【Rust每周一知】Rust为什么会有String和&str?!长文预警!
本文是Amos博客文章“Working with strings in Rust”的翻译。
原文地址:https://fasterthanli.me/blog/2020/working-with-strings-in-rust/
人们选择Rust编程语言时总会遇到一个问题:为什么会有两种字符串类型?为什么会出现String和&str?
Amos在其另一篇文章"declarative-memory-management"中部分回答了这个问题。但是在本文中又进行了一些实验,看看是否可以为Rust的做法“辩护”。文章主要分为C和Rust两大部分。
C语言部分:
print程序示例
UTF-8编码
print程序处理UTF-8编码
传递字符串
C语言的print程序示例
让我们从简单C程序开始,打印参数。
// in `print.c`
#include // for printf
int main(int argc, char **argv) {
for (int i = 0; i < argc; i++) {
char *arg = argv[i];
printf("%s\n", arg);
}
return 0;
} $ gcc print.c -o print
$ ./print "ready" "set" "go"
./print
ready
set
go好的!很简单。程序使用的是标准的C11主函数签名,该签名用int定义参数个数(argc,参数计数),和用char**或char *[]“字符串数组”定义参数(argv,参数向量)。然后,使用printf格式说明符%s将每个参数打印为字符串,其后跟\n换行符。确实,它将每个参数打印在自己的行上。
在继续之前,请确保我们对正在发生的事情有正确的了解。修改以上的程序,使用%p格式说明符打印指针!
// in `print.c`
int main(int argc, char **argv) {
printf("argv = %p\n", argv); // new!
for (int i = 0; i < argc; i++) {
char *arg = argv[i];
printf("argv[%d] = %p\n", i, argv[i]); // new!
printf("%s\n", arg);
}
return 0;
}$ gcc print.c -o print
$ ./print "ready" "set" "go"
argv = 0x7ffcc35d84a8
argv[0] = 0x7ffcc35d9039
./print
argv[1] = 0x7ffcc35d9041
ready
argv[2] = 0x7ffcc35d9047
set
argv[3] = 0x7ffcc35d904b
go好的,argv是一个地址数组,在这些地址上有字符串数据。像这样:
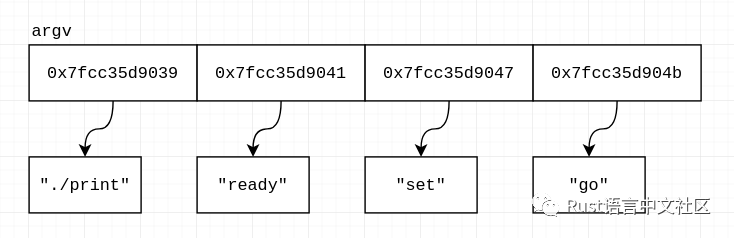
printf的%s格式符怎么知道什么时候停止打印?因为它只获得一个地址,而不是起始地址和结束地址,或者起始地址和长度。让我们尝试自己打印每个参数:
// in `print.c`
#include // printf
int main(int argc, char **argv) {
for (int i = 0; i < argc; i++) {
char *arg = argv[i];
// we don't know where to stop, so let's just print 15 characters.
for (int j = 0; j < 15; j++) {
char character = arg[j];
// the %c specifier is for characters
printf("%c", character);
}
printf("\n");
}
return 0;
} $ gcc print.c -o print
$ ./print "ready" "set" "go"
./printreadys
readysetgoCD
setgoCDPATH=.
goCDPATH=.:/ho哦哦~我们的命令行参数相互“渗入”。让我们尝试将我们的程序通过管道xxd传输到一个十六进制的转储程序中,以查看发生了什么事:
$ # note: "-g 1" means "show groups of one byte",
$ # xxd defaults to "-g 2".
$ ./print "ready" "set" "go" | xxd -g 1
00000000: 2e 2f 70 72 69 6e 74 00 72 65 61 64 79 00 73 0a ./print.ready.s.
00000010: 72 65 61 64 79 00 73 65 74 00 67 6f 00 43 44 0a ready.set.go.CD.
00000020: 73 65 74 00 67 6f 00 43 44 50 41 54 48 3d 2e 0a set.go.CDPATH=..
00000030: 67 6f 00 43 44 50 41 54 48 3d 2e 3a 2f 68 6f 0a go.CDPATH=.:/ho.啊啊!它们确实彼此跟随,但是两者之间有一些区别:这是相同的输出,用^^进行注释的位置是分隔符:
00000000: 2e 2f 70 72 69 6e 74 00 72 65 61 64 79 00 73 0a ./print.ready.s.
. / p r i n t ^^ r e a d y ^^似乎每个参数都由值0来终止。确实,C具有以null终止的字符串。因此,我们可以“修复”我们的打印程序:
#include // printf
int main(int argc, char **argv) {
for (int i = 0; i < argc; i++) {
char *arg = argv[i];
// note: the loop condition is gone, we just loop forever.
