Java基础2面向对象和数组
第四章 Java面向对象基础
4.1 面向过程和面向对象
面向过程(Procedure Oriented)和面向对象(Object Oriented,OO)都是对软件分析、设计和开发的一种思想,它指导着人们以不同的方式去分析、设计和开发软件。早期先有面向过程思想,随着软件规模的扩大,问题复杂性的提高,面向过程的弊端越来越明显的显示出来,出现了面向对象思想并成为目前主流的方式。两者都贯穿于软件分析、设计和开发各个阶段,对应面向对象就分别称为面向对象分析(OOA)、面向对象设计(OOD)和面向对象编程(OOP)。C语言是一种典型的面向过程语言,Java是一种典型的面向对象语言。
面向过程思想思考问题时,我们首先思考“怎么按步骤实现?”并将步骤对应成方法,一步一步,最终完成。 这个适合简单任务,不需要过多协作的情况下。比如,如何开车?我们很容易就列出实现步骤:
1.发动车 2.挂挡 3.踩油门 4. 走你
面向过程适合简单、不需要协作的事务。 但是当我们思考比较复杂的问题,比如“如何造车?”,就会发现列出1234这样的步骤,是不可能的。那是因为,造车太复杂,需要很多协作才能完成。此时面向对象思想就应运而生了。
面向对象(Object)思想更契合人的思维模式。我们首先思考的是“怎么设计这个事物?” 比如思考造车,我们就会先思考“车怎么设计?”,而不是“怎么按步骤造车的问题”。这就是思维方式的转变。
一、面向对象思想思考造车,发现车由如下对象组成:
1.轮胎2. 发动机3. 车壳4. 座椅5. 挡风玻璃
为了便于协作,我们找轮胎厂完成制造轮胎的步骤,发动机厂完成制造发动机的步骤;这样,发现大家可以同时进行车的制造,最终进行组装,大大提高了效率。但是,具体到轮胎厂的一个流水线操作,仍然是有步骤的,还是离不开面向过程思想!
因此,面向对象可以帮助我们从宏观上把握、从整体上分析整个系统。 但是,具体到实现部分的微观操作(就是一个个方法),仍然需要面向过程的思路去处理。
我们千万不要把面向过程和面向对象对立起来。他们是相辅相成的。面向对象离不开面向过程!
面向对象和面向过程的总结
1、都是解决问题的思维方式,都是代码组织的方式。
2、解决简单问题可以使用面向过程
3、解决复杂问题:宏观上使用面向对象把握,微观处理上仍然是面向过程。
面向对象思考方式
遇到复杂问题,先从问题中找名词,然后确立这些名词哪些可以作为类,再根据问题需求确定的类的属性和方法,确定类之间的关系。
建议
1.面向对象具有三大特征:封装性、继承性和多态性,而面向过程没有继承性和多态性,并且面向过程的封装只是封装功能,而面向对象可以封装数据和功能。所以面向对象优势更明显。
2.一个经典的比喻:面向对象是盖浇饭、面向过程是蛋炒饭。盖浇饭的好处就是“菜”“饭”分离,从而提高了制作盖浇饭的灵活性。饭不满意就换饭,菜不满意换菜。用软件工程的专业术语就是“可维护性”比较好,“饭” 和“菜”的耦合度比较低。
4.2 对象的进化史(数据管理和企业管理共通之处)
事物的发展总是遵循“量变引起质变”的哲学原则;企业管理和数据管理、甚至社会管理也有很多共通的地方。本节课类比企业发展,让大家更容易理解为什么会产生“对象”这个概念。
·数据无管理时代
最初的计算机语言只有基本变量(类似我们学习的基本数据类型),用来保存数据。那时候面对的数据非常简单,只需要几个变量即可搞定;这个时候不涉及“数据管理”的问题。同理,就像在企业最初发展阶段只有几个人,不涉及管理问题,大家闷头做事就OK了。
·数组管理和企业部门制
企业发展中,员工多了怎么办?我们很自然的想法就是归类,将类型一致的人放到一起;企业中,会将都做销售工作的放到销售部管理;会将研发软件的放到开发部管理。同理在编程中,变量多了,我们很容易的想法就是“将同类型数据放到一起”, 于是就形成了“数组”的概念,单词对应“array”。 这种“归类”的思想,便于管理数据、管理人。
·对象和企业项目制
企业继续发展,面对的场景更加复杂。一个项目可能需要经常协同多个部门才能完成工作;一个项目从谈判接触可能需要销售部介入;谈判完成后,需求调研开始,研发部和销售部一起介入;开发阶段需要开发部和测试部互相配合敏捷开发,同时整个过程财务部也需要跟进。在企业中,为了便于协作和管理,很自然就兴起了“项目制”,以项目组的形式组织,一个项目组可能包含各种类型的人员。 一个完整的项目组,麻雀虽小五脏俱全,就是个创业公司甚至小型公司的编制,包含行政后勤人员、财务核算人员、开发人员、售前人员、售后人员、测试人员、设计人员等等。事实上,华为、腾讯、阿里巴巴等大型公司内部都是采用这种“项目制”的方式进行管理。
同理,计算机编程继续发展,各种类型的变量更加多了,而且对数据的操作(指的就是方法,方法可以看做是对数据操作的管理)也复杂了,怎么办?
为了便于协作和管理,我们“将相关数据和相关方法封装到一个独立的实体”,于是“对象”产生了。 比如,我们的一个学生对象:
有属性(静态特征):年龄:18,姓名:高淇,学号:1234
也可以有方法(动态行为):学习,吃饭,考试
请大家举一反三,根据上表理解一下企业的进化史,会发现大道至简。原来,数据管理、企业管理、社会发展也是有很多共通的地方。“量变引起质变,不同的数量级必然采用不同的管理模式”。

总结
1.对象说白了也是一种数据结构(对数据的管理模式),将数据和数据的行为放到了一起。
2.在内存上,对象就是一个内存块,存放了相关的数据集合!
3.对象的本质就一种数据的组织方式!
4.3 对象和类的概念
我们人认识世界,其实就是面向对象的(此对象可不是男女谈对象的彼对象呀)。比如现在让大家认识一下“天使”这个新事物,天使大家没见过吧,怎么样认识呢?最好的办法就是,给你们面前摆4个天使,带翅膀的美女,让大家看,看完以后,即使我不说,大家下一次是不是就都认识天使了。
但是,看完10个天使后,我们总要总结一下,什么样的东东才算天使?天使是无数的,总有没见过的!所以必须总结抽象,便于认识未知事物!总结的过程就是抽象的过程。小时候,我们学自然数时怎么定义的?像1,2,3,4…这样的数就叫做自然数。 通过抽象,我们发现天使有这样一下特征:
1.带翅膀(带翅膀不一定是天使,还可能是鸟人)
2.女孩(天使掉下来脸着地,也是天使!)
3.善良
4. 头上有光环
那么通过这4个具体的天使,我们进行抽象,抽象出了天使的特征,我们也可以归纳一个天使类。 通过这个过程,类就是对象的抽象。
类可以看做是一个模版,或者图纸,系统根据类的定义来造出对象。我们要造一个汽车,怎么样造?类就是这个图纸,规定了汽车的详细信息,然后根据图纸将汽车造出来。
类:我们叫做class。 对象:我们叫做Object,instance(实例)。以后我们说某个类的对象,某个类的实例。是一样的意思。
总结
1.对象是具体的事物;类是对对象的抽象;
2.类可以看成一类对象的模板,对象可以看成该类的一个具体实例。
3.类是用于描述同一类型的对象的一个抽象概念,类中定义了这一类对象所应具有的共同的属性、方法。
4.3.1 第一个类的定义
【示例4-1】类的定义方式
// 每一个源文件必须有且只有一个public class,并且类名和文件名保持一致!
public class Car {
}
class Tyre { // 一个Java文件可以同时定义多个class
}
class Engine {
}
class Seat {
}
上面的类定义好后,没有任何的其他信息,就跟我们拿到一张张图纸,但是纸上没有任何信息,这是一个空类,没有任何实际意义。所以,我们需要定义类的具体信息。对于一个类来说,一般有三种常见的成员:属性field、方法method、构造器constructor。这三种成员都可以定义零个或多个。
【示例4-2】简单的学生类编写
public class SxtStu {
//属性(成员变量)
int id;
String sname;
int age;
//方法
void study(){
System.out.println("我正在学习!");
}
//构造方法
SxtStu(){
}
}
4.3.2 属性(field,或者叫成员变量)
属性用于定义该类或该类对象包含的数据或者说静态特征。属性作用范围是整个类体。
在定义成员变量时可以对其初始化,如果不对其初始化,Java使用默认的值对其初始化。

属性定义格式:
[修饰符] 属性类型 属性名 = [默认值] ;
4.3.3 方法
方法用于定义该类或该类实例的行为特征和功能实现。方法是类和对象行为特征的抽象。方法很类似于面向过程中的函数。面向过程中,函数是最基本单位,整个程序由一个个函数调用组成。面向对象中,整个程序的基本单位是类,方法是从属于类和对象的。
方法定义格式:
[修饰符] 方法返回值类型 方法名(形参列表) {
// n条语句
}
4.3.4 一个典型类的定义和UML图
【示例4-3】模拟学生使用电脑学习
//一个.java文件可以写多个类,但只能写一个public类
class Computer {
String brand; //品牌
}
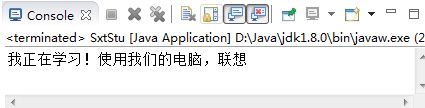
public class SxtStu {
// field
int id;
String sname;
int age;
Computer comp;//类和类之间是可以互相引用的、嵌套的
//方法
void study() {
System.out.println("我正在学习!使用我们的电脑,"+comp.brand);
}
void play(){
System.out.println("我在玩游戏!王者农药!");
}
//构造方法。用于创建这个类的对象。无参的构造方法可以由系统自动创建
SxtStu() {
}
public static void main(String[] args) {
SxtStu stu1 = new SxtStu();
stu1.sname = "张三";
Computer comp1 = new Computer();
comp1.brand = "联想";
stu1.comp = comp1;
stu1.study();
}
}
执行结果:

4.4 面向对象的内存分析
为了让大家对于面向对象编程有更深入的了解,我们要对程序的执行过程中,内存到底发生了什么变化进行剖析,让大家做到“心中有数”,通过更加形象方式理解程序的执行方式。
建议:
1.本节课是为了让初学者更深入了解程序底层执行情况,为了完整的体现内存分析流程,会有些新的名词,比如:线程、Class对象。大家暂时可以不求甚解的了解,后期学了这两个概念再回头来看我们这篇内存分析,肯定收获会更大。
2.学习本节,一定要结合视频学习!
Java虚拟机的内存可以分为三个区域:栈stack、堆heap、方法区method area。
栈的特点如下:
1.栈描述的是方法执行的内存模型。每个方法被调用都会创建一个栈帧(存储局部变量、操作数、方法出口等)
2.JVM为每个线程创建一个栈,用于存放该线程执行方法的信息(实际参数、局部变量等)
3.栈属于线程私有,不能实现线程间的共享!
4.栈的存储特性是“先进后出,后进先出”
5.栈是由系统自动分配,速度快!栈是一个连续的内存空间!
堆的特点如下:
1.堆用于存储创建好的对象和数组(数组也是对象)
2.JVM只有一个堆,被所有线程共享
3.堆是一个不连续的内存空间,分配灵活,速度慢!
方法区(又叫静态区)特点如下:
1.JVM只有一个方法区,被所有线程共享!
2.方法区实际也是堆,只是用于存储类、常量相关的信息!
3.用来存放程序中永远是不变或唯一的内容。(类信息【Class对象】、静态变量、字符串常量等)
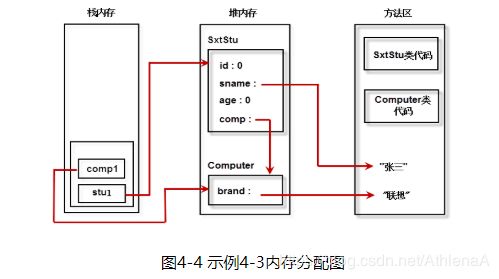

