【Hive 入门 CentOS7】Hive-1.2.1入门基础 2019.10.14
Hive入门基础·非命令
- 简介
- 个人理解
- 优劣势
- 架构
- 运行机制
- 与数据库区别
- 资源网址
- 部署及命令测试
- 部署
- Cli客户端基础命令测试
- 更改默认元数据数据库
- 部署 MySQL
- 修改 Hive 配置
- Hive的JDBC访问
- Java实例
- 补 其他
- Hive Shell命令 常用选项
- cli Shell终端命令
- 查看hdfs文件系统
- cli 查看本地文件系统
- hive历史命令
- 配置简述
- hive配置文件
- log4j配置文件
- 修改配置的方式
- XML文件修改
- Shell 命令选项修改
- Cli命令修改
- 数据类型
- 原始类型
- AMSU类型
- 类型转换
- 隐式转换
- 强制转换
- 测试实例
- 数仓对象层级
简介
Hive基于Hadoop系统的 数据仓库 工具。
功能:将 结构化数据对象(eg:文件) 中的数据抽取处理并映射成一张 数据库表,并提供类 SQL 功能
实质:将H(S)QL语句通过已定义模版转换为 MapReduce 程序。
运行环境:YARN,Hadoop完全分布式
个人理解
Hive,可以表层理解为一个 Hadoop的客户端(可以运行在Linux端,也可以在Java程序中连接),并且这个客户端的所有命令设计符合SQL语法。
但其实质是一个Hadoop体系中MapReduce的一款计算框架,它预先做了大量工作——SQL实现到MapReduce实现的转换模版,这个转换模版是通用的,大家都一致的MR代码。
而 Hive 要求程序猿的工作,仅是创建一个 数据库意义上的 Table 概念,然后手动将 Hadoop 系统(HDFS)中的大数据装载至 Hive 的 Table 概念中,以这个 Table(结构性行列数据) 作为 根基 进行 类SQL 的DML操作。
当然,Hive看起来,很牛逼很简单,疯狂简化了大量MapReduce代码,但是但是但是,大多数时候需求是复杂的,工具是不完整的,所能处理的问题仅仅是已有功能的排列组合,复杂逻辑需求还得自己写MR代码。
最后,需要理解到的是,Hive一共操作2个部分,一个是 MetaStore——》元数据(数据库+表),一个是 HDFS(分布式存储仓库)——》源数据(大量数据文件)。它们两个之间的联系仅仅是被Hive执行 增删改查 CRUD操作命令关系,是两套系统(一般情况下,MetaStore存储在关系型数据库如MySQL)。
数据仓库:大而多
数据库:小而美
注:为什么叫数据仓库,而不是数据库?
①量级:数据仓库——大,例如TB,PB,EZYB。而传统数据库——小,通常都是GB,TB级别。
②分布式:数据仓库意味着对分布式存储的大量数据操作对象
③核心因素:除了符合SQL语法,数据库的其他功能都没有。比如安全、事务等等
形象化:
一个精致机械车间(数据库),有各种操作规范流程以及机械手臂,抓取运输货物。
再想象一个大工厂(数仓),里面有许多的小机器人(京东的全自动物流坞)抓取运输货物。
优劣势
优:
- 省略编写 MapReduce 程序的复杂过程。
- 通用 SQL Syntax,减少大量的学习成本
- 处理大数据量 PB EB(毕竟基于Hadoop系统)TPEZYB
- 高扩展性——可以从TB快速扩展到EB级别(因为是基于HDFS,它拥有这样的能力)
- 支持自定义函数
劣:
- 不擅长小数据处理
- HQL 能力有限,不能做过多复杂操作,例如迭代式算法等,数据挖掘方面
- 无太多可控制,调优的地方
- 不能快速查询——实时查询
- 不能以行级作为更新单位(HDFS不支持行粒度的修改,只支持以文件为单位的修改)
- 不支持事务,因为主要用来做 OLAP(联机分析处理),而 不是 OLTP(联机事务处理)
架构
客户端:Cli(Linux),JDBC+Connection Driver(Java),解析器\编译器\优化器\执行器(HQL)
元数据:Meta Store(MySQL)
Hadoop:MapReduce,YARN,HDFS(数据来源+计算)

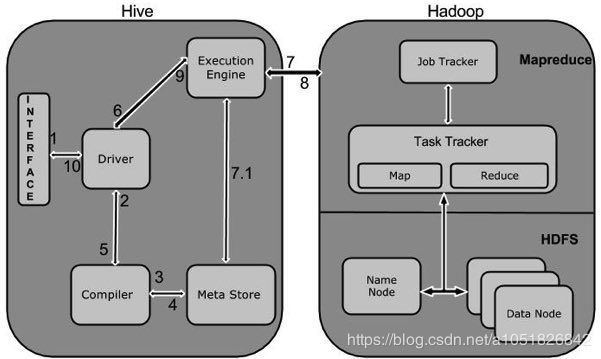
运行机制
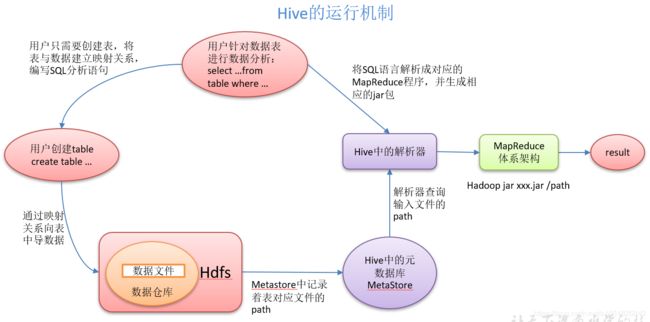
下图来源:易百教程
此图,更加清晰的可以理解到,Hive基于Hadoop体系。
同时MetaStore与Hadoop是两个完全不相干的子系统,只是Hive在这两个系统上分别操作。
与数据库区别
相同点:
与SQL语法Syntax 类似——HQL。为什么要设计为类SQL语法,只是为降低学习成本。
都可自定义用户延展函数
不同点:其他都不一样
| Hive | MySQL | |
|---|---|---|
| 查询语言 | HQL | SQL |
| 存储位置 | HDFS,分布式文件存储系统 | 本地文件系统 |
| 表更新 | 可改但禁用,覆盖追加 | 随机更新 |
| 索引 | 无(全表扫描) | 有 |
| 执行延迟 | 高(非大量数据) | 低(非大量数据) |
| 集群扩展性 | 千/万,与Hadoop保持一致 | 百台 |
| 数据规模 | TPEZB | 500w条记录 |
| 操作进程 | 多个 | 单个 |
| 索引 | 0.8之后推出简单索引 | 支持复杂索引 |
| 应用场景 | 海量数据查询 | 实时数据查询 |
资源网址
官网:http://hive.apache.org/
镜像列表:http://www.apache.org/dyn/closer.cgi/hive/
1.2.2:http://apache.mirrors.ionfish.org/hive/hive-1.2.2/apache-hive-1.2.2-bin.tar.gz
