【LanczosNet】LANCZOSNET: MULTI-SCALE DEEP GRAPH CONVOLUTIONAL NETWORKS 论文笔记
引用:
http://www.lifesequence.co/krylov_subspace_arnoldi_iterate/ Krylov子空间
https://blog.csdn.net/qq_39521554/article/details/79913323 Krylov子空间方法
补充
1.Lanczos algorithm
Lanczos算法是一种将对称矩阵通过正交相似变换变成对称 三对角矩阵的算法。
对称三对角矩阵类似于下式:
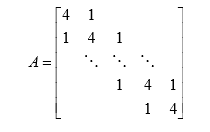
2.方法大致思路

LANCZOSNET: MULTI-SCALE DEEP GRAPH CONVOLUTIONAL NETWORKS
摘要
- 提出 LanczosNet,对于图卷积,使用Lanczos algorithm 构建图拉普拉斯的低秩近似
- 依靠Lanczos algorithm 的三对角分解,有两个好处:通过矩阵乘方的快速近似计算有效地利用多尺度信息;设计了可学习的谱滤波器。
- LanczosNet 可以促进图的核学习以及节点嵌入的学习(node representation:学习图的每个节点的向量)
引言
- 监督和半监督的任务,如图或节点的分类和回归,大致分为两种:基于图卷积;基于现在的卷积网络(GNN:通过在节点之间交换信息,在图上反复展开传递过程的消息。缺点:难训练)
- 现在的卷积方法有俩个主要问题:1:除了直接叠加多层之外,如何有效地利用多尺度信息尚不清楚。(Graph coarsening: 这种粗化过程在推理和学习过程中都是固定的,可能会造成一定的偏差)2:基于当前图卷积模型中的谱滤波器大多是固定的.
模型的容量:是指其拟合各种函数的能力。容量低的模型很难拟合训练集,容量高的模型容易过拟合。通过处理特征课改变模型容量,例如假设真实数据符合三次分布,那么用二次函数很难拟合(容量低),加入三次项后效果提高,若用九次项拟合(容量过高)会发生过拟合。
LanczosNet 的优点:
- 基于Lanczos算法所隐含的三对角分解,模型利用了图拉普拉斯矩阵的低秩近似。这种近似有利于矩阵幂的有效计算,从而便于多尺度信息的采集。】
- 设计了基于近似的可学习谱滤波器,有效地提高了模型容量。
- 在需要学习图形内核和/或节点嵌入的场景中,提出了自适应Lanczos网络(AdaLanczosNet),它通过Lanczos算法反向传播。
背景
![]()
 节点的集合 ,
节点的集合 , 是邻接矩阵 ,
是邻接矩阵 , 
 节点特征表示
节点特征表示
图的傅里叶变换
基于邻接矩阵 ,计算 图拉普拉斯矩阵有三种形式:![]()
由于定义(3)是实对称的、正半定的(PSD: positive semi-definite ),特征值位于[0,2],所以在GSP( graph signal processing (GSP) approaches)研究中经常使用定义(3)。
我们定义 图的傅里叶变换 为 ![]() ,逆变换
,逆变换 ![]() ,拉普拉斯矩阵的(3)与亲和力矩阵
,拉普拉斯矩阵的(3)与亲和力矩阵 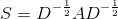 共享相同的特征值 即
共享相同的特征值 即![]() 。
。
局部多项式滤波器
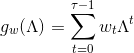 ,
, ![]() 是滤波器系数,即 可以学习的参数。 主要的应用是 切尔雪夫多项式滤波。
是滤波器系数,即 可以学习的参数。 主要的应用是 切尔雪夫多项式滤波。
本文中:
使用亲和力矩阵  ,局部多项式滤波器的形式:
,局部多项式滤波器的形式:
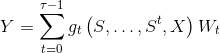
