程序员C语言快速上手——工程篇(十二)
文章目录
- 链接与库
- 前言
- 虚拟内存
- 总结
- 理解链接
- C程序编译的四个阶段
- 预处理器
- 编译器
- 汇编器
- 链接器
- 总结
- 什么是链接
- 查看符号表
- *拓展:nm命令查看符号类型
- 静态链接
- 函数库
- 静态库
- 打包静态库
- 链接静态库
- 动态库
- 生成与位置无关的目标文件
- 打包动态库
- 关联动态库
- 动态库与静态库的区别
- 动态链接
- 位置无关代码
- 总结
- 动态库的运行时加载
- 欢迎关注我的公众号:编程之路从0到1
链接与库
前言
其实学完C语言的语法后,我们往往会有数不清的疑惑,例如编译器在编译的时候就可以分配内存,那么不同的程序会不会分配到相同的内存地址,计算机如何处理这种冲突?C语言既然可以操作内存,我们能不能修改其他程序的内存数据,游戏外挂是不是这样实现的?程序是怎么被加载到内存的,C语言main函数又是谁调用的?为什么编译之后还要链接?什么是动态库什么又是静态库?
大家是否也曾和我有过一样的疑问呢?这些知识其实都分散在操作系统原理、编译原理、汇编语言等领域,零散而不成系统,只有C语言才能将之串联成一条线索,但遗憾的是,市面上并没有一本讲C语言的书能把这些串起来,成体系的而又深入浅出的讲解清楚。也几乎没有太多书能深入的回答我上面提出的那些疑问。要想弄清楚这些问题,可能需要阅读大量的书籍,学习相当多的基础知识,往往让人望而却步。然而这些知识又是编程领域的九阳神功,一旦练成,其他花招只不过是信手拈来。这里,我结合自身的学习经验,谈谈最重要的一些概念,如果希望对这些概念有深入全面的学习和理解,推荐一本好书《程序员的自我修养——链接、 装载与库》,这是目前唯一一本综合起来讲解这些知识的书,当然,可能还需要看以下书籍《深入理解计算机系统(原书第3版)》、《链接器和加载器》、《汇编语言:基于LINUX 环境(第3版)》
好了,学习C语言语法的资料汗牛充栋,千篇一律,但是真正的干货却不多,下面就开始我们这个系列文章真正的干货吧
虚拟内存
在早期的计算机系统中,程序是可以直接操作物理内存的,例如我们可以使用C语言,往某个内存地址如0xff0001的空间写入数据,但是这样一样来,带来了许多无法避免的问题。比如说,程序A占用了绝大部分内存,那么再运行起程序B时,发现没有内存可用了,因此早期的系统是单任务的,同一时间不能运行多个程序,B程序想要启动,必须等到A程序运行结束,释放了内存之后,它才能启动。
随着计算机的发展,多任务的系统出现,同时可以运行多个程序,这时候带来新的问题,譬如内存重叠,内存冲突。假如编译器在编译程序A时,使用了0xff0001这个空间,而程序B在编译时也使用了这个地址,这两个程序同时一运行不就冲突了吗?程序在编译的时候,永远无法确定哪个内存地址是没有被人使用的,就像你去超市储物箱存东西,你不可能事先选定一个编号的柜子去存。不仅如此,还会存在其他的问题,比如恶意程序可以随意修改其他程序正在使用的内存,假如0xff0001是存的游戏中的金币数,那么其他任意程序都可以修改这个内存中的值,不存在软件安全可言。
为了适用计算机发展的需要,为了更高效的调度内存资源,为了解决以上的问题,操作系统出现了虚拟内存的概念。
关于虚拟内存的理解,这里举个形象的例子。