2.3.6:http://apache.mirrors.ionfish.org/hive/hive-2.3.6/apache-hive-2.3.6-bin.tar.gz
3.1.2:http://apache.mirrors.ionfish.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
Getting Started:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
中文教程:https://www.yiibai.com/hive/
参考博文:https://www.cnblogs.com/qingyunzong/p/8707885.html
部署及命令测试
提前准备:将 apache-hive-1.2.1-bin.tar.gz,上传到 CentOS 7 的 /opt/software 目录下
部署
# 1.解压 apache-hive-1.2.1-bin.tar.gz 到 /opt/module/目录下
cd /opt/software
tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /opt/module/
# 2.修改文件名为 hive-1.2.1 (与 hadoop-2.7.2 保持一致)
cd /opt/module
mv apache-hive-1.2.1-bin/ hive-1.2.1
# 3.修改 Hive 配置文件 hive-env.sh
# 3.1 复制 hive-env.sh.template 为 hive-env.sh
# 3.2 增加内容
cd conf/
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
>>
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export HIVE_CONF_DIR=/opt/module/hive-1.2.1/conf
<<
# 4.修改 Hadoop 配置文件 core-site.xml ,修改后需要重启集群
# 这里主要是,将/tmp目录的拥有者,从dr.who改为本用户atguigu
# 在默认情况下,hive是在hdfs上的/tmp目录下创建hive目录
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
# 5.启动 Hadoop 集群
sbin/start-dfs.sh
sbin/start-yarn.sh
# 6.启动 hive 客户端
cd /opt/module/hive-1.2.1
bin/hive
hive>
hive> quit;
Cli客户端基础命令测试
# 启动hive
[atguigu@hadoop102 hive]$ bin/hive
# show 数据库s
hive> show databases;
# use default数据库
hive> use default;
# show default数据库中的表s
hive> show tables;
# create 表【注意,默认分隔符,不是\t,可自定义】
hive> create table student(id int, name string);
hive> create table student(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
# desc 表结构
hive> desc student;
# show create 表详细结构
hive> show create table student;
# insert 向表插入数据
hive> insert into student values(1000,"ss");
# load 向表中加载数据文件
hive> load data local inpath '/opt/module/data/student.txt' into table student;
# select表中数据
hive> select * from student;
# 退出hive
hive> quit;
更改默认元数据数据库
Hive,默认使用 derby 数据库存储元数据,且只能单开一个Hive客户端,因为只能有一个 访问 derby 数据库的 连接。
更改,derby 为 MySQL 来存储 元数据。
部署 MySQL
提前准备:MySQL-server,MySQL-client,mysql-connector-java
# 1.查询是否已安装 MySQL,及mariadb
rpm -qa|grep MySQL
rpm -qa|grep mariadb
# 1.1如果有则进行卸载
rpm -e --nodeps mysql-libs-5.x.xxx
rpm -e --nodeps mariadb-xxx
# 2.安装MySQL服务器
rpm -ivh MySQL-server-5.6.24-1.el6.x86_64.rpm
# 2.1查询临时密码,用于登录root用户
cat /root/.mysql_secret
# 2.2启动MySQL服务
systemctl start mysql
# 3.安装MySQL客户端
rpm -ivh MySQL-client-5.6.24-1.el6.x86_64.rpm
# 3.1登录MySQL
mysql -uroot -p
# 3.2修改密码,
mysql>SET PASSWORD=PASSWORD('Root123456');
# 3.3删除其他远程访问规则,只留 where host='%' 这一条记录
mysql>select User, Host, Password from user;
mysql>update user set host='%' where host='localhost';