// well, until a 'break' at least.
for (int j = 0;; j++) {
char character = arg[j];
// technically, we ought to use '\0' rather than just 0,
// but even `gcc -Wall -Wextra -Wpedantic` doesn't chastise
// us, so let's just go with it.
if (character == 0) {
break;
}
printf("%c", character);
}
printf("\n");
}
return 0;
} $ gcc print.c -o print
$ ./print "ready" "set" "go"
./print
ready
set
go一切都更好!虽然,我们也需要修复图:
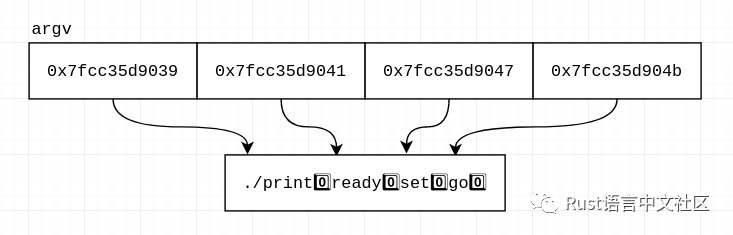
提示:可能已经注意到,当我们的打印程序超出参数范围时,
CDPATH=.:/ho也会显示出来。那是(一部分)环境变量!这些都在GNU C库glibc中程序参数旁边。但是具体细节不在本文讨论范围之内,需要查看制作自己的可执行打包程序系列。
好的!现在我们完全了解发生了什么,让我们做一些更有趣的事情:将参数转换为大写。因此,如果我们运行./print hello,它应该打印HELLO。我们也将跳过第一个参数,因为它是程序的名称,现在对我们而言这并不是很有趣。
#include // printf
#include // toupper
int main(int argc, char **argv) {
// start from 1, skips program name
for (int i = 1; i < argc; i++) {
char *arg = argv[i];
for (int j = 0;; j++) {
char character = arg[j];
if (character == 0) {
break;
}
printf("%c", toupper(character));
}
printf("\n");
}
return 0;
} $ gcc print.c -o print
$ ./print "hello"
HELLO好的!太好了!在我看来功能齐全,可以发货了。出于谨慎考虑,让我们运行最后一个测试:
$ gcc print.c -o print
$ ./print "élément"
éLéMENT哦~我们真正想要的是“ÉLÉMENT”,但显然,我们还没有弄清正在发生的一切。好的,也许现在大写字母太复杂了,让我们做些简单的事情:打印每个字符并用空格隔开。
// in `print.c`
#include // printf
int main(int argc, char **argv) {
for (int i = 1; i < argc; i++) {
char *arg = argv[i];
for (int j = 0;; j++) {
char character = arg[j];
if (character == 0) {
break;
}
// notice the space following `%c`
printf("%c ", character);
}
printf("\n");
}
return 0;
} $ gcc print.c -o print
$ ./print "élément"
l m e n t不好了。这不会做,根本不会做。让我们回到最后一个行为良好的版本,该版本仅打印每个字符,中间没有空格,并查看输出的实际内容。
// in main
// in for
// in second for
printf("%c", character); // notice the lack of space after `%c`$ gcc print.c -o print
$ ./print "élément" | xxd -g 1
00000000: c3 a9 6c c3 a9 6d 65 6e 74 0a ..l..ment.
^^^^^ ^^^^^如果正确阅读此信息,则“é”不是一个char,实际上是2个char。好像...很奇怪。
让我们快速编写一个JavaScript程序,并使用Node.js运行它:
// in `print.js`
const { argv, stdout } = process;
// we have to skip *two* arguments: the path to node,
// and the path to our script
for (const arg of argv.slice(2)) {
for (const character of arg) {
stdout.write(character);
stdout.write(" ");
}
stdout.write("\n");
}$ node print.js "élément"
é l é m e n t啊! 好多了!Node.js能正确转换为大写吗?
// in `print.js`
const { argv, stdout } = process;
for (const arg of argv.slice(2)) {
stdout.write(arg.toUpperCase());
stdout.write("\n");
}$ node print.js "élément"
ÉLÉMENT它可以。让我们看一下十六进制转储:
$ node print.js "élément" | xxd -g 1
00000000: c3 89 4c c3 89 4d 45 4e 54 0a ..L..MENT.
^^^^^ ^^^^^虽然Node.js程序行为与预期相同,但我们可以看到,É也与其他字母不同,“c3 a9”的大写字母对应为“c3 89”。
C程序没有正常工作,因为它将“c3”和“a9”独立对待,它应将其看作一个单一的“Unicode值”。为什么将“é”编码为“c3 a9”?现在是时候进行快速的UTF-8编码入门了。
快速的UTF-8入门
“abcdefghijklmnopqrstuvwxyz”,“ABCDEFGHIJKLMNOPQRSTUVWXYZ”和“123456789”以及“!@#$%^&*()”等字符都有对应的数字值。例如,“A”的数字值是65。为什么会这样呢?这是个惯例,计算机只知道数字,而我们经常使用字节作为最小单位,因此很久以前人们决定,如果一个字节的值为65,则它表示字母“A”。
由于ASCII是7位编码,因此它具有128个可能的值:0到127(含0)。但是在现代机器上,一个字节为8位,因此还有“另外”128个可能的值。大家都以为。我们可以在其中填充“特殊字符”:
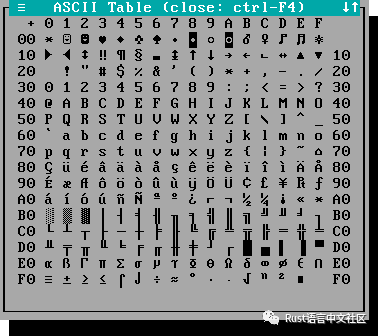
不只是ASCII,而是ASCII加我们选择的128个字符。当然有很多语言,因此并非每种语言的非ASCII字符都可以容纳这些额外的128个值,因此对于那些大于127的值,有几种替代的解释。这些解释被称为“代码页”。上面的图片是Codepage 437,也称为CP437,OEM-US,OEM 437,PC-8或DOS Latin US。
如果不关心大写字母,那么对于法语这样的语言来说已经足够了。但是对所有东欧语言,这是不够的,甚至一开始没覆盖亚洲语言。因此,日本想出了自己的办法,他们用日元符号代替了ASCII的反斜杠,并用上划线代替了波浪号,并引入了双字节字符,因为有128个额外的字符对他们来说还不够。
对于使用小字母的语言,人们使用诸如Windows-1252之类的代码页已有多年了,西方世界中的大多数文本仍然有点像ASCII,也称为“扩展ASCII”。但是最终,世界集体开始整理他们的事务,并决定采用UTF-8,该UTF-8:
看起来像ASCII字符的ASCII(未扩展),并且使用相同的空格。
允许更多的字符,多字节序列。
在这之前人们会问:两个字节还不够吗?(或者是两个双字节字符的序列?),当然也可以是四个字节,但是最终,由于诸如紧凑性之类的重要原因,并为使大多数C程序保持half-broken而不是完全不可用,采用了UTF-8。
除了微软。他们做了,但感觉太少,太迟了。内部一切仍然是UTF-16。RIP。
那么,ASCII加多字节字符序列,它如何工作?相同的基本原理,每个字符都有一个值,因此在Unicode中,“é”的数字是“e9”,我们通常这样写“U+00E9”。0xE9是十进制,其大于127,所以它不是ASCII 233,而我们需要做多字节编码。
UTF-8如何进行多字节编码?使用位序列!