游泳馆一般都有储物柜,没有虚拟内存之前,就相当于没人管理储物柜,你自己可随便去打开一个储物柜放东西,有时候你打开的柜子可能已经被别人使用了,这就造成了冲突。现在游泳馆升级了,有专门的人管理储物柜,你不能直接去存东西,要存东西,你只能去柜台上找服务员,你找到服务员说,把我的包存到10号柜子里面去。服务人员看了你一眼说必须登记,于是你把自己的手机号报给了她,这时候服务员在登记表上记下你的手机号,以及你指定的10号柜,然后找到一个空的23号柜子,于是记一笔,实际存放于23号。等到你去取包时,你跟服务员说取10号柜子的包,然后报一下手机号,服务员则根据登记记录帮你去23号柜取出来。在这个例子中,10号就是虚拟地址,23号就是物理地址。使用虚拟地址的一个好处就是我们可以拥有完整的地址空间,什么意思呢,简单说,如果游泳馆共用100个柜子,编号从1到100,那么我们可以任意的使用1~100个虚拟地址,对应程序而言,它根本不知道自己使用的是虚拟地址。
现代操作系统,都是建立在虚拟内存管理之上的。所谓虚拟内存,简单说就是一张地址转换表,就如同我们上面举例中的登记表。程序不能直接操作物理内存了,只能操作这张转换表。虚拟内存的这张表为了提升查找效率,采用了分页的方式,因此这张表也叫页表。
来看一下简单的示意图
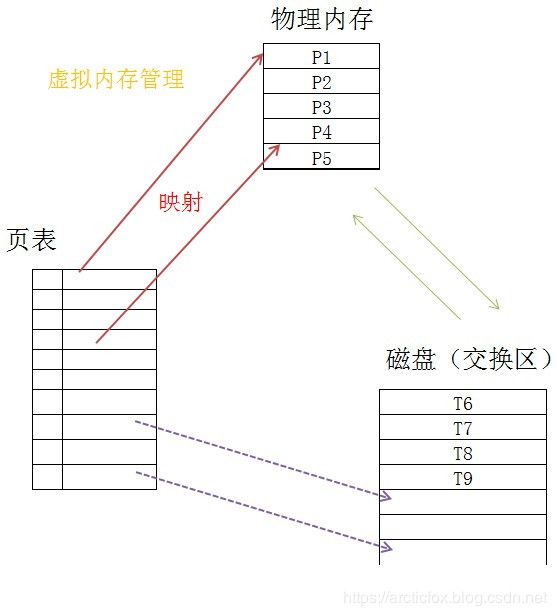
程序实际上操作的是页表中的虚拟内存地址,而页表映射了物理内存地址。这个页表好比一本字典中的目录索引,当程序访问一个虚拟内存地址时,经过页表转换后,才对应到真正的物理内存中,因此程序就不需要再关注真正的物理内存。对程序而言,它的一切操作都是对虚拟内存地址进行的,由操作系统在底层再去转换真正的物理内存地址。
那么这样做有什么好处呢?
- 避免地址冲突。即使两个程序操作了一个相同的内存地址也不会冲突,因为程序操作的都是虚拟地址,操作系统可以根据这两个程序不同的进程,分别将两个相同的虚拟地址映射到不同的物理地址中储存。比如两个人都住在76号,但一个是霞飞路76号,一个是上海路76号,根本不会冲突。
- 控制访问权限。现在大家都是操作的虚拟地址,如果你操其他程序的内存空间,操作系统在页表这一关就把你拦截掉了,根本无法操作到其他程序真正的物理内存空间。这在内存上保证了程序的安全性。
如果装过Linux系统,一定会很奇怪,为什么每次装系统都要设置一个交换区大小,交换区又是什么?
如果没有交换区,那么操作系统对内存的利用还是不够高效。例如我们电脑只有1G内存,当我们启动一个非常占用内存的程序A之后,加上操作系统,整个内存被使用了百分之九十还多,这个时候没有足够的内存了,是不是我们就不能其他启动其他程序了呢?这样的体验非常不好,开启一个大程序之后就不能启动其他程序了,多任务系统的优势没有发挥出来。虽然我们有时候在后台会开启多个程序,但往往是在多个程序之间切换的,并不都是同时使用,而且有些程序虽然开了,但是活跃性并不高,可能是用户无意开启了没有关闭。这时候交换区就派上了用场,实际上交换区就是在磁盘上开辟的一个固定空间,通常就是我们的硬盘,然后将不经常使用的程序所占用的内存移入到这个空间,相当于腾出内存供新开的程序使用。
关于交换区访问,我们以上图为例,如果在页表中访问T6的地址,发现页表中没有,那么就被称为缺页,系统就会启动对应的处理程序,简单说就是将物理内存中不活跃的内存,比如说是P5移入到交换区空间中,腾出P5的空间,然后将T6从交换区移入到之前P5的空间,再更新相关的页表,这样就发生了物理内存和交换区的内容交换,之后程序就可以正常访问T6的数据了。
因为内存是一种比较昂贵又紧俏的资源,因此大家只能轮换着来使用,交换区也正是利用的这么个思想。有了交换区的存在,我们实际使用的总内存就可以超过物理内存的总大小了。当然,交换区的大小也不能太大,因为硬盘的访问速度要比内存慢十万多倍,如果将大量的数据存在硬盘的交换区中,那么会严重影响程序的运行速度,卡慢就会这么发生。
