视频学习
-
深度学习的数学基础
-
卷积神经网络
代码练习
MNIST 数据集分类
- 配置
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy
# 一个函数,用来计算模型中有多少参数
def get_n_params(model):
np=0
for p in list(model.parameters()):
np += p.nelement()
return np
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
-
下载数据集
DataLoader是一个比较重要的类
显示数据集中的部分图像

-
创建网络
一个全连接和一个cnn -
在小型全连接网络上训练结果
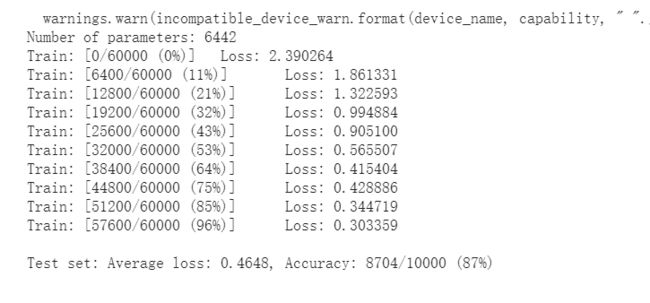
-
在卷积神经网络上训练

-
打乱像素顺序再次在两个网络上训练与测试

-
全连接结果
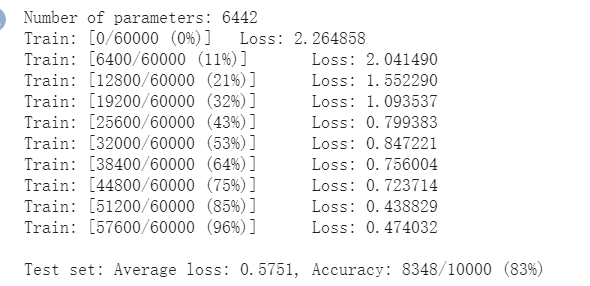
-
CNN结果

打乱像素顺序后,全连接网络的性能基本上没有发生变化,但是卷积神经网络的性能明显下降。
这是因为对于卷积神经网络,会利用像素的局部关系,但是打乱顺序以后,这些像素间的关系将无法得到利用。
CIFAR10 数据集分类
-
数据集下载,把范围在[0,1]的输出变为[-1,1]的张量 Tensors。
input[channel] = (input[channel] - mean[channel]) / std[channel]
由((0,1)-0.5)/0.5=(-1,1) -
展示 CIFAR10 里面的一些图片(8*8)和第一行的标签

truck truck frog cat plane deer dog car -
定义网络,损失函数和优化器
-
训练结果
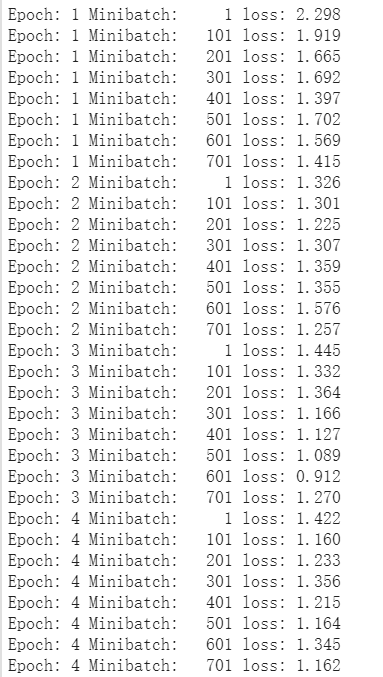
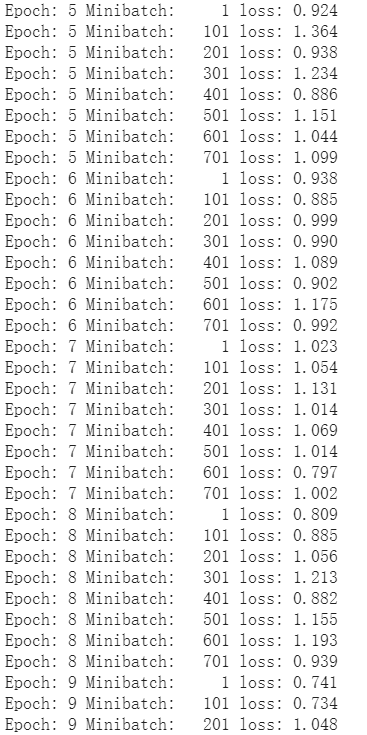