 使用节点特征的 的函数 , 以亲和矩阵的幂次为输入,输出N×F矩阵。
使用节点特征的 的函数 , 以亲和矩阵的幂次为输入,输出N×F矩阵。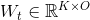 对应的滤波器系数
对应的滤波器系数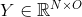 是输出
是输出- 在切尔雪夫多项式滤波中,
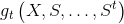 的 第 i列 位于 Krylov subspace
的 第 i列 位于 Krylov subspace 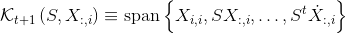 。
。
针对某一个向量近似成立的解 - 我们有m阶矩阵A和一个向量v,定义向量组
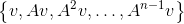 所张成的子空间为n阶Krylov子空间
所张成的子空间为n阶Krylov子空间 ,假定我们现在想计算一个矩阵函数f(A)与向量v的乘积,将这个矩阵函数做泰勒展开(如果可以的话),保留前n项,那么只需要用Krylov子空间中的向量就可以将这个结果计算出来了。这就是针对某一个向量近似成立这句话的部分含义。
,假定我们现在想计算一个矩阵函数f(A)与向量v的乘积,将这个矩阵函数做泰勒展开(如果可以的话),保留前n项,那么只需要用Krylov子空间中的向量就可以将这个结果计算出来了。这就是针对某一个向量近似成立这句话的部分含义。 - Krylov子空间方法:https://blog.csdn.net/qq_39521554/article/details/79913323(求稀疏矩阵的特征值)
LANCZOS NETWORKS
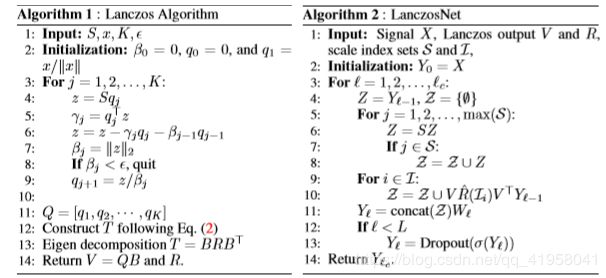
LANCZOS ALGORITHM
输入亲和力矩阵 和 节点特征  ,经过 N步 Lanczos algorithm 计算出 正交矩阵
,经过 N步 Lanczos algorithm 计算出 正交矩阵 (
(![Q=\left[q_{1}, \cdots, q_{N}\right]](http://img.e-com-net.com/image/info8/950fb2f9ff5d4d6380f0761065e919dc.gif) )和 一个对称的三对角矩阵
)和 一个对称的三对角矩阵 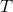 ,即:
,即: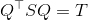 。 组成了Krylov子空间
。 组成了Krylov子空间 ![]() 的正交基。
的正交基。
LANCZOSNET
Localized Polynomial Filter 输入是 ![]() ,输出是
,输出是 ![]() 。Lanczos algorithm 得到
。Lanczos algorithm 得到 ![]() (Krylov 子空间的正交基)和 三对角矩阵
(Krylov 子空间的正交基)和 三对角矩阵 ![]() 。图卷积可以表示为:
。图卷积可以表示为:
![]() (3)
(3)
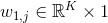 可以学习的参数。
可以学习的参数。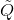 取决于
取决于 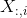 。缺点: 如果想要堆叠多层卷积层,由于 依赖于 ,所以 对于计算量较大的图卷积层,需要单独运行Lanczos算法。
。缺点: 如果想要堆叠多层卷积层,由于 依赖于 ,所以 对于计算量较大的图卷积层,需要单独运行Lanczos算法。