总结
除了裸机环境(单片机之类)下,在现代操作系统中,C语言操作的都是虚拟内存,并不能直接操作物理内存。
理解链接
所谓链接,是指将多个目标文件合并成一个可执行文件的过程。链接解决了人们模块化开发的问题。如果我们把所有代码写在一个源码文件中,包括标准库实现,那么就可以不需要链接了。
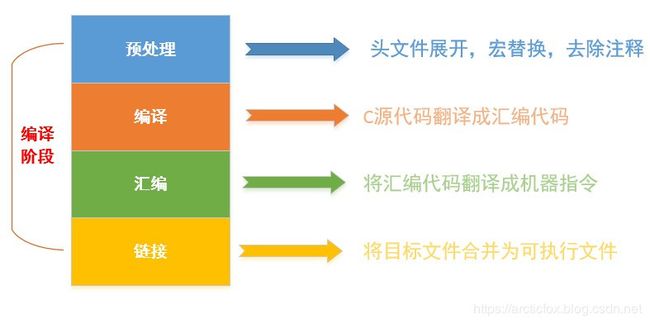
C程序编译的四个阶段
回顾一下C语言编译的四个阶段
- 预处理
- 编译
- 汇编
- 链接
在GCC编译器中,这四个阶段实际上是分别调用四个程序来处理,gcc对其提供了包装命令。之前的章节已经叙述过gcc包装之后的命令,这里我们直接使用这四个程序来处理。注:本系列内容使用MinGW开发环境,请阅读 程序员C语言快速上手——环境准备篇(一)
main.c
#define A 1
#define B 2
int add(int a,int b);
int start(){
add(A,B);
return 0;
}
calc.c
int add(int a,int b){
return a + b;
}
预处理器
使用cpp(C Pre-Processing)命令,其位于MinGW的bin目录下,配置好环境变量后可以直接使用。这里的cpp是预编译器。
cpp calc.c -o calc.i
cpp main.c -o main.i
使用-o指定输出.i后缀名的文件,这是预编译之后的源文件。对应的gcc包装命令是
gcc -E calc.c -o calc.i
编译器
使用cc1命令进行编译,将源文件编译为汇编代码。这里的cc1是编译器, cc1并不在MinGW的bin目录下,根据自己的系统版本,找到MinGW下面的cc1.exe,并将cc1.exe所在的文件夹加入系统环境变量中,我这里的路径是G:\developer\mingw64\MinGW\libexec\gcc\x86_64-w64-mingw32\7.2.0
cc1 calc.i -o calc.s
cc1 main.i -o main.s
编译后,生成的.s后缀名文件为汇编代码的源文件。对应的gcc包装命令是
gcc -S calc.i -o calc.s
汇编器
使用as命令生成二进制的目标文件。这里的as是汇编器。
as calc.s -o calc.o
as main.s -o main.o
对应的gcc包装命令是
gcc -c calc.s -o calc.o
链接器
使用ld命令进行链接,生成最后的可执行文件。这里的ld是链接器。
ld calc.o main.o -e start -o main.exe
对应的gcc包装命令是
gcc calc.o main.o -o main
注意:
C语言标准中,并未规定main函数作为入口函数,而GCC工具在链接时,也并未直接使用链接器进行链接,而是使用collect2库来处理链接,它会调用各种初始化函数,并使用libgcc库来设置__main符号,从而将main函数作为入口。详见GCC文档关于 collect2部分
实际上在汇编程序中,真正的入口是_start符号,这里我们就将start函数作为程序的入口,这是为了让链接命令更简洁,如果我们使用main作为入口,又使用链接器ld直接手动链接,那么链接命令会非常复杂。
通过链接器,将相关的目标文件(.o文件)链接起来,并使用-e参数指定程序的入口函数为start函数,最后生成main.exe可执行程序。
总结
有人说,一个C语言代码,为什么要经过这么多阶段才能被计算机运行呢?