如果一个字节以110开头,则意味着我们需要两个字节
如果一个字节以1110开头,则意味着我们需要三个字节
如果一个字节以11110开头,则意味着我们需要四个字节
如果一个字节以10开头,则表示它是多字节字符序列的延续。
因此,对于具有“U+00E9”的“é”,其二进制表示形式为“11101001”,并且我们知道我们将需要两个字节,因此我们应该具有以下内容:
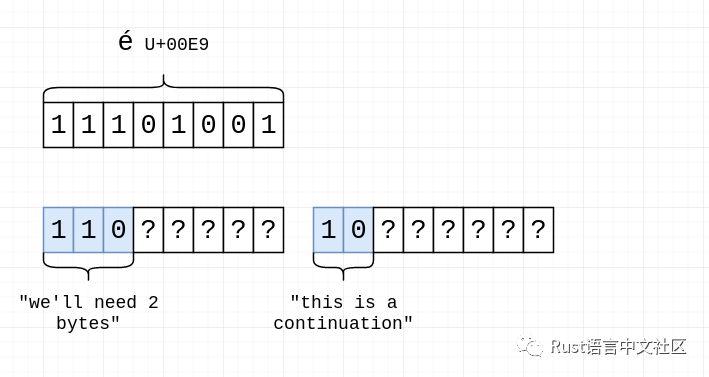
我们可以看到两个字节的UTF-8序列为我们提供11位存储空间:第一个字节为5位,第二个字节为6位。我们只需要8位,因此我们从右到左填充它们,首先是最后6位:
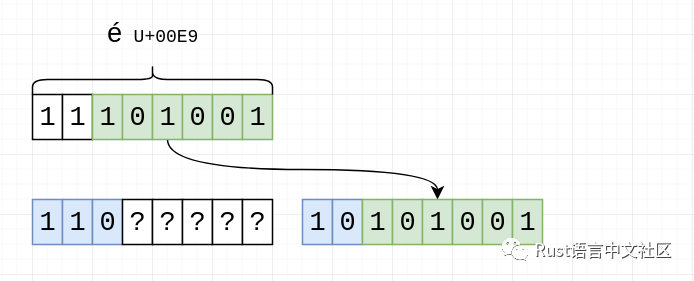
然后是剩下的2位:
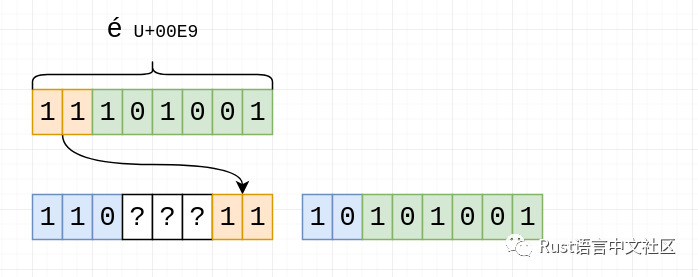
其余的位填充零:
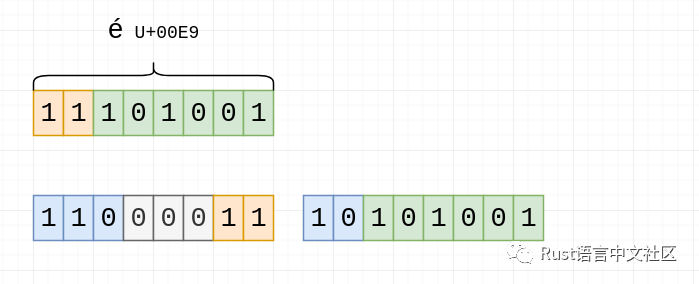
大功告成!0b11000011是0xC3和0b10101001是0xA9。与我们之前看到的相对应:“é”是“c3 a9”。
返回C的print程序
所以C程序,如果要真正分离字符,则必须进行一些UTF-8解码。我们仍然可以尝试自己做。
// in `print.c`
#include // printf
#include // uint8_t
void print_spaced(char *s) {
// start at the beginning
int i = 0;
while (1) {
// we're going to be shifting bytes around,
// so treat them like unsigned 8-bit values
uint8_t c = s[i];
if (c == 0) {
// reached null terminator, stop printing
break;
}
// length of the sequence, ie., number of bytes
// that encode a single Unicode scalar value
int len = 1;
if (c >> 5 == 0b110) {
len = 2;
} else if (c >> 4 == 0b1110) {
len = 3;
} else if (c >> 3 == 0b11110) {
len = 4;
}
// print the entire UTF-8-encoded Unicode scalar value
for (; len > 0; len--) {
printf("%c", s[i]);
i++;
}
// print space separator
printf(" ");
}
}
int main(int argc, char **argv) {
for (int i = 1; i < argc; i++) {
print_spaced(argv[i]);
printf("\n");
}
return 0;
} 没有讨论String和&str。关于Rust字符串处理的文章却没有Rust代码,而且已经花了大约十分钟!