-
测试
测试图片

标签:cat ship ship plane frog frog car frog
结果:cat ship ship ship(×) deer(×) frog truck(×) frog
使用生个数据集测试的结果
![]()
使用 VGG16 对 CIFAR10 分类
- 定义 dataloader
mport torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
- VGG 网络定义
有个报错修改
cfg = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M']
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
#self.cfg = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M']
self.features = self._make_layers(cfg)
self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
# 网络放到GPU上
net = VGG().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
- 网络训练
结果
Epoch: 1 Minibatch: 1 loss: 2.531
Epoch: 1 Minibatch: 101 loss: 1.400
Epoch: 1 Minibatch: 201 loss: 1.315
Epoch: 1 Minibatch: 301 loss: 1.169
Epoch: 2 Minibatch: 1 loss: 0.968
Epoch: 2 Minibatch: 101 loss: 0.932
Epoch: 2 Minibatch: 201 loss: 1.006
Epoch: 2 Minibatch: 301 loss: 0.818
Epoch: 3 Minibatch: 1 loss: 0.968
Epoch: 3 Minibatch: 101 loss: 0.761
Epoch: 3 Minibatch: 201 loss: 0.848
Epoch: 3 Minibatch: 301 loss: 0.613
Epoch: 4 Minibatch: 1 loss: 0.716
Epoch: 4 Minibatch: 101 loss: 0.836
Epoch: 4 Minibatch: 201 loss: 0.553
Epoch: 4 Minibatch: 301 loss: 0.553
Epoch: 5 Minibatch: 1 loss: 0.616
Epoch: 5 Minibatch: 101 loss: 0.440
Epoch: 5 Minibatch: 201 loss: 0.438
Epoch: 5 Minibatch: 301 loss: 0.511
Epoch: 6 Minibatch: 1 loss: 0.478
Epoch: 6 Minibatch: 101 loss: 0.770
Epoch: 6 Minibatch: 201 loss: 0.614
Epoch: 6 Minibatch: 301 loss: 0.803
Epoch: 7 Minibatch: 1 loss: 0.485
Epoch: 7 Minibatch: 101 loss: 0.561
Epoch: 7 Minibatch: 201 loss: 0.507
Epoch: 7 Minibatch: 301 loss: 0.436
Epoch: 8 Minibatch: 1 loss: 0.451
Epoch: 8 Minibatch: 101 loss: 0.581
Epoch: 8 Minibatch: 201 loss: 0.552
Epoch: 8 Minibatch: 301 loss: 0.366
Epoch: 9 Minibatch: 1 loss: 0.465
Epoch: 9 Minibatch: 101 loss: 0.414
Epoch: 9 Minibatch: 201 loss: 0.277
Epoch: 9 Minibatch: 301 loss: 0.388
Epoch: 10 Minibatch: 1 loss: 0.388
Epoch: 10 Minibatch: 101 loss: 0.367
Epoch: 10 Minibatch: 201 loss: 0.396
Epoch: 10 Minibatch: 301 loss: 0.569
Finished Training
- 测试验证准确率

使用VGG模型迁移学习进行猫狗大战
- 下载数据集,处理图片为224×224×3,并归一化
# 数据部分属性
['cats', 'dogs']
{'cats': 0, 'dogs': 1}
[('./dogscats/train/cats/cat.0.jpg', 0), ('./dogscats/train/cats/cat.1.jpg', 0), ('./dogscats/train/cats/cat.10.jpg', 0), ('./dogscats/train/cats/cat.100.jpg', 0), ('./dogscats/train/cats/cat.101.jpg', 0)]
dset_sizes: {'train': 1800, 'valid': 2000}
第一个batch的5张图片

-
创建 VGG模型
使用训练好的vgg模型进行预测
{{uploading-image-68054.png(uploading...)}} -
修改最后一层,冻结前面层的参数
设置 required_grad=False,只反向传递训练最后一层
print(model_vgg)
model_vgg_new = model_vgg;
for param in model_vgg_new.parameters():
param.requires_grad = False
model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2)
model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1)
model_vgg_new = model_vgg_new.to(device)
print(model_vgg_new.classifier)
结果:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=2, bias=True)
(7): LogSoftmax(dim=1)
)
- 训练并测试全连接层
1.创建损失函数和优化器;
2.训练模型;
3.测试模型。
'''
第一步:创建损失函数和优化器
损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签.
它不会为我们计算对数概率,适合最后一层是log_softmax()的网络.
'''
criterion = nn.NLLLoss()
# 学习率
lr = 0.001
# 随机梯度下降
optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr = lr)
'''
第二步:训练模型
'''
def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train()
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer = optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs)
print('Training: No. ', count, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
# 模型训练
train_model(model_vgg_new,loader_train,size=dset_sizes['train'], epochs=1,
optimizer=optimizer_vgg)

def test_model(model,dataloader,size):
model.eval()
predictions = np.zeros(size)
all_classes = np.zeros(size)
all_proba = np.zeros((size,2))
i = 0
running_loss = 0.0
running_corrects = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
predictions[i:i+len(classes)] = preds.to('cpu').numpy()
all_classes[i:i+len(classes)] = classes.to('cpu').numpy()
all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy()
i += len(classes)
print('Testing: No. ', i, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
return predictions, all_proba, all_classes
predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['valid'])

- 可视化模型预测结果(主观分析)
主观分析就是把预测的结果和相对应的测试图像输出出来看看,人工判断一下?一般有四(五?)种方式:
1.随机查看一些预测正确的图片
2.随机查看一些预测错误的图片
3.预测正确,同时具有较大的probability的图片
4.预测错误,同时具有较大的probability的图片
5.最不确定的图片,比如说预测概率接近0.5的图片
# 单次可视化显示的图片个数
n_view = 8
correct = np.where(predictions==all_classes)[0]
from numpy.random import random, permutation
idx = permutation(correct)[:n_view]
print('random correct idx: ', idx)
loader_correct = torch.utils.data.DataLoader([dsets['valid'][x] for x in idx],
batch_size = n_view,shuffle=True)
for data in loader_correct:
inputs_cor,labels_cor = data
# Make a grid from batch
out = torchvision.utils.make_grid(inputs_cor)
imshow(out, title=[l.item() for l in labels_cor])
# 类似的思路,可以显示错误分类的图片,这里不再重复代码