根本原因是因为CPU只懂二进制指令,其他的啥也不懂,你写的C语言代码CPU不认识。而二进制指令又非常难懂,难以编写,人类为了偷懒,一步一步发明了更复杂的更有结构的编程语言。二进制指令被称为机器语言,在此之后人们发明了汇编语言,但是汇编语言仍然比较繁琐,达不到偷懒的目的,在汇编语言之上又开发了高级语言,C语言就是其中一种最成功的。这样整个发展过程就非常清晰,C语言编译过程四个阶段的中间两个阶段就是在干翻译的事情而已,先将C语言源代码翻译成汇编代码,再调用汇编器,将汇编代码翻译成二进制指令。目标文件就是二进制指令的集合,是能直接被CPU所理解的。但是目标文件是不完整的,可以理解为瑕疵品,最后还需要链接器画龙点睛。
又有人会疑问了,C语言不能直接翻译成机器语言二进制指令吗?为什么非得经过汇编语言转接一次呢?这当然是为了站在巨人的肩膀上摘苹果啦,机器语言的编写是非常困难的,而且也非常难理解,借助汇编语言的难度则小得多,能有更简单更好的方式为什么不用呢。
什么是链接
当C语言源码经过汇编后,生成的便是目标文件,通常在Linux上是后缀名为.o的文件,微软的VC编译器生成的是后缀名为.obj的文件,但MinGW生成的目标文件也是.o文件。目标文件实际上已经是二进制文件了,它与可执行文件的区别仅仅是没有经过链接而已。
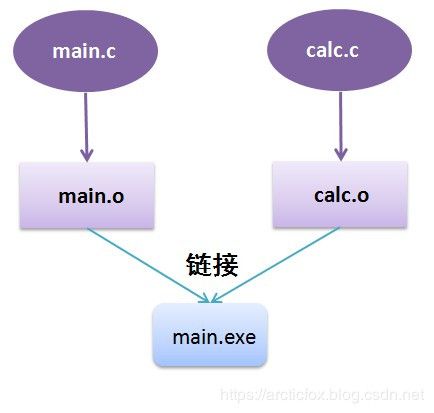
链接过程的本质就是把多个不同的目标文件合并到一起。为了使不同目标文件之间能够相互拼合, 这些目标文件之间必须有固定的规则。
在链接中, 目标文件之间相互拼合实际上是目标文件之间对地址的引用, 即对函数和变量的地址的引用。 比如目标文件main.o用到了目标文件calc.o中的函数add, 那么我们就称目标文件calc.o定义了函数add, 称目标文件main.o引用了目标文件calc.o中的函数add。 这两个概念也同样适用于变量。 每个函数或变量都有自己独特的名字, 才能避免链接过程中不同变量和函数之间的混淆。 在链接中, 我们将函数和变量统称为符号(Symbol) , 函数名或变量名就是符号名(Symbol Name) 。
将符号看作是链接中的粘合剂, 整个链接过程正是基于符号完成的。 链接过程中关键的一部分就是对符号的管理, 每一个目标文件都会有一个相应的符号表(Symbol Table),这个表里面记录了目标文件中用到的所有符号。 每个定义的符号有一个对应的值, 叫做符号值(Symbol Value) , 对于变量和函数来说, 符号值就是它们的地址。
简单理解,符号在汇编中代表一个地址,经汇编器处理之后,所有的符号都会被替换成它所代表的地址值。在C语言中我们通过变量名访问一个变量,其实就是读写某个地址的内存空间,通过函数名调用一个函数,其实就是跳转到该函数第一条指令所在的地址,所以变量名和函数名都是符号,本质上就是代表内存地址。
查看符号表
说了这么多,赶紧动手来验证一下理论。我们可以使用GNU GCC提供的工具链来验证,主要可以使用nm命令来查看目标文件的符号表,除此外还可以使用objdump命令来查看符号表
分别查看两个目标文件的命令:nm calc.o、nm main.o,然后nm main.exe查看可执行文件,可以很显著的发现main.exe的符号表就是将nm calc.o、nm main.o两个文件的合并起来的。
使用objdump命令也可以查看
objdump -t calc.o、objdump -t main.o
*拓展:nm命令查看符号类型
以下为常见符号类型,非全部。
| 符号类型 | 含义 |
|---|---|
| B、b | 表示符号位于未初始化数据段(bss)中。例如,在一个文件中定义的静态全局变量static int num |
| D | 表示已初始化的全局数据。 |
| N | 表示一个调试符号 |
| R | 表示符号位于只读数据区。通常表示常量。例如:const int LEN = 10 |
| T | 表示符号位于代码区。通常是指源码中的函数 |
| U | 表示该符号在当前文件中是未定义的,即该符号定义在别的源文件中。例如调用其他源文件中的函数。 |
| W | 表示该符号为弱符号。如果其他目标文件中也定义了这个符号,则其他目标文件中的符号可以覆盖该符号,否则使用该弱符号 |
静态链接
链接主要有两方面工作
- 符号解析。符号解析的目的是将符号引用和符号定义关联起来。正如上面的例子所示。
- 地址重定位。如果我们上面查看了目标文件的符号表,可能会注意到,生成的目标文件中的符号地址是0,这显然是一个无效的地址,链接器需要做的,正是在合并生成的可执行文件中对这些原目标文件的符号的地址进行修改,分配一个真实有效的地址。
关于第二点,使用nm查看符号表
calc.o 如下,add函数符号地址为0
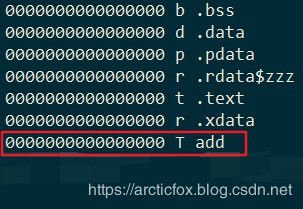
main.o如下,start符号地址也为0,这里main.o引用了另一个目标文件中定义的符号add,关于符号类型详见上表。
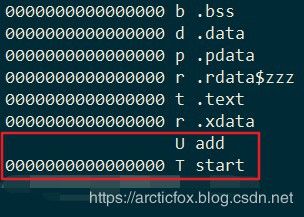
由上可知,仅编译后生成的二进制目标文件,其符号表中的相关符号地址都是用0代替的,是无效地址。
我们再查看main.exe可执行文件的符号表
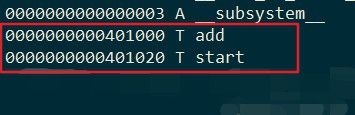
可以清晰的看出来,链接之后生成的可执行文件,其符号的地址被修改成了一个有效值,这就是所谓的重定位。
根据本篇介绍的关于操作系统的虚拟内存知识,我们知道操作系统的虚拟内存会给每个程序映射一个完整的地址空间,简单说就是每个程序进程都可以拥有相同的内存地址,这样就不会发生地址冲突。
总结:
如上面的示例这样,将多个目标文件的内容拷贝合并到一个可执行文件的链接方式,被称为静态链接。静态链接是最直观,最简单易懂的链接方式,除此外,还有一种被称为动态链接的链接方式。通常的动态链接更灵活更常用,但是动态链接的性能稍微低于静态链接。关于动态链接的详细内容,在后面的动态库小结中叙述。
函数库
所谓库也就是我们经常说的C语言函数库。那到底什么是库呢?库这个词,通常指库房,库存,显然库应该是一种存放东西的容器。想通这一点,我们会疑问,函数库到底存放的是什么东西呢,存放的是函数吗?
