Python爬虫实例-爬取豆瓣电影Top250
这是本人Python爬虫实例的第二个实例,不过想来好像没有很大的难度所以适合当做新手入门的第一个爬虫。放在这里供大家参考。
本次实例爬取的网站为豆瓣电影Top250,使用到的第三方库有urllib,BeautifulSoup,以及将数据写入mysql所需的pymysql库
- 分析html代码
chrom打开豆瓣电影Top250,F12查看源代码,鼠标移至各个div查看div的覆盖情况,最终确定电影信息所在的div位置
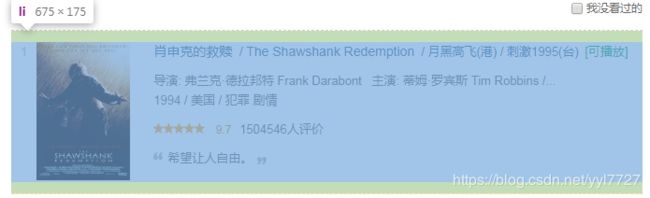
可以看到每一条电影信息是存放在一个有序列表中的。
(吐槽一下台湾同胞的翻译水平刺激1995...)
展开有序列表中的li标签继续分析

这里看出每一个电影信息放在class为item的一个div中,信息又分为图片和其他信息,本次爬取信息不考虑图片,直接展开class为info的div



在class为info的div中逐个检查div的覆盖区域,发现电影链接、标题、别名、能否播放等信息存放在class为hd的div中;导演、主演、上映年份、地区、类型、评分、评价数量、简评等信息存放在class为bd的div中。
展开hd继续分析
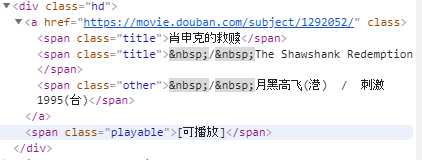
此处我们已经得到了电影链接、标题、别名、能否播放等信息的存放位置
然后看bd

现在我们已经得到了一部电影的所有信息,我们需要做的就是通过解析html来获取我们所需要的数据,剔除无用的标签、标签属性等信息。
html的解析使用BeautifulSoup库,如果不会使用可以参考我的博客:BeautifulSoup库使用,或者官方文档。
- 代码编写
首先定义一个Moive类用于保存基本信息
class Moive:
#电影链接
url=''
#电影名称
name=''
#电影别名
other=''
#是否可播放
playable=''
#导演
director=''
#主演
actor=''
#上映年份
year=''
#地区
district=''
#地区
type=''
#评分
rating=''
#评论数
comment=''定义一个list用于保存共计250个电影信息
list_moive=[]一页总共用25条电影数据,考虑循环处理每一条电影数据。在前面html分析工作中我们已经得知每一条电影数据存放在一个class为item的div中
for div in div_moive:
#TODO 循环处理每一条电影数据这样我们每次循环的div中就保存了一条电影数据,对div进行处理
moive = Moive()
#第一个div 包含 电影链接 电影名称 电影别名 能否播放等信息的处理
div_head = div.find("div",class_="hd")
moive.url = div_head.a["href"]
moive.name = div_head.find_all("span",class_="title")
moive.name = "".join([t.text for t in moive.name])
moive.other = div_head.find("span",class_="other").text.lstrip('\xa0/')
moive.playable = div.select("span.playable")
moive.playable = "".join([o.text for o in moive.playable])
#第二个div 包含 导演 主演 年份 地区 类型 星级 评论数量的处理
div_body = div.find("div",class_="bd")
tempP = div_body.select("p")
tempP = tempP[0].text.strip().replace("\n", "")
tempP = tempP.split(" ")
tempPOne = tempP[0].split(":")
if len(tempPOne) == 3:
moive.director = tempPOne[1].strip("主演: ").replace("\xa0","")
moive.actor = tempPOne[2].strip("\xa0")
tempPTwo=tempP[1].strip().replace("\xa0", "").split("/")
if len(tempPTwo) < 3:
moive.year = "暂无"
moive.district = "暂无"
moive.type = "暂无"
else:
moive.year = tempPTwo[0]
moive.district = tempPTwo[1]
moive.type = tempPTwo[2]
#第三个div 包含评分 评价数量的处理 该div在div_body中
div_star = div_body.find("div",class_="star")
moive.rating = div_star.find("span",class_="rating_num")
moive.rating = moive.rating.text
moive.comment = div_star.find_all("span")
moive.comment = moive.comment[3].text.strip("人评价")
list_moive.append(moive)
现在我们就完成了第一页25条数据的处理,那如何处理后续的9页。首先点击第二页观察url的变化情况
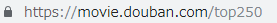
变为
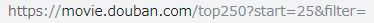
观察url变化情况后考虑如果将25修改为0能否显示第一页的数据
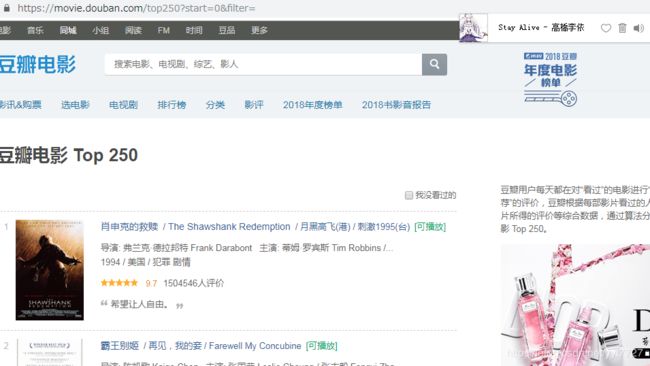
实测可行,那么我们就不需要对第一页的url进行特殊判断,现在需要一个10次的循环
for x in range(1, 11):
前面每一页电影的处理封装为一个方法进行调用。
start = (x-1) * 25
url = "https://movie.douban.com/top250?start={0}&filter=".format(start)
getOnePage(url)
print("抓取第 {0}\t页成功".format(x))
- 运行结果
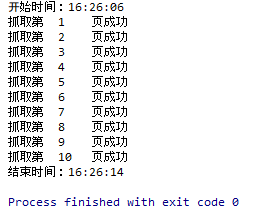
- 写入数据库
def writeInDatabase(list):
conn=pymysql.connect(host="127.0.0.1",port=3306,user="root",password="1111",database="PythonStudy",charset="utf8")
for i in range(len(list)):
cursor = conn.cursor()
sql = "INSERT INTO douban_movie250(url,moviename,nickname,playable,daoyan,zhuyan,year,district,type,rate,count) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s);"
url=list_moive[i].url
moviename=list_moive[i].name
nickname=list_moive[i].other
playable=list_moive[i].playable
daoyan=list_moive[i].director
zhuyan=list_moive[i].actor
year=list_moive[i].year
district=list_moive[i].district
type=list_moive[i].type
rate=list_moive[i].rating
count=list_moive[i].comment
try:
# 执行SQL语句
cursor.execute(sql, [url, moviename, nickname, playable, daoyan, zhuyan, year, district, type, rate, count])
# 提交事务
conn.commit()
except Exception as e:
# 有异常,回滚事务
conn.rollback()
#用完记得关!!
cursor.close()
conn.close()

