大汇总 | 一文学会八篇经典CNN论文
本文主要是回顾一下一些经典的CNN网络的主要贡献。
论文传送门
【google团队】
- [2014.09]inception v1: https://arxiv.org/pdf/1409.4842.pdf
- [2015.02]inception v2: https://arxiv.org/pdf/1502.03167.pdf
- [2015.12]inception v3: https://arxiv.org/pdf/1512.00567.pdf
- [2016.02]inception v4: https://arxiv.org/pdf/1602.07261.pdf
【microsoft】
- [2015.12]resnet : https://arxiv.org/pdf/1512.03385v1.pdf
【Facebook】
- [2016.11]resnext : https://arxiv.org/pdf/1611.05431.pdf
【CORNELL & Tsinghua & Facebook】
- [2016.08]DenseNet : https://arxiv.org/pdf/1608.06993.pdf
【momenta】
- [2017.09]SEnet : https://arxiv.org/pdf/1709.01507.pdf
Inception v1
【主要贡献】
在传统网络中,神经网络都是通过增加深度来扩展的。Inception结构的最大特点是从网络的宽度上进行改进,通过concat操作将经过不同kernel尺度处理的feature map进行拼接。
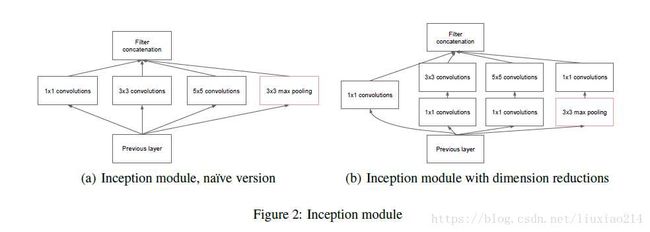
【其他贡献】
使用global average pooling代替全连接层,减小参数数量;使用1*1卷积层来缩减通道数量
Inception v2
【主要贡献】
首次提出BN层,减少Internal Covariate Shift。
Inception v3
【主要贡献】
提出卷积分解,用两个3*3卷积核代替5*5的卷积,用三个3*3卷积核代替7*7卷积核,后来提出用1*n,n*1的卷积核代替n*n
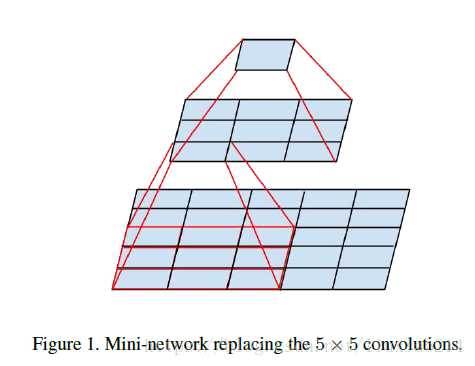
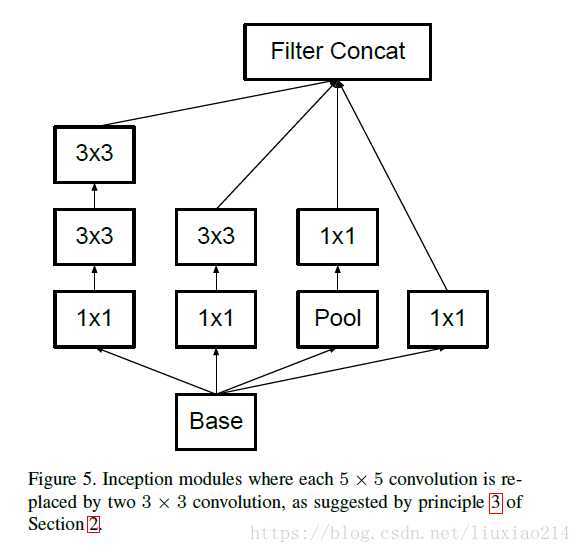

Inception v4
【主要贡献】
基于inception v3的基础上,引入残差结构,提出了inception-resnet-v1和inception-resnet-v2,并修改inception模块提出了inception v4结构。
【值得一提的是】
基于inception v4的网络实验发现在不引入残差结构的基础上也能达到和inception-resnet-v2结构相似的结果,从而认为何凯明等人认为的:“要想得到深度卷积网络必须使用残差结构”这一观点是不完全正确的。
Inception v4的结构
感觉到Inception v4,结构就有点诡异而复杂了,有点魔改的味道。

