【Active Learning - 03】Adaptive Active Learning for Image Classification
主动学习系列博文:
【Active Learning - 00】主动学习重要资源总结、分享(提供源码的论文、一些AL相关的研究者):https://blog.csdn.net/Houchaoqun_XMU/article/details/85245714
【Active Learning - 01】深入学习“主动学习”:如何显著地减少标注代价:https://blog.csdn.net/Houchaoqun_XMU/article/details/80146710
【Active Learning - 02】Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally:https://blog.csdn.net/Houchaoqun_XMU/article/details/78874834
【Active Learning - 03】Adaptive Active Learning for Image Classification:https://blog.csdn.net/Houchaoqun_XMU/article/details/89553144
【Active Learning - 04】Generative Adversarial Active Learning:https://blog.csdn.net/Houchaoqun_XMU/article/details/89631986
【Active Learning - 05】Adversarial Sampling for Active Learning:https://blog.csdn.net/Houchaoqun_XMU/article/details/89736607
【Active Learning - 06】面向图像分类任务的主动学习系统(理论篇):https://blog.csdn.net/Houchaoqun_XMU/article/details/89717028
【Active Learning - 07】面向图像分类任务的主动学习系统(实践篇 - 展示):https://blog.csdn.net/Houchaoqun_XMU/article/details/89955561
【Active Learning - 08】主动学习(Active Learning)资料汇总与分享:https://blog.csdn.net/Houchaoqun_XMU/article/details/96210160
【Active Learning - 09】主动学习策略研究及其在图像分类中的应用:研究背景与研究意义:https://blog.csdn.net/Houchaoqun_XMU/article/details/100177750
【Active Learning - 10】图像分类技术和主动学习方法概述:https://blog.csdn.net/Houchaoqun_XMU/article/details/101126055
【Active Learning - 11】一种噪声鲁棒的半监督主动学习框架:https://blog.csdn.net/Houchaoqun_XMU/article/details/102417465
【Active Learning - 12】一种基于生成对抗网络的二阶段主动学习方法:https://blog.csdn.net/Houchaoqun_XMU/article/details/103093810
【Active Learning - 13】总结与展望 & 参考文献的整理与分享(The End…):https://blog.csdn.net/Houchaoqun_XMU/article/details/103094113
【2013-CVPR】Adaptive Active Learning for Image Classification
阅读时间:
-
20181023:摘要
-
20181024:Related Work
-
20181025:Uncertainty Measure、Information Density Measure、A Combination Framework
-
20181026:all of the left…
衍生的参考资料:
- http://image-net.org/download-attributes
一些需要进一步理解的关键字:
-
prior density:
-
information density:
-
dense region:
-
sparse region:
-
mutual information:is a quantity that measures the mutual dependence of two sets of variables
-
representativeness measure.
-
Gaussian Process Framework:A Gaussian Process is a joint distribution over a (possibly infinite) set of random variables, such that the marginal distribution over any finite subset of variables is multivariate Gaussian.