实际上C语言的库并不是什么很难理解的概念,它其实就是一个文件包。文件包是我们经常打交道的东西,比如zip包、rar包、7z包等压缩包,而函数库就是一个目标文件(.o或.obj)的文件包。
函数库又根据链接方式的不同,分为静态库和动态库。
静态库
首先来模拟一下静态库的使用情境。代码如下
main.c
#include add.c
// 整数加法函数
int int_add(int a,int b){
return a + b;
}
sub.c
// 整数减法函数
int int_sub(int a,int b){
return a - b;
}
使用gcc命令编译生成目标文件。同一行执行多条命令,使用&符分隔命令
gcc -c main.c -o main.o & gcc -c add.c -o add.o & gcc -c sub.c -o sub.o
使用gcc将生成的三个目标文件静态链接起来生成main.exe可执行程序
gcc main.o add.o sub.o -o main
在命令行执行main.exe正常。但是我们发现一个问题,那就是链接起来非常麻烦,以上仅三个目标文件,如果我们编写的函数非常多,分很多个模块,假设有几十个目标文件,那链接起来就酸爽了,而且这么多的目标文件,非常零散,又不便管理,这时候我们就可以给它打个包。
打包静态库
ar rs libcalc.a add.o sub.o
命令简析:
ar命令用来打包;其中rs分别代表两个参数,r表示为后面的目标文件创建文件包,s专用于生成静态库,表示为静态库创建索引。libcalc.a是静态库的全文件名称,其中库文件名须以lib作为前缀,calc作为库名,通常地,在Linux系统上,静态库以.a作为文件后缀,Windows系统则以.lib作为文件后缀,但是这里开发环境是MinGW,在Windows上仍以.a做静态库文件后缀。
链接静态库
重新链接静态库,并生成可执行文件main2.exe
gcc main.o -L. -lcalc -o main2
命令简析:
-L参数表示设置链接的库的路径,这里.表示当前路径下,使用的是相对路径,-L后面可以跟绝对路径,注意参数与路径之间是没有空格的;这里-l参数是小写,后面跟的是库名称,注意这里是库名称不是库的文件名,不能带有lib前缀,也不能带有文件后缀。
命令行运行main2.exe,打印结果
add = 16
sub = 8
现在我们有了自己的静态库,可以直接对源码进行编译链接 gcc main.c -L. -lcalc -o main2
C语言的一大特点就是代码逆向的难度非常高,如果我们编写了一个函数库,但又不想让别人看到源码,那么我们就可以将写好的代码编译成一个个目标文件,然后将这些目标文件打成一个包发布出去给别人使用。目标文件基本上是不能还原成源代码的,源代码编译成二进制目标文件的过程是不可逆的。
动态库
动态库又被称为共享库,由于静态库存在很大的弊端,动态库的出现正是为了解决静态库的缺陷。首先让我们来模拟一种情境
新建 div.c
// 整数除法函数
int int_div(int a,int b){
return a / b;
}
生成div.o,并结合上面的静态库示例,将add.o、sub.o、div.o打包成新的静态库libcalc.a
ar rs libcalc.a add.o sub.o div.o
现在静态库增加了除法函数,假设我们需要开发一个专门计算器除法的应用,编写如下代码
app1.c
#include 编译程序:gcc app1.c -L. -lcalc -o app1
执行程序后,命令行等待我们输入两个数,以逗号间隔,这里我们输入10,2
***** Division calculation ******
10,2
