R语言-豆瓣电影top250数据爬取和分析
R语言-豆瓣电影top250数据爬取和分析
1. 在豆瓣网站爬取TOP250电影的信息。
首先加载包。
由网站可知豆瓣电影信息包含排名、电影名、评分、评分人数、导演、演员、年份、国家、类型信息,利用RCurl包、rvest包等将其爬取并存放在数据框内,最后将将其保存为Excel文件。
library(stringr)
library(rvest)
library(RCurl)
library(openxlsx)
library(XML)
library(dplyr)
library(magrittr)
#构建数据框存放数据
top <-data.frame()
#设置网页入口网 根据页数设置循环
i<- seq(0,225,by=25)
for (i in 1:10){
url1 <- "https://movie.douban.com/top250"
url2 <- "?start="
url3 <-"&filter="
url <-paste(url1,url2,a[i],url3,sep = "")
webpage <-read_html(url,encoding = 'utf-8')
#电影名
title <- html_nodes(webpage,".title:nth-child(1)") %>% html_text()
#排名
rank <- html_nodes(webpage,"em") %>% html_text()
rank <- as.numeric(rank)
#评分
rate <- html_nodes(webpage, ".rating_num") %>% html_text()
rate <-as.numeric(rate)
#评分人数
num <- html_nodes(webpage, ".rating_num~ span") %>% html_text() %>%
str_match("[0-9]*")
num <- as.numeric(num)
num <- num[!is.na(num)]
#评论
comment <- html_nodes(webpage, ".inq") %>% html_text()
#提取所有的附加信息
info <- webpage %>% html_nodes("div.info div.bd p:nth-child(1)") %>%
html_text(trim = TRUE)
info <- str_split(info, "\\n")
info1 <- sapply(info, "[", 1)
#导演
director <- str_trim(sapply(str_split(info1, "\\s{3}"), "[", 1))
#演员
actor <- str_trim(sapply(str_split(info1, "\\s{3}"), "[", 2))
info2 <- sapply(info, "[", 2)
#年份
year <- str_trim(sapply(str_split(info2, "/"), "[", 1))
#国家
region <- str_trim(sapply(str_split(info2, "/"), "[", 2))
#类型
category <- str_trim(sapply(str_split(info2, "/"), "[", 3))
top <- rbind(top,data.frame(rank,title,rate,num,director,actor,year,region,category))
}
#导出为Excel文件
wb <-createWorkbook()
addWorksheet(wb,"1")
writeDataTable(wb,1,top,tableStyle = "TableStyleLight16")
saveWorkbook(wb,"6.xlsx",overwrite = TRUE)2. 数据预处理、对数据进行探索性分析
在爬取的数据中,排名为有序型变量,年份,评分人数及评分为连续型变量,电影名称,导演,演员,国家,电影类型为名义型变量。首先进行异常值处理,通过观察发现由于网页内容原因有一个国家的数据以及两个电影类型的数据出现了错误,通过定位到该数据进行定向修改来完成处理。
#处理部分异常数据 年份
movie <- read.xlsx("C:\\Users\\asus\\Documents\\6.xlsx")
movie[,7] <-str_extract(movie[,7],'[0-9]{4}')
movie$year <- as.numeric(as.character(movie$year))
#处理异常数据 把国家单独提出来并修改
area <- movie[,8]