程序有效吗?
$ gcc print.c -o print
$ ./print "eat the rich"
e a t t h e r i c h$ ./print "platée de rösti"
p l a t é e d e r ö s t i$ ./print "23€ ≈ ¥2731"
2 3 € ≈ ¥ 2 7 3 1 $ ./print "text ???? encoding"
t e x t ???? e n c o d i n g好吧,我不知道每个人都在抱怨什么,UTF-8超易实现,只花了我们几分钟时间,而且100%正确,符合标准,永远适用于所有输入,并且始终做正确的事。是吗?反例来了,考虑以下字符串:
$ echo "noe\\u0308l"
noël
这只是法国的圣诞节!当然,我们的程序可以解决此问题,而且不会费力:
$ ./print $(echo "noe\\u0308l")
n o e ̈ l
哦哦~事实上,U+0308是“组合解析”,是“仅在前一个字符上打两个点”。实际上,如果需要,我们可以打更多的东西(以增加圣诞节的欢呼声):
提示:显示单个“形状”的多个标量值的组合被称为“字素簇”,了解更多有关内容阅读Henri Sivonen的文章 "????????♂️".length == 7。
另外,由于作者Amos是法国人,整篇文章都带有Latin-1偏爱。了解更多有关内容阅读Manish Goregaokar的文章Breaking Our Latin-1 Assumptions。
因此,也许我们的程序并未实现UTF-8编码的所有微妙之处,但是我们已经接近了。我们现在暂时不考虑字符的组合,而将重点放在Unicode标量值上。我们想要的是:
解码我们的输入,将其从UTF-8转换为一系列Unicode标量值(我们将选择uint32_t)
将标量值转换为大写对应值
重新编码为UTF-8
打印到控制台
因此,让我们从一个decode_utf8函数开始。我们将只处理2个字节的序列:
// in `upper.c`
#include // printf
#include // uint8_t, uint32_t
#include // exit
void decode_utf8(char *src, uint32_t *dst) {
int i = 0;
int j = 0;
while (1) {
uint8_t c = src[i];
if (c == 0) {
dst[j] = 0;
break; // null terminator
}
uint32_t scalar;
int len;
if (c >> 3 == 0b11110) {
fprintf(stderr, "decode_utf8: 4-byte sequences are not supported!\n");
exit(1);
} if (c >> 4 == 0b1110) {
fprintf(stderr, "decode_utf8: 3-byte sequences are not supported!\n");
exit(1);
} else if (c >> 5 == 0b110) {
// 2-byte sequence
uint32_t b1 = (uint32_t) src[i];
uint32_t b2 = (uint32_t) src[i + 1];
uint32_t mask1 = 0b0000011111000000;
uint32_t mask2 = 0b0000000000111111;
scalar = ((b1 << 6) & mask1) | ((b2 << 0) & mask2);
len = 2;
} else {
// 1-byte sequence
scalar = (uint32_t) c;
len = 1;
}
dst[j++] = scalar;
i += len;
}
}
int main(int argc, char **argv) {
uint32_t scalars[1024]; // hopefully that's enough
decode_utf8(argv[1], scalars);
for (int i = 0;; i++) {
if (scalars[i] == 0) {
break;
}
printf("U+%04X ", scalars[i]);
}
printf("\n");
return 0;
} $ gcc upper.c -o upper
$ ./upper "noël"
U+006E U+006F U+00EB U+006C从逻辑上讲,U+00EB应该是“ë”的代码位置,确实是的!
它的全名是“带Diaeresis的拉丁文小写字母E”。因此,现在我们只需要进行反向转换即可!
// in `upper.c`
void encode_utf8(uint32_t *src, char *dst) {
int i = 0;
int j = 0;
while (1) {
uint32_t scalar = src[i];
if (scalar == 0) {
dst[j] = 0; // null terminator
break;
}
if (scalar > 0b11111111111) {
fprintf(stderr, "Can only encode codepoints <= 0x%x", 0b11111111111);
exit(1);
}
if (scalar > 0b1111111) { // 7 bits
// 2-byte sequence
uint8_t b1 = 0b11000000 | ((uint8_t) ((scalar & 0b11111000000) >> 6));
// 2-byte marker first 5 of 11 bits
uint8_t b2 = 0b10000000 | ((uint8_t) (scalar & 0b111111));
// continuation last 6 of 11 bits
dst[j + 0] = b1;
dst[j + 1] = b2;
j += 2;
} else {
// 1-byte sequence
dst[j] = (char) scalar;
j++;
}
i++;
}
}
// omitted: decode_utf8
int main(int argc, char **argv) {
uint32_t scalars[1024]; // hopefully that's enough
decode_utf8(argv[1], scalars);
for (int i = 0;; i++) {
if (scalars[i] == 0) {
break;
}
printf("U+%04X ", scalars[i]);
}
printf("\n");
uint8_t result[1024]; // yolo
encode_utf8(scalars, result);
printf("%s\n", result);
return 0;
}$ gcc upper.c -o upper
$ ./upper "noël"
U+006E U+006F U+00EB U+006C
noël太棒了!现在,我们需要的只是某种转换表!从小写的代码位置到大写的对应值。我们将编写足以支持法语的内容:
#include // toupper
int main(int argc, char **argv) {
uint32_t scalars[1024]; // hopefully that's enough
decode_utf8(argv[1], scalars);
for (int i = 0;; i++) {
if (scalars[i] == 0) {
break;
}
printf("U+%04X ", scalars[i]);
}
printf("\n");
// this is the highest codepoint we can decode/encode successfully
const size_t table_size = 0b11111111111;
uint32_t lower_to_upper[table_size];
// initialize the table to just return the codepoint unchanged
for (uint32_t cp = 0; cp < table_size; cp++) {
lower_to_upper[cp] = cp;
}
// set a-z => A-Z
for (int c = 97; c <= 122; c++) { // ha.