-
symmetric positive definite Kernel function:对称正定的核函数
论文(2013 - CVPR):
【2013-CVPR】Adaptive Active Learning for Image Classification.pdf
摘要:
近期,主动学习在计算机视觉领域引起广泛的关注。因为主动学习旨在减少时间和花费成本,在此基础上为视觉数据分析提供高质量的标注样本。计算机视觉领域现有的大多数主动学习方法都是应用 Uncertainty 作为样本的筛选策略。虽然 Uncertainty 策略在很多场景下取得了有效的成果,但在"存在大量未标注样本"场景下,效果往往不佳(倾向于离群点)。本研究中,作者尝试提出一种新颖的自适应的主动学习方法,将“information density”和“most uncertainty”等两种策略进行组合,进而筛选出 critical instances 给专家标注,最后对分类模型进行训练。本研究的实验部分包括计算机视觉领域中2个基础的任务:1)object recognition、2)scene recognition,验证本文提出方法的有效性。
阅读感想(hcq):
what the fk:主动学习相关的论文在2013年就登上 CVPR 了,提出了“information density + most uncertainty”的样本筛选策略。后续要仔细研究研究这篇论文的各种细节!【20181023 - 16:08:25】**
Introduction:摘要
图像分类在计算机视觉研究中是一个留存已久的问题,并且遗留了一个的主要挑战:由于“形状、颜色、尺寸、环境”等因素造成图像之间广泛的类间多样性。为了构建一个鲁棒的图像分类器,往往需要大量的标注样本进行训练。例如,文献[33]将10000个手写体数字的样本用于训练分类器。准备大量的标注样本需要巨大的时间和金钱开销。另一方面,在人类视觉系统中存在一个令人着迷的特征:我们仅仅使用少量的标注训练样本就能够达到较好的分类效果(意思是说,人类的视觉系统非常强大,你要对一些物体进行分类,只需要少部分标注样本进行学习即可)。那么,计算机通过可靠的机器学习算法是否也能够达到这种效果?这就是本研究的动机。作者旨在开发一种有效的主动学习方法,在有限的少数标注样本的情况下,训练一个较好的分类器。
在机器学习研究中,如何尽可能的减少样本标注代价并且训练一个较好的分类器是一项关键的挑战(critical challenge)。在很多情况下,随机选择未标注样本给专家标注往往比较低效,因为一些不具有信息量的样本以及一些冗余的样本很有可能被选中(浪费标注代价,因为这些样本基本上无法提高模型的性能,甚至有可能降低模型的性能)。主动学习方法被用于控制标注的过程,主要目的就是减少样本的标注代价。近期,主动学习在计算机视觉引起广泛的关注[3, 14, 13, 15, 16],特别是基于未标注样本池的场景(pool-based setting)。然而,这些研究仅仅通过最不确定性指标(most uncertainty measures)计算样本的信息量。他们认为样本具有更高的不确定性就更应该优先被筛选出来标注。尽管通过最不确定性指标筛选最有信息的样本在很多场景下取得了有效的成果,但是他们仅仅是根据当前分类模型获取样本间的关系**(the relationship of the candidate instance;疑问:是样本之间的关系吗?不只是计算每个样本的不确定性吗?),而忽略了未标注样本之间的数据分布信息(引入半监督学习,是不是就可以利用未标注样本之间的信息?)。
仅仅利用最不确定性指标可能导致筛选出一些没用的样本。例如,未标注样本之间存在某些离群样本,这些样本对当前分类器而言不确定性往往很高(很容易被优先选择给专家标注),然而离群样本不仅对提升分类器性能没有帮助,反而可能降低性能。因此,在开发一个主动选择策略时,除了考虑基于分类器的最不确定性指标以外,也应该考虑其他有可能影响的指标。
本研究中,作者提出一种新颖的自适应主动选择策略,在样本选择时,同时利用了标注样本和未标注样本等信息。作者提出的筛选指标是一种自适应的组合方法,包括两种形式:1)基于当前分类器的最不确定性指标;2)一种信息密度形式,能够衡量候选样本和未标注样本之间的相互信息(感觉这就是文本的重点了:and