area <- strsplit(movie[,8], split = "\\s")
area <- sapply(area,function(x) x[1]) %>% str_trim()
area[219] <- "中国大陆"
area[71] <- "中国大陆"
#新数据框
ty <-movie[,9] %>% strsplit(movie[,9],split="\\s")
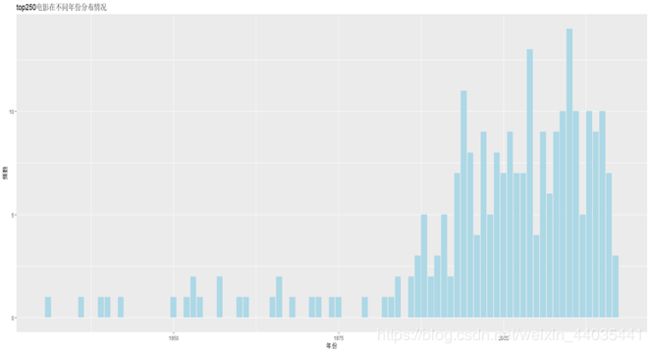
ty <-sapply(ty, function(x) x[1])%>% str_trim()对变量进行单变量分析,通过箱线图可知,年份的数据并不集中,中位数在2000之后,主要分布在1988-2017之间,有小部分异常小的数据。电影评分的数据相对比较集中,中位数为8.8,主要分布在8.6-9.0,有一异常值9.6。评分人数的数据相对比较不集中,中位数为298684,有小部分异常大的数据,最大值超过130万。考虑到数据源的特殊性,保留异常值。(部分图片未上传)


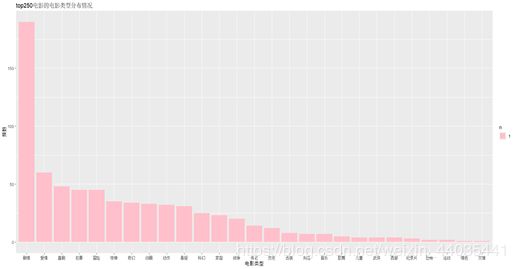
通过饼图等可知,总共有21个国家的电影进入榜单,在发行电影的国家中,美国占接近一半,为占比最大的国家,其次为日本、香港、英国。通过柱形图可知,总共有27种电影类型。在各种电影类型中,“剧情”占比超过7/10,为占比最大的电影类型,其次为“爱情”、“喜剧”、“犯罪”。(部分图片未上传)
area0 <-data.frame(area)
movie1 <-rbind( data.frame(movie$rank, ty, area))
movie1 <-movie1[-71,]
movie1 <-movie1[-218,]
#画图 bar-国家
ggplot(area0,aes(x=area0$area))+geom_bar(stat="count",fill="lightgreen")+labs(
x="国家",y="频数", title="top250电影在不同国家分布情况")
area1 <-table(with(area0,tapply(area, list(area), length)))
area1 = area0 %>% group_by(area) %>% count %>% ungroup
install.packages("ggthemes")
library("ggthemes")
# 扇形图 国家
ggplot(area1,aes(x="",y= area1$n,fill=area1$area))+geom_bar(stat="identity")+ coord_polar(theta = "y")+theme_bw()
#散点图 排名与国家
ggplot(movie1,aes(y=movie1$movie.rank,x=movie1$area)) + geom_point(color ="darkblue" )+labs(
x="电影排名",y="国家" ,title="top250电影排名及其国家分布情况")
#散点图 排名与类型
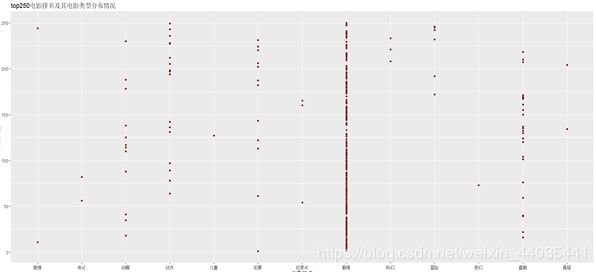
ggplot(movie1,aes(y=movie1$movie.rank,x=movie1$ty)) + geom_point(color ="darkred" )+labs(
x="电影排名",y="电影类型" ,title="top250电影排名及其电影类型分布情况")
#柱形图 年份
ggplot(movie,aes(x=movie$year))+geom_bar(stat="count",fill="lightblue")+labs(
x="年份",y="频数", title="top250电影在不同年份分布情况")
#画图 分数与评分人数的关系
ggplot(movie,aes(x=movie$rate,y=movie$num)) + geom_point(color ="darkblue" )+labs(
x="电影评分",y="评分人数" ,title="top250电影分数与评分人数情况")
# 评分人数 排名
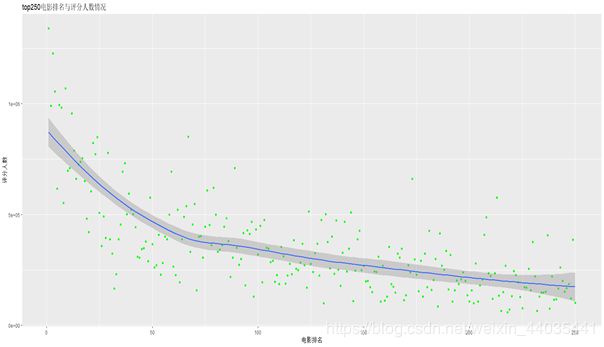
ggplot(movie,aes(x=movie$rank,y=movie$num)) + geom_point(color ="green" )+labs(
x="电影排名",y="评分人数" ,title="top250电影排名与评分人数情况")+stat_smooth()
#中位数
median(movie$num)
nation <- data.frame()
nation <- (movie$region)
#连续型变量箱线图
#年份