lower_to_upper[(uint32_t) c] = (uint32_t) toupper(c);
}
// note: nested functions is a GNU extension!
void set(char *lower, char *upper) {
uint32_t lower_s[1024];
uint32_t upper_s[1024];
decode_utf8(lower, lower_s);
decode_utf8(upper, upper_s);
for (int i = 0;; i++) {
if (lower_s[i] == 0) {
break;
}
lower_to_upper[lower_s[i]] = upper_s[i];
}
}
// set a few more
set(
"éêèàâëüöïÿôîçæœ",
"ÉÊÈÀÂËÜÖÏŸÔÎÇÆŒ"
);
// now convert our scalars to upper-case
for (int i = 0;; i++) {
if (scalars[i] == 0) {
break;
}
scalars[i] = lower_to_upper[scalars[i]];
}
uint8_t result[1024]; // yolo
encode_utf8(scalars, result);
printf("%s\n", result);
return 0;
} $ gcc upper.c -o upper
$ ./upper "Voix ambiguë d'un cœur qui, au zéphyr, préfère les jattes de kiwis"
U+0056 U+006F U+0069 U+0078 U+0020 U+0061 U+006D U+0062 U+0069 U+0067 U+0075 U+00EB U+0020 U+0064 U+0027 U+0075 U+006E U+0020 U+0063 U+0153 U+0075 U+0072 U+0020 U+0071 U+0075 U+0069 U+002C U+0020 U+0061 U+0075 U+0020 U+007A U+00E9 U+0070 U+0068 U+0079 U+0072 U+002C U+0020 U+0070 U+0072 U+00E9 U+0066 U+00E8 U+0072 U+0065 U+0020 U+006C U+0065 U+0073 U+0020 U+006A U+0061 U+0074 U+0074 U+0065 U+0073 U+0020 U+0064 U+0065 U+0020 U+006B U+0069 U+0077 U+0069 U+0073
VOIX AMBIGUË D'UN CŒUR QUI, AU ZÉPHYR, PRÉFÈRE LES JATTES DE KIWIS传递字符串
首先,是C程序,C很容易!只需使用char *。
// in `woops.c`
#include
int len(char *s) {
int l = 0;
while (s[l]) {
l++;
}
return l;
}
int main(int argc, char **argv) {
char *arg = argv[1];
int l = len(arg);
printf("length of \"%s\" = %d\n", arg, l);
} $ # we're back into the parent of the "rustre" directory
$ # (in case you're following along)
$ gcc woops.c -o woops
$ ./woops "dog"
length of "dog" = 3看到?简单!没什么String/&str。回到现实。首先,这实际上不是字符串的长度。它是使用UTF-8对其进行编码所需的字节数。因此,例如:
$ ./woops "née"
length of "née" = 4
$ ./woops "????"
length of "????" = 4我们不会花费一半的文章来实现UTF-8解码器和编码器,只是感到惊讶的是,我们无法正确地计算字符数。而且,那不是现在困扰我的事情。现在困扰我的是,编译器没有采取任何措施阻止我们执行此操作:
#include
int len(char *s) {
s[0] = '\0';
return 0;
}
int main(int argc, char **argv) {
char *arg = argv[1];
int l = len(arg);
printf("length of \"%s\" = %d\n", arg, l);
} $ gcc woops.c -o woops
$ ./woops "some user input"
length of "" = 0len()是正确的,将通过单元测试。通过它执行完成时,字符串的长度是零。如果没有人愿意去看len函数本身,例如,如果它在第三方库中,或更糟的是在专有的第三方库中,那么调试将很有趣。当然,C有const:
int len(const char *s) {
s[0] = '\0';
return 0;
}但它不会通过编译:
woops.c: In function ‘len’:
woops.c:4:10: error: assignment of read-only location ‘*s’
4 | s[0] = '\0';
|修改下:
int len(const char *s) {
char *S = (void *) s;
S[0] = '\0';
return 0;
}现在它再次通过编译,运行它,它会默默地覆盖我们的输入字符串,就像之前一样。
Rust程序部分:
print程序
错误处理
迭代
传递字符串转换成大写
索引
print程序
让我们看看实现打印参数,Rust程序是怎样实现的:
$ cargo new rustre
Created binary (application) `rustre` package
$ cd rustrefn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
println!("{}", arg.to_uppercase());
}以上内容的说明:std::env::args()返回一个Iterator字符串。skip(1)忽略程序名称(通常是第一个参数),next()获取迭代器中的下一个元素(第一个“实际”)参数。可能有下一个参数,也可能没有。如果没有,.expect(msg)通过停止程序打印msg。如果有,就有了一个Option!