an information density term that measures the mutual information between the candidate instance and the remaining
unlabeled instances)**。作者通过设置权重的方式对这两种形式进行组合,并通过选择权重参数去最小化分类器在未标注样本之间的分类误差,从而达到一种自适应的权重调整。作者在一些图像分类数据集上进行实验,验证了本研究提出方法的有效性。
Related Work:相关工作
大量关于主动学习技术的被发表在各种文献中。大多数文献都是聚焦于研究如何在每次筛选出一个最具有信息量的未标注样本。大多数研究是基于较短浅的决策,仅仅基于当前状态的分类器使用最不确定性指标原则去筛选出最优先被标注的未标注样本。文献[16, 26]中,通过计算信息熵(entropy)表示最不确定的样本(the most uncertain instance is taken as the one that has the largest entropy on the conditional distribution over its labels)。SVM 选择离支持向量最近的样本的作为最不确定的样本[2, 25, 28]。基于委员会的筛选算法(Query-by-committee)通过训练一组分类器委员,然后以委员投票的方式决定筛选哪个样本作为最不确定的样本。
上述主动学习策略存在一个较明显的不足:他们仅仅基于当前分类器决定哪个样本是最不确定的,却忽略了大量未标注样本之间的信息。如上文分析的那样,上述的选择策略更倾向于(prone to)选择离群样本(如果这组数据存在很多离群样本的话,那么训练得到的分类器性能肯定会大大降低)。然而,主动学习的目标是产生一个具有泛化能力且分类精度较高的分类器,能够适用于目标领域中未经过模型训练的样本(unseen instance in the problem domain)。虽然不能直接得到domain的分布,但是能够通过大量未标注样本池获得相关的信息。
**已提出很多主动学习方法利用标注样本的信息去最小化分类器的泛化误差(minimize the generalization error)。在文献[24]中,根据样本的后验估计通过最大化未标注样本之间期望误差(expected error reduction),从而直接最小化分类器的泛化误差(有点不知道在讲啥,应该是文献24期望筛选的样本是那些能够最大化未标注样本的expected error reduction,从而达到最小化分类器的泛化误差,具体细节还得看原论文)。还有一类主动学习算法通过减少模型的方差间接的减少分类器的泛化误差,包括基于统计方法的文献[4];此外,文献[35]也是类似的方法,基于 Fisher 信息筛选最优样本。以上关于减少泛化误差(generalization error minimization)**的方法都有一个共同的问题:计算代价昂贵。
**另一类主动学习方法使用大量的启发式指标去利用未标注样本的信息。**文献[19, 32]通过使用未标注样本的先验密度(prior density)p(x)作为不确定性指标的权重,从而达到利用未标注样本的目的。文献[26]提出一种相似的框架,使用cosine distance衡量信息密度(information density)。文献[6, 20]将聚类方法和主动学习方法进行结合,进而同时利用了标注样本和未标注样本的信息。在文献[10 ,17]中,优先选择的样本是为了最大化“基于Gaussian Process models被选中的样本和剩下的未被选中的样本”之间的信息增量。文献[23]通过利用未标注样本信息改进了 query-by-committee 方法。文献[11]尝试去筛选的最优样本使得选中的样本和剩下的未标注样本之间的相关信息最大化,含蓄地利用了未标注样本之间的聚类信息(这段翻译起来有点不不知道在讲啥,哈哈,后续有时间去看看原论文)。
在计算机视觉领域中,研究者将主动学习应用到图像/视频标注[16, 34, 31],图像/视频检索[29, 12]和识别[30, 15, 13, 22, 14]。文献[29]将主动学习应用到目标检测中,旨在处理大量的在线爬虫图像。文献[14]将基于间隔(margin-based)的不确定性指标推广到多类案例中。文献[22]提出一种2维空间上的主动学习方法,筛选出一对样本而不仅仅是一个样本(不是很理解,值得好好看看)。文献[13]介绍一种基于变形KNN(a probabilistic variant of a KNN method)的主动学习方法。文献[15]在二分类问题上使用 Gaussian Process 作为概率预测模型去直接获取样本的不确定估计值。
