搭建实时处理详细过程
scala+spark+flume+kafka实现大数据实时处理
此教程仅用于简单的单机环境搭建,实现效果就是可以监测某个文件夹下一个log文件内容的变化。
进阶用法请参考其它教程。
1.确保安装jdk 我的是1.8(建议)
2.安装zookeeper
首先下载,然后解压,打开解压得到的文件夹,找到conf文件夹打开,将zoo_sample.cfg重命名成zoo.cfg
在zoo.cfg文件中加入
dataDir=D:\data\zookeeper
dataLogDir=D:\logs\zookeeper
配置环境变量,变量名:ZOOKEEPER_HOME ,变量值:zookeeper的目录地址(如:D:\zookeeper\zookeeper-3.4.13)
并在Path后添加 %ZOOKEEPER_HOME%\bin(不要忘记用分号隔开)
(我的还是会报错,可能是bug,继续安装kafka即可)
3.安装kafka
首先下载,然后解压,进入config目录,编辑 server.properties文件,找到并编辑log.dirs= E:\bigdata\kafka_2.11-0.8.2.2\logs(自定就行,后面如果是windows系统要用到这个路径),找到并编辑zookeeper.connect=localhost:2181。表示本地运行。
(Kafka会按照默认,在9092端口上运行,并连接zookeeper的默认端口:2181)
启动zookeeper,格式大概是这样,E:\bigdata\kafka_2.11-0.8.2.2>bin\windows\zookeeper-server-start.bat config\zookeeper.properties
启动kafka,格式大概是这样, E:\bigdata\kafka_2.11-0.8.2.2>bin\windows\kafka-server-start.bat config\server.properties
如果出现找不到系统路径,修改E:\大三文件\生产实习\大数据材料\kafka_2.11-0.11.0.1\bin\windows 的kafka-run-class.bat文件,把jdk路径变成绝对路径
IF ["%JAVA_HOME%"] EQU [""] (
set JAVA=java
) ELSE (
set JAVA="F:\jdk1.8\bin\java"
)
使用命令行创建 topic,下面为创建名为hello的topic
D:\tools\kafka_2.12-2.1.0\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1–topic hello
4.安装flume
解压安装包
进入apache-flume-1.7.0\conf文件夹中创建一个example.conf文件。
如果使用tail 命令,windows需要安装tail工具到system32文件夹下
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
# windows不支持taildir
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f E:\\log\\log.txt
#a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
#新增内容:
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = hello
a1.sinks.k1.brokerList = 127.0.0.1:9092
#该文件需要用gbk编码,所以:
#a1.sources.r1.inputCharset=GB18030
启动flume监听日志变化
apache-flume-1.8.0-bin/bin > flume-ng agent --conf …/conf --conf-file …/conf/example.conf --name a1 -property flume.root.logger=INFO,console
5.转战spark
版本是 spark 2.0 + scala 2.11
一般大家都使用编译器,以eclipse为例,需要在项目中添加jar包
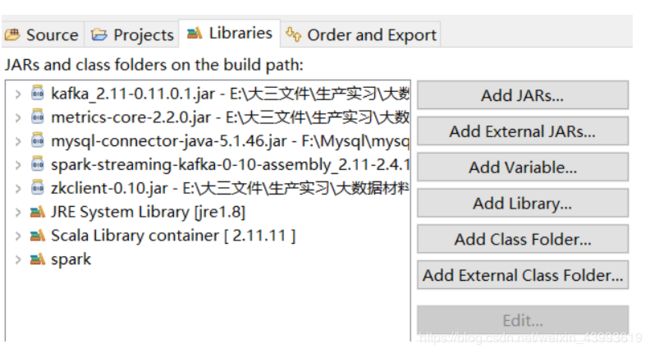
这几个是必要的,然后就可以使用spark streaming编程了
环境清单:
- Scala 2.11.11
- Spark 2.02
- Hadoop 2.7
- Zookeeper 3.4.14
- Flume 1.7.0
- Kafka 0.11
注:kafka安装包要和scala版本匹配;flume采集日志有多种方式,可以上网搜索flume source 有几种 type,根据需要更改设置;tail工具自行百度下载。
列举一些我曾经看过的不错的教程供大家参考:
日志采集系统flume和kafka有什么区别及联系
Flume+Kafka+Spark Streaming+MySQL实时数据处理
flume环境搭建、整合kafka、读取日志文件
Spark:Spark Streaming概述、DStream离散流