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.01s
Running `target/debug/rustre`
thread 'main' panicked at 'should have one argument', src/libcore/option.rs:1188:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace.好的!因此,当我们不传递参数时,运行程序会有如上输出。让我们传递一些测试字符串:
$ cargo run --quiet -- "noël"
NOËL
$ cargo run --quiet -- "trans rights"
TRANS RIGHTS
$ cargo run --quiet -- "voix ambiguë d'un cœur qui, au zéphyr, préfère les jattes de kiwis"
VOIX AMBIGUË D'UN CŒUR QUI, AU ZÉPHYR, PRÉFÈRE LES JATTES DE KIWIS
$ cargo run --quiet -- "heinz große"
HEINZ GROSSE一切都测试了!最后一个特别酷,用德语的“ß”,确实是“ss”的连字。好吧,这很复杂,但这就是要点。
错误处理
因此Rust的行为就像字符串是UTF-8一样,这意味着它必须在某个时刻解码我们的命令行参数,意味着这可能会失败。但是,只在没有参数的情况下看到错误处理,而对于参数无效的UTF-8则看不到错误处理。什么是无效的UTF-8?好吧,我们已经看到“é”被编码为“c3 e9”,所以可以这样工作:
$ cargo run --quiet -- $(printf "\\xC3\\xA9")
É我们已经看到一个双字节的UTF-8序列具有:
在第一个字节中指示它是一个双字节的序列(前三个位,110)
在第二个字节中指示它是多字节序列的延续(前两个位10)
如果我们开始读取一个双字节的序列,然后突然停止怎么办?如果我们传入了C3,但未传入A9呢?
$ cargo run --quiet -- $(printf "\\xC3")
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: "\xC3"', src/libcore/result.rs:1188:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace.查看错误堆栈信息。
$ RUST_BACKTRACE=1 cargo run --quiet -- $(printf "\\xC3")
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: "\xC3"', src/libcore/result.rs:1188:5
stack backtrace:
(cut)
13: core::result::unwrap_failed
at src/libcore/result.rs:1188
14: core::result::Result::unwrap
at /rustc/5e1a799842ba6ed4a57e91f7ab9435947482f7d8/src/libcore/result.rs:956
15: ::next::{{closure}}
at src/libstd/env.rs:789
16: core::option::Option::map
at /rustc/5e1a799842ba6ed4a57e91f7ab9435947482f7d8/src/libcore/option.rs:450
17: ::next
at src/libstd/env.rs:789
18: <&mut I as core::iter::traits::iterator::Iterator>::next
at /rustc/5e1a799842ba6ed4a57e91f7ab9435947482f7d8/src/libcore/iter/traits/iterator.rs:2991
19: core::iter::traits::iterator::Iterator::nth
at /rustc/5e1a799842ba6ed4a57e91f7ab9435947482f7d8/src/libcore/iter/traits/iterator.rs:323
20: as core::iter::traits::iterator::Iterator>::next
at /rustc/5e1a799842ba6ed4a57e91f7ab9435947482f7d8/src/libcore/iter/adapters/mod.rs:1657
21: rustre::main
at src/main.rs:2
(cut) 基本上是这样:
在
main()我们调用
Iterator的.next()最后调用
Result的.unwrap()此时panicked
这意味着只有当我们尝试将参数作为String获取时,它才会出现panic。如果我们将其作为OsString,就不会panic:
fn main() {
let arg = std::env::args_os()
.skip(1)
.next()
.expect("should have one argument");
println!("{:?}", arg)
}$ cargo run --quiet -- hello
"hello"
$ cargo run --quiet $(printf "\\xC3")
"\xC3"但是它没有.to_uppercase()方法。因为它是一个OsString,它是一系列字节。C程序如何处理无效的UTF-8输入?
$ ../upper $(printf "\\xC3")
U+00C0 U+0043 U+0044 U+0050 U+0041 U+0054 U+0048 U+003D U+002E U+003A U+002F U+0068 U+006F U+006D U+0065 U+002F U+0061 U+006D U+006F U+0073 U+002F U+0072 U+0075 U+0073 U+0074 U+003A U+002F U+0068 U+006F U+006D U+0065 U+002F U+0061 U+006D U+006F U+0073 U+002F U+0067 U+006F U+003A U+002F U+0068 U+006F U+006D U+0065 U+002F U+0061 U+006D U+006F U+0073 U+002F U+0066 U+0074 U+006C U+003A U+002F U+0068 U+006F U+006D U+0065 U+002F U+0061 U+006D U+006F U+0073 U+002F U+0070 U+0065 U+0072 U+0073 U+006F U+003A U+002F U+0068 U+006F U+006D U+0065 U+002F U+0061 U+006D U+006F U+0073 U+002F U+0077 U+006F U+0072 U+006B
ÀCDPATH=.:/HOME/AMOS/RUST:/HOME/AMOS/GO:/HOME/AMOS/FTL:/HOME/AMOS/PERSO:/HOME/AMOS/WORK答案是:不好。实际上一点也不好。UTF-8解码器首先读取C3,然后读取下一个字节(是空终止符),结果应为“à”。但它不再停下来,而是读完参数末尾,直接进入环境块,找到第一个环境变量。现在,在这种情况下,这似乎很温和。但是如果该C程序被用作Web服务器的一部分,并且其输出直接显示给用户怎么办?如果第一个环境变量不是CDPATH,而是 SECRET_API_TOKEN怎么办?那将是一场灾难。
但如果命令行参数是无效的UTF-8,Rust程序就会尽早panic。如果想优雅地处理这种情况怎么办?可以使用OsStr::to_str,它返回一个Option值。
fn main() {
let arg = std::env::args_os()
.skip(1)
.next()
.expect("should have one argument");
match arg.to_str() {
Some(arg) => println!("valid UTF-8: {}", arg),
None => println!("not valid UTF-8: {:?}", arg),
}
}$ cargo run --quiet -- "é"
valid UTF-8: é
$ cargo run --quiet -- $(printf "\\xC3")
not valid UTF-8: "\xC3"精彩。我们学到了什么?