虽然有很多不同的预测模型应用到这些方法中,但他们在筛选样本时都是使用简单的不确定性指标的主动选择策略。因此,这些方法都存在一个共同缺陷:忽略了大量未标注样本之间的分布信息。在本研究中,作者针对图像分类任务提出一种新的主动学习方法,解决了不确定性指标的内在限制(overcomes the inherent limitation of uncertainty sampling)。
Proposed Approach:本研究提出的方法
根据当前给定分类器进行鉴定哪个样本最应优先被筛选时,不同主动学习策略有不同的优势。本节中,作者展示一种新颖的主动学习方法,以自适应的方式结合了不同选择策略的优势。主要包括如下3个关键部分:1)一种不确定性指标;2)一种信息密度的衡量;3)一种自适应的组合框架。作者将逐一介绍这3个关键部分。此外,作者提出的方法是基于概率分类模型(在本研究的实验中使用逻辑回归模型)。
一些符号的说明:
Uncertainty Measure
Uncertainty Sampling 是最简单、最常用的一种主动学习策略,旨在选择最不确定的样本给专家标注。对于概率分类模型,Uncertainty Measure 被定义为样本类别Y的条件熵(conditional entropy):给定一个样本x,对应类别 Y 的条件熵如下:
(emmm,这部分不是重点,而且有点重复,直接贴图了)
Information Density Measure
为了解决 uncertainty sampling 策略的缺陷,作者在筛选样本的时候也考虑了未标注样本的信息。本研究的动机是找到最富有信息的样本构成模型输入的分布,从而提升目标分类器的泛化性能。虽然输入的分布(input distribution)通常是未给定,但我们可以通过大量的未标注样本逼近输入空间(input space)。文献[5, 27]在半监督学习的相关工作中已经证明了未标注样本的分布对训练一个较好的分类器非常有帮助。(Intuitively)显然,我们更倾向于选择那些坐落于密集区域的未标注样本,因为这些样本比坐落于稀疏区域的样本更具有信息量(意思是说,可以通过密集/稀疏性去表示样本所具有的信息量)。因此,作者使用 information density 形式去表示剩下的未标注样本的信息量。值得注意的是,作者在本研究中通过 Gaussian Process framework 将“信息密度程度(information density measure)”定义为候选样本和剩下的未标注样本之间的相互信息。(感觉这句话很重要,但翻译得不够,原话:Specifically, in this work, we define the information density measure as the mutual information between the candidate instance and the remaining unlabeled instances within a Gaussian Process framework.)
Mutual information 是一个衡量两组变量之间的相互依赖性的值,比文献[19, 32, 27]中使用的 marginal density p(x) 更直观的代表性指标,同样也比文献[26]使用的 cosine distance 更 principled representativeness measure。作者将基于信息密度指标(information density measure) 的相互信息量(multual information)定义为:![]()
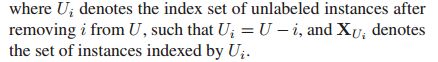
作者使用 Gaussian Process Framework 去计算公式(3)中的信息熵(entropy terms)。Gaussian Process 表示在一组(可能无穷大)随机变量的联合分布,因此。在本研究的问题中,作者将每个样本和一组随机变量联系起来(we associate a random variable X (x) with each instance x)。然后,使用一个对称正定核函数 K(·, ·) 去生成一个协方差矩阵,因此σ = K(xi, xi),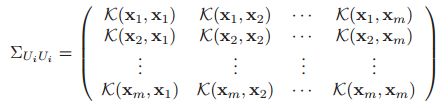


