习率的SGD,效果并不好,直到SGD在训练的过程中所见了学习率,才可以得到一个收敛的结果;
- 而使用Stochastic weight averaging可以在学习率恒定的情况下,快速收敛,而且过程平稳。
1.2 python与实现
这里讲如何在pytorch深度学习框架中加入swa作为优化器:
from torchcontrib.optim import SWA
# training loop
base_opt = torch.optim.SGD(model.parameters(), lr=0.1)
opt = torchcontrib.optim.SWA(base_opt, swa_start=10, swa_freq=5, swa_lr=0.05)
for _ in range(100):
opt.zero_grad()
loss_fn(model(input), target).backward()
opt.step()
opt.swap_swa_sgd()
如果使用了swa的话,那么lr_schedule这个方法就不需要在使用了,非常的方便。
【关于参数】:
使用swa的时候,就直接通过
torchcontrib.optim.SWA(base_opt,swa_start,swa_greq,swa_lr)
来封装原来的优化器。
- swa_start:是一个整数,表示经过swa_start个steps后,将学习率切换为固定值swa_lr。(在swa_start之前的step中,lr是0.1,在10个steps之后,lr变成0.05)
- swa_freq:在swa_freq个step优化之后,会将对应的权重加到swa滑动平均的结果上,相当于算法中的c;
- 使用opt.swap_swa_sgd()之后,可以将模型的权重替换为swa的滑动平均的权重。
1.3 关于BN
这里有一个问题就是在BatchNorm层训练的时候,BN层中也是有两个训练参数的,使用 w s w a w_{swa} wswa重置了模型参数,但是并没有更新BN层的参数,所以如果有bn层的话,还需要加上:
opt.bn_update(train_loader,model)
2 Pseudo-Label
- 伪标签
- 这是一种半监督的方法。其实非常简单,就是对于未标记的数据,许纳泽预测概率最大的标记作为该样本的pseudo-label,然后给未标记数据设置一个权重,在训练过程中慢慢增加未标记数据的权重。
这个方法的loss如下:
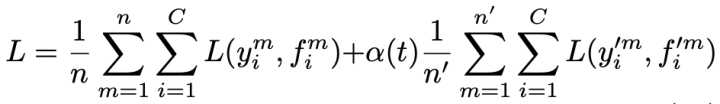
非常好理解了,前面一项就是训练集的loss,后面是测试集的loss,然后用一个 α ( t ) \alpha(t) α(t)来做权重。
然后这个 α ( t ) \alpha(t) α(t)就是随着训练的迭代次数增加而慢慢的线性增加(如果按照原来的论文中的描述):

【一些关于pseudo-label的杂谈】
这个方法提出在2013年,然后再2015年作者用entropy信息熵来证明这个方法的有效性。但是证明过程较为牵强。这个伪标签我在2017年的一个项目中想到了,但是不知道可行不可行自己当时也无法进行证明,就作罢了,没想到现在看到同样的方法在2013年就提出来了。有点五味杂陈哈哈。
参考文献:
-
Izmailov, Pavel, et al. “Averaging weights leads to wider optima and better generalization.” arXiv preprint arXiv:1803.05407 (2018).
-
Grandvalet, Yves, and Yoshua Bengio. “Semi-supervised learning by entropy minimization.” Advances in neural information processing systems. 2005.