在Rust中,只要你不明确地用unsafe,类型String的值永远是有效的UTF-8。如果尝试使用无效的UTF-8构建String,则会出现错误。一些程序,像std::env::args()会隐藏错误处理,因为错误的情况非常少。但它仍然会检查错误,并会检查是否发生错误,因为这样做是安全的。
相比之下,C没有字符串类型。它甚至没有真正的字符类型。char是一个ASCII字符加上一个附加位,实际上,它只是一个带符号的8位整数:int8_t。绝对不能保证char *其中的任何内容都是有效的UTF-8。没有与char *关联的编码,只是内存中的地址。也没有关联的长度,计算其长度涉及找到空终止符。空终止字符也是一个严重的安全问题,更不用说NUL是有效的Unicode字符,因此以空字符结尾的字符串不能表示所有有效的UTF-8字符串。
迭代 Iteration
我们将如何用空格分隔字符?
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
for c in arg.chars() {
print!("{} ", c);
}
println!()
}$ cargo run --quiet -- "cup of tea"
c u p o f t e a很简单!让我们尝试使用非ASCII字符:
$ cargo run --quiet -- "23€ ≈ ¥2731"
2 3 € ≈ ¥ 2 7 3 1
$ cargo run --quiet -- "memory safety ???? please ????"
m e m o r y s a f e t y ???? p l e a s e ????一切似乎都很好。如果我们要打印Unicode标量值的数字而不是它们的字形,该怎么办?
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
for c in arg.chars() {
print!("{} (U+{:04X}) ", c, c as u32);
}
println!()
}$ cargo run --quiet -- "aimée"
a (U+0061) i (U+0069) m (U+006D) é (U+00E9) e (U+0065)酷!如果我们想显示其为UTF-8编码怎么办?我的意思是打印单个字节?
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
for b in arg.bytes() {
print!("{:02X} ", b);
}
println!()
}$ cargo run --quiet -- "aimée"
61 69 6D C3 A9 65 有我们的"c3 a9"!很简单。目前为止,我们还没对类型的担心,在我们的Rust程序中还没有一个String或&str。所以,让我们去寻找麻烦。
传递字符串转换成大写
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
println!("upp = {}", uppercase(arg));
println!("arg = {}", arg);
}
fn uppercase(s: String) -> String {
s.to_uppercase()
}$ cargo build --quiet
error[E0382]: borrow of moved value: `arg`
--> src/main.rs:8:26
|
2 | let arg = std::env::args()
| --- move occurs because `arg` has type `std::string::String`, which does not implement the `Copy` trait
...
7 | println!("upp = {}", uppercase(arg));
| --- value moved here
8 | println!("arg = {}", arg);
| ^^^ value borrowed here after move
error: aborting due to previous error
For more information about this error, try `rustc --explain E0382`.
error: could not compile `rustre`.哦,上帝,编译器来了。问题在于我们将arg传入uppercase(),然后又再次使用它。我们可以先打印arg,然后再调用uppercase()。那行得通吗?可以。但是,假设我们就是需要先调用uppercase呢?
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
println!("upp = {}", uppercase(arg.clone()));
println!("arg = {}", arg);
}
fn uppercase(s: String) -> String {
s.to_uppercase()
}$ cargo run --quiet -- "dog"
upp = DOG
arg = dog但是这有点愚蠢。为什么我们需要克隆arg?只是传入uppercase,我们不需要在内存中有第二个拷贝。现在在内存中,我们有:
arg(“dog”)
arg的拷贝,我们传入
uppercase()(“dog”)uppercase()返回值(“DOG”)
我猜这是&str存在的意义吧?让我们尝试一下:
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
println!("upp = {}", uppercase(arg));
println!("arg = {}", arg);
}
fn uppercase(s: &str) -> String {
s.to_uppercase()
}cargo run --quiet -- "dog"
error[E0308]: mismatched types
--> src/main.rs:7:36
|
7 | println!("upp = {}", uppercase(arg));
| ^^^
| |
| expected `&str`, found struct `std::string::String`
| help: consider borrowing here: `&arg`根据编译器的提示修改:
println!("upp = {}", uppercase(&arg));$ cargo run --quiet -- "dog"
upp = DOG
arg = dog为了使其更接近于C代码,我们应该:
分配一个“目标”
传递“目标”到
uppercase()uppercase()遍历每个字符,将其转换为大写,并将其附加到"目标"
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
let mut upp = String::new();
println!("upp = {}", uppercase(&arg, upp));
println!("arg = {}", arg);
}
fn uppercase(src: &str, dst: String) -> String {
for c in src.chars() {
dst.push(c.to_uppercase());
}
dst
}$ cargo run --quiet -- "dog"
error[E0308]: mismatched types
--> src/main.rs:14:18
|
14 | dst.push(c.to_uppercase());
| ^^^^^^^^^^^^^^^^ expected `char`, found struct `std::char::ToUppercase`ToUppercase,该结构由char上的to_uppercase方法创建,返回一个迭代器,该迭代器生成char的大写等效项。
迭代器,知道这一点,我们可以使用for x in y:
fn uppercase(src: &str, dst: String) -> String {
for c in src.chars() {
for c in c.to_uppercase() {
dst.push(c);
}
}
dst
}$ error[E0596]: cannot borrow `dst` as mutable, as it is not declared as mutable
--> src/main.rs:15:13
|
12 | fn uppercase(src: &str, dst: String) -> String {
| --- help: consider changing this to be mutable: `mut dst`
...
15 | dst.push(c);
| ^^^ cannot borrow as mutable让我们看一下String::push的声明:
pub fn push(&mut self, ch: char)因此dst.push(c)与String::push(&mut dst, c)完全相同。根据编译器建议修改:
fn uppercase(src: &str, mut dst: String) -> String {
...