(协方差矩阵其实就是一个定义在所有未标注样本上的核矩阵。一个较通用的核函数是高斯核)
根据多元高斯分布(multivariate Gaussian distribution)的性质,
A Combination Framework
分别定义好“uncertainty measure”和“information density”等两个衡量指标之后,作者的下一个目标是将两者的优势进行结合。最主要的想法就是筛选的样本既要满足“基于当前分类器是最不确定的”,又要满足“相对剩下的未标注样本是非常富有信息量的(very informative)”。因此,将这些样本给分类器进行训练后,相对其他未被筛选的未标注样本更能够提升预测精度。作者将上述的组合方式写成如下通用形式**(20181026-09:56,感觉公式(9)的值,越大表示该样本具有越多的信息量,more informative):![]()
其中,0<=β<=1 是两种衡量指标的权衡控制参数。如公式(9)所示,尽管f(x)是一种判别性的指标,而信息密度指标d(xi)1-β是根据输入空间进行计算,并且跟目标判别分类器模型没有直接的联系。使用类似这种启发式组合指标,作者最主要的目的是筛选出最具有信息量的样本去减少分类器模型的泛化误差,而且不用花费昂贵的计算代价(steps of retraining classification model for each candidate instance)。
(这部分主要介绍了作者提出的组合框架中,唯一需要较大计算量的部分是“计算矩阵的逆”。作者巧妙的引入文献[36]的方法缓解了计算量)上述的组合方式中,唯一需要较昂贵计算量的操作是计算计算公式(5)中的条件协方差(conditional covariance,σ)时,计算矩阵(Σ)的逆。对每个候选样本i∈U都计算一个矩阵的逆是非常低效的。作者采用了文献[36]中的一种快速算法,通过移除行/列去计算矩阵的逆(compute the inverse matrix with one row/column removed),从而缓解了计算的问题:对于任一候选样本i∈U,我们可以通过给定的Σ 和 Σ 直接计算矩阵的逆(Σ ),详情请参考文献[36]。因此,我们只需要在主动学习过程的开始阶段做一个矩阵求逆的操作即可。此外,还有一个能够为处理大量未标注样本较少计算代价的方法是使用二次抽样(subsampling)。换句话说,在主动学习的每次迭代过程中,首先可以对所有未标注样本进行随机采样产生一个子集,然后限制只能从这个子集中筛选候选样本。(是个值得借鉴的方法)
文献[26]已经提出了一种跟本研究的式(9)相似的组合策略,形如 [f(x)d(x)]。然而,文献[26]使用候选样本和所有未标注样本之间的平均 cosine 距离作为 information density measure。此外,文献[26]中的参数β式预训练的权重(应该是想说,它是个预训练好的定值)。作者将在下文介绍,在主动学习的每一轮迭代中,从一个事先定义好的范围中,自适应选择最优参数β。
(阅读感想:作者提出的组合策略其实并不是凭空而出的,也是参考了文献[26]提出的组合策略,形式大同小异。较大的亮点就是将组合权重β改装成自适应的方式。)**
Adaptive Combination
关于作者在上文提到的组合策略中,一个重要的问题就是选择一个合适的权重参数β(0<=β<=1)。β的值控制着两种衡量指标的重要程度(也就是本次主动学习迭代中,更侧重于应用哪个指标进行筛选样本)。当β>0.5时,uncertainty measure 被视为比 information density 更加重要,因为相对更大的权重置于 uncertainty measure 上。举个极端的例子,当 β=1 时,此时的组合策略就仅仅使用了 uncertainty measure。同样地,当 β < 0.5 时,更大的权重被置于 information density 上。然而,对于每个不同的数据集,很难去事先定义好这两种评价指标的重要程度(就是说,对于不同的数据集,β对应不同的最优解)。此外,根据主动学习过程的每个阶段以及不同的迭代,可以通过动态地修改β值进而找到权衡两种不同指标重要程度的最优解。为了在每次迭代中尽可能选择最佳样本,我们需要动态地评估两种评价指标的相对信息量,从而决定每次迭代筛选时 β 的值。不幸的是,这是一个非常难搞定的问题。(难题出现了,或许下文是个亮点)