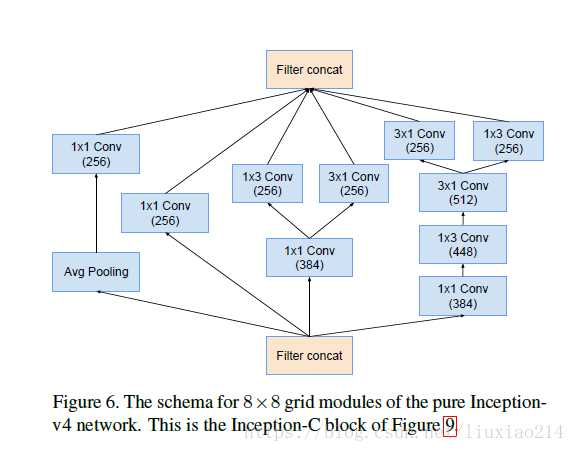
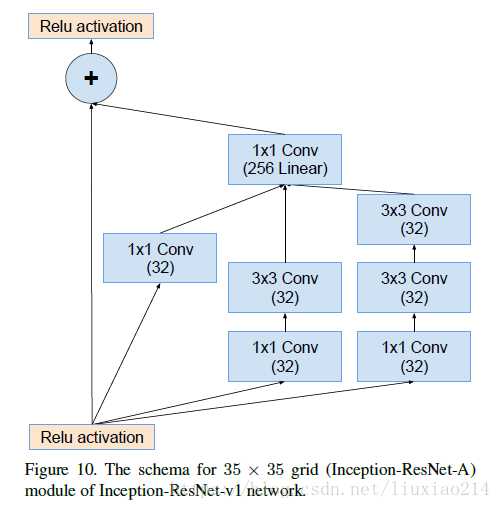
Inception-resnet-v1
就是有一个残差结构,其他部分也是跟inception v4类似。
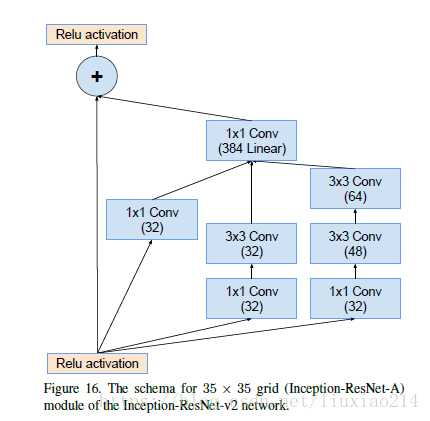
Inception-resnet-v2
与incpetion-resnet-v1差别不大,在通道数上做了修改。
实验结果对比
- 在inception-resnet-v1与inception v3的对比中,inception-resnet-v1虽然训练速度更快,不过最后结果有那么一丢丢的差于inception v3;
- 在inception-resnet-v2与inception v4的对比中,inception-resnet-v2的训练速度更块,而且结果比inception v4也更好一点。所以最后胜出的就是inception-resnet-v2。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WY0nLAar-1595354152991)(http://helloworld2020.net/wp-content/uploads/2020/07/wp_editor_md_a786245a7925825316bcee5bbd2c5ff8.jpg)]
【个人建议把重点放在inceptionv1-v3上,对v4了解一下即可】
Resnet
resnet提出是在Inception v3和inception v4中间,这样时间线就连上了。
【主要贡献】
残差结构提出解决了梯度消失的问题。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AeHfneIF-1595354152992)(http://helloworld2020.net/wp-content/uploads/2020/07/wp_editor_md_9fc0fb9e4584d9612e630ef0f4a742cf.jpg)]
左边是基本的结构,右边是使用1*1卷积核来降低参数。
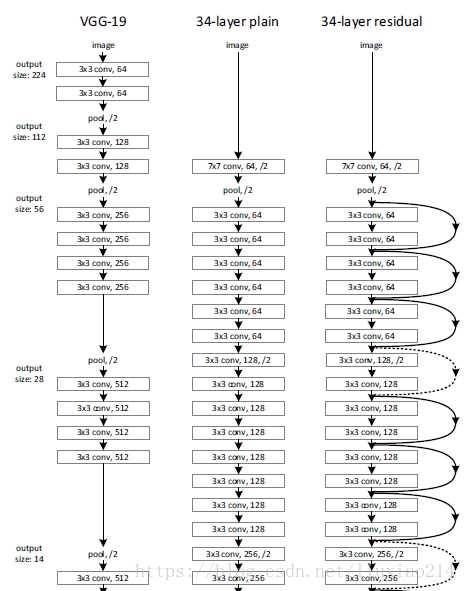
下图是VGG网络,plain网络和残差网络的对比,重点就是体现残差网络的残差结构的跳跃的感觉。

ResNext
增加网络的深度depth是改进网络的一种思路,GoogLeNet增加网络的宽度width是另一种思路,ResNext提出了一种新的方式叫做cardinality,基数。
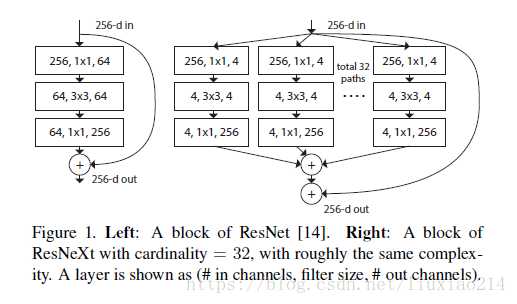
cardinality=32的时候,就是分成32组进行卷积。上图中右边的模块,就是把输入feature map卷积从256通道压缩到4通道,然后再对4通道的特征图进行3*3的卷积。然后这个过程并行重复32次,最后再把所有的结果相加,然后再根据残差结构加上输入的特征图。
【值得一提的是】