*********************************
10/2 = 5
程序编写OK了,我们可以把app1.exe发布出去,给用户安装使用。直到有一天,有用户反馈说,当输入的除数为0时,如输入10,0,程序崩溃了,如下
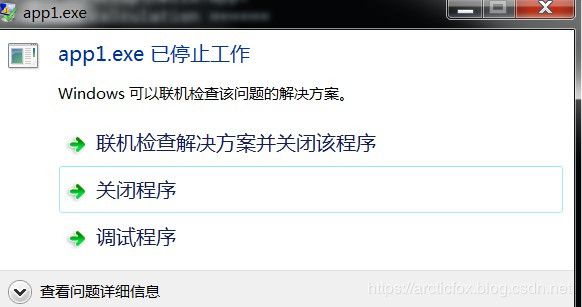
我们检查代码后发现,这是除数为0导致的,算术运算时,除数为0会造成程序异常退出。静态库中的除法函数中没有做除数的非零判断。于是我们赶紧修改除法函数,让代码更严谨。
div.c
// 整数除法函数
int int_div(int a,int b){
if (b == 0){
return 0;
}
return a / b; //除数不等于0时,我们才去计算
}
重新打包生成静态库,并且对外发布libcalc.a的2.0版本,告知所有使用我们静态库的人,我们修复了一个BUG,请大家更新使用2.0版本的libcalc.a,与此同时,我们自己开发的app1.exe应用也需要重新编译,它需要依赖一个新版本的静态库。
重新编译除法计算器程序,并命名为app2
gcc app1.c -L. -lcalc -o app2
验证程序,发现当除数为0时,程序不会再崩溃了
***** Division calculation ******
10,0
*********************************
10/0 = 0
程序虽然修改好了,但是我们不可避免的产生了一个新问题,我们需要重新发布app2.exe,并告知所有正在使用该应用程序的用户,他们必须重新去网站下载新的程序,并重新安装一次。这样,以后每一次修改了新的问题时,我们都必须重复以上步骤,这种用户体验是非常差劲的,相信几次之后,用户就会抛弃你。
市场上的主流应用程序,并不会使用这种开发方式,包括我们使用的QQ之类的,他们修复了问题,并不需要用户去重新下载,重新安装。应用程序可以在不知不觉的情况下自动更新,这种技术被称为热更新或热修复,其实质就是我们这一节要介绍的动态库。
生成与位置无关的目标文件
使用一下代码,生成与位置无关的目标文件add.o、sub.o、div.o
gcc -fPIC -c add.c sub.c div.c
-f后面跟PIC表示生成位置无关代码(Position Independent Code)
打包动态库
gcc -shared add.o sub.o div.o -o libcalc.dll
-shared表示生成共享库,即动态库。关于库的命名与静态库相似,lib为前缀,calc为库名称,Windows系统上的动态库通常为.dll文件后缀名(Dynamical Linking Library),在Linux上通常为.so后缀名(DSO, Dynamic
Shared Objects)。
另外,我们也可以只使用一条命令直接将源码编译为动态库
gcc -shared -fPIC add.c sub.c div.c -o libcalc.dll
关联动态库
请首先删除之前生成的.a静态库,防止干扰。
关联动态库生成app3.exe可执行文件,此处命令有三种写法,
1). 直接关联
gcc app1.c libcalc.dll -o app3
2). gcc参数指定库路径
gcc app1.c -L. -lcalc -o app3
该命令用法与链接静态库时相同,-L参数指定库路径,-l指定库名称
3). 设置环境变量LD_LIBRARY_PATH
以下设置临时环境变量,关闭命令行时失效,也可以配置为全局环境变量。
# Windows设置临时环境变量方式
set LD_LIBRARY_PATH="动态库的绝对路径"
# Linux设置临时环境变量
export LD_LIBRARY_PATH="动态库的绝对路径"