在本研究中,作者提出了选择一个简单且非短视的步骤(a simple nonmyopic step)去自适应地从一组事先定义好的候选值中选择一个合适值作为β。更加明确来讲,在主动学习的每次迭代中,作者首先分别对每个候选样本 xi 计算 uncertainty measure f(x) 以及 information density measure d(x)。然后,作者依次从事先定义好的集合B中选出一个值作为β值,每个β值应用到对应不同的样本中(此时,有 b = length(B) 个样本,分别一个 β 值)。例如,事先给定集合 B = [0.1, 0.2, … , 0.9, 1.0],此时就可以选择b=10个样本,每个样本对应集合B中的一个值,即beat值。然后,根据公式(9)对每个样本(此时,每个样本都对应一个β值)进行计算,筛选出最优的β值就相当于从b个样本中筛选出最具有信息量的样本。作者提出一种β的选择方式,通过在未标注的候选样本中最小化期望分类误差。对于来自候选样本集合S中的每一个候选样本x,作者使用P(y|x, θ) 方式得到样本x的标签概率值(理解:基于当前模型θL,给定样本x,就可以计算得到对应的概率值y,并作为样本的标签)。按照这种方式依次计算候选样本集合S中的每个候选样本,得到对应的“样本-标签 = ”小队,然后将这些带有标签的样本加入训练数据集中,重新训练(retrian)分类器模型。we can measure the prediction loss of the new classifier on all unlabeled instances(这是原论文的描述,字面意思是说,通过得到的新的分类器就可以在所有未标注样本中得到预测损失。这里的“all unlabeled instances”仅仅是指候选样本,还是 unlabeled pool 中的所有未标注样本,如是pool中的未标注样本,那这些没有标签的样本怎么得到 prediction loss?可以计算得到 prediction value,但是没有标签怎么计算loss?【20181026-12:22】读完全文后再来思考这个问题:这里指的是候选样本集合,并不是所有的未标注样本,可以参考论文中的算法1)The expected loss of the candidate instance x can be computed as a weighted sum of the prediction loss obtained using all possible labels y under the distribution P (y|x, θ). Specifically, we conduct instance selection from the set S using the following equation:
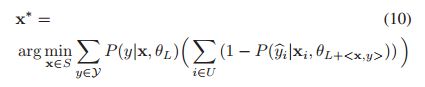
其中,θ表示原来的训练数据集中加入新的标注样本
上述介绍的主动学习算法如下算法1所示。虽然分类器重新训练需要计算分类器的期望误差,但这个过程仅仅需要对非常少量的事先选择好的候选样本集S。计算代价能够控制在合理的范围内。

(-- start
Emmm,原文中没有对给出的算法1流程做解释。基于对论文的精读,理解如下:
算法1中用到的相关公式:
(1)uncertainty measure
(2)information density![]()
(9)组合:uncertainty measure + information density![]()
(10)求解最优样本: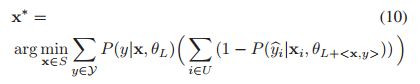
输入:训练样本集L(标注样本集),未标注样本集U,事先定义好的集合B = [0.1, 0.2, … , 1](β的候选值)
重复如下步骤,直到满足足够的样本量:
-
基于现有的标注样本集L,训练一个概率分类器;
-
for 循环,i ∈ U:
-
使用公式(1)计算 f(x)
-
使用公式(2)计算d(x)
-