java命令启动程序,把代码加载到空间里。
1首先方法区有了我们类的信息,SxtStu 类相关信息:1代码2静态变量3静态方法4字符串常量:“我正在学习!使用我们的电脑,” “我在玩游戏!王者农药!” “张三” “联想”。
2然后找main函数,调用main方法时在栈中开辟一个main方法栈帧。首先定义了一个stu1局部变量,styu1=null。
3然后new SxtStu();调new的时候就需要建一个对象,调SxtStu()的时候就去调用了类的构造方法SxtStu(),又开辟了一个新的栈帧,开辟完以后,就开始执行这个方法去创建一个这个类的实例对。
4因为内存的方法区中已经有这个类的信息,所以我们在堆里建出一个对象了,这个对象有属性有方法,
id 0
sname null
age 0
comp null
study()
play()
5建好的每个对象都有一个地址,这个内存块都有一个地址,在堆里面有很多个这样的内存块,地址一般是一个数字表示。例:![]() 这串数字就是地址。
这串数字就是地址。
SxtStu stu1 = new SxtStu();这样就把这个值赋值给了stu1对象
stu1 = 15db9742,一个简单的赋值就把它们俩给关联起来了。
所以,当我写个stu1时,它就明白我指的是这个15db9742的地方。
6stu1.sname = “张三”;找到15db9742,
id 0
sname “张三“ 去方法区中找到字符串,把字符串的地址告诉属性sname
age 0
comp null
study()
play()
7Computer comp1
新建局部变量comp1 ,也在main方法中建一个局部变量comp1=null。
8= new Computer();
调用Computer()构造器,开辟一个新的栈帧,然后就会在堆中创建新的对象
brand null
9堆中的对象一样有个地址15db9753,把地址给了comp1,把它们俩关联起来了。
10comp1.brand = “联想”;把字符串常量对象给了brand属性
brand 联想
11stu1.comp = comp1;
comp 15db9753
12stu1.study();
4.5 构造方法
构造器也叫构造方法(constructor),用于对象的初始化。构造器是一个创建对象时被自动调用的特殊方法,目的是对象的初始化。构造器的名称应与类的名称一致。Java通过new关键字来调用构造器,从而返回该类的实例,是一种特殊的方法。
声明格式:
[修饰符] 类名(形参列表){
//n条语句
}
要点:
1.通过new关键字调用!!
2.构造器虽然有返回值,但是不能定义返回值类型(返回值的类型肯定是本类),不能在构造器里使用return返回某个值。
3.如果我们没有定义构造器,则编译器会自动定义一个无参的构造函数。如果已定义则编译器不会自动添加!
4.构造器的方法名必须和类名一致!
课堂练习:
1.定义一个“点”(Point)类用来表示二维空间中的点(有两个坐标)。要求如下:
(1) 可以生成具有特定坐标的点对象。
(2)提供可以设置坐标的方法。
(3)提供可以计算该“点”距另外一点距离的方法。
参考答案:
class Point {
double x, y;
//(1) 可以生成具有特定坐标的点对象。
//这是一个构造方法,通过构造器把点构造出来了
//若你已经定义了构造方法,则类不会自动帮你添加无参的构造方法了,若你还想要无参的构造方法呢,你就需要自己创建
public Point(double _x, double _y) {//这里括号里也可以用x,如果用x就可以用this来区别
x = _x;
y = _y;
}
//(3)提供可以计算该“点”距另外一点距离的方法。
public double getDistance(Point p) {
return Math.sqrt((x - p.x) * (x - p.x) + (y - p.y) * (y - p.y));
}
}
public class TestConstructor {
public static void main(String[] args) {
Point p = new Point(3.0, 4.0);//创建第一个点,把3.0传给了_x,把4.0传给了_y,传给了对象中的属性。
Point origin = new Point(0.0, 0.0);
System.out.println(p.getDistance(origin));
}
}
作业:
1.很多零基础同学会在这个地方开始晕菜。大家都学过内存分析,将这个程序的执行过程的内存分析画出来。如果画不出,好好再温习一下内存分析那一节课
4.6 构造方法的重载
构造方法也是方法,只不过有特殊的作用而已。与普通方法一样,构造方法也可以重载。
构造方法经常需要重载,因为我们经常需要对对象采用不同的创建方式。
【示例4-6】构造方法重载(创建不同用户对象)
public class User {
int id; // id
String name; // 账户名
String pwd; // 密码
public User() {
}
//根据号码和姓名创建对象
public User(int id, String name) {
super();//构造方法的第一句总是super(),你删了编译器会帮你自动调用super()
this.id = id;//在方法内部,你直接写个id的时候,用就近原则,即什么都不写直接写id时,指的就是局部变量id。而不是我的成员变量的id。
this.name = name;//this表示创建好的对象,这里表示对象的成员变量,即属性
}
//根据号码姓名密码创建对象
public User(int id, String name, String pwd) {
this.id = id;
this.name = name;
this.pwd = pwd;
}
public static void main(String[] args) {
User u1 = new User();
User u2 = new User(101, "高小七");
User u3 = new User(100, "高淇", "123456");
}
}
雷区:
如果方法构造中形参名与属性名相同时,需要使用this关键字区分属性与形参。如示例4-6所示:
this.id 表示属性id;id表示形参id
4.7 垃圾回收机制(Garbage Collection)
Java引入了垃圾回收机制,令C++程序员最头疼的内存管理问题迎刃而解。Java程序员可以将更多的精力放到业务逻辑上而不是内存管理工作上,大大的提高了开发效率。
C++在桌子上吃完必须自己擦完桌子,下一个人才能使用。
Java在桌子上吃完可以自己不用擦,服务员擦,便于下一个人使用。
4.7.1 垃圾回收原理和算法
·内存管理
Java的内存管理很大程度指的就是对象的管理,其中包括对象空间的分配和释放。
对象空间的分配:使用new关键字创建对象即可
对象空间的释放:将对象赋值null即可。垃圾回收器将负责回收所有”不可达”对象的内存空间。
·垃圾回收过程
任何一种垃圾回收算法一般要做两件基本事情:
1.发现无用的对象,怎么发现他是个关键问题
2.回收无用对象占用的内存空间。
垃圾回收机制保证可以将“无用的对象”进行回收。无用的对象指的就是没有任何变量引用该对象。Java的垃圾回收器通过相关算法发现无用对象,并进行清除和整理。
·垃圾回收相关算法
1.引用计数法
堆中每个对象都有一个引用计数。
被引用一次,计数加1.
被引用变量值变为null,则计数减1,直到计数为0,则表示变成无用对象。
优点是算法简单,缺点是“循环引用的无用对象”无法别识别。
【示例4-7】循环引用示例
public class Student {
String name;
Student friend;
public static void main(String[] args) {
Student s1 = new Student();
Student s2 = new Student();
s1.friend = s2;
s2.friend = s1;
s1 = null;
s2 = null;
}
}
s1和s2互相引用对方,导致他们引用计数不为0,但是实际已经无用,但无法被识别。
2.引用可达法(根搜索算法)
程序把所有的引用关系看作一张图,从一个节点GC ROOT开始,寻找对应的引用节点,找到这个节点以后,继续寻找这个节点的引用节点,当所有的引用节点寻找完毕之后,剩余的节点则被认为是没有被引用到的节点,即无用的节点。
4.7.2 通用的分代垃圾回收机制
分代垃圾回收机制,是基于这样一个事实:不同的对象的生命周期是不一样的。因此,不同生命周期的对象可以采取不同的回收算法,以便提高回收效率。我们将对象分为三种状态:年轻代、年老代、持久代。JVM将堆内存划分为 Eden、Survivor 和 Tenured/Old 空间。
1.年轻代
所有新生成的对象首先都是放在Eden区。 年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象,对应的是Minor GC,每次 Minor GC 会清理年轻代的内存,算法采用效率较高的复制算法,频繁的操作,但是会浪费内存空间。当“年轻代”区域存放满对象后,就将对象存放到年老代区域。
2. 年老代
在年轻代中经历了N(默认15)次垃圾回收后仍然存活的对象,就会被放到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。年老代对象越来越多,我们就需要启动Major GC和Full GC(全量回收),来一次大扫除,全面清理年轻代区域和年老代区域。
3. 持久代、用于存放静态文件,如Java类、方法等。持久代对垃圾回收没有显著影响。

·Minor GC:
用于清理年轻代区域。Eden区满了就会触发一次Minor GC。清理无用对象,将有用对象复制到“Survivor1”、“Survivor2”区中(这两个区,大小空间也相同,同一时刻Survivor1和Survivor2只有一个在用,一个为空)
·Major GC:
用于清理老年代区域。
·Full GC:
用于清理年轻代、年老代区域。 成本较高,会对系统性能产生影响。
垃圾回收过程:
1、新创建的对象,绝大多数都会存储在Eden中,
2、当Eden满了(达到一定比例)不能创建新对象,则触发垃圾回收(GC),将无用对象清理掉,
然后剩余对象复制到某个Survivor中,如S1,同时清空Eden区
3、当Eden区再次满了,会将S1中的不能清空的对象存到另外一个Survivor中,如S2,
同时将Eden区中的不能清空的对象,也复制到S1中,保证Eden和S1,均被清空。
4、重复多次(默认15次)Survivor中没有被清理的对象,则会复制到老年代Old(Tenured)区中,
5、当Old区满了,则会触发一个一次完整地垃圾回收(FullGC),之前新生代的垃圾回收称为(minorGC)
4.7.3 JVM调优和Full GC
在对JVM调优的过程中,很大一部分工作就是对于Full GC的调节。有如下原因可能导致Full GC:
1.年老代(Tenured)被写满
2.持久代(Perm)被写满
3.System.gc()被显式调用(程序建议GC启动,不是调用GC)
4.上一次GC之后Heap的各域分配策略动态变化
4.7.4 开发中容易造成内存泄露的操作
建议:
1.在实际开发中,经常会造成系统的崩溃。如下这些操作我们应该注意这些使用场景。 请大家学完相关内容后,回头过来温习下面的内容。不要求此处掌握相关细节。
如下四种情况时最容易造成内存泄露的场景,请大家开发时一定注意:
· 创建大量无用对象
比如,我们在需要大量拼接字符串时,使用了String而不是StringBuilder。
String str = "";
for (int i = 0; i < 10000; i++) {
str += i; //相当于产生了10000个String对象
}
· 静态集合类的使用
像HashMap、Vector、List等的使用最容易出现内存泄露,这些静态变量的生命周期和应用程序一致,所有的对象Object也不能被释放。
· 各种连接对象(IO流对象、数据库连接对象、网络连接对象)未关闭
IO流对象、数据库连接对象、网络连接对象等连接对象属于物理连接,和硬盘或者网络连接,不使用的时候一定要关闭。
· 监听器的使用
释放对象时,没有删除相应的监听器。
要点:
1.程序员无权调用垃圾回收器。
2.程序员可以调用System.gc(),该方法只是通知JVM,并不是运行垃圾回收器。尽量少用,会申请启动Full GC,成本高,影响系统性能。
3. finalize方法,是Java提供给程序员用来释放对象或资源的方法,但是尽量少用。
4.8 this关键字
this用于普通的方法和构造器,它用来指代当前对象
· 对象创建的过程和this的本质
构造方法是创建Java对象的重要途径,通过new关键字调用构造器时,构造器也确实返回该类的对象,但这个对象并不是完全由构造器负责创建。创建一个对象分为如下四步:
1.分配对象空间,并将对象成员变量初始化为0或空
2.执行属性值的显式初始化
3.执行构造方法(构造的时候对象已经建好了,这里构造只是进行更进一步的初始化工作,所以构造去哦器中也可以用this指代当前对象)
4.返回对象的地址给相关的变量
this的本质就是“创建好的对象的地址”! 由于在构造方法调用前,对象已经创建。因此,在构造方法中也可以使用this代表“当前对象” 。
this最常的用法:
1.在程序中产生二义性之处,应使用this来指明当前对象;
普通方法中,this总是指向调用该方法的对象。
void eat() {
this.sing(); // 调用本类中的sing();这里的this可写可不写
System.out.println(“你妈妈喊你回家吃饭!”);
}
构造方法中,this总是指向正要初始化的对象。
TestThis(int a, int b) {
// TestThis(); //这样是无法调用构造方法的!
this(); // 调用无参的构造方法,并且必须位于第一行!
a = a;// 这里都是指的局部变量而不是成员变量
// 这样就区分了成员变量和局部变量. 这种情况占了this使用情况大多数!
this.a = a;
this.b = b;
}
2.使用this关键字调用重载的构造方法,避免相同的初始化代码。但只能在构造方法中用,并且必须位于构造方法的第一句。
TestThis(int a, int b, int c) {
this(a, b); // 调用带参的构造方法,并且必须位于第一行!因为我们之前已经写过了,所以我们直接去调用,就是通过this调用
this.c = c;
}
3.this不能用于static方法中。(因为this是指代当前对象,而static是在方法区里面,是类的信息)
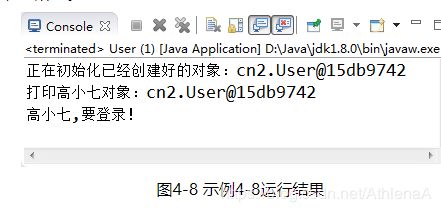
【示例4-8】this代表“当前对象”示例
public class User {
int id; //id
String name; //账户名
String pwd; //密码
public User() {
}
public User(int id, String name) {
System.out.println("正在初始化已经创建好的对象:"+this);
this.id = id; //不写this,无法区分局部变量id和成员变量id
this.name = name;
}
public void login(){
System.out.println(this.name+",要登录!"); //不写this效果一样
}
public static void main(String[] args) {
User u3 = new User(101,"高小七");
System.out.println("打印高小七对象:"+u3);
u3.login();
}
}
运行结果如图4-8所示。
【示例4-9】this()调用重载构造方法
public class TestThis {
int a, b, c;
TestThis() {
System.out.println("正要初始化一个Hello对象");
}
TestThis(int a, int b) {
// TestThis(); //这样是无法调用构造方法的!
this(); // 调用无参的构造方法,并且必须位于第一行!
a = a;// 这里都是指的局部变量而不是成员变量
// 这样就区分了成员变量和局部变量. 这种情况占了this使用情况大多数!
this.a = a;
this.b = b;
}
TestThis(int a, int b, int c) {
this(a, b); // 调用带参的构造方法,并且必须位于第一行!
this.c = c;
}
void sing() {
}
void eat() {
this.sing(); // 调用本类中的sing();
System.out.println("你妈妈喊你回家吃饭!");
}
public static void main(String[] args) {
TestThis hi = new TestThis(2, 3);
hi.eat();
}
}
4.9 static 关键字
在类中,用static声明的成员变量为静态成员变量,也称为类变量。 类变量的生命周期和类相同,在整个应用程序执行期间都有效。它有如下特点:
1.为该类的公用变量,属于类,被该类的所有实例共享,在类被载入时被显式初始化。
2.对于该类的所有对象来说,static成员变量只有一份。被该类的所有对象共享!!
3.一般用“类名.类属性/方法”来调用。(也可以通过对象引用或类名(不需要实例化)访问静态成员。)
4.在static方法中不可直接访问非static的成员。
核心要点:
static修饰的成员变量和方法,从属于类。
普通变量和方法从属于对象的。
【示例4-10】static关键字的使用
public class User2 {
int id; // id
String name; // 账户名
String pwd; // 密码
//静态成员
static String company = "北京尚学堂"; // 公司名称
public User2(int id, String name) {
this.id = id;
this.name = name;
}
public void login() {
printCompany();//普通方法中调用静态方法
System.out.println(company); //调用静态变量
System.out.println("登录:" + name);
}
//静态方法
public static void printCompany() {
// login();//调用非静态成员,编译就会报错
System.out.println(company);
}
public static void main(String[] args) {
User2 u = new User2(101, "高小七");
User2.printCompany();
User2.company = "北京阿里爷爷";
User2.printCompany();
}
}
运行结果如图4-9所示。
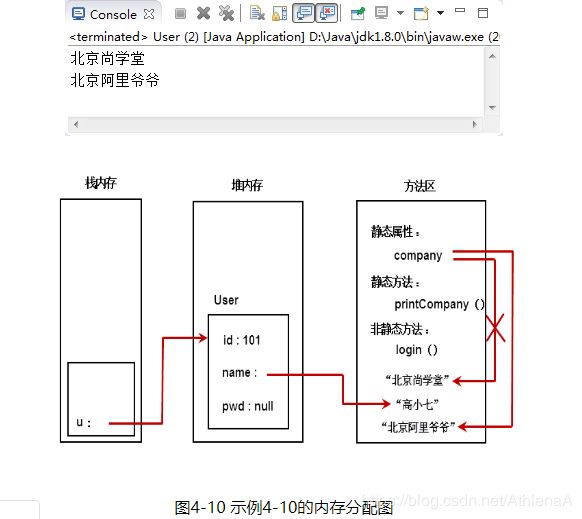
1首先把代码加载到内存中,在方法区中写上User2类的信息:
代码、
静态变量、company
静态方法、printCompany()
常量/“北京尚学堂” “登录:” “高小七” “北京阿里爷爷”
这就是加载完类后的内容
2然后栈中有一个main
3堆中,创建对象
id 1001
name 高小七
pws null
login()
4我们可以看出,堆中的name:可以指向方法区中的"高小七"
堆中的login():可以指向方法区中的静态方法
但方法区中的静态方法可以去调用堆中的普通方法吗?不能,因为我们类中的静态方法找不到堆中的对象的方法
5我们回到上一小节的this,那么this可以用于普通的对象里面,却不能用于调用静态变量和静态方法,以为这些都是类的
4.10 静态初始化块
构造方法用于对象的初始化!静态初始化块,用于类的初始化操作!
在静态初始化块中不能直接访问非static成员。
注意事项:
静态初始化块执行顺序(学完继承再看这里):
1.上溯到Object类,先执行Object的静态初始化块,再向下执行子类的静态初始化块,直到我们的类的静态初始化块为止。
2.构造方法执行顺序和上面顺序一样!!
【示例4-11】static初始化块
public class User3 {
int id; //id
String name; //账户名
String pwd; //密码
//静态变量
static String company; //公司名称
//静态块(与语句块类似)
static {//这个静态块在类初始的时候进行执行,做类的初始化
//这个静态块中不能调用非静态的变量和方法,因为这只是画图纸,还没有对象
System.out.println("执行类的初始化工作");
company = "北京尚学堂";
printCompany();
}
//静态方法
public static void printCompany(){
System.out.println(company);
}
public static void main(String[] args) {
User3 u3 = new User3();
}
}
执行结果如图4-11所示。