mysql>delete from user where Host='127.0.0.1';
mysql>delete from user where Host='::1';
mysql>flush privileges;
mysql>exit
# 4.解压 mysql-connector.jar 至 hive/lib 目录,令 hive客户端 可以访问到 mysql 数据库
tar -zxvf mysql-connector-java-5.1.27.tar.gz
cp /opt/software/mysql-libs/mysql-connector-java-5.1.27/mysql-connector-java-5.1.27-bin.jar /opt/module/hive/lib/
修改 Hive 配置
可以参考:https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties,虽然我没太看懂
# 建立自定义Hive配置文件
cd /opt/module/hive-1.2.1/conf
vim hive-site.xml
>>
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 设置MetaStore连接URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<!-- 设置连接驱动 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!-- 设置MetaStore访问用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<!-- 设置MetaStore访问密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
<description>password to use against metastore database</description>
</property>
</configuration>
<<
# end 结束,如果出现一些不可控其他问题,请尝试重启。万事不决先重启。
# 校验:在正常打开 bin/hive 后,在mysql数据库中可以发现新的数据库metastore(show databases;)
Hive的JDBC访问
Hive共有3种访问方式:
1,Shell 终端命令行(Command Line Interface)Client
2,JDBC/ODBC,基于 JDBC框架 提供的Java客户端
3,Web UI
下面简述 Linux端 基于beeline 的 JDBC 访问
Hive面向JDBC框架的访问机制——HiveServer2服务
启动 HiveServer2 服务:$ bin/hiveserver2
Linux本地访问HiveServer2的beeline客户端:$ bin/beeline
通过beeline访问实例:
$ bin/beeline
beeline> !connect jdbc:hive2://hadoop102:10000(回车)
Connecting to jdbc:hive2://hadoop102:10000
Enter username for jdbc:hive2://hadoop102:10000: atguigu(回车)
Enter password for jdbc:hive2://hadoop102:10000: (直接回车)
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop102:10000> show databases;
+----------------+--+
| database_name |
+----------------+--+
| default |
| hive_db2 |
+----------------+--+
顺带一提:HiveServer与HiveServer2
关系:HS2已经完全替代HS,解决多客户端的并发请求
两者都允许远程客户端使用多种编程语言,通过HiveServer或者HiveServer2,远程客户端可以在不启动CLI的情况下对Hive中的数据进行操作。例如远程客户端使用多种编程语言如java(JDBC),python等向hive提交请求,并取回结果。
Java实例
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveCreateTable {
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("CREATE TABLE IF NOT EXISTS "
+" employee ( eid int, name String, "
+" salary String, destignation String)"
+" COMMENT ‘Employee details’"
+" ROW FORMAT DELIMITED"
+" FIELDS TERMINATED BY ‘\t’"
+" LINES TERMINATED BY ‘\n’"
+" STORED AS TEXTFILE;");
System.out.println(“ Table employee created.”);
con.close();
}
}
//原文出自【易百教程】,商业转载请联系作者获得授权,非商业请保留原文链接:
//https://www.yiibai.com/hive/hive_create_table.html
补 其他
Hive Shell命令 常用选项
# 查询 hive 命令列表
$ bin/hive -help
# -e 不进入cli执行HQL命令
$ bin/hive -e "select id from student;"