下面的三种变体完全等价:

- 图A就是之说的结构;
- 图B是在3x3卷积后进行了concat,然后再通过统一的1x1卷积操作,这个有点类似于inception-resnet;
- C图结构更简洁且速度更快。采用组卷积。采用32个group,每个group的输入输出的通道数都是4;
【因为组卷积的放在在pytorch等库函数中支持,所以使用组卷积的方法来实现resnext就非常的方便,就改一下参数就可以了。】
【实验结果来说,增加Cardinality的效果是有的,和resnet50/101相比,参数量相近的情况下,resnext的准确率有所提升。】
【个人感想:这个resnext我觉得就是一个提升网络模型的trick,在建立模型的时候,baseline跑完了,可以可以试一试分组卷积,看看是否会有提升】
DenseNet
densenet紧接着在resnet之后提出,结合了resnet的思想。网络改进除了像resnet和inception在深度和宽度上做文章外,densenet通过利用feature来减少参数的同时提高效果,对feature进行有效利用并加强feature的传递。
【主要贡献】
将每一层都与后面的所有层连接起来,如果一个网络中有L层,那么会有L(L+1)/2个连接,具体连接如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xrejbcum-1595354152997)(http://helloworld2020.net/wp-content/uploads/2020/07/wp_editor_md_9e9ef882bc4e97834a21465a97bf49e5.jpg)]
DenseNet的一个优点是网络更浅,参数更少,很大一部分原因得益于这种dense block的设计,dense block中每个卷积层的输出feature map的数量都很小(小于100),而不是像其他网络一样动不动就几百上千的宽度。同时这种连接方式使得特征和梯度的传递更加有效,网络也就更加容易训练。原文的一句话非常喜欢:Each layer has direct access to the gradients from the loss function and the original input signal, leading to an implicit deep supervision.直接解释了为什么这个网络的效果会很好。前面提到过梯度消失问题在网络深度越深的时候越容易出现,原因就是输入信息和梯度信息在很多层之间传递导致的,而现在这种dense connection相当于每一层都直接连接input和loss,因此就可以减轻梯度消失现象,这样更深网络不是问题。另外作者还观察到这种dense connection有正则化的效果,因此对于过拟合有一定的抑制作用,博主认为是因为参数减少了,所以过拟合现象减轻。