- 完成!
- 源码
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pymysql
from Moive import Moive
import time
list_moive=[]
def getOnePage(url):
htmlCode = urlopen(url)
bs = BeautifulSoup(htmlCode,"html.parser")
#获取本页所有电影信息的div
div_moive = bs.select("div.item")
#循环对每一个电影进行处理
for div in div_moive:
moive = Moive()
#第一个div 包含 电影链接 电影名称 电影别名 能否播放等信息的处理
div_head = div.find("div",class_="hd")
moive.url = div_head.a["href"]
moive.name = div_head.find_all("span",class_="title")
moive.name = "".join([t.text for t in moive.name])
moive.other = div_head.find("span",class_="other").text.lstrip('\xa0/')
moive.playable = div.select("span.playable")
moive.playable = "".join([o.text for o in moive.playable])
#第二个div 包含 导演 主演 年份 地区 类型 星级 评论数量的处理
div_body = div.find("div",class_="bd")
tempP = div_body.select("p")
tempP = tempP[0].text.strip().replace("\n", "")
tempP = tempP.split(" ")
tempPOne = tempP[0].split(":")
if len(tempPOne) == 3:
moive.director = tempPOne[1].strip("主演: ").replace("\xa0","")
moive.actor = tempPOne[2].strip("\xa0")
tempPTwo=tempP[1].strip().replace("\xa0", "").split("/")
if len(tempPTwo) < 3:
moive.year = "暂无"
moive.district = "暂无"
moive.type = "暂无"
else:
moive.year = tempPTwo[0]
moive.district = tempPTwo[1]
moive.type = tempPTwo[2]
#第三个div 包含评分 评价数量的处理 该div在div_body中
div_star = div_body.find("div",class_="star")
moive.rating = div_star.find("span",class_="rating_num")
moive.rating = moive.rating.text
moive.comment = div_star.find_all("span")
moive.comment = moive.comment[3].text.strip("人评价")
list_moive.append(moive)
## 抓取整个豆瓣电影Top250的函数定义
def getTop250():
print(''.join("开始时间:{0}").format(time.strftime('%H:%M:%S',time.localtime(time.time()))))
## 每次抓取一页数据
for x in range(1, 11):
start = (x-1) * 25
url = "https://movie.douban.com/top250?start={0}&filter=".format(start)
getOnePage(url)
print("抓取第 {0}\t页成功".format(x))
print(''.join("结束时间:{0}").format(time.strftime('%H:%M:%S',time.localtime(time.time()))))
def writeInDatabase(list):
conn=pymysql.connect(host="127.0.0.1",port=3306,user="root",password="1111",database="PythonStudy",charset="utf8")
for i in range(len(list)):
cursor = conn.cursor()
sql = "INSERT INTO douban_movie250(url,moviename,nickname,playable,daoyan,zhuyan,year,district,type,rate,count) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s);"
url=list_moive[i].url
moviename=list_moive[i].name
nickname=list_moive[i].other
playable=list_moive[i].playable
daoyan=list_moive[i].director
zhuyan=list_moive[i].actor
year=list_moive[i].year
district=list_moive[i].district
type=list_moive[i].type
rate=list_moive[i].rating
count=list_moive[i].comment
try:
# 执行SQL语句
cursor.execute(sql, [url, moviename, nickname, playable, daoyan, zhuyan, year, district, type, rate, count])
# 提交事务
conn.commit()
except Exception as e:
# 有异常,回滚事务
conn.rollback()
#用完记得关!!
cursor.close()
conn.close()
## 调度函数执行抓取
getTop250()
##写入数据库
writeInDatabase(list_moive)
- moive类
class Moive:
#电影链接
url=''
#电影名称
name=''
#电影别名
other=''
#是否可播放
playable=''
#导演
director=''
#主演
actor=''
#上映年份
year=''
#地区
district=''
#地区
type=''
#评分
rating=''
#评论数
comment=''