# -f 不进入cli执行脚本文件的HQL语句
#(1)在/opt/module/datas目录下创建hivef.sql文件
$ touch hivef.sql
>>
select * from student;
<<
#(2)执行文件中的sql语句
$ bin/hive -f /opt/module/datas/hivef.sql
#(3)执行文件中的sql语句并将结果写入文件中
$ bin/hive -f /opt/module/datas/hivef.sql > /opt/module/datas/hive_result.txt
cli Shell终端命令
查看hdfs文件系统
hive> dfs -ls /;
cli 查看本地文件系统
hive> ! ls /opt/module/datas;
hive历史命令
cat /home/atguigu/.hivehistory
cat /root/.hivehistory
配置简述
配置文件均在 hive-1.2.1/conf 目录下。
hive配置文件
Hive默认配置文件:hive-default.xml
Hive用户自定义配置文件(覆盖默认配置文件属性):hive-site.xml
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
<description>location of default database for the warehousedescription>
property>
<property>
<name>hive.cli.print.headername>
<value>truevalue>
property>
<property>
<name>hive.cli.print.current.dbname>
<value>truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://hadoop102:3306/metastore?createDatabaseIfNotExist=truevalue>
<description>JDBC connect string for a JDBC metastoredescription>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
<description>Driver class name for a JDBC metastoredescription>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
<description>username to use against metastore databasedescription>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>000000value>
<description>password to use against metastore databasedescription>
property>
log4j配置文件
日志系统默认配置文件:hive-log4j.properties.template
用户自定义配置文件:hive-log4j.properties
# 默认存放在/tmp/atguigu/hive.log
hive.log.dir=/opt/module/hive/logs
修改配置的方式
XML文件修改
永久有效
Shell 命令选项修改
仅对本次hive启动有效
bin/hive -hiveconf mapred.reduce.tasks=10
Cli命令修改
此次 Hive Cli 执行有效,重启 Hive Cli 失效
# 查询 'set field;'
hive(default)> set mapred.reduce.tasks;
# 修改 'set field=value;'
hive(default)> set mapred.reduce.tasks=100;
注1:上述三种设定方式的优先级依次递增。即配置文件<命令行参数<参数声明。
注2:log4j系统级设定,只能采用前两种,Cli命令无法设置。
数据类型
data_type
| primitive_type
| array_type
| map_type
| struct_type
| union_type – (Note: Available in Hive 0.7.0 and later)
原始类型
| Hive数据类型 | Java数据类型 | 长度 | 例子 |
|---|---|---|---|
| TINYINT | byte | 1byte有符号整数 | 20 |
| SMALINT | short | 2byte有符号整数 | 20 |
| INT | int | 4byte有符号整数 | 20 |
| BIGINT | long | 8byte有符号整数 | 20 |
| BOOLEAN | boolean | 布尔类型,true或者false | TRUE FALSE |
| FLOAT | float | 单精度浮点数 | 3.14159 |
| DOUBLE | double | 双精度浮点数 | 3.14159 |
| STRING | String | 字符系列。可以指定字符集。可以使用单引号或者双引号。 | ‘now is the time’ “for all good men” |
| TIMESTAMP | 时间类型 | ||
| DATE | 时间类型 | ||
| BINARY | 字节数组 | ||
| CHAR | 字符数组 | ||
| VARCHAR | 可变字符数组 |
常用:int类型,string类型(可变字符串,理论上可存储2GB字符数)