后来引入了dense block来解决特征图尺寸不一致的问题:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rKAk3LkT-1595354152998)(http://helloworld2020.net/wp-content/uploads/2020/07/wp_editor_md_a32ae17d48596eaa0dab4ee33e83b8af.jpg)]
可以看出,只有在dense block内才会网络层全连接的这种结构,彼此dense block并无连接。
SENet
【主要贡献】
从特征通道之间的关系入手,对特征通道之间的关系进行建模表示,根据重要程度增强有用的特征、抑制没有用的特征。
个人感觉像是在通道上做权重,类似于通道上的attention。
SE是这个结构的两个步骤,squeeze和excitation。
squeeze挤压
对通道进行挤压,也就是全局平均池化,将shape为[C,H,W]的特征图变成[C,1,1]。

Excitation激励
首先通过一个全连接层进行降维,即如下公式中的W1z,然后经过relu激活函数。即δ(W1z),再经过全连接进行升维,即W2(δ(W1z)),然后通过sigmoid进行权重激活。
s = σ ( W 2 δ ( W 1 z ) ) s = \sigma(W_2\delta(W_1z)) s=σ(W2δ(W1z))
这个s就是特征图每一个通道的权重值。
之后我们把这个s和每一个通道相乘,就可以得到权衡过通道重要性的特征图了。个人经过这个SENet,效果真的不错。
下面试SENet block:
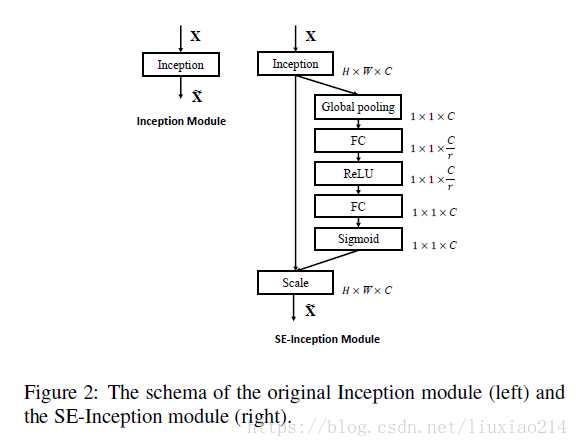
可以看到,这个模块是放在Inception模块之后的,所以在自己的网络中,也可以加入一个SENet组件进去。SE block是一个寄生在其他网络结构上的一个性能提升trick。
下面是残差se block,增加了残差结构:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EtTXUvVx-1595354153001)(http://helloworld2020.net/wp-content/uploads/2020/07/wp_editor_md_f06ae59318f59a0910a03135737a1924.jpg)]
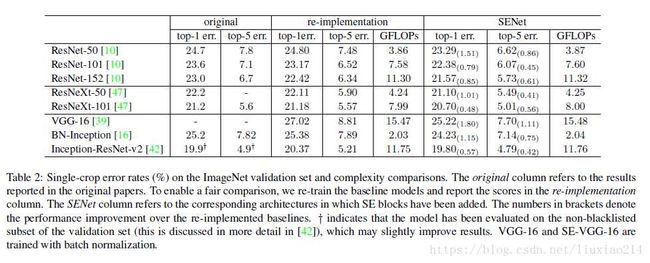
【性能对比】
论文中,作者浮现了各大主流网络模型,然后加入了SE模块,发现性能均有提升!
参考博文:
- https://www.cnblogs.com/shouhuxianjian/p/7786760.html
- https://blog.csdn.net/loveliuzz/article/details/79135583
- https://blog.csdn.net/u014380165/article/details/71667916
- https://blog.csdn.net/xjz18298268521/article/details/79078551
- http://www.sohu.com/a/161633191_465975