}$ cargo run --quiet -- "dog"
upp = DOG
arg = doguppercase没有返回值呢?
fn uppercase(src: &str, mut dst: String) {
for c in src.chars() {
for c in c.to_uppercase() {
dst.push(c);
}
}
}cargo run --quiet -- "dog"
error[E0382]: borrow of moved value: `upp`
--> src/main.rs:10:26
|
7 | let upp = String::new();
| --- move occurs because `upp` has type `std::string::String`, which does not implement the `Copy` trait
8 | uppercase(&arg, upp);
| --- value moved here
9 |
10 | println!("upp = {}", upp);
| ^^^ value borrowed here after move我们需要让upp可变地借用。
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
let mut upp = String::new();
// was just `upp`
uppercase(&arg, &mut upp);
println!("upp = {}", upp);
println!("arg = {}", arg);
}
// was `mut dst: String`
fn uppercase(src: &str, dst: &mut String) {
for c in src.chars() {
for c in c.to_uppercase() {
dst.push(c);
}
}
}$ cargo run --quiet -- "dog"
upp = DOG
arg = dog现在又可以使用了!可增长的字符串,这是否意味着我们可以预分配合理大小的String,然后将其重新用于多个uppercase 调用?
索引
C允许我们直接索引,Rust允许我们这样做吗?
fn main() {
for arg in std::env::args().skip(1) {
for i in 0..arg.len() {
println!("arg[{}] = {}", i, arg[i]);
}
}
}$ cargo run --quiet -- "dog"
error[E0277]: the type `std::string::String` cannot be indexed by `usize`
--> src/main.rs:4:41
|
4 | println!("arg[{}] = {}", i, arg[i]);
| ^^^^^^ `std::string::String` cannot be indexed by `usize`
|
= help: the trait `std::ops::Index` is not implemented for `std::string::String` 我们不可以。我们可以先将其转换为Unicode标量值数组,然后对其进行索引:
fn main() {
for arg in std::env::args().skip(1) {
let scalars: Vec = arg.chars().collect();
for i in 0..scalars.len() {
println!("arg[{}] = {}", i, scalars[i]);
}
}
} $ cargo run --quiet -- "dog"
arg[0] = d
arg[1] = o
arg[2] = g是的,行得通!老实说,这样比较好,因为我们只需要解码一次UTF-8字符串,然后我们就可以进行随机访问了。这可能就是为什么它没有实现Index的原因。
有趣的事情:Index。
fn main() {
for arg in std::env::args().skip(1) {
let mut stripped = &arg[..];
while stripped.starts_with(" ") {
stripped = &stripped[1..]
}
while stripped.ends_with(" ") {
stripped = &stripped[..stripped.len() - 1]
}
println!(" arg = {:?}", arg);
println!("stripped = {:?}", stripped);
}
}$ cargo run --quiet -- " floating in space "
arg = " floating in space "
stripped = "floating in space"String是堆分配的,因为它是可增长的。而&str可以从任何地方引用数据:堆,栈,甚至程序的数据段。
&str,它是不同的,它指向相同的内存区域,只是在不同的偏移量处开始和结束。实际上,我们可以使其成为一个函数:
fn main() {
for arg in std::env::args().skip(1) {
let stripped = strip(&arg);
println!(" arg = {:?}", arg);
println!("stripped = {:?}", stripped);
}
}
fn strip(src: &str) -> &str {
let mut dst = &src[..];
while dst.starts_with(" ") {
dst = &dst[1..]
}
while dst.ends_with(" ") {
dst = &dst[..dst.len() - 1]
}
dst
}而且效果也一样。不过,这似乎很危险。如果原始字符串的内存被释放怎么办?
fn main() {
let stripped;
{
let original = String::from(" floating in space ");
stripped = strip(&original);
}
println!("stripped = {:?}", stripped);
}$ cargo run --quiet -- " floating in space "
error[E0597]: `original` does not live long enough
--> src/main.rs:5:26
|
5 | stripped = strip(&original);
| ^^^^^^^^^ borrowed value does not live long enough
6 | }
| - `original` dropped here while still borrowed
7 | println!("stripped = {:?}", stripped);
| -------- borrow later used here在Rust中?编译器将检查所有的"恶作剧"。
最后,String用范围索引,很酷,但是..是字符范围吗?
fn main() {
for arg in std::env::args().skip(1) {
println!("first four = {:?}", &arg[..4]);
}
}$ cargo run --quiet -- "want safety?"
first four = "want"
$ cargo run --quiet -- "????????????????"
first four = "????"字节范围。我以为所有Rust字符串都是UTF-8?但是使用切片,我们可以得到部分多字节序列,或无效的UTF-8?假如:
fn main() {
for arg in std::env::args().skip(1) {
println!("first two = {:?}", &arg[..2]);
}
}$ cargo run --quiet -- "????????????????"
thread 'main' panicked at 'byte index 2 is not a char boundary; it is inside '????' (bytes 0..4) of `????????????????`', src/libcore/str/mod.rs:2069:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace.那太好了。它会panic,这是安全的事情。
结束语
无论如何,这篇文章已经很长了。希望它对Rust中的字符串处理有足够的介绍,以及Rust为什么同时具有String和&str。
答案当然依旧是安全性,正确性和性能。
在我们编写的最后一个Rust字符串操作程序时,确实遇到了障碍,但是它们主要是编译时错误或panic。我们没有一次:
从无效地址读取
写入无效的地址
忘了释放东西
覆盖了其他一些数据
需要一个额外的工具来告诉我们问题出在哪里
而且,加上令人惊叹的编译器信息以及社区,这就是Rust的美。
原文地址:https://fasterthanli.me/blog/2020/working-with-strings-in-rust/