注:未提及 DOUBLE PRECISION,DECIMAL,DECIMAL(precision, scale)
AMSU类型
| 数据类型 | 描述 | 语法示例 |
|---|---|---|
| ARRAY | 数组是一组具有相同类型和名称的变量的集合。arrayName[0] 访问 | ARRAY < data_type > |
| MAP | MAP是一组键-值对元组集合,使用数组表示法可以访问数据。key[‘value’] 访问 | MAP < primitive_type, data_type > |
| STRUCT | 和c语言中的struct类似,都可以通过“点”符号访问元素内容。field.table 访问 | STRUCT < col_name : data_type [COMMENT col_comment], …> |
| UNION | UNIONTYPE < data_type, data_type, … > |
注:非原始数据类型允许任意层次的嵌套
类型转换
隐式转换
任何数值类型,均可从低精度转换为高精度、小范围转换为大范围类型。
TINYINT——INT——BIGINT;
整数(3INT)类型、FLOAT、STRING——DOUBLE;
TINYINT、SMALLINT、INT——FLOAT;
BOOLEAN不能转换为任意类型
强制转换
格式:CAST(value AS TYPE),CAST强制转换
实例:CAST(‘1’ AS INT),将把字符串’1’ 转换成整数1;若强制类型转换失败,如CAST(‘X’ AS INT),表达式返回NULL
测试实例
//原始数据
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //列表Array,
"children": { //键值Map,
"xiao song": 18 ,
"xiaoxiao song": 19
}
"address": { //结构Struct,
"street": "hui long guan" ,
"city": "beijing"
}
}
# 创建Linux 本地test.txt数据文件
vim test.txt
>>
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
<<
注意:MAP,STRUCT和ARRAY里的元素间关系都可以用同一个字符表示,这里用“_”。
hive (default)>
create table test(
name string,
friends array<string>,
children map<string, int>,
address struct<street:string, city:string>
)
row format delimited
fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';
hive (default)>
load data local inpath "/opt/module/hive-1.2.1/data/test.txt" into table test;
hive (default)>
select friends[1],children['xiao song'],address.city from test where name="songsong";
| 语法 | 解释 |
|---|---|
| row format delimited fields terminated by ‘,’ | 列分隔符 |
| collection items terminated by ‘_’ | MAP STRUCT 和 ARRAY 的分隔符(数据分割符号) |
| map keys terminated by ‘:’ | MAP中的key与value的分隔符 |
| lines terminated by ‘\n’ | 行分隔符 |
查询结果:访问三种集合列里的数据,分别以ARRAY,MAP,STRUCT数据结构访问
_c0 _c1 city
lili 18 beijing
数仓对象层级
- 数据库 database
- 表 table
- 分区 partition
- 具体数据
- 分区 partition
- 视图 view
- 表 table
数据库,表,分区实际对应 指定HDFS路径上的目录对象。表数据对应 HDFS 对应目录下的文件。
Hive 中所有的数据都存储在 HDFS 中,没有自己的数据类型,通过指定不同的分割符来代表不同的数据结构。从文件中读取字符,如果符合特定数据结构格式则识别为该结构——Schema On Read。
例如:Hive 默认列分隔符:控制符 Ctrl + A,\x01;默认行分隔符:换行符 \n
数仓对象解析:
database:在 HDFS ${hive.metastore.warehouse.dir} (/user/hive/warehouse)路径下一个文件夹
table:所属 database 目录下的一个子目录
manager table:对管理表的drop会导致,HDFS数据文件的删除
external table:对外部表的操作不会影响 HDFS数据文件
partition:为 table 目录下的分区子目录
bucket:在表目录或者分区目录下根据某个字段的值默认进行 hash 散列之后的多个数据文件
view:与传统数据库类似,只读,基于基本表创建
管理表,外部表,分区表,分桶表解析:
管理表==对当前表及表数据拥有所有权限
外部表==无表数据的删除权限(通常情况不对表数据更改,且默认禁用改功能)
分区表==手动指定分区字段,将数据集分目录细化,从而实现分部加速——>部分查询更快
分桶表==分桶原理对应 MR 中的 HashPartitioner,令数据文件分文件细化,只用于抽样检测