p<- ggplot(movie,aes(y=movie$year))+geom_boxplot(fill="orange")+labs(
y = "年份")
#评分
pp<- ggplot(movie,aes(y=movie$rate))+geom_boxplot(fill="green")+labs(
y = "电影评分")
#评分人数
ppp<- ggplot(movie,aes(y=movie$num))+geom_boxplot(fill="pink")+labs(
y = "评分人数")
#柱状图 评分
ggplot(movie,aes(x=movie$rate))+geom_bar(stat="count",fill="purple")+labs(
x="评分",y="频数")
3.简单分析
词云制作:

#wordclond
#java
#download package from website first
install.packages("rJava")
Sys.setenv(JAVA_HOME="C:\\Program Files\\Java\\jre1.8.0_201")
library(rJava)
library(wordcloud2)
library(wordcloud)
library(devtools)
library(Rweibo)
library(Rwordseg)
library(ggplot2)
data <- read.xlsx("6.xlsx")
data1=data[,9]
write.table(data1, "C:\\Users\\asus\\data.txt", sep = "\t", quote = FALSE, row.names = FALSE)
text <- text[-1]
text <- segmentCN("C:\\Users\\asus\\data.txt",returnType = "tm")
#读入分词文件
text1 <- readLines("C:\\Users\\asus\\data.txt",encoding = 'utf-8')
#正则表达式按空格把词汇分开
word = lapply(X = text1, FUN = strsplit, "\\s") #word是一个长list.
word1=unlist(word)
#统计词频
df=table(word1)
df=sort(df,decreasing = T)
#把词汇词频存入数据框
df1 = data.frame(word = names(df), freq = df)
df1 <- df1[,2:3]
#修改异常值
df1 <- df1[-26,]
df1 <- df1[-26,]
df1 <- df1[-28,]
wordcloud2(df1,color="random-light",backgroundColor = 'black')
wordcloud2(df1)
wordcloud2(df1, fontFamily = "微软雅黑",
color = "random-light", backgroundColor = "grey") 通过相关系数矩阵可得,电影排名与电影评分以及电影排名相关性较强,为强相关,电影评分与评分人数相关性中等。
Rank rate num
rank 1.0 -0.7 -0.7 rate -0.7 1.0 0.3
num -0.7 0.3 1.0 year NA NA NA
#相关性系数矩阵
mydata <- read.delim("C:\\Users\\asus\\Documents\\11.txt",header = TRUE)
d<- mydata[,c(1,3,4,7)]
d <- as.matrix(d)
#进行转换后变成字符串矩阵,要将其转为数据值。当apply函数的第二个值为1时则修改的是行
d <- apply(d,2,as.numeric)
res <- cor(d)
round(res,1)
install.packages("corrplot")
library(corrplot)
corrplot(res,type="upper",order="hclust",tl.col="black",tl.srt=45)通过散点图等的分析可知,电影评分与评分人数没有很大的相关性,电影排名与评分人数呈正相关,电影评分人数越多,排名越靠前。电影类型为剧情或美国出品的电影分布在排名的各个区间,数量也是最多,排名也较靠前。(图片可用ggplot2包制作)
4.分析结论
在豆瓣电影的TOP250中,电影产地为美国、类型为剧情的电影最受欢迎,其次是爱情、喜剧、犯罪类型的电影也比较受欢迎。大多数时候评分人数越多,电影评分也会越高。
其中,美国的电影“肖申克的救赎”获得极大多人的喜爱,为TOP1,电影评分与评分人数都遥遥领先于其他电影。