Spectral Filter 理想情况:计算Lanczos 向量,只计算一次。为此,选择一个带有单位范数的随机初始向量,并将K阶Lanczos层输出作为低秩近似 ![]() 。 有标准正交列并且不依赖于节点特征
。 有标准正交列并且不依赖于节点特征  。用下面的理论证明来限制近似误差。
。用下面的理论证明来限制近似误差。
理论1:
分解三对角矩阵 ![]() ,
, 中包含Ritz值,
中包含Ritz值,  是一个正交矩阵。亲和力矩阵
是一个正交矩阵。亲和力矩阵![]() 的低秩近似,
的低秩近似, 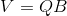 ,然后上述卷积公式重写为:
,然后上述卷积公式重写为:
![]() (4)
(4)
(3)和(4)的区别是 前者使用了正交基,后者使用了 ![]() 的直接基的近似(这里有点不好理解哇!!)。由于我们明确地对谱的近似进行运算,即, Ritz值,它是一个谱滤波器。由于S的t次幂可以近似为
的直接基的近似(这里有点不好理解哇!!)。由于我们明确地对谱的近似进行运算,即, Ritz值,它是一个谱滤波器。由于S的t次幂可以近似为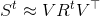 ,在考虑长的范围/尺度依赖关系时,这种滤波形式将具有显著的计算优势,我们只需要提高R的对角项的t次幂。
,在考虑长的范围/尺度依赖关系时,这种滤波形式将具有显著的计算优势,我们只需要提高R的对角项的t次幂。
Learning the Spectral Filter
设计可以学习的谱滤波器。使用K个不同的谱滤波器,第k步的输出:![]() ,
,  是一个多层感知器, 是相应的度矩阵的度向量。
是一个多层感知器, 是相应的度矩阵的度向量。 ![]() 是基于 的输出向量的度矩阵。因此,我们有如下的滤波:
是基于 的输出向量的度矩阵。因此,我们有如下的滤波:
![]() (5)
(5)
注意,它将多项式滤波器作为特殊情况包含在内,当考虑到半正定时,可以对mlp的输出应用类似ReLU的激活函数。
Multi-scale Graph Convolution 以可学习的谱滤波器为例,我们可以用一种紧凑的方式写出一个图卷积层,如下所示
![]() (6)
(6)
- 权重
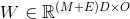
- 是 短尺度
 的参数集合,
的参数集合, 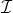 是 长尺度
是 长尺度 的参数集合。
的参数集合。 - 尺度参数:非负整数
- 当矩阵向量乘积的次数与 的最大尺度相等时,短尺度相应的卷积与DCNN类似
- 相反,长尺度的卷积分离 Lanczos 步 K 和 尺度参数 ,因此在把尺度作为超参数微调时有很大的调试空间。选择合适的K值可以平衡计算量和低秩近似的精度。
- 我们的实验中,短尺度一般低于10,长尺度不大于100.如果的最大特征值是1,我们甚至可以把幂次提高到无穷大,这对应于图上扩散过程的平衡态。
堆叠多层图卷积层,并且每一层都有自己的谱滤波权重,可以在层之间加非线性的激活函数。即如算法2。带着顶层表示,可以使用softmax实现分类或全连接层实现回归。Lanczos算法在构建网络时,每个图预先运行一次,在推理和学习过程中不会被调用。
AdaLanczosNet
补充资料:
Graph kernel是一种有效的图结构相似度的近似度量方式
首先Graph kennel 是一种kernel method
实际上 kernel method 在图结构中的研究主要有两类:一是Graph embedding 算法,将图(Graph)结构嵌入到向量空间;另一类就是Graph kernel算法。
第一类得到图结构的向量化表示,然后直接应用基于向量的核函数(RBF kernel, Sigmoid kernel, etc.) 处理,但是这类方法将结构化数据降维到向量空间损失了大量结构化信息。而Graph kernel 直接面向图结构数据,既保留了核函数计算高效的优点,又包含了图数据在希尔伯特高维空间的结构化信息。