使用公式(9),对于不同的β∈B,计算h(x)
-
令候选样本集合 S = 空集
-
for 循环,β ∈ B:
-
选出一个样本x,使其最大化:x = arg maxh(x)
-
将样本 x 加入候选集合 S 中:S = S ∪ x
-
使用公式(10)从候选集合S中筛选出最佳样本x*
-
将x*从未标注样本集从去除
-
专家标注:得到x对应的真实标签y,并将标注样本
– end…)
Experimental Results:实验结果
作者在3组分类数据集上验证了本研究提出方法的有效性,包括1组场景识别的数据集(13 Natural Scene Categories dataset [8],a superset of MIT Urban and Natural Scene dataset [21]),2组目标识别的数据集。
实验设置 - 数据集:
-
场景分类数据集(总共 3859 张图像)- 13 Natural Scene Categories dataset:自然场景(coast, forest, mountain, etc.)、人造场景(kitchen, tall building, street, etc.)。
-
目标识别(8677 张图像):
-
**Caltech-101:**包括背景有102个类别。本研究并不是使用全部的数据集,而是从每个类别中随机取30张图像作为本实验的数据集(总共102*30=3060张图像,称之为 Caltech101数据集)
-
**Pascal VOC 2007 datasets:**总共5011张图像(训练集+验证集)。因为本研究中没有涉及到多类标问题,因此只选择其中的单类标样本,因此最终只有2989张图像,20个物体类别。
-
实验设置 - 对比实验:
-
随机筛选:Random Sampling
-
最不确定性指标:Most Uncertainty
-
Near Optimal [10]
-
Fixed Combination [26]:cos distance 衡量 information density,使用参数 beta 进行组合 [f(x)d(x)β]
实验中的分类器模型:在上述所有对比实验中使用逻辑回归作为分类器模型,最终使用概率值表示分类的结果。
实验1:场景识别(Scene Recongnition)
首先,作者分析(conducted)了使用 GIST[21] 特征的 13 Natural Scene dataset。作者随机从整个数据集中选择了5个类别的2组子集,10个类别的3组子集。对于每一组子集,样本按照2%、68%、30%等比例分别被随机分配到标注样本集合中(训练集)、未标注样本集、测试集。每个主动学习算法先使用已有的2%训练集对模型进行训练,然后在每次迭代中依次根据不同的策略从未标注样本集中筛选最佳样本给专家标注(作者设置了最大迭代次数为100)。在本研究中,每次迭代都会产生一个带有真实标签的标注样本加入训练集,然后使用逻辑回归分类器在训练集中重新训练、在测试集中进行验证,并记录分类器的精度。
本次实验重复进行了10次并取平均值,如图下图1所示(坐标图展示的是30%的测试数据):
-
(a) 本研究提出的自适应选择策略在少数几轮迭代中,分类器就取得了较好的性能。而且,每次迭代得到的分类器性能都比其他4种对比实验的效果更好。从而证明了本研究提出的选择策略帮助模型筛选出更有代表性的样本。其中,β ∈ {0.25, 0.5, 0.75, 1}。
-
(b) 本研究提出的选择策略的优势更加突出,与实验(a)的不同之处在于:
-
©(d)(e) 是在3组10分类的子集上做实验。本文提出的自适应组合的选择策略相对其他对比方法仍是最优,表明了该策略能够适用于不同的多分类(5分类、10分类)的任务。
-
(f) 实验还尝试了在给定不同β候选集合的情况:如,β ∈ {0.25, 0.5, 0.75, 1} 的10分类任务上,仍是本文提出的方法取得最优解。表明了β取值的有效性和重要性。
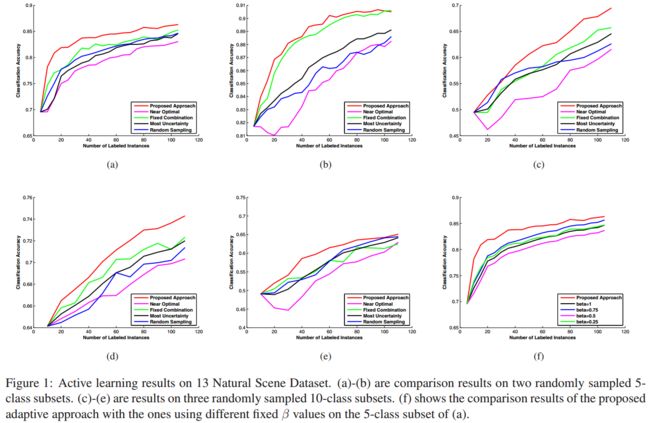
实验2:目标试别(Object Recognition)
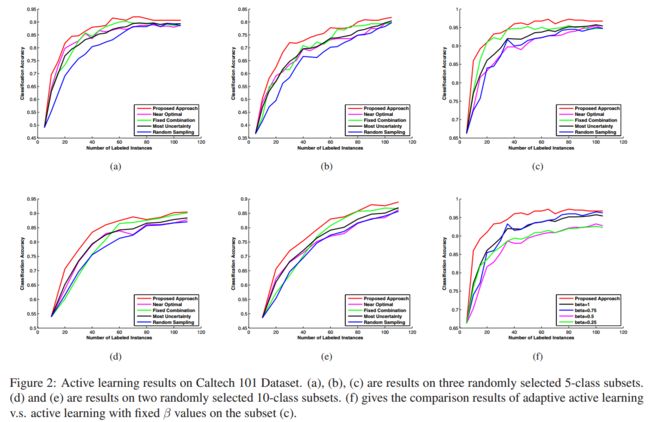
这部分的实验数据集包括:1)Pascal VOC 2007;2)Caletch101。作者使用了分别为两个数据集预先计算好的密度SIFT特征(precomputed dense SIFT features)。