4.11 参数传值机制
Java中,方法中所有参数都是**“值传递”**,也就是“传递的是值的副本”。 也就是说,我们得到的是“原参数的复印件,而不是原件”。因此,复印件改变不会影响原件。
你,没有把原件传给了它,而是把复印件传递给了它,所以对复印件的改变不会影响原件。
我的文件的地址是123,复印件的地址一样的123,所以对此地址上的东西的改变都有影响。
· 基本数据类型参数的传值
传递的是值的副本。 副本改变不会影响原件。
· 引用类型参数的传值
传递的是值的副本。但是引用类型指的是“对象的地址”。因此,副本和原参数都指向了同一个“地址”,改变“副本指向地址对象的值,也意味着原参数指向对象的值也发生了改变”。
【示例4-12】 多个变量指向同一个对象
/**
* 测试参数传值机制
* @author 高淇
*
*/
public class User4 {
int id; //id
String name; //账户名
String pwd; //密码
public User4(int id, String name) {
this.id = id;
this.name = name;
}
public void testParameterTransfer01(User4 u){
u.name="高小八";
}
public void testParameterTransfer02(User4 u){
u = new User4(200,"高三");
}
public static void main(String[] args) {
User4 u1 = new User4(100, "高小七");
u1.testParameterTransfer01(u1);
System.out.println(u1.name);//从高小七变成了高小八
u1.testParameterTransfer02(u1);
System.out.println(u1.name);
}
}
执行结果如图4-12所示。
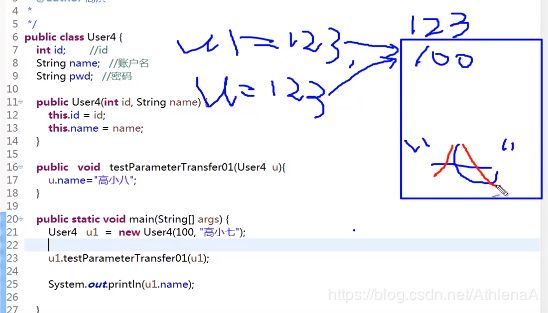
第一个输出的执行过程:
1首先堆中产生u1,
id 100
name 高小七
地址是123,即u1=123
2调用testParameterTransfer01,这样就把u1的地址123传给了u
所以现在u=123
id 100
name 高小八
java是值传递,是拷贝值的内容。
但是呢,传对象的时候,因为它们经常会指向同一个对象,多个变量的地址都是一样的,所以通过一个变量改变了这个对象的值,那么原来呢这个地方的对象的值也会被改变。
第二个输出的执行过程
现在u1.name是高小八
此时去执行testParameterTransfer02(),执行完name没有变化
1首先堆中产生u1,
id 100
name 高小七
地址是123,即u1=123
01中的u是局部变量,执行完之后就没有了
22调用testParameterTransfer02,这样就把u1的地址123传给了u
所以现在u=123
然后又新建了一个对象,新对象的地址是124,把新对象的地址给了u
u=124
这时
id 200
name 高三
只是改变了124地址上的对象,而没有改变123地址上的对象
所以此时打印u1.name是没有改变的

注意甄别,对象传递的时候传递的是地址的拷贝,但是也是有可能改变以前对象的值的
4.13 包
包机制是Java中管理类的重要手段。 开发中,我们会遇到大量同名的类,通过包我们很容易对解决类重名的问题,也可以实现对类的有效管理。 包对于类,相当于文件夹对于文件的作用。
电脑为什么需要文件夹,是因为要分类。包也一样。
4.13 package
我们通过package实现对类的管理,package的使用有两个要点:
1.通常是类的第一句非注释性语句。
2.包名:域名倒着写即可,再加上模块名,便于内部管理类。
A公司的域名,
京东:jd.com 项目名称
包名:com.jd
【示例4-13】package的命名举例
com.sun.test;
com.oracle.test;
cn.sxt.gao.test;
cn.sxt.gao.view;
cn.sxt.gao.view.model;
注意事项:
1.写项目时都要加包,不要使用默认包。
2.com.gao和com.gao.car,这两个包没有包含关系,是两个完全独立的包。只是逻辑上看起来后者是前者的一部分。
【示例4-14】package的使用
package cn.sxt;
public class Test {
public static void main(String[] args) {
System.out.println("helloworld");
}
}
·在eclipse项目中新建包
在src目录上单击右键,选择new->package
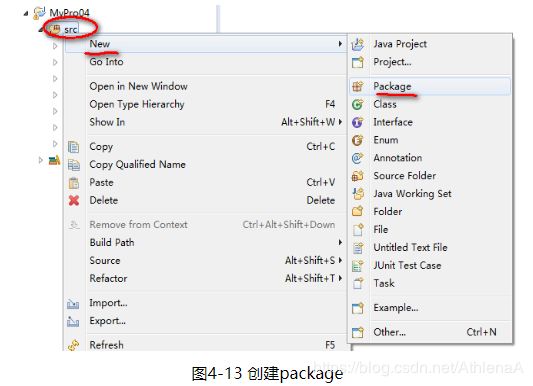
在package窗口上输入包名即可

接下来,我们就可以在包上单击右键,新建类啦!
4.13.1 JDK中的主要包

language lang里面的包不需要导入就可以使用
4.13.2 导入类import
如果我们要使用其他包的类,需要使用import导入,从而可以在本类中直接通过类名来调用,否则就需要书写类的完整包名和类名。import后,便于编写代码,提高可维护性。

这样写没问题,直接的写,清楚的的告诉了他,这样太繁琐

注意要点:
1.Java会默认导入java.lang包下所有的类,因此这些类我们可以直接使用。
2.如果导入两个同名的类,只能用包名+类名来显示调用相关类:
java.util.Date date = new java.util.Date();
【示例4-15】导入同名类的处理
import java.sql.Date;
import java.util.*;//导入该包下所有的类。会降低编译速度,但不会降低运行速度。
public class Test{
public static void main(String[] args) {
//这里指的是java.sql.Date
Date now;
//java.util.Date因为和java.sql.Date类同名,需要完整路径
java.util.Date now2 = new java.util.Date();
System.out.println(now2);
//java.util包的非同名类不需要完整路径
Scanner input = new Scanner(System.in);
}
}
4.13.3 静态导入
静态导入(static import)是在JDK1.5新增加的功能,其作用是用于导入指定类的静态属性,这样我们可以直接使用静态属性。
【示例4-16】静态导入的使用
package cn.sxt;
//以下两种静态导入的方式二选一即可
import static java.lang.Math.*;//导入Math类的所有静态属性
import static java.lang.Math.PI;//导入Math类的PI属性
public class Test2{
public static void main(String [] args){
System.out.println(PI);
System.out.println(random());
}
}
执行结果如图4-15所示。

总结
1.面向对象可以帮助我们从宏观上把握、从整体上分析整个系统。 但是具体到实现部分的微观操作(就是一个个方法),仍然需要面向过程的思路去处理。
2.类可以看成一类对象的模板,对象可以看成该类的一个具体实例。
3. 对于一个类来说,一般有三种常见的成员:属性field、方法method、构造器constructor。
4. 构造器也叫构造方法,用于对象的初始化。构造器是一个创建对象时被自动调用的特殊方法,目的是对象的初始化。构造器的名称应与类的名称一致。
5. Java引入了垃圾回收机制,令C++程序员最头疼的内存管理问题迎刃而解。Java程序员可将更多的精力放到业务逻辑上而不是内存管理工作,大大提高开发效率。
6. this的本质就是“创建好的对象的地址”! this不能用于static方法中。
7. 在类中,用static声明的成员变量为静态成员变量,也称为类变量。类变量的生命周期和类相同,在整个应用程序执行期间都有效。在static方法中不可直接访问非static的成员。
8. Java方法中所有参数都是“值传递”,也就是“传递的是值的副本”。也就是说,我们得到的是“原参数的复印件,而不是原件”。因此,复印件改变不会影响原件。
9. 通过package实现对类的管理;如果我们要使用其他包的类,需要使用import导入,从而可以在本类中直接通过类名来调用。
Java面向对象进阶
5.1 概述
本章重点针对面向对象的三大特征:继承、封装、多态进行详细的讲解。另外还包括抽象类、接口、内部类等概念。很多概念对于初学者来说,更多的是先进行语法性质的了解。不要期望,通过本章学习就“搞透面向对象”。本章只是面向对象的起点,后面所有的章节说白了都是对面向对象这一章的应用。
老鸟建议:建议大家,学习本章,莫停留!学完以后,迅速开展后面的章节。可以这么说,以后所有的编程都是“面向对象”的应用而已!
继承
5.1.1 继承的实现
继承让我们更加容易实现类的扩展。 比如,我们定义了人类,再定义Boy类就只需要扩展人类即可。实现了代码的重用,不用再重新发明轮子(don’t reinvent wheels)。
从英文字面意思理解,extends的意思是“扩展”。子类是父类的扩展。现实世界中的继承无处不在。比如:
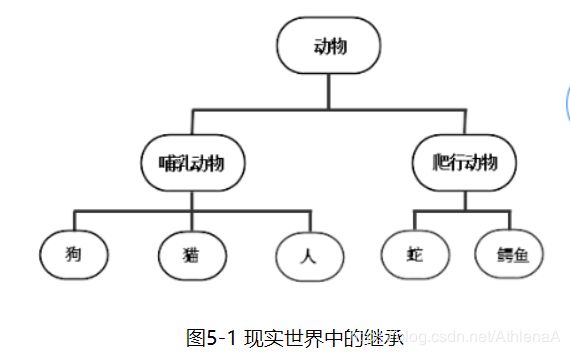
上图中,哺乳动物继承了动物。意味着,动物的特性,哺乳动物都有;在我们编程中,如果新定义一个Student类,发现已经有Person类包含了我们需要的属性和方法,那么Student类只需要继承Person类即可拥有Person类的属性和方法。
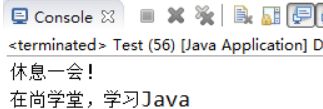
【示例5-1】使用extends实现继承
public class Test{
public static void main(String[] args) {
Student s = new Student("高淇",172,"Java");
s.rest();
s.study();
}
}
class Person {
String name;
int height;
public void rest(){
System.out.println("休息一会!");
}
}
class Student extends Person {
String major; //专业
public void study(){
System.out.println("在尚学堂,学习Java");
}
public Student(String name,int height,String major) {
//天然拥有父类的属性
this.name = name;
this.height = height;
this.major = major;
}
}
执行结果如图5-2所示:
5.1.2 instanceof 运算符
instanceof是二元运算符,左边是对象,右边是类;当对象是右面类或子类所创建对象时,返回true;否则,返回false。比如:
【示例5-2】使用instanceof运算符进行类型判断
public class Test{
public static void main(String[] args) {
Student s = new Student("高淇",172,"Java");
System.out.println(s instanceof Person);
System.out.println(s instanceof Student);
}
}
两条语句的输出结果都是true。
5.1.3 继承使用要点
1.父类也称作超类、基类、派生类等。
2.Java中只有单继承,没有像C++那样的多继承。多继承会引起混乱,使得继承链过于复杂,系统难于维护。
3.Java中类没有多继承,接口有多继承。
4.子类继承父类,可以得到父类的全部属性和方法 (除了父类的构造方法),但不见得可以直接访问(比如,父类私有的属性和方法)。
5.如果定义一个类时,没有调用extends,则它的父类是:java.lang.Object。
5.1.4方法的重写override
子类通过重写父类的方法,可以用自身的行为替换父类的行为。方法的重写是实现多态的必要条件。
方法的重写需要符合下面的三个要点:
1.“==”: 方法名、形参列表相同。
2.“≤”:返回值类型和声明异常类型,子类小于等于父类。
返回值类型
3.“≥”: 访问权限,子类大于等于父类。
【示例5-3】方法重写
public class TestOverride {
public static void main(String[] args) {
Vehicle v1 = new Vehicle();
Vehicle v2 = new Horse();
Vehicle v3 = new Plane();
v1.run();
v2.run();
v3.run();
v2.stop();
v3.stop();
}
}
class Vehicle { // 交通工具类
public void run() {
System.out.println("跑....");
}
public void stop() {
System.out.println("停止不动");
}
public Person whoIsPsg(){
return new Person();
}
}
class Horse extends Vehicle { // 马也是交通工具
public void run() { // 重写父类方法
System.out.println("四蹄翻飞,嘚嘚嘚...");
}
public Student whoIsPsg(){//这也算重写,返回值类型是小于父类的
return new Student();
}
}
class Plane extends Vehicle {
public void run() { // 重写父类方法
System.out.println("天上飞!");
}
public void stop() {
System.out.println("空中不能停,坠毁了!");
}
}
执行结果如图5-3所示: 
5.2.1 Object类基本特性
Object类是所有Java类的根基类,也就意味着所有的Java对象都拥有Object类的属性和方法。如果在类的声明中未使用extends关键字指明其父类,则默认继承Object类。
【示例5-4】Object类
public class Person {
...
}
//等价于:
public class Person extends Object {
...
}
5.2.2 toString方法
Object类中定义有public String toString()方法,其返回值是 String 类型。Object类中toString方法的源码为:
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
根据如上源码得知,默认会返回“类名+@+16进制的hashcode”。在打印输出或者用字符串连接对象时,会自动调用该对象的toString()方法。
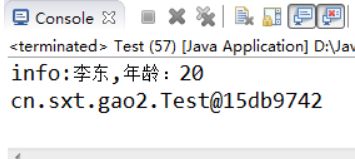
【示例5-5】toString()方法测试和重写toString()方法
class Person {
String name;
int age;
@Override
public String toString() {//重写了toString()方法
return name+",年龄:"+age;
}
}
public class Test {
public static void main(String[] args) {
Person p=new Person();
p.age=20;
p.name="李东";
System.out.println("info:"+p);
Test t = new Test();
System.out.println(t);
}
}
执行结果如图5-4所示:
5.2.3 ==和equals方法
“==”代表比较双方是否相同。如果是基本类型则表示值相等,如果是引用类型则表示地址相等即是同一个对象。
Object类中定义有:public boolean equals(Object obj)方法,提供定义“对象内容相等”的逻辑。比如,我们在公安系统中认为id相同的人就是同一个人、学籍系统中认为学号相同的人就是同一个人。
Object 的 equals 方法默认就是比较两个对象的hashcode,是同一个对象的引用时返回 true 否则返回 false。但是,我们可以根据我们自己的要求重写equals方法。
【示例5-6】equals方法测试和自定义类重写equals方法
public class TestEquals {
public static void main(String[] args) {
Person p1 = new Person(123,"高淇");
Person p2 = new Person(123,"高小七");
System.out.println(p1==p2); //false,不是同一个对象
System.out.println(p1.equals(p2)); //true,id相同则认为两个对象内容相同,因为我们重写了
String s1 = new String("尚学堂");
String s2 = new String("尚学堂");
System.out.println(s1==s2); //false, 两个字符串不是同一个对象
System.out.println(s1.equals(s2)); //true, 两个字符串内容相同
}
}
class Person {
int id;
String name;
public Person(int id,String name) {
this.id=id;
this.name=name;
}
public boolean equals(Object obj) {//重写了equals()方法
if(obj == null){
return false;
}else {
if(obj instanceof Person) {
Person c = (Person)obj;
if(c.id==this.id) {
return true;
}
}
}
return false;
}
}
JDK提供的一些类,如String、Date、包装类等,重写了Object的equals方法,调用这些类的equals方法, x.equals (y) ,当x和y所引用的对象是同一类对象且属性内容相等时(并不一定是相同对象),返回 true 否则返回 false。