需注意,该环境变量是Linux系统下的,经测试MinGW在Windows上设置无效
验证
确保app2.exe和libcalc.dll在同一文件夹下,可正常运行app2.exe程序,当我们删除libcalc.dll后,程序无法正常执行。
到这里,就可以将我们的app2.exe、libcalc.dll一起发布出去给用户使用了。当我们修复了函数库的BUG后,无需重新编译并发布app2.exe,只需编译一个新版本的libcalc.dll,然后将用户安装目录下的旧dll文件替换掉就行了,这个过程可以通过一个网络程序从服务器下载,自动完成替换,这就是所谓的热更新。
通常一个应用程序会有很多动态库,升级或修复程序,只需要替换某个相应的动态库即可,这样大大提升了软件升级的体验。
动态库与静态库的区别
实质上就是动态链接与静态链接的区别
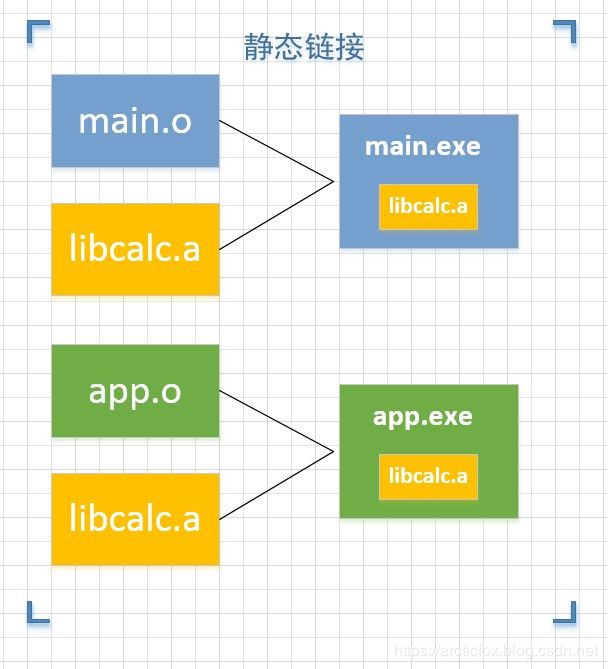
静态链接的程序体积大,如果多个程序使用相同的静态库,那么每个程序都会包含相同的部分。无论是对于磁盘还是内存,这都是一种空间的浪费。而且如果库本身的代码修改了,所有使用该库的程序整个都必须重新编译和发布。
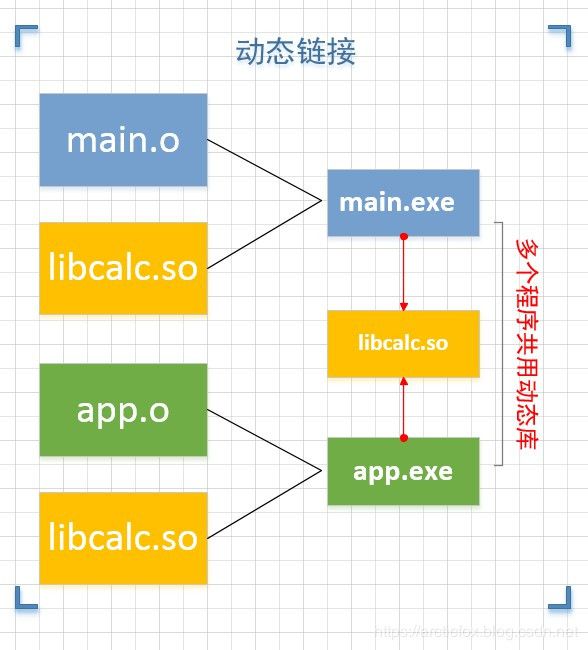
使用动态链接技术的动态库又被称为共享库,共享一词阐明了它本身的特点。使用动态库的程序,没有将所依赖的库拷贝到最终的可执行程序中,这样既减小了程序的大小,又节省了加载到内存的空间,而且也更灵活,多个程序可以共享同一份动态库。库发生修改时,只需更新对应的动态库即可,而不用整个都重新编译发布。
动态链接
动态链接要比静态链接复杂得多,而且概念极易混淆,需要单独进行说明。
我们这里所说的动态链接和前文所谓的链接实际上是两回事,前面我们谈的链接,是指编译时链接,也就是编译过程中第四个阶段所谓的链接,经过链接后生成可执行程序。事实上,编译时链接都是静态链接。
动态链接并不能在编译时进行,它只能在加载时进行。因此,当我们编写好代码,并依赖动态库生成可执行文件时,说的是关联动态库,而不是链接动态库。动态链接工作是由一个叫动态链接器的东西完成的, 不是由gcc编译时调用ld完成的。
动态链接的基本思想是把程序按照模块拆分成各个相对独立的部分, 在程序运行时才将它们链接在一起形成一个完整的程序, 而不是像静态链接一样把所有的程序模块都链接成一个单独的可执行文件。
动态链接涉及运行时的链接及多个文件的装载, 因此必需要有操作系统的支持。 目前主流的操作系统也几乎都支持动态链接这种方式。这从另一个角度告诉我们,不同的操作系统中,动态链接的实现方式和实现原理是不同的,虽然原理有所不同,但是在使用上,大体还是相差不多。关于动态链接,本文主要介绍的是Linux系统中的实现原理,这是因为类Linux的动态链接具有广泛的通用性,从Linux系统到MacOS系统,都具有适用性,适用场景包括嵌入式开发、Android开发、IOS开发、MacOS开发、Linux开发等,唯独Windows的DLL实现原理是完全不同的,仅在Windows端适用。
我们以前面的例子具体说明动态链接过程。
当链接器ld将app1.o链接成可执行文件时, 这时链接器必须确定app1.o中所引用的int_div函数的性质。 如果int_div函数是一个定义在其他静态目标模块中的函数, 那么链接器将会按照静态链接的规则, 将app1.o中的int_div地址重定位; 如果int_div是一个定义在某个动态共享库中的函数, 那么链接器就会将这个符号的引用标记为一个动态链接的符号, 不对它进行地址重定位,而是把实际的动态链接过程留到加载时再进行。
那么问题来了, 链接器如何知道int_div的引用是一个静态符号还是一个动态符号呢?