针对不同的图结构(labeled graphs, weighted graphs, directed graphs, etc.) 有不同的Graph kernel
作者:一个安静的胖子
链接:https://www.zhihu.com/question/57269332/answer/157375170
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。Graph Kernel 节点特征 和 图 ![]() ,我们想要学习一个图核函数,它可以捕获节点表示的固有几何形状。我们定义一个各向异性图核,
,我们想要学习一个图核函数,它可以捕获节点表示的固有几何形状。我们定义一个各向异性图核,![]() ,数据点
,数据点![]() :
:
 (7)
(7)
 是多层感知器。这类各向异性核具有很强的表达能力,包括自调核和具有马氏距离的高斯核
是多层感知器。这类各向异性核具有很强的表达能力,包括自调核和具有马氏距离的高斯核- 此外,对于不同的核函数,得到的图拉普拉斯算子渐近收敛于不同的极限算子。比如:即使对于各向同性高斯核,在不同的归一化条件下,图拉普拉斯算子也可以点向拉普拉斯-贝尔特拉米、福克-普朗克算子和热核收敛
在实际中,注意到![]() 有助于对两两距离进行归一化,从而避免了指数函数引起的梯度消失问题。这种可学习的各向异性扩散在两个方面是有用的。首先,它增加了模型容量,从而可能获得更好的性能。其次,它能较好地适应流形上数据点的非均匀密度或流行上底层数据点的非线性测量。构建邻接矩阵 A
有助于对两两距离进行归一化,从而避免了指数函数引起的梯度消失问题。这种可学习的各向异性扩散在两个方面是有用的。首先,它增加了模型容量,从而可能获得更好的性能。其次,它能较好地适应流形上数据点的非均匀密度或流行上底层数据点的非线性测量。构建邻接矩阵 A ![]() ,否则
,否则![]() ,然后可以得到亲和力矩阵 。
,然后可以得到亲和力矩阵 。
Node Embedding 在一些应用中,我们不观测节点特征,而是观测图本身,所以我们需要学习每个节点的嵌入向量。我们仍然可以使用上面的图核构造亲和矩阵,除了 被丢弃外,亲和矩阵的形式是相同的。学习嵌入 就等于学习节点之间的相似性。
被丢弃外,亲和矩阵的形式是相同的。学习嵌入 就等于学习节点之间的相似性。
Tridiagonal Decomposition 虽然LanczosNet中的所有操作都是可微的,但我们从经验上观察到,通过三对角矩阵的特征分解进行反向传播在数值上是不稳定的。 如果多个特征值在数值上接近,或者一个特征值在式(6)中取很大的幂,情况会更糟。解决: 直接利用通过运行Lanczos算法K步得到的近似三对角分解![]() .则图卷积层带着可以学习的滤波器表示如下:
.则图卷积层带着可以学习的滤波器表示如下:
![]() (8)
(8)
- 其中
 是可以学习的谱滤波器。每个由一个表示为
是可以学习的谱滤波器。每个由一个表示为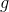 的单独MLP构成,该MLP以
的单独MLP构成,该MLP以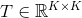 为输入,输出相同大小的矩阵
为输入,输出相同大小的矩阵 - 为了确保 输出一个对称矩阵,定义
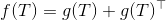 。
。
使用上面的参数化图的拉普拉斯算子和三对角分解,我们可以反向传播损失通过兰索斯算法去图形内核参数θ或节点嵌入x。整体模型类似于LanczosNet除了兰索斯算法需要为每个推理通过调用。
LANCZOS NETWORK AND DIFFUSION MAPS
主要讲LanczosNet 和 基于流行排序算法的图——扩散图之间的关系
什么是扩散图呢??