这上面是自动生成的
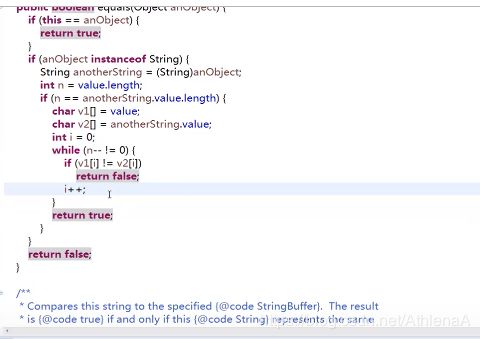
字符串类的equels源码
5.3 super关键字
super是直接父类对象的引用。可以通过super来访问父类中被子类覆盖的方法或属性。
使用super调用普通方法,语句没有位置限制,可以在子类中随便调用。
若是构造方法的第一行代码没有显式的调用super(…)或者this(…);那么Java默认都会调用super(),含义是调用父类的无参数构造方法。这里的super()可以省略。
【示例5-7】super关键字的使用
public class TestSuper01 {
public static void main(String[] args) {
new ChildClass().f();
}
}
class FatherClass {
public int value;
public void f(){
value = 100;
System.out.println ("FatherClass.value="+value);
}
}
class ChildClass extends FatherClass {
public int value;
public void f() {
super.f(); //调用父类对象的普通方法
value = 200;
System.out.println("ChildClass.value="+value);
System.out.println(value);
System.out.println(super.value); //调用父类对象的成员变量
}
}
执行结果如图5-5所示:
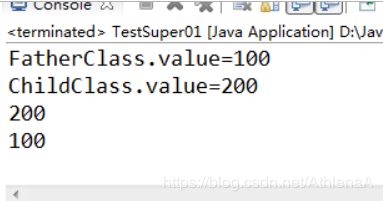
super.f()是调用父类的方法
super.value调用被子类覆盖的值
5.3.1 继承树追溯
·属性/方法查找顺序:(比如:查找变量h)
1.查找当前类中有没有属性h
2.依次上溯每个父类,查看每个父类中是否有h,直到Object
3.如果没找到,则出现编译错误。
4.上面步骤,只要找到h变量,则这个过程终止。
·构造方法调用顺序:
构造方法第一句总是:super(…)来调用父类对应的构造方法。所以,流程就是:先向上追溯到Object,然后再依次向下执行类的初始化块和构造方法,直到当前子类为止。
注:静态初始化块调用顺序,与构造方法调用顺序一样,不再重复。
【示例5-8】构造方法向上追溯执行测试
public class TestSuper02 {
public static void main(String[] args) {
System.out.println("开始创建一个ChildClass对象......");
new ChildClass();
}
}
class FatherClass {
public FatherClass() {
System.out.println("创建FatherClass");
}
}
class ChildClass extends FatherClass {
public ChildClass() {
System.out.println("创建ChildClass");
}
}
执行结果如图5-6所示:
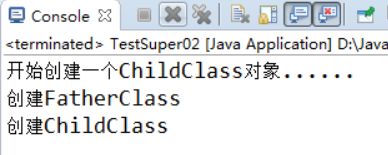
即使没有super(),它还是调用到了父类的构造方法,在子类的构造方法前面,会自动给你加一个super();语句。
O
F
C
5.4.1 封装的作用和含义
我要看电视,只需要按一下开关和换台就可以了。有必要了解电视机内部的结构吗?有必要碰碰显像管吗?制造厂家为了方便我们使用电视,把复杂的内部细节全部封装起来,只给我们暴露简单的接口,比如:电源开关。具体内部是怎么实现的,我们不需要操心。
需要让用户知道的才暴露出来,不需要让用户知道的全部隐藏起来,这就是封装。说的专业一点,封装就是把对象的属性和操作结合为一个独立的整体,并尽可能隐藏对象的内部实现细节。
我们程序设计要追求“高内聚,低耦合”。 高内聚就是类的内部数据操作细节自己完成,不允许外部干涉;低耦合是仅暴露少量的方法给外部使用,尽量方便外部调用。
编程中封装的具体优点:
1.提高代码的安全性。
2.提高代码的复用性。
3.“高内聚”:封装细节,便于修改内部代码,提高可维护性。
4.“低耦合”:简化外部调用,便于调用者使用,便于扩展和协作。
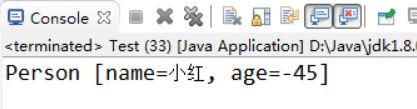
【示例5-9】没有封装的代码会出现一些问题
class Person {
String name;
int age;
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
}
public class Test {
public static void main(String[] args) {
Person p = new Person();
p.name = "小红";
p.age = -45;//年龄可以通过这种方式随意赋值,没有任何限制
System.out.println(p);
}
}
我们都知道,年龄不可能是负数,也不可能超过130岁,但是如果没有使用封装的话,便可以给年龄赋值成任意的整数,这显然不符合我们的正常逻辑思维。执行结果如图5-7所示:
再比如说,如果哪天我们需要将Person类中的age属性修改为String类型的,你会怎么办?你只有一处使用了这个类的话那还比较幸运,但如果你有几十处甚至上百处都用到了,那你岂不是要改到崩溃。而封装恰恰能解决这样的问题。如果使用封装,我们只需要稍微修改下Person类的setAge()方法即可,而无需修改使用了该类的客户代码。
这样的话所有的类都可以改变你的age属性,显然不好。需要将age封装起来,给age加个壳子。不让别的类访问。
5.4.2 封装的实现—使用访问控制符
Java是使用“访问控制符”来控制哪些细节需要封装,哪些细节需要暴露的。 Java中4种“访问控制符”分别为private、default、protected、public,它们说明了面向对象的封装性,所以我们要利用它们尽可能的让访问权限降到最低,从而提高安全性。
下面详细讲述它们的访问权限问题。其访问权限范围如表5-1所示。
表5-1 访问权限修饰符
这里的子类是指不同包的子类
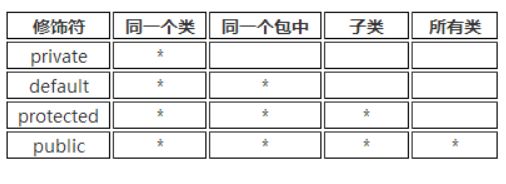
1.private 表示私有,只有自己类能访问
2.default表示没有修饰符修饰,只有同一个包的类能访问
3.protected表示可以被同一个包的类以及其他包中的子类访问
4.public表示可以被该项目的所有包中的所有类访问
例1:
package cn.sxt.oo2;
public class TestEncapsulation{
public static void main(String[] args){
Human h=new Human();
//h.age=13;//不可以直接调用私有属性和方法
h.name;
}
}
class Human{
private int age;//私有的属性,只能被同一个类调用
String name;//默认的default属性,同一个包内oo2的类都可以调用这个属性,不能被不同包的类访问
void sayAge(){
System.out.println(age);
}
}
class Boy extends Human{
void sayHello(){
//System.out.println(age);//子类无法使用父类的私有属性和方法
}
}
例2:
package cn.sxt.oo2;
public class Human{
private int age;//只能被本类访问
String name;//可以被本包下面的类访问
protected int height;//可以被本类或者本包,不同包的子类访问
void sayAge(){
System.out.println(age);
}
}
package cn.sxt.oo;
import cn.sxt.too2.Human;
public class TestEncapsulation2{
public static void main(String[] args){
Human h=new Human();
//h.age=13;//不可以直接调用私有属性和方法
h.name;//
}
}
class Girl extends Human{
void sayGood(){
System.out.println(height);//同一包下都可以访问
}
}
下面做进一步说明Java中4种访问权限修饰符的区别:首先我们创建4个类:Person类、Student类、Animal类和Computer类,分别比较本类、本包、子类、其他包的区别。
public访问权限修饰符:
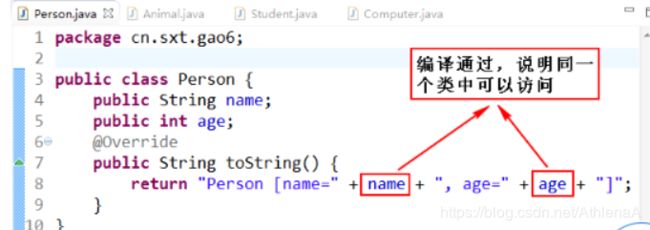
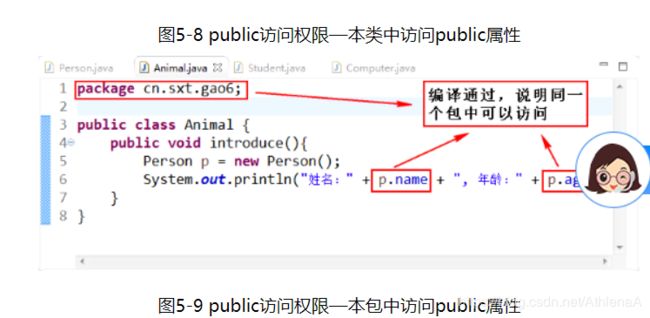
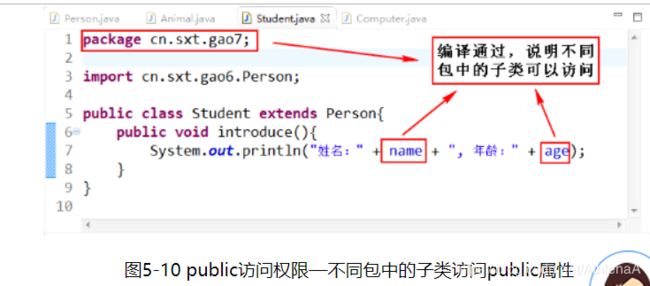
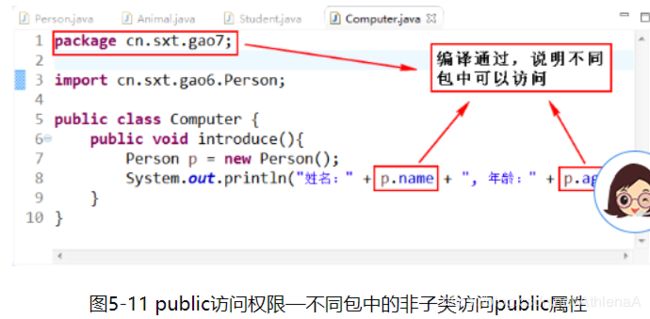
通过图5-8 ~ 图5-11可以说明,public修饰符的访问权限为:该项目的所有包中的所有类。
protected访问权限修饰符:将Person类中属性改为protected,其他类不修改。
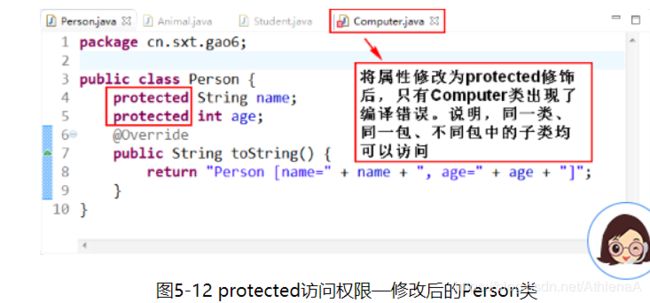
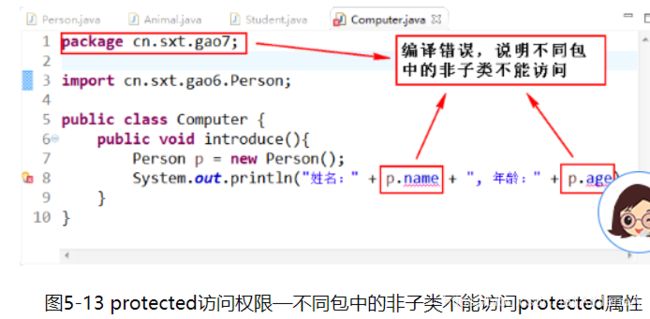
通过图5-12和图5-13可以说明,protected修饰符的访问权限为:同一个包中的类以及其他包中的子类。
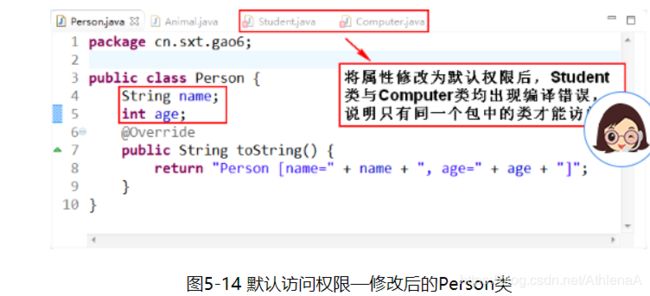
默认访问权限修饰符:将Person类中属性改为默认的,其他类不修改。
通过图5-14可以说明,默认修饰符的访问权限为:同一个包中的类。
private访问权限修饰符:将Person类中属性改为private,其他类不修改。