这实际上就是我们要在编译时关联libcalc.dll的原因。动态库中保存了完整的符号信息, 链接器在解析符号时就可以知道int_div是一个定义在动态库中的动态符号。 这样链接器就可以对int_div的引用做特殊的处理, 使它成为一个对动态符号的引用。
位置无关代码
前面我们编译动态库时,添加-fPIC参数,生成位置无关代码,那么什么是位置无关代码呢?
如果我们不加这个参数,不生成与位置无关的代码,那么动态库中被引用的符号地址只能被固定写死。这就跟静态库链接时的重定位一样,只是这个过程被推迟到加载时而已。例如int_div在编译时地址是0,当动态库被加载时动态链接器给他分配的地址是0x100010,这时候动态链接就需要修改动态库指令,对int_div符号进行地址重定位。
然而动态库的指令部分是需要在多个进程之间共享的, 由于加载时重定位的方法需要修改指令, 所以没有办法做到同一份指令被多个进程共享, 因为指令被重定位后对于每个进程来讲是不同的。
试想这样一种情况,如果电脑上有A、B两个程序,他们都使用了同一个动态库,那么同时启动这两个程序会怎么样呢?显然,我们的系统有虚拟内存机制,这两个程序不会存在内存重叠或冲突的情况,也就是说,动态库仍然会被加载两遍,这样动态库在内存中就存在两份,没能实现多个程序链接同一个动态库时,只在内存中存在一份的目标,因此每个进程操作的只是自己的那个副本。
要实现多个程序在内存中共用同一动态库的目标,我们需要一种与位置无关的机制。也就是说,动态库可以被加载到内存的任意地址,而不是指定一个固定地址。
GCC对目标文件的做法是在数据段里面建立一个指向这些符号的指针数组, 也被称为全局偏移表—— GOT( Global Offset Table)。当模块需要调用目标函数时, 可以通过GOT中的项进行间接跳转,因为符号的地址是相对的偏移量,而不是一个绝对地址。
如果两个进程同时操作动态库中的全局变量,会造成冲突吗?
当一个动态库被两个进程加载时, 它的数据段部分会在每个进程中都有独立的副本, 任何一个进程访问的只是自己的那个副本,因此两个进程同时修改动态库中的全局变量时,并不会相互干扰。因为动态库共享的是代码段,而不是数据段。
总结
-
静态库
- 生成的可执行文件体积大
- 任何修改都需要重新编译发布,不便于更新和维护
- 整个应用只由一个可执行文件构成
- 符号使用绝对地址,性能略高与动态库
-
动态库
- 生成的可执行文件体积小
- 可以热更新,修改和维护方便
- 通常一个完整的应用程序由一个可执行文件和多个动态库文件组成
- 动态库的调用需要跳转,相比静态库而言性能略低,且不能脱离共享库文件
动态库的运行时加载
动态库除了以上的使用方式,还有一种更灵活的用法,那就是运行时加载。以上我们都是在编译时关联动态库的,有时候可能有更灵活的需求,我们想让程序在运行的时候,根据输入的条件,自由切换相关的动态库。有了这种技术,可以让C语言实现强大的框架功能,整个程序都不用停止,在程序正在运行的时候给它增加或切换新功能。
由于运行时加载动态库在Windows系统和Linux系统上的实现不同,因此需要调用不同的函数完成,以下我们编写一份跨平台代码,同时将两种平台的使用方式列出
新建app2.c
#include 使用gcc编译时,必须定义一个宏,确定当前是哪个系统平台
gcc app2.c -o app3 -DPLATFORM_WIN32
这里-D参数用于在gcc命令行中定义宏,它后面紧跟宏名称PLATFORM_WIN32
以上我们实现了一个跨平台的代码,可以同时在Windows下和Linux下进行编译,根据宏参数,实现条件编译。参考代码可以发现,虽然Windows平台和Linux平台在运行时加载动态库的函数不同,但是基本使用步骤是相同的
- 加载动态库,需传入一个动态库的文件路径
- 查询待调用函数的内存地址,返回的是一个函数指针
- 通过函数指针调用函数
- 释放引用
【参考资料】
1.《程序员的自我修养——链接、 装载与库》
2.《深入理解计算机系统(原书第3版)》
3.《链接器和加载器》
欢迎关注我的公众号:编程之路从0到1