在扩散图中,邻接矩阵中的权值定义了图上的离散随机游走,其中马尔可夫转移矩阵![]() 显示了在一个时间步长内的转移概率。
显示了在一个时间步长内的转移概率。![]() :从节点i开始到节点j结束的所有长度为t的路径的概率之和。我们使用特征值和P的右特征值向量
:从节点i开始到节点j结束的所有长度为t的路径的概率之和。我们使用特征值和P的右特征值向量 ![]() 定义扩散图
定义扩散图 ![]() 为:
为:
![]() (9)
(9)
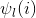 是 特征向量
是 特征向量 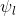 的第 i 项
的第 i 项- 原始的随机矩阵 P 与 S 相似,即
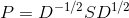 ,有
,有 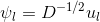
- 图
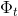 满足
满足 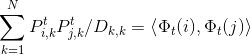 ,
,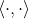 是 欧几里得空间上的内积。
是 欧几里得空间上的内积。 - i和j之间的扩散距离:
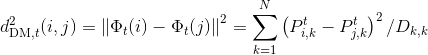 是随机游走的概率云从i点开始,在t步之后结束于j点之间的加权
是随机游走的概率云从i点开始,在t步之后结束于j点之间的加权 近似度。
近似度。 - 因为S 所有的特征向量 范围为 [-1,1],对于公式9 ,当一些很大的t时,接近0,只用几个最大的特征值及其特征向量就可以很好地逼近
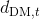
Connection to Graph Convolution 除了使用扩散图嵌入不同时间尺度的节点特性X外,还可以使用它计算X的频率表示形式如下
![]() (10)
(10)
 是 的特征值 ,并且定义了图的傅里叶变换。
是 的特征值 ,并且定义了图的傅里叶变换。- 通过 特征值
 的幂给
的幂给 加权,抑制带有小特征值的项
加权,抑制带有小特征值的项 - 因此,在LanczosNet中,将节点特征X投影到不同尺度的多个扩散图上得到的频率表示实际上是使用了频谱滤波器。
实验
定量输出称为回归,或者说是连续变量预测;
举例:预测明天的气温是多少度,这是一个回归任务;
- 9个对比图网络
- 两个主要任务:在3个引用网路中的半监督文件分类;QM8量子化学数据集上分子性质的监督回归
- https://github.com/lrjconan/LanczosNetwork
引用网络
如表1
- 3个引用网络:Cora, Citeseer and Pubmed
- 节点是文件,连接基于它们的引用链接。每个节点都与一个词包特征向量相关联,特别是,给定一部分节点及其标记的内容类别,例如历史、科学,任务是预测同一图中其他未标记节点的类别。附录中总结了这些数据集的统计数据
- 所有的实验用不同的随机种子点重复10次,每次运行时,所有的方法共享相同的随机种子点。我们首先对公共数据进行分割实验,发现几乎所有算法都存在严重的过拟合。解决方法:通过将训练示例的部分减少到几个级别并随机分割数据来增加任务的难度。
- 我们可以看到,无论是LanczosNet还是AdaLanczosNet在随机困难的分割上都达到了最先进的精度,并且在公共分割上的性能与GAT非常接近。这可能是由于训练实例较少,模型需要更长的规模方案来在图上传播监督信息。我们的模型提供了一种利用这种大规模信息的有效方法。
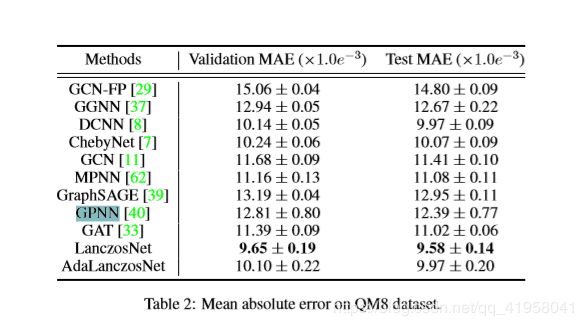
量子化学
如表2
结论
在本文中,我们提出了利用Lanczos算法构造图拉普拉斯矩阵的低秩近似的LanczosNet。它不仅为图卷积提供了一种有效的多尺度信息采集方法,而且使学习频谱滤波器成为可能。此外,我们还提出了一个模型变体AdaLanczosNet,该模型简化了图形内核和节点嵌入学习。结果表明,该模型与基于图的流形学习,特别是扩散图有着密切的关系。实验结果表明,该模型在具有挑战性的图问题上优于其他图网络。我们目前正在探索三对角矩阵的自定义特征分解方法,这将进一步改进我们的AdaLanczosNet。总的来说,在这个方向上的工作有望使深度学习扩展到非常大的图形问题。