Caletch101数据集中,作者制作了3个5分类的子集、2个10分类的子集,当然也是采用随机的放置方式。在如下子集的实验中,不同方法在不同的场景中有不同的优势,但仍是本研究提出的自适应组合策略取得最佳效果。
-
图2(a)(b)© 在3个5分类的子集上重复进行10次实验并取平均值,分别跟其他4个对比实验进行比较。
-
图2(d)(e) 在2个10分类的子集上使用相同的方式进行实验。
-
图2(f) 将自适应组合策略与非自适应性组合版本进行比较,设置了几个不同的 β 定值作为非自适应版本的实验(β=0.25、0.5、0.75、1.0)。实验结果又再次表明,自适应调整β值的重要性。
Pascal VOC 2007 数据集,作者分别随机制作了2组5分类的子集、1组10分类的子集。实验结果如下图3所示,仍是本研究提出的自适应组合策略取得最佳效果,自适应选择β值比定值的效果更佳。此外,作者在5分类的子集上统计了被选中样本的所属类的分布信息,如下图3(e)通过直方图进行展示,表明了来自不同类别的图像具有不一样的信息量。
综上:上述实验证实了本研究提出的自适应组合式的主动学习选择策略在三组数据集上的效果都优于本研究中的其他对比实验。
Conclusion:总结
在本研究中,作者提出一种新颖的自适应组合式的主动选择策略,包括1)uncertainty measure;2)information density,通过自适应调整2种衡量指标的权重在每次迭代中选择最佳样本给专家进行标注。自适应的特点使得能够在不同的阶段、不同场景下充分利用2种不同评价指标的优势。该方法能够有效的利用未标注样本的信息,从而提升 uncertainty sampling 的性能(uncertainty sampling 没有利用到未标注样本的信息)。本研究使用图像分类任务作为实验,本研究提出的选择策略相对其他已存在的选择策略中,能够在提升分类器性能的情况下,减少训练样本量。
精读后的总结:后续可用于大论文中的语句
总结:
这篇 CVPR-2013 的文章主要提出一种“自适应组合的主动学习策略”,通过自适应的方式在每次迭代筛选样本时,充分利用不确定性指标和信息密度(uncertainty measure and information density)等两种不同的选择策略。作者将提出的策略应用到3组图像分类(1组场景识别、2组目标识别)相关的数据集中,并与4种不同的主动选择策略进行实验对比,取得了所有实验的最佳结果。其中,值得一提的是,作者还验证了引入自适应选择的优势。
文章亮点:
-
Related Work:作者很详细的整理了截止2013年关于主动学习相关的研究。大多数主动学习相关的文章都仅仅使用样本的最不确定性指标,忽略了未标注样本的信息,带来了比较明显的缺陷就是容易选择离群样本。为了解决这个缺陷,也有一些文章开始关注未标注样本的信息(聚类方法、组合不同策略的方法)。
-
组合等两种不同的策略:文献[26]提出了一种形如 [f(x)d(x)] 的组合策略。其中,information density 是基于 cosine distance 来衡量,并且 β 是个定值。作者借鉴文献[26]的思路,将 uncertainty measure 和 information density 进行组合。其中,information density 是使用 Gaussian Process Framework 进行计算,形如公式(3)所示。
-
引入自适应权衡两种策略的特点:这是本研究中较大的亮点(作者在原文中也提到,如何衡量两种策略的重要程度是一个非常难的问题),也是相对文献[26]中最不一样的地方。作者通过自适应的方式去调整 β 的值,在每次迭代过程中充分利用两种不同策略的优势,筛选出最佳的样本。
-
在一定程度上缓解了计算代价:作者提出的自适应组合策略中唯一存在较大计算代价的是矩阵的逆运算,作者参考了文献[36]的方案,通过移除行/列去计算矩阵的逆(compute the inverse matrix with one row/column removed),从而缓解了计算的问题(详情参考原文献)。此外,作者还提出一个值得借鉴的方法:在主动学习的每次迭代过程中,首先可以对所有未标注样本进行随机采样产生一个子集,然后限制只能从这个子集中筛选候选样本。
-
实验结果一致验证了作者提出方法的有效性。