通过图5-15可以说明,private修饰符的访问权限为:同一个类。
5.4.3 封装的使用细节
类的属性的处理:
1.一般使用private访问权限。
2. 提供相应的get/set方法来访问相关属性,这些方法通常是public修饰的,以提供对属性的赋值与读取操作(注意:boolean变量的get方法是is开头!)。
3.一些只用于本类的辅助性方法可以用private修饰,希望其他类调用的方法用public修饰。
【示例5-10】JavaBean的封装实例
public class Person {
// 属性一般使用private修饰
private String name;
private int age;
private boolean flag;
// 为属性提供public修饰的set/get方法
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public boolean isFlag() {// 注意:boolean类型的属性get方法是is开头的
return flag;
}
public void setFlag(boolean flag) {
this.flag = flag;
}
}
下面我们使用封装来解决一下5.4.1中提到的年龄非法赋值的问题。
【示例5-11】封装的使用
class Person {
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
// this.age = age;//构造方法中不能直接赋值,应该调用setAge方法
setAge(age);
}
public void setName(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setAge(int age) {//通过private对本类暴露一个属性,通过setAge设为public来对外提供接口。这就是
//在赋值之前先判断年龄是否合法
if (age > 130 || age < 0) {
this.age = 18;//不合法赋默认值18
} else {
this.age = age;//合法才能赋值给属性age
}
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
}
public class Test2 {
public static void main(String[] args) {
Person p1 = new Person();
//p1.name = "小红"; //编译错误
//p1.age = -45; //编译错误
p1.setName("小红");
p1.setAge(-45);
System.out.println(p1);
Person p2 = new Person("小白", 300);
System.out.println(p2);
}
}
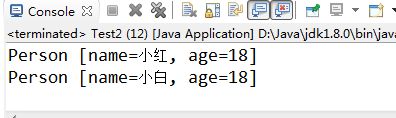
执行结果如图5-16所示:
5.5 多态(polymorphism)
多态指的是同一个方法调用,由于对象不同可能会有不同的行为。现实生活中,同一个方法,具体实现会完全不同。 比如:同样是调用人的“休息”方法,张三是睡觉,李四是旅游,高淇老师是敲代码,数学教授是做数学题; 同样是调用人“吃饭”的方法,中国人用筷子吃饭,英国人用刀叉吃饭,印度人用手吃饭。
多态的要点:
1.多态是方法的多态,不是属性的多态(多态与属性无关)。
2.多态的存在要有3个必要条件:继承,方法重写,父类引用指向子类对象。
3.父类引用指向子类对象后,用该父类引用调用子类重写的方法,此时多态就出现了。
【示例5-12】多态和类型转换测试
class Animal {
public void shout() {
System.out.println("叫了一声!");
}
}
class Dog extends Animal {
public void shout() {
System.out.println("旺旺旺!");
}
public void seeDoor() {
System.out.println("看门中....");
}
}
class Cat extends Animal {
public void shout() {
System.out.println("喵喵喵喵!");
}
}
public class TestPolym {
public static void main(String[] args) {
Animal a1 = new Cat(); // 向上可以自动转型
//传的具体是哪一个类就调用哪一个类的方法。大大提高了程序的可扩展性。
animalCry(a1);
Animal a2 = new Dog();
animalCry(a2);//a2为编译类型,Dog对象才是运行时类型。
//编写程序时,如果想调用运行时类型的方法,只能进行强制类型转换。
// 否则通不过编译器的检查。
Dog dog = (Dog)a2;//向下需要强制类型转换
dog.seeDoor();
}
// 有了多态,只需要让增加的这个类继承Animal类就可以了。
static void animalCry(Animal a) {
a.shout();
}
/* 如果没有多态,我们这里需要写很多重载的方法。
* 每增加一种动物,就需要重载一种动物的喊叫方法。非常麻烦。
static void animalCry(Dog d) {
d.shout();
}
static void animalCry(Cat c) {
c.shout();
}*/
}
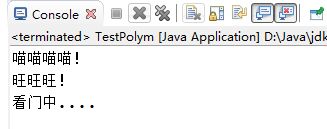
执行结果如图5-17所示:
示例5-12给大家展示了多态最为多见的一种用法,即父类引用做方法的形参,实参可以是任意的子类对象,可以通过不同的子类对象实现不同的行为方式。
由此,我们可以看出多态的主要优势是提高了代码的可扩展性,符合开闭原则。但是多态也有弊端,就是无法调用子类特有的功能,比如,我不能使用父类的引用变量调用Dog类特有的seeDoor()方法。
那如果我们就想使用子类特有的功能行不行呢?行!这就是我们下一章节所讲的内容:对象的转型。
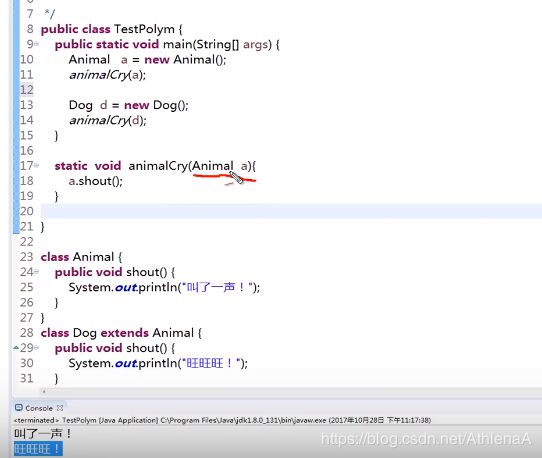
我们新建了一个Dog类型的对象d,把d传递给Animal类父类引用,
即父类引用指向了子类对象,这时候就发生了多态。
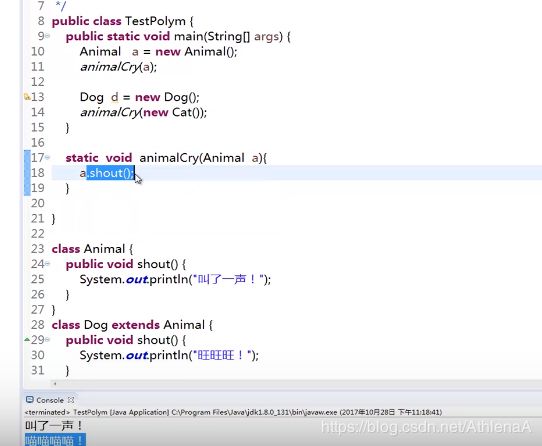
这里因为传的对象的类型不一样,调用的方法也不一样。
如果我们这里假设没有这个方法,static void animalCry(Animal a){a.shout();}
所以这里父类引用不能指向子类对象了,所以这里需要写多个重载的方法:
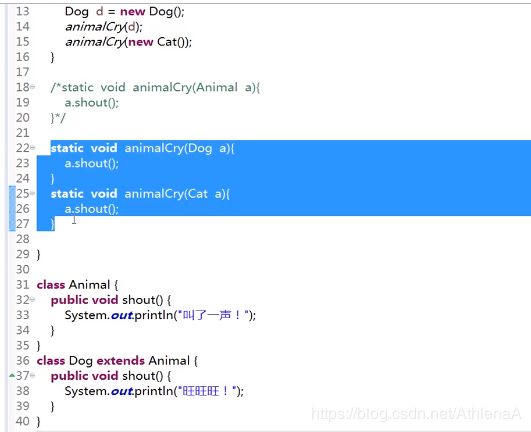
所以这里会出现大量的重载方法,这样肯定是不对的
所以有了多态,我们只用让父类引用指向子类对象,即可。
5.6 对象的转型(casting)
父类引用指向子类对象,我们称这个过程为向上转型,属于自动类型转换。
如:Animal d=new Dog();
向上转型后的父类引用变量只能调用它编译类型的方法,不能调用它运行时类型的方法。
因为编译器只认得d是Animal类型的,只认Animal的方法。
如果d还想使用狗类的方法seeDoor(),必须强制转回来。
这时,我们就需要进行类型的强制转换,我们称之为向下转型!
如:Dog d2=(Dog)d;
d2.seeDoor();
【示例5-13】对象的转型
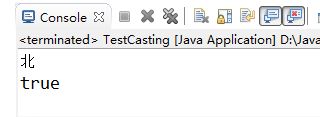
public class TestCasting {
public static void main(String[] args) {
Object obj = new String("北京尚学堂"); // 向上可以自动转型
// obj.charAt(0) 无法调用。编译器认为obj是Object类型而不是String类型
/* 编写程序时,如果想调用运行时类型的方法,只能进行强制类型转换。
* 不然通不过编译器的检查。 */
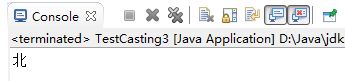
String str = (String) obj; // 向下转型
System.out.println(str.charAt(0)); // 位于0索引位置的字符
System.out.println(obj == str); // true.他们俩运行时是同一个对象
}
}
执行结果如果5-18所示:
在向下转型过程中,必须将引用变量转成真实的子类类型(运行时类型)否则会出现类型转换异常ClassCastException。如示例5-14所示。
【示例5-14】类型转换异常
public class TestCasting2 {
public static void main(String[] args) {
Object obj = new String("北京尚学堂");
//真实的子类类型是String,但是此处向下转型为StringBuffer
StringBuffer str = (StringBuffer) obj;
System.out.println(str.charAt(0));
}
}
执行结果如果5-19所示:

为了避免出现这种异常,我们可以使用5.1.2中所学的instanceof运算符进行判断,如示例5-15所示。
【示例5-15】向下转型中使用instanceof
public class TestCasting3 {
public static void main(String[] args) {
Object obj = new String("北京尚学堂");
if(obj instanceof String){
String str = (String)obj;
System.out.println(str.charAt(0));
}else if(obj instanceof StringBuffer){
StringBuffer str = (StringBuffer) obj;
System.out.println(str.charAt(0));
}
}
}
执行结果如果5-20所示:
5.7 final关键字
final关键字的作用:
1.修饰变量: 被他修饰的变量不可改变。一旦赋了初值,就不能被重新赋值。常量!
final int MAX_SPEED = 120;
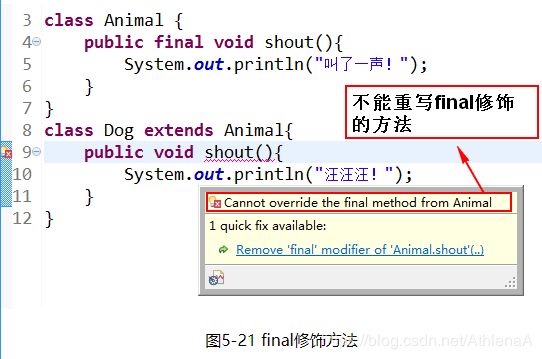
2.修饰方法:该方法不可被子类重写。但是可以被重载!
final void study(){}
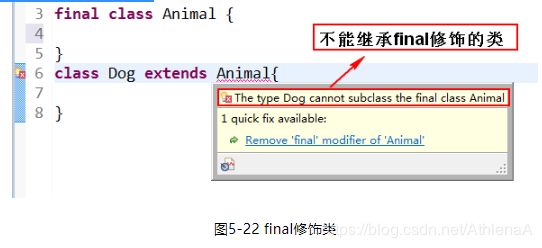
3. 修饰类: 修饰的类不能被继承。比如:Math、String等。
final class A {}
final修饰变量
详见第二章示例2-9。
final修饰方法
如图5-21所示。
final修饰类
如图5-22所示。
5.8 抽象方法和抽象类
·抽象方法
使用abstract修饰的方法,没有方法体,只有声明。定义的是一种“规范”,就是告诉子类必须要给抽象方法提供具体的实现。
·抽象类
包含抽象方法的类就是抽象类。通过abstract方法定义规范,然后要求子类必须定义具体实现。通过抽象类,我们就可以做到严格限制子类的设计,使子类之间更加通用。
【示例5-16】抽象类和抽象方法的基本用法
//抽象类的意义就在于:为子类提供统一的、规范的模板。子类必须实现相关的抽象方法。
abstract class Animal {
//第一:没有实现 第二:子类必须实现
abstract public void shout(); //抽象方法
public void run(){//当然抽象类中可以定义非抽象方法
}
}
class Dog extends Animal {
//子类必须实现父类的抽象方法,否则编译错误
public void shout() {
System.out.println("汪汪汪!");
}
public void seeDoor(){
System.out.println("看门中....");
}
}
//测试抽象类
public class TestAbstractClass {
public static void main(String[] args) {
Dog a = new Dog();
a.shout();
a.seeDoor();
}
}
抽象类的使用要点:
1.有抽象方法的类只能定义成抽象类
2.抽象类不能实例化,即不能用new来实例化抽象类。
不能new Animal();
可以Animal a= new Dog();
3.抽象类可以包含属性、方法、构造方法。但是构造方法不能用来new实例,只能用来被子类调用。
4.抽象类只能用来被继承。
5.抽象方法必须被子类实现。
5.9.1接口的作用
· 为什么需要接口?接口和抽象类的区别?
接口就是比“抽象类”还“抽象”的“抽象类”,可以更加规范的对子类进行约束。全面地专业地实现了:规范和具体实现的分离。接口只定义规范,只有抽象方法,没有普通方法,不定义具体实现。
抽象类还提供某些具体实现,接口不提供任何实现,接口中所有方法都是抽象方法。接口是完全面向规范的,规定了一批类具有的公共方法规范。
从接口的实现者角度看,接口定义了可以向外部提供的服务。
从接口的调用者角度看,接口定义了实现者能提供那些服务。
接口是两个模块之间通信的标准,通信的规范。如果能把你要设计的模块之间的接口定义好,就相当于完成了系统的设计大纲,剩下的就是添砖加瓦的具体实现了。大家在工作以后,做系统时往往就是使用“面向接口”的思想来设计系统。
接口和实现类不是父子关系,是实现规则的关系。比如:我定义一个接口Runnable,Car实现它就能在地上跑,Train实现它也能在地上跑,飞机实现它也能在地上跑。就是说,如果它是交通工具,就一定能跑,但是一定要实现Runnable接口。
· 接口的本质探讨
接口就是规范,定义的是一组规则,体现了现实世界中“如果你是…则必须能…”的思想。如果你是天使,则必须能飞。如果你是汽车,则必须能跑。如果你是好人,则必须能干掉坏人;如果你是坏人,则必须欺负好人。
接口的本质是契约,就像我们人间的法律一样。制定好后大家都遵守。
面向对象的精髓,是对对象的抽象,最能体现这一点的就是接口。为什么我们讨论设计模式都只针对具备了抽象能力的语言(比如C++、Java、C#等),就是因为设计模式所研究的,实际上就是如何合理的去抽象。
区别
1.普通类:具体实现
2.抽象类:具体实现,规范(抽象方法)
3.接口:规范!
5.9.2 如何定义和使用接口?
声明格式:
[访问修饰符] interface 接口名 [extends 父接口1,父接口2…] {
常量定义; //接口中只能定义常量,不能定义变量。因为只能定义不变的稳定的东西
方法定义;
}
定义接口的详细说明:
1.访问修饰符:只能是public或默认。
2.接口名:和类名采用相同命名机制。
3. extends:接口可以多继承。
4. 常量:接口中的属性只能是常量,总是:public static final 修饰。不写也是。
5. 方法:接口中的方法只能是:public abstract。 省略的话,也是public abstract。
要点
1.子类通过implements来实现接口中的规范。
2. 接口不能创建实例,但是可用于声明引用变量类型。
3. 一个类实现了接口,必须实现接口中所有的方法,并且这些方法只能是public的。
4. JDK1.7之前,接口中只能包含静态常量、抽象方法,不能有普通属性、构造方法、普通方法。
5. JDK1.8后,接口中包含普通的静态方法。
【示例5-17】接口的使用
public class TestInterface {
public static void main(String[] args) {
Volant volant = new Angel();//这里定义了天使为Volant 类型的,
//那么只能使用Volant 有的方法,不能使用helpOther()
volant.fly();
System.out.println(Volant.FLY_HIGHT);
Honest honest = new GoodMan();
honest.helpOther();
}
}
/**飞行接口*/
interface Volant { //只要实现了我这个接口就能飞行
int FLY_HIGHT = 100; // 总是:public static final类型的;
void fly(); //总是:public abstract void fly();
}
/**善良接口*/
interface Honest {
void helpOther();
}
/**Angle类实现飞行接口和善良接口*/
class Angel implements Volant, Honest{
public void fly() {
System.out.println("我是天使,飞起来啦!");
}
public void helpOther() {
System.out.println("扶老奶奶过马路!");
}
}
/**GoodMan 类实现善良接口*/
class GoodMan implements Honest {
public void helpOther() {
System.out.println("扶老奶奶过马路!");
}
}
/**BirdMan 类实现飞行接口*/
class BirdMan implements Volant {
public void fly() {
System.out.println("我是鸟人,正在飞!");
}
}
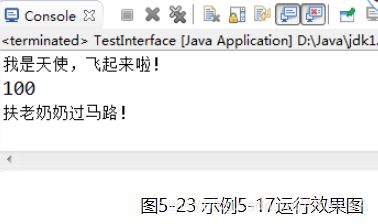
执行结果如果5-23所示:
5.9.3 接口的多继承
接口完全支持多继承。和类的继承类似,子接口扩展某个父接口,将会获得父接口中所定义的一切。
多继承和多层继承
多继承是可以有好几个父亲
【示例5-18】接口的多继承
interface A {
void testa();
}
interface B {
void testb();
}
/**接口可以多继承:接口C继承接口A和B*/
interface C extends A, B {
void testc();
}
public class Test implements C {
public void testc() {
}
public void testa() {
}
public void testb() {
}
}
5.9.4 面向接口编程
面向接口编程是面向对象编程的一部分。
为什么需要面向接口编程? 软件设计中最难处理的就是需求的复杂变化,需求的变化更多的体现在具体实现上。我们的编程如果围绕具体实现来展开就会陷入”复杂变化”的汪洋大海中,软件也就不能最终实现。我们必须围绕某种稳定的东西开展,才能以静制动,实现规范的高质量的项目。
接口就是规范,就是项目中最稳定的东东! 面向接口编程可以让我们把握住真正核心的东西,使实现复杂多变的需求成为可能。
通过面向接口编程,而不是面向实现类编程,可以大大降低程序模块间的耦合性,提高整个系统的可扩展性和和可维护性。
面向接口编程的概念比接口本身的概念要大得多。设计阶段相对比较困难,在你没有写实现时就要想好接口,接口一变就乱套了,所以设计要比实现难!
老鸟建议
接口语法本身非常简单,但是如何真正使用?这才是大学问。我们需要后面在项目中反复使用,大家才能体会到。 学到此处,能了解基本概念,熟悉基本语法,就是“好学生”了。 请继续努力!再请工作后,闲余时间再看看上面这段话,相信你会有更深的体会。
5.10.1内部类的概念
一般情况,我们把类定义成独立的单元。有些情况下,我们把一个类放在另一个类的内部定义,称为内部类(innerclasses)。
内部类可以使用public、default、protected 、private以及static修饰。
而外部顶级类(我们以前接触的类)只能使用public和default修饰。
注意
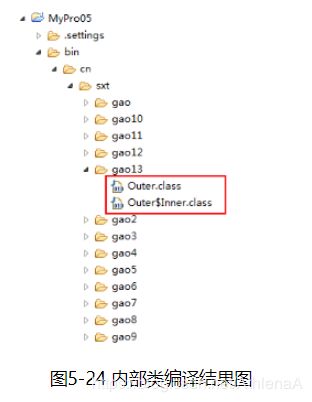
内部类只是一个编译时概念,一旦我们编译成功,就会成为完全不同的两个类。对于一个名为Outer的外部类和其内部定义的名为Inner的内部类。编译完成后会出现Outer.class和Outer$Inner.class两个类的字节码文件。所以内部类是相对独立的一种存在,其成员变量/方法名可以和外部类的相同。
【示例5-19】内部类介绍
/**外部类Outer*/
class Outer {
private int age = 10;
public void show(){
System.out.println(age);//10
}
/**内部类Inner*/
public class Inner {
//内部类中可以声明与外部类同名的属性与方法
private int age = 20;
public void show(){
System.out.println(age);//20
}
}
}
示例5-19编译后会产生两个不同的字节码文件,如图5-24所示:
内部类的作用:
1.内部类提供了更好的封装。只能让外部类直接访问,不允许同一个包中的其他类直接访问。
2.内部类可以直接访问外部类的私有属性,内部类被当成其外部类的成员。 但外部类不能访问内部类的内部属性。
3.接口只是解决了多重继承的部分问题,而内部类使得多重继承的解决方案变得更加完整。
内部类的使用场合:
1.由于内部类提供了更好的封装特性,并且可以很方便的访问外部类的属性。所以,在只为外部类提供服务的情况下可以优先考虑使用内部类。
2. 使用内部类间接实现多继承:每个内部类都能独立地继承一个类或者实现某些接口,所以无论外部类是否已经继承了某个类或者实现了某些接口,对于内部类没有任何影响。
5.10.2内部类的分类
在Java中内部类主要分为成员内部类(非静态内部类、静态内部类)、匿名内部类、局部内部类。
一
. 成员内部类(可以使用private、default、protected、public任意进行修饰。 类文件:外部类$内部类.class)
1
a) 非静态内部类(外部类里使用非静态内部类和平时使用其他类没什么不同)
i. 非静态内部类必须寄存在一个外部类对象里。因此,如果有一个非静态内部类对象那么一定存在对应的外部类对象。非静态内部类对象单独属于外部类的某个对象。
ii. 非静态内部类可以直接访问外部类的成员,但是外部类不能直接访问非静态内部类成员。
iii. 非静态内部类不能有静态方法、静态属性和静态初始化块。
iv. 外部类的静态方法、静态代码块不能访问非静态内部类,包括不能使用非静态内部类定义变量、创建实例。
v. 成员变量访问要点:
1.内部类里方法的局部变量:变量名。
2.内部类属性:this.变量名。
3.外部类属性:外部类名.this.变量名。
【示例5-20】成员变量的访问要点
class Outer {
private int age = 10;
class Inner {//非静态内部类
int age = 20;
public void show() {
int age = 30;
System.out.println("内部类方法里的局部变量age:" + age);// 30
System.out.println("内部类的成员变量age:" + this.age);// 20
System.out.println("外部类的成员变量age:" + Outer.this.age);// 10 非静态内部类可以直接访问外部类的成员
}
}
}
vi.内部类的访问:
1.外部类中定义内部类:new Inner()
2. 外部类以外的地方使用非静态内部类: Outer.Inner varname = new Outer().new Inner()。
【示例5-21】内部类的访问
public class TestInnerClass {
public static void main(String[] args) {
//先创建外部类实例,然后使用该外部类实例创建内部类实例
Outer.Inner inner = new Outer().new Inner();
inner.show();
Outer outer = new Outer();
Outer.Inner inn = outer.new Inner();
inn.show();
}
}
执行结果如图5-25所示:

2
b) 静态内部类
i. 定义方式:
static class ClassName {
//类体
}
ii. 使用要点:
1.当一个静态内部类对象存在,并不一定存在对应的外部类对象。 因此,静态内部类的实例方法不能直接访问外部类的实例方法。
2.静态内部类看做外部类的一个静态成员。 因此,外部类的方法中可以通过:“静态内部类.名字”的方式访问静态内部类的静态成员,通过 new 静态内部类()访问静态内部类的实例。
【示例5-22】静态内部类的访问
class Outer{
//相当于外部类的一个静态成员
static class Inner{
}
}
public class TestStaticInnerClass {
public static void main(String[] args) {
//通过 new 外部类名.内部类名() 来创建内部类对象
//Outer.Inner inner = new Outer().new Inner();这是前面要依赖外部类的情况下创建内部类对象
Outer.Inner inner =new Outer.Inner();
}
}
二
. 匿名内部类
适合那种只需要使用一次的类。比如:键盘监听操作等等。
语法:
new 父类构造器(实参类表) \实现接口 () {
//匿名内部类类体!
}
【示例5-23】匿名内部类的使用
this.addWindowListener(new WindowAdapter(){
@Override
public void windowClosing(WindowEvent e) {
System.exit(0);
}
}
);
this.addKeyListener(new KeyAdapter(){
@Override
public void keyPressed(KeyEvent e) {
myTank.keyPressed(e);
}
@Override
public void keyReleased(KeyEvent e) {
myTank.keyReleased(e);
}
}
);
注意
1.匿名内部类没有访问修饰符。
2.匿名内部类没有构造方法。因为它连名字都没有那又何来构造方法呢。
三
.局部内部类
还有一种内部类,它是定义在方法内部的,作用域只限于本方法,称为局部内部类。
局部内部类的的使用主要是用来解决比较复杂的问题,想创建一个类来辅助我们的解决方案,到那时又不希望这个类是公共可用的,所以就产生了局部内部类。局部内部类和成员内部类一样被编译,只是它的作用域发生了改变,它只能在该方法中被使用,出了该方法就会失效。
局部内部类在实际开发中应用很少。
【示例5-24】方法中的内部类
public class Test2 {
public void show() {
//作用域仅限于该方法
class Inner {
public void fun() {
System.out.println("helloworld");
}
}
new Inner().fun();
}
public static void main(String[] args) {
new Test2().show();
}
}
执行结果如图5-26所示:
5.11.1 String基础
1.String类又称作不可变字符序列。
2.String位于java.lang包中,Java程序默认导入java.lang包下的所有类。
3.Java字符串就是Unicode字符序列,例如字符串“Java”就是4个Unicode字符’J’、’a’、’v’、’a’组成的。
4. Java没有内置的字符串类型,而是在标准Java类库中提供了一个预定义的类String,每个用双引号括起来的字符串都是String类的一个实例。
如:String str=“abc”;或
String str2=new String(“def”);或
String str3=“abc”+“as”;
【示例5-25】String类的实例
String e = "" ; // 空字符串
String greeting = " Hello World ";
5.Java允许使用符号"+"把两个字符串连接起来。
【示例5-26】字符串连接
String s1 = "Hello";
String s2 = "World! ";
String s = s1 + s2; //HelloWorld!
n-符号"+“把两个字符串按给定的顺序连接在一起,并且是完全按照给定的形式。
n-当”+“运算符两侧的操作数中只要有一个是字符串(String)类型,系统会自动将另一个操作数转换为字符串然后再进行连接。
【示例5-27】”+"连接符
int age = 18;
String str = "age is" + age; //str赋值为"age is 18"
//这种特性通常被用在输出语句中:
System.out.println("age is" + age);
5.11.2 String类和常量池
在Java的内存分析中,我们会经常听到关于“常量池”的描述,实际上常量池也分了以下三种:
1.全局字符串常量池(String Pool)
全局字符串常量池中存放的内容是在类加载完成后存到String Pool中的,在每个VM中只有一份,存放的是字符串常量的引用值(在堆中生成字符串对象实例)。
2.class文件常量池(Class Constant Pool)
class常量池是在编译的时候每个class都有的,在编译阶段,存放的是常量(文本字符串、final常量等)和符号引用。
3.运行时常量池(Runtime Constant Pool)
运行时常量池是在类加载完成之后,将每个class常量池中的符号引用值转存到运行时常量池中,也就是说,每个class都有一个运行时常量池,类在解析之后,将符号引用替换成直接引用,与全局常量池中的引用值保持一致。


通常比较字符串时,使用equals比较内容
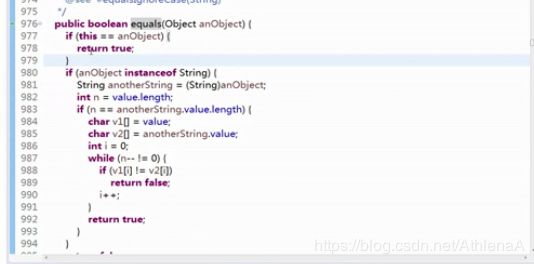
【示例5-28】常量池
String str1 = "abc";//自动放到常量池里,放的是引用地址
String str2 = new String("def");
String str3 = "abc";
String str4 = str2.intern();
String str5 = "def";
System.out.println(str1 == str3);// true
System.out.println(str2 == str4);// false
System.out.println(str4 == str5);// true
示例5-28的首先经过编译之后,在该类的class常量池中存放一些符号引用,然后类加载之后,将class常量池中存放的符号引用转存到运行时常量池中,然后经过验证,准备阶段之后,在堆中生成驻留字符串的实例对象(也就是上例中str1所指向的“abc”实例对象),然后将这个对象的引用存到全局String Pool中,也就是String Pool中,最后在解析阶段,要把运行时常量池中的符号引用替换成直接引用,那么就直接查询String Pool,保证String Pool里的引用值与运行时常量池中的引用值一致,大概整个过程就是这样了。
回到示例5-28的那个程序,现在就很容易解释整个程序的内存分配过程了,首先,在堆中会有一个“abc”实例,全局String Pool中存放着“abc”的一个引用值,然后在运行第二句的时候会生成两个实例,一个是“def”的实例对象,并且String Pool中存储一个“def”的引用值,还有一个是new出来的一个“def”的实例对象,与上面那个是不同的实例,当在解析str3的时候查找String Pool,里面有“abc”的全局驻留字符串引用,所以str3的引用地址与之前的那个已存在的相同,str4是在运行的时候调用intern()函数,返回String Pool中“def”的引用值,如果没有就将str2的引用值添加进去,在这里,String Pool中已经有了“def”的引用值了,所以返回上面在new str2的时候添加到String Pool中的 “def”引用值,最后str5在解析的时候就也是指向存在于String Pool中的“def”的引用值,那么这样一分析之后,结果就容易理解了。
5.11.3阅读API文档
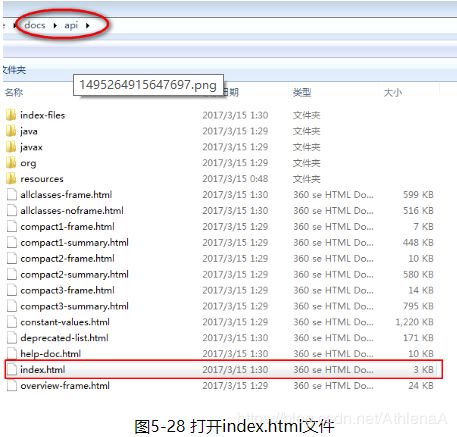
· 如何下载API文档
1.下载地址,点击进入:
http://www.oracle.com/technetwork/java/javase/documentation/jdk8-doc-downloads-2133158.html

2. 下载成功后,解压下载的压缩文件,点击进入docs/api下的index.html文件即可。
·API文档如何阅读
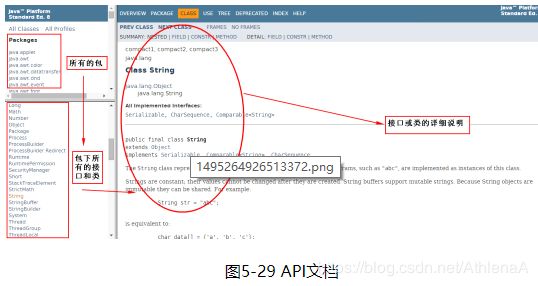
· eclipse中将鼠标放到类或方法上,即可看到相关的注释说明;再按下F2即可将注释窗口固定。
5.11.4 String类常用的方法
String类是我们最常使用的类。字符串类的方法我们必须非常熟悉!我们列出常用的方法,请大家熟悉。
表5-2 String类的常用方法列表

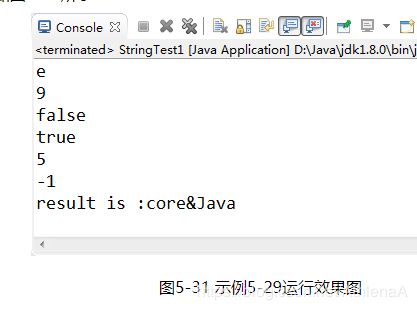
【示例5-29】String类常用方法一
public class StringTest1 {
public static void main(String[] args) {
String s1 = "core Java";
String s2 = "Core Java";
System.out.println(s1.charAt(3));//提取下标为3的字符 e
System.out.println(s2.length());//字符串的长度
System.out.println(s1.equals(s2));//比较两个字符串是否相等
System.out.println(s1.equalsIgnoreCase(s2));//比较两个字符串(忽略大小写)
System.out.println(s1.indexOf("Java"));//字符串s1中是否包含Java
System.out.println(s1.indexOf("apple"));//字符串s1中是否包含apple
String s = s1.replace(' ', '&');//将s1中的空格替换成&
System.out.println("result is :" + s);
}
}
执行结果如图5-31所示:
【示例5-30】String类常用方法二
public class StringTest2 {
public static void main(String[] args) {
String s = “”;
String s1 = “How are you?”;
System.out.println(s1.startsWith(“How”));//是否以How开头
System.out.println(s1.endsWith(“you”));//是否以you结尾
s = s1.substring(4);//提取子字符串:从下标为4的开始到字符串结尾为止
System.out.println(s);
s = s1.substring(4, 7);//提取子字符串:下标[4, 7) 不包括7
System.out.println(s);
s = s1.toLowerCase();//转小写
System.out.println(s);
s = s1.toUpperCase();//转大写
System.out.println(s);
String s2 = " How old are you!! ";
s = s2.trim();//去除字符串首尾的空格。注意:中间的空格不能去除
System.out.println(s);
System.out.println(s2);//因为String是不可变字符串,所以s2不变
}
}
执行结果如图5-32所示:

5.11.5 字符串相等的判断
1.equals方法用来检测两个字符串内容是否相等。如果字符串s和t内容相等,则s.equals(t)返回true,否则返回false。
2.要测试两个字符串除了大小写区别外是否是相等的,需要使用equalsIgnoreCase方法。
3.判断字符串是否相等不要使用"=="。
【示例5-31】忽略大小写的字符串比较
"Hello".equalsIgnoreCase("hellO");//true
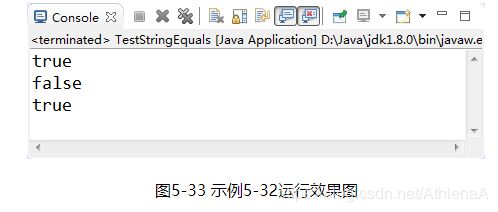
【示例5-32】字符串的比较"=="与equals()方法
public class TestStringEquals {
public static void main(String[] args) {
String g1 = "北京尚学堂";
String g2 = "北京尚学堂";
String g3 = new String("北京尚学堂");
System.out.println(g1 == g2); // true 指向同样的字符串常量对象
System.out.println(g1 == g3); // false g3是新创建的对象
System.out.println(g1.equals(g3)); // true g1和g3里面的字符串内容是一样的
}
}
执行结果如图5-33所示:

5.12.1 开闭原则
开闭原则(Open-Closed Principle)就是让设计的系统对扩展开放,对修改封闭。
· 对扩展开放:
就是指,应对需求变化要灵活。 要增加新功能时,不需要修改已有的代码,增加新代码即可。
· 对修改关闭:
就是指,核心部分经过精心设计后,不再因为需求变化而改变。
在实际开发中,我们无法完全做到,但应尽量遵守开闭原则。
5.12.2 模板方法模式和回调机制
模板方法模式很常用,其目的是在一个方法中定义一个算法骨架,而将一些步骤延迟到子类中。模板方法使得子类可以在不改变算法结构的情况下,重新定义算法的某些步骤。在标准的模板方法模式实现中,主要是使用继承的方式,来让父类在运行期间可以调用到子类的方法。 详见抽象类部分示例。
其实在Java开发中,还有另外一个方法可以实现同样的功能,那就是Java回调技术。回调是一种双向的调用模式,也就是说,被调用的接口被调用时也会调用对方的接口,简单点说明就是:A类中调用B类中的C方法,然后B类中的C方法中反过来调用A类中的D方法,那么D这个方法就叫回调方法。
回调的具体过程如下:
1. Class A实现接口CallBack —— 背景1
2. class A中包含class B的引用 ——背景2
3. class B有一个参数为CallBack的方法C ——背景3
4. 前三条是我们的准备条件,接下来A的对象调用B的方法C
5. 然后class B就可以在C方法中调用A的方法D
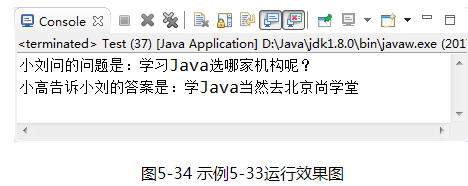
这样说大家可能还是不太理解,下面我们根据示例5-33来说明回调机制。该示例的生活背景为:有一天小刘遇到一个很难的问题“学习Java选哪家机构呢?”,于是就打电话问小高,小高一时也不太了解行情,就跟小刘说,我现在还有事,等忙完了给你咨询咨询,小刘也不会傻傻的拿着电话去等小高的答案,于是小刘对小高说,先挂电话吧,你知道答案后再打我电话告诉我吧,于是挂了电话。小高先去办自己的事情去了,过了几个小时,小高打电话给小刘,告诉他答案是“学Java当然去北京尚学堂”。
【示例5-33】回调机制示例
/**
* 回调接口
*/
interface CallBack {
/**
* 小高知道答案后告诉小刘时需要调用的方法,即回调方法
* @param result 是问题的答案
*/
public void answer(String result);
}
/**
* 小刘类:实现了回调接口CallBack(背景一)
*/
class Liu implements CallBack {
/**
* 包含小高对象的引用 (背景二)
*/
private Gao gao;
public Liu(Gao gao){
this.gao = gao;
}
/**
* 小刘通过这个方法去问小高
* @param question 小刘问的问题“学习Java选哪家机构呢?”
*/
public void askQuestion(String question){
//小刘问小高问题
gao.execute(Liu.this, question);
}
/**
* 小高知道答案后调用此方法告诉小刘
*/
@Override
public void answer(String result) {
System.out.println("小高告诉小刘的答案是:" + result);
}
}
/**
* 小高类
*/
class Gao {
/**
* 相当于class B有一个参数为CallBack的方法C(背景三)
*/
public void execute(CallBack callBack, String question){
System.out.println("小刘问的问题是:" + question);
//模拟小高挂点后先办自己的事情花了很长时间
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//小高办完自己的事情后想到了答案
String result = "学Java当然去北京尚学堂";
//小高打电话把答案告诉小刘,相当于class B 反过来调用class A 的D方法
callBack.answer(result);
}
}
public class Test {
public static void main(String[] args) {
Gao gao= new Gao();
Liu liu = new Liu(gao);
//小刘问问题
liu.askQuestion("学习Java选哪家机构呢?");
}
}
执行结果如图5-34所示:
通过回调在接口中定义的方法,调用到具体的实现类中的方法,其本质是利用Java的动态绑定技术,在这种实现中,可以不把实现类写成单独的类,而使用内部类或匿名内部类来实现回调方法。
5.12.3 组合模式
组合模式是将对象组合成树形结构以表示“部分-整体”的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。
【示例5-34】对象的组合
class Cpu {
public void run() {
System.out.println("quickly.........");
}
}
class MainBoard {
public void connect() {
System.out.println("connect...........");
}
}
class Memory {
public void store() {
System.out.println("store........");
}
}
public class Computer {
Cpu cpu;
Memory memory;
MainBoard mainBoard;
public void work() {
cpu.run();
memory.store();
mainBoard.connect();
}
public static void main(String[] args) {
Computer computer = new Computer();
computer.cpu = new Cpu();
computer.mainBoard = new MainBoard();
computer.memory = new Memory();
computer.work();
}
}
执行结果如图5-36所示:
总结
· 高级语言可分为:面向过程和面向对象两大类
1.面向过程与面向对象都是解决问题的思维方式,都是代码组织的方式。
2.解决简单问题可以使用面向过程。
3.解决复杂问题:宏观上使用面向对象把握,微观处理上仍然是面向过程。
· 对象和类的关系是特殊到一般,具体到抽象的关系。
· 栈内存
1.每个线程私有,不能实现线程间的共享!
2.局部变量放置于栈中。
3.栈是由系统自动分配,速度快!栈是一个连续的内存空间!
· 堆内存
1.放置new出来的对象!
2.堆是一个不连续的内存空间,分配灵活,速度慢!
· 方法区
1.被所有线程共享!
2.用来存放程序中永远是不变或唯一的内容(类代码信息、静态变量、字符串常量)。
· 属性用于定义该类或该类对象包含的数据或者说静态属性。属性作用范围是整个类体。Java使用默认的值对其初始化。
· 方法则用于定义该类或该类实例的行为特征和功能实现。方法是类和对象行为特征的抽象。
· 构造器又叫做构造方法(constructor),用于构造该类的实例。Java通过new关键字来调用构造方法,从而返回该类的实例,是一种特殊的方法。
· 垃圾回收机制
1.程序员无权调用垃圾回收器。
2.程序员可以通过System.gc()通知垃圾回收器(Garbage Collection,简称GC)运行,但是Java规范并不能保证立刻运行。
3.finalize方法,是Java提供给程序员用来释放对象或资源的方法,但是尽量少用。
· 方法的重载是指一个类中可以定义有相同的名字,但参数不同的多个方法。 调用时,会根据不同的参数表选择对应的方法。
· this关键字的作用
1.让类中的一个方法,访问该类的另一个方法或属性。
2.使用this关键字调用重载构造方法,可以避免相同的初始化代码,只能在构造方法中用,并且必须位于构造方法的第一句。
· static关键字
1.在类中,用static声明的成员变量为静态成员变量,也称为类变量。
2.用static声明的方法为静态方法。
3.可以通过对象引用或类名(不需要实例化)访问静态成员。
· package的作用
1.可以解决类之间的重名问题。
2.便于管理类:合适的类位于合适的包!
· impport的作用
1.通过import可以导入其他包下面的类,从而可以在本类中直接通过类名来调用。
· super关键字的作用
1.super是直接父类对象的引用。可以通过super来访问父类中被子类覆盖的方法或属性。
· 面向对象的三大特征:继承、封装、多态。
· Object类是所有Java类的根基类。
· 访问权限控制符:范围由小到大分别是private、default、protected、public。
· 引用变量名 instanceof 类名 来判断该引用类型变量所“指向”的对象是否属于该类或该类的子类。
· final关键字可以修饰变量、修饰方法、修饰类。
· 抽象类是一种模版模式。抽象类为所有子类提供了一个通用模版,子类可以在这个模版基础上进行扩展,使用abstract修饰。
· 使用abstract修饰的方法为抽象方法必须被子类实现,除非子类也是抽象类。
· 使用interface声明接口
1.从接口的实现者角度看,接口定义了可以向外部提供的服务。
2.从接口的调用者角度看,接口定义了实现者能提供哪些服务。
· 内部类分为成员内部类、匿名内部类和局部内部类。
· String位于java.lang包中,Java程序默认导入java.lang包。
· 字符串的比较"=="与equals()方法的区别。
第七章 数组
7.1数组概述和特点
数组是相同类型数据的有序集合。(有序指的就是它的下标)
数组描述的是相同类型的若干个数据,按照一定的先后次序排列组合而成。其中,每一个数据称作一个元素,每个元素可以通过一个索引(下标)来访问它们。
数组的三个基本特点:
1.长度是确定的。数组一旦被创建,它的大小就是不可以改变的。
2. 其元素必须是相同类型,不允许出现混合类型。
3.数组类型可以是任何数据类型,包括基本类型和引用类型。
老鸟建议
数组变量属引用类型,数组也可以看成是对象,数组中的每个元素相当于该对象的成员变量。数组本身就是对象,Java中对象是在堆中的,因此数组无论保存原始类型还是其他对象类型,数组对象本身是在堆中存储的。
7.2.1 数组声明
【示例7-1】数组的声明方式有两种(以一维数组为例)
type[] arr_name; //(推荐使用这种方式)
type arr_name[];
如:
//数组的声明
int[] arr01;或int arr01[];
String[] arr02;或String arr02[];
User[] arr03;或User arr03[];
//实例化数组对象
arr01=new int[10];
arr02=new String[5];
arr03=new User[3];
//给数组元素赋值,一个个赋值或者采用循环赋值
arr01[0]=13;
arr01[1]=15;
arr01[2]=20;
//arr01[100]=20;虽然编译通过了,但是会报错下标越界
for(int i=0;i注意事项
1.声明的时候并没有实例化任何对象,只有在实例化数组对象时,JVM才分配空间,这时才与长度有关。
2.声明一个数组的时候并没有数组真正被创建。
3.构造一个数组,必须指定长度。
【示例7-2】创建基本类型一维数组
public class Test {
public static void main(String args[]) {
int[] s = null; // 声明数组;
s = new int[10]; // 给数组分配空间;
for (int i = 0; i < 10; i++) {
s[i] = 2 * i + 1;//给数组元素赋值;
System.out.println(s[i]);
}
}
}

int[] s = null; // 声明数组;栈里面有了一个s,但是堆里面什么都没有
s = new int[10]; // 给数组分配空间;在堆里分配空间,创造出一个数组对象,每个元素可以看做是对象的成员变量,所以执行完这一步是,里面的int元素都是0
for (int i = 0; i < 10; i++) {
s[i] = 2 * i + 1;//给数组元素赋值;通过索引下标来赋值
System.out.println(s[i]);
}
【示例7-3】创建引用类型一维数组
class Man{
private int age;
private int id;
public Man(int id,int age) {
super();
this.age = age;
this.id = id;
}
}
public class AppMain {
public static void main(String[] args) {
Man[] mans; //声明引用类型数组;
mans = new Man[10]; //给引用类型数组分配空间;
Man m1 = new Man(1,11);
Man m2 = new Man(2,22);
mans[0]=m1;//给引用类型数组元素赋值;
mans[1]=m2;//给引用类型数组元素赋值;
}
}
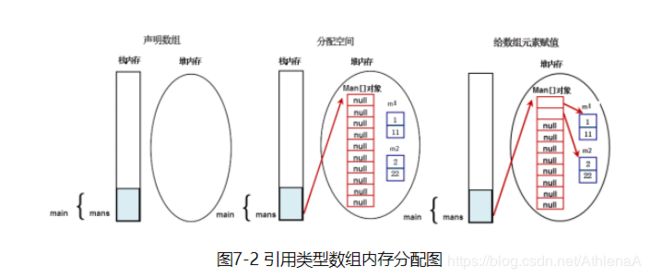
声明完mans对象数组后,会在堆内存中有一个列表。然后每个列表中都创建一个新的对象,指向新对象的地址。 而不是把每个对象直接放到里面。

存的是引用类型,也就是我们新对象的地址,并不是把对象直接放到里面,
7.2.2初始化
数组的初始化方式总共有三种:静态初始化、动态初始化、默认初始化。下面针对这三种方式分别讲解。
1.静态初始化
除了用new关键字来产生数组以外,还可以直接在定义数组的同时就为数组元素分配空间并赋值。
【示例7-4】静态初始化数组
int[] a = { 1, 2, 3 };// 静态初始化基本类型数组;
Man[] mans = { new Man(1, 1), new Man(2, 2) };// 静态初始化引用类型数组;
2.动态初始化
数组定义与为数组元素分配空间并赋值的操作分开进行。
【示例7-5】动态初始化数组
int[] a1 = new int[2];//动态初始化数组,先分配空间;
a1[0]=1;//给数组元素赋值;
a1[1]=2;//给数组元素赋值;
3.数组的默认初始化
数组是引用类型,它的元素相当于类的实例变量,因此数组一经分配空间,其中的每个元素也被按照实例变量同样的方式被隐式初始化。
【示例7-6】数组的默认初始化
int a2[] = new int[2]; // 默认值:0,0
boolean[] b = new boolean[2]; // 默认值:false,false
String[] s = new String[2]; // 默认值:null, null
7.3.1 数组的遍历
数组元素下标的合法区间:[0, length-1]。我们可以通过下标来遍历数组中的元素,遍历时可以读取元素的值或者修改元素的值。
【示例7-7】 使用循环遍历初始化和读取数组
public class Test {
public static void main(String[] args) {
int[] a = new int[4];
//初始化数组元素的值
for(int i=0;i执行结果如图7-3所示:
7.3.2 for-each循环
增强for循环for-each是JDK1.5新增加的功能,专门用于读取数组或集合中所有的元素,即对数组进行遍历。
【示例7-8】增强for循环
public class Test {
public static void main(String[] args) {
String[] ss = { "aa", "bbb", "ccc", "ddd" };//静态初始化
//foreach循环用于读取数组元素的值。因为没有下标,不能修改元素的值
for (String temp : ss) {
System.out.println(temp);
}
}
}
执行结果如图7-4所示:
注意事项
1.for-each增强for循环在遍历数组过程中不能修改数组中某元素的值。
2.for-each仅适用于遍历,不涉及有关索引(下标)的操作。
7.3.3数组的拷贝
System类里也包含了一个
static void arraycopy(object src,int srcpos,object dest, int destpos,int length)
方法,该方法可以将src数组里的元素值赋给dest数组的元素,其中srcpos指定从src数组的第几个元素开始赋值,length参数指定将src数组的多少个元素赋给dest数组的元素。
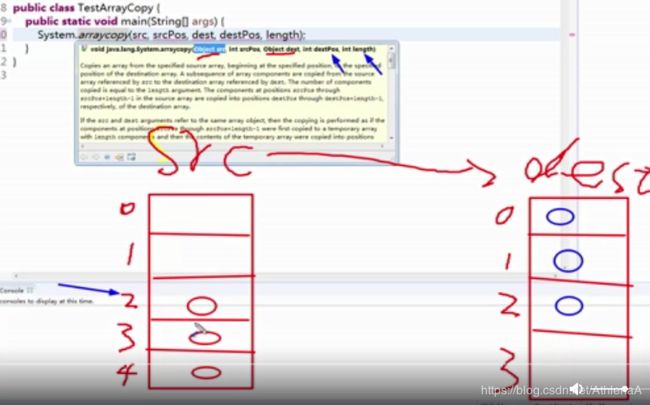
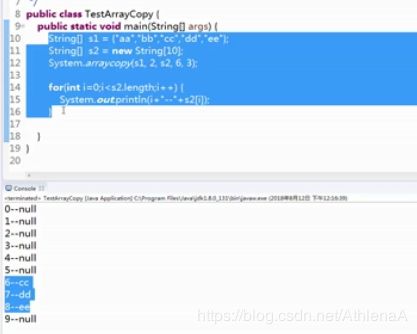
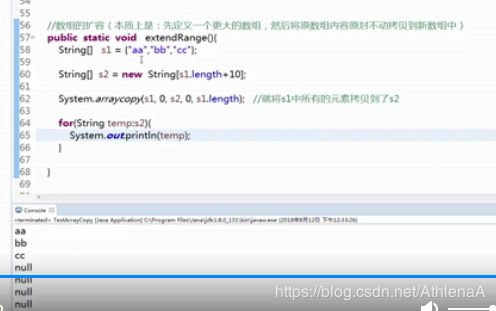
【示例7-9】数组拷贝
public class Test {
public static void main(String args[]) {
String[] s = {"阿里","尚学堂","京东","搜狐","网易"};
String[] sBak = new String[6];
System.arraycopy(s,0,sBak,0,s.length);
for (int i = 0; i < sBak.length; i++) {
System.out.print(sBak[i]+ "\t");
}
}
}
执行结果如图7-5所示:

例:
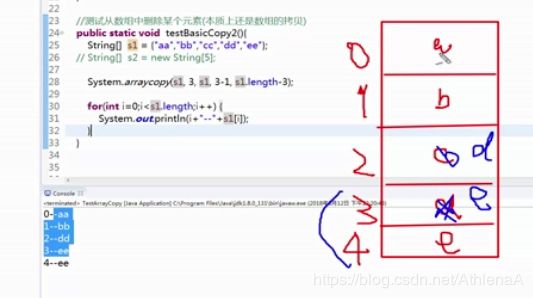
数组的拷贝——插入和删除元素的本质
例:
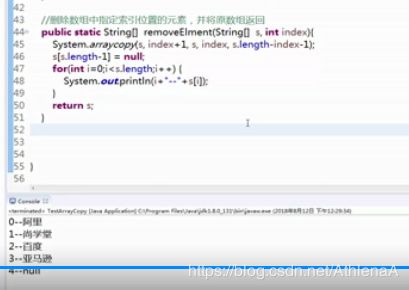
例:
例:数组扩容
例:数组插入
7.3.4 java.util.Arrays类
JDK提供的java.util.Arrays类,包含了常用的数组操作,方便我们日常开发。Arrays类包含了:排序、查找、填充、打印内容等常见的操作。
1打印内容
【示例7-10】打印数组
import java.util.Arrays;
public class Test {
public static void main(String args[]) {
int[] a = { 1, 2 };
System.out.println(a); // 打印数组引用的值;
System.out.println(Arrays.toString(a)); // 打印数组元素的值;
}
}
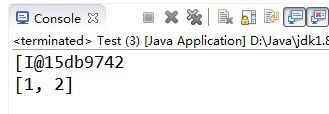
菜鸟雷区
此处的Arrays.toString()方法是Arrays类的静态方法,不是前面讲的Object的toString()方法。
2排序
【示例7-11】数组元素的排序
import java.util.Arrays;
public class Test {
public static void main(String args[]) {
int[] a = {1,2,323,23,543,12,59};
System.out.println(Arrays.toString(a));
Arrays.sort(a);
System.out.println(Arrays.toString(a));
}
}
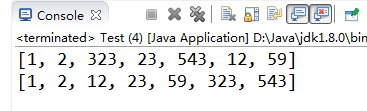
从小到大拍好了
对基本类型和字符串有排序功能
对于我们自己定义的类要排序的话,要实现Comparable 接口,然后在里面重写compareTo方法
【示例7-12】数组元素是引用类型的排序(Comparable接口的应用)
import java.util.Arrays;
public class Test {
public static void main(String[] args) {
Man[] msMans = { new Man(3, "a"), new Man(60, "b"), new Man(2, "c") };
Arrays.sort(msMans);
System.out.println(Arrays.toString(msMans));
}
}
class Man implements Comparable {
int age;
int id;
String name;
public Man(int age, String name) {
super();
this.age = age;
this.name = name;
}
public String toString() {
return this.name;
}
public int compareTo(Object o) {
Man man = (Man) o;
if (this.age < man.age) {
return -1;
}
if (this.age > man.age) {
return 1;
}
return 0;
}
}
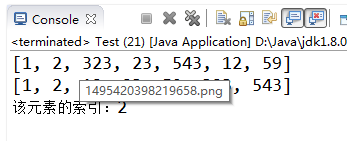
【示例7-13】二分法查找
import java.util.Arrays;
public class Test {
public static void main(String[] args) {
int[] a = {1,2,323,23,543,12,59};
System.out.println(Arrays.toString(a));
Arrays.sort(a); //使用二分法查找,必须先对数组进行排序;
System.out.println(Arrays.toString(a));
//返回排序后新的索引位置,若未找到返回负数。
System.out.println("该元素的索引:"+Arrays.binarySearch(a, 12));
}
}
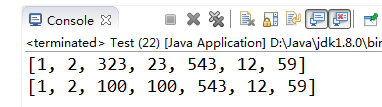
【示例7-14】数组填充
import java.util.Arrays;
public class Test {
public static void main(String[] args) {
int[] a= {1,2,323,23,543,12,59};
System.out.println(Arrays.toString(a));
Arrays.fill(a, 2, 4, 100); //将2到4索引的元素替换为100;
System.out.println(Arrays.toString(a));
}
}
7.4多维数组
多维数组可以看成以数组为元素的数组。可以有二维、三维、甚至更多维数组,但是实际开发中用的非常少。最多到二维数组(学习容器后,我们一般使用容器,二维数组用的都很少)。
二维数组也一样,因为我们前面说过:数组也是对象。
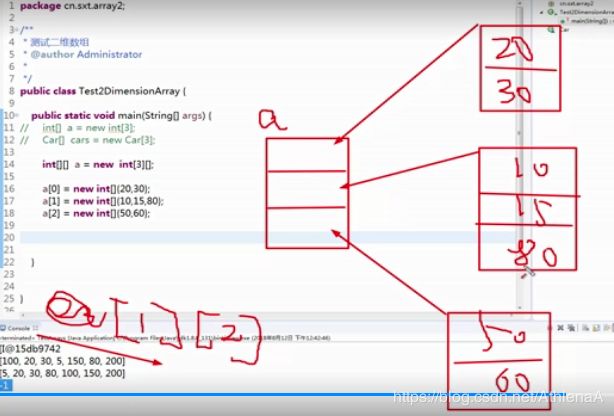
【示例7-15】二维数组的声明
public class Test {
public static void main(String[] args) {
// Java中多维数组的声明和初始化应按从低维到高维的顺序进行
int[][] a = new int[3][];
a[0] = new int[2];
a[1] = new int[4];
a[2] = new int[3];
// int a1[][]=new int[][4];//非法
}
}
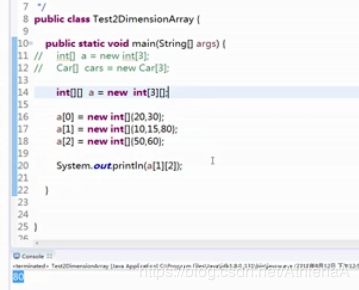
【示例7-16】二维数组的静态初始化
public class Test {
public static void main(String[] args) {
int[][] a = { { 1, 2, 3 }, { 3, 4 }, { 3, 5, 6, 7 } };
System.out.println(a[2][3]);
}
}
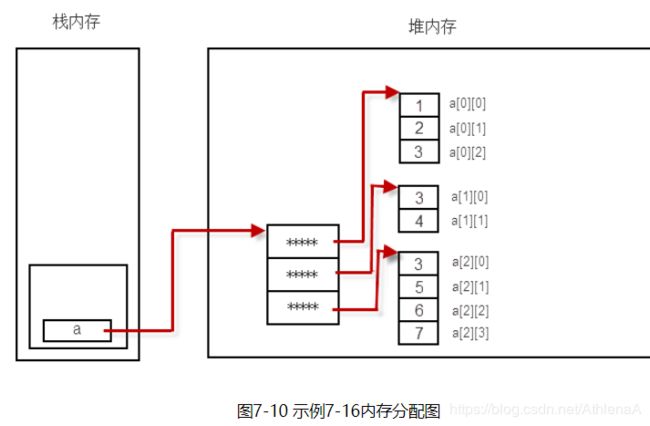
【示例7-17】二维数组的动态初始化
import java.util.Arrays;
public class Test {
public static void main(String[] args) {
int[][] a = new int[3][];
// a[0] = {1,2,5}; //错误,没有声明类型就初始化
a[0] = new int[] { 1, 2 };
a[1] = new int[] { 2, 2 };
a[2] = new int[] { 2, 2, 3, 4 };
System.out.println(a[2][3]);
System.out.println(Arrays.toString(a[0]));
System.out.println(Arrays.toString(a[1]));
System.out.println(Arrays.toString(a[2]));
}
}
执行结果如图7-11所示:
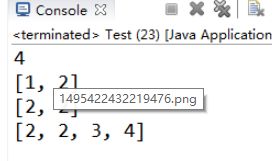
【示例7-18】获取数组长度
//获取的二维数组第一维数组的长度。
System.out.println(a.length);
//获取第二维第一个数组长度。
System.out.println(a[0].length);
7.5 数组存储表格数据
表格数据模型是计算机世界最普遍的模型,可以这么说,大家在互联网上看到的所有数据本质上都是“表格”,无非是表格之间互相套用。如下表格是一张雇员表:
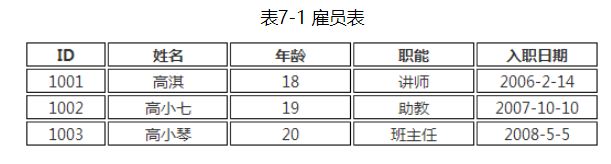
我们观察表格,发现每一行可以使用一个一维数组存储:
Object[] a1 = {1001,"高淇",18,"讲师","2006-2-14"};
Object[] a2 = {1002,"高小七",19,"助教","2007-10-10"};
Object[] a3 = {1003,"高小琴",20,"班主任","2008-5-5"};
注意事项
此处基本数据类型”1001”,本质不是Object对象。JAVA编译器会自动把基本数据类型“自动装箱”成包装类对象。大家在下一章学了包装类后就懂了。
这样我们只需要再定义一个二维数组,将上面3个数组放入即可:
Object[][] emps = new Object[3][];
emps[0] = a1;
emps[1] = a2;
emps[2] = a3;
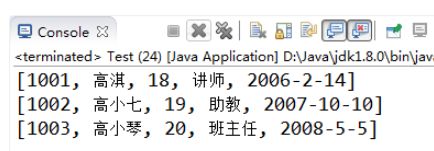
【示例7-19】 二维数组保存表格数据
import java.util.Arrays;
public class Test {
public static void main(String[] args) {
Object[] a1 = {1001,"高淇",18,"讲师","2006-2-14"};
Object[] a2 = {1002,"高小七",19,"助教","2007-10-10"};
Object[] a3 = {1003,"高小琴",20,"班主任","2008-5-5"};
Object[][] emps = new Object[3][];
emps[0] = a1;
emps[1] = a2;
emps[2] = a3;
System.out.println(Arrays.toString(emps[0]));
System.out.println(Arrays.toString(emps[1]));
System.out.println(Arrays.toString(emps[2]));
}
}
执行结果如图7-12所示:
7.6.1 冒泡排序的基础算法
冒泡排序是最常用的排序算法,在笔试中也非常常见,能手写出冒泡排序算法可以说是基本的素养。
算法重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来,这样越大的元素会经由交换慢慢“浮”到数列的顶端。
冒泡排序算法的运作如下:
1.比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
3.针对所有的元素重复以上的步骤,除了最后一个。
4.持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。

第一趟,把9找出来
则我们需要外面套个循环,让它循环length-1次
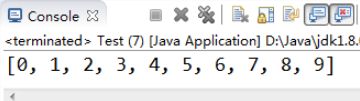
【示例7-20】冒泡排序的基础算法
import java.util.Arrays;
public class Test {
public static void main(String[] args) {
int[] values = { 3, 1, 6, 2, 9, 0, 7, 4, 5, 8 };
bubbleSort(values);
System.out.println(Arrays.toString(values));
}
public static void bubbleSort(int[] values) {
int temp;
for (int i = 0; i < values.length; i++) {
for (int j = 0; j < values.length - 1 - i; j++) {
if (values[j] > values[j + 1]) {
temp = values[j];
values[j] = values[j + 1];
values[j + 1] = temp;
}
}
}
}
}
执行结果如图7-14所示:
7.6.2 冒泡排序的优化算法
其实,我们可以把7.6.1的冒泡排序的算法优化一下,基于冒泡排序的以下特点:
1.整个数列分成两部分:前面是无序数列,后面是有序数列。
2.初始状态下,整个数列都是无序的,有序数列是空。
3.每一趟循环可以让无序数列中最大数排到最后,(也就是说有序数列的元素个数增加1),也就是不用再去顾及有序序列。
4.每一趟循环都从数列的第一个元素开始进行比较,依次比较相邻的两个元素,比较到无序数列的末尾即可(而不是数列的末尾);如果前一个大于后一个,交换。
5.判断每一趟是否发生了数组元素的交换,如果没有发生,则说明此时数组已经有序,无需再进行后续趟数的比较了。此时可以中止比较。
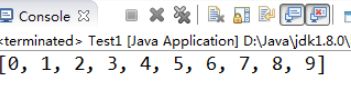
【示例7-21】冒泡排序的优化算法
import java.util.Arrays;
public class Test1 {
public static void main(String[] args) {
int[] values = { 3, 1, 6, 2, 9, 0, 7, 4, 5, 8 };
bubbleSort(values);
System.out.println(Arrays.toString(values));
}
public static void bubbleSort(int[] values) {
int temp;
int i;
// 外层循环:n个元素排序,则至多需要n-1趟循环
for (i = 0; i < values.length - 1; i++) {
// 定义一个布尔类型的变量,标记数组是否已达到有序状态
boolean flag = true;
/*内层循环:每一趟循环都从数列的前两个元素开始进行比较,比较到无序数组的最后*/
for (int j = 0; j < values.length - 1 - i; j++) {
// 如果前一个元素大于后一个元素,则交换两元素的值;
if (values[j] > values[j + 1]) {
temp = values[j];
values[j] = values[j + 1];
values[j + 1] = temp;
//本趟发生了交换,表明该数组在本趟处于无序状态,需要继续比较;
flag = false;
}
}
//根据标记量的值判断数组是否有序,如果有序,则退出;无序,则继续循环。
if (flag) {
break;
}
}
}
}
执行结果如图7-15所示:
7.7 二分法查找
二分法检索(binary search)又称折半检索,二分法检索的基本思想是设数组中的元素从小到大有序地存放在数组(array)中,首先将给定值key与数组中间位置上元素的关键码(key)比较,如果相等,则检索成功;
否则,若key小,则在数组前半部分中继续进行二分法检索;
若key大,则在数组后半部分中继续进行二分法检索。
这样,经过一次比较就缩小一半的检索区间,如此进行下去,直到检索成功或检索失败。
二分法检索是一种效率较高的检索方法。比如,我们要在数组[7, 8, 9, 10, 12, 20, 30, 40, 50, 80, 100]中查询到10元素,过程如下:
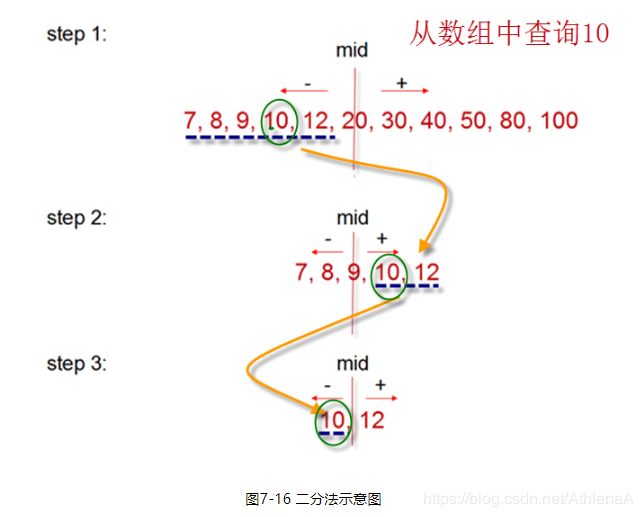
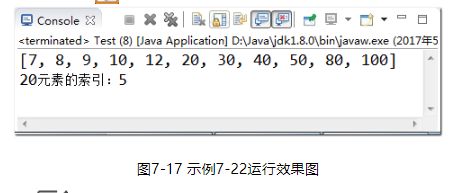
【示例7-22】二分法查找
import java.util.Arrays;
public class Test {
public static void main(String[] args) {
int[] arr = { 30,20,50,10,80,9,7,12,100,40,8};
int searchWord = 20; // 所要查找的数
Arrays.sort(arr); //二分法查找之前,一定要对数组元素排序
System.out.println(Arrays.toString(arr));
System.out.println(searchWord+"元素的索引:"+binarySearch(arr,searchWord));
}
public static int binarySearch(int[] array, int value){
int low = 0;
int high = array.length - 1;
while(low <= high){
int middle = (low + high) / 2;
if(value == array[middle]){
return middle; //返回查询到的索引位置
}
if(value > array[middle]){
low = middle + 1;
}
if(value < array[middle]){
high = middle - 1;
}
}
return -1; //上面循环完毕,说明未找到,返回-1
}
}
执行结果如图7-17所示: