简历准备(一)—— 科大讯飞 (CV方向)
文章目录
- `项目一: 目标跟踪`
- SiameRPN
- VGG16
- RPN
- This
- EAO
- VOT简介
- Accuracy
- Robustness
- VOT2013
- VOT2014
- VOT2015
- VOT2016
- `项目二: UAV-DET`
- RetinaNet
- RetinaHead
- MobileNet/ShuffleNet
- Attention in CNN
- CBAM
- Non-global
- 平衡
- FPN-BFP (Libra-RCNN)
- Loss改进
- 多尺度训练/测试
- `项目三:防抖`
- 图像特征
- HOG/fHOG特征
- HOG
- fHOG
- 特征点检测/描述
- sift
- 高斯图像金字塔
- 空间极值点检测
- 关键点方向分配
- 关键点特征描述
- surf (Speeded Up Robust Features)
- Hessian检测
- SURF的尺度空间
- 兴趣点主方向获得
- SURF描述子
- 快速索引匹配
- 光流
- 运动模型
- 变换矩阵
- RANSAC
- 滤波
- 卡尔曼滤波
- 项目简化的KL
项目一: 目标跟踪
SiameRPN
VGG16
RPN
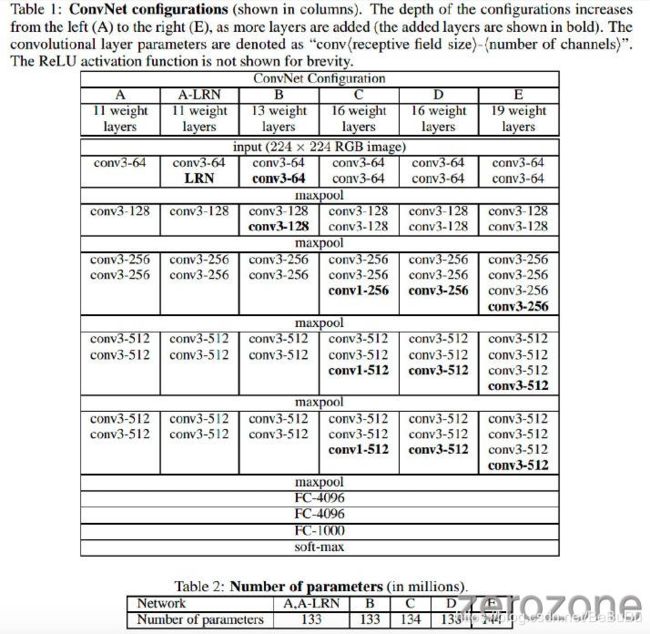
- RPN 主要是通过在 BackBone 网络输出的特征图谱上设置一组固定大小的
anchor boxes实现. - 对于图谱上的每一个像素点, 都会枚举 k k k 个具有预设尺寸的 anchor boxes. 对于一个 W × H W×H W×H 大小的特征图谱, 总共会产生 W H k WHk WHk个 anchor boxes. 对于每一个 anchor box, 我们需要预测 (4+2) 个值,代表 location 偏移量和是否包含物体的二分类预测(正负样本,类别位置)


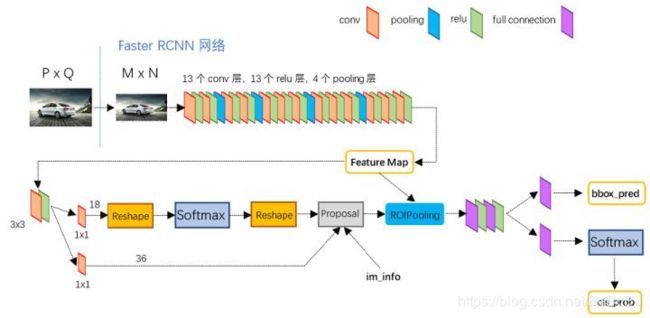
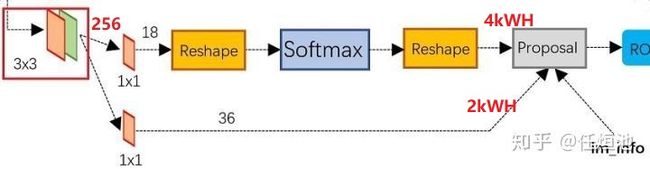
- RPN分为两条线,分别进行正负样本分类和边框回归
- 上面一条线:① 使用 3 × 3 3×3 3×3的filter对feature map进行卷积,目的是使提取出来的feature更鲁棒;② 使用 3 × 3 3×3 3×3的filter对feature map进行卷积,目的是使提取出来的feature更鲁棒;③ 使用 1 × 1 1×1 1×1的filter进行卷积,一共为18个;④ reshape操作 ( W , H , D = 18 ) (W,H,D=18) (W,H,D=18)reshape成 ( 2 , 9 × W × H ) (2,9×W×H) (2,9×W×H);⑤ 然后我们进行softmax,得出对这 9 × W × H 9×W×H 9×W×H每一个的两个score,一个是有物体,一个是没有物体。PS:9个Anchor!
This

- 在RPN的分类分支中,模板图像和检测图像的feature map,都将首先通过一个卷积层,该卷积层主要是对模板图像的feature map进行channel上的升维,令其维度变为检测图像的feature map的维度的2k倍(k为RPN中设定的anchor数)。此后,将模板图像的feature map在channel上按序等分为2k份,作为2k个卷积核,在检测图像的feature map完成卷积操作,得到一个维度为2k的score map。该score map同样在channel上按序等分为k份,得到对应k个anchor的k个维度为2的score map,两个维度分别对应anchor中前景(目标)和后景(背景)的分类分数,是关于目标的置信度。
- 在RPN的回归分支中,模板图像和检测图像的feature map,都将首先通过一个卷积层,该卷积层主要是对模板图像的feature map进行channel上的升维,令其维度变为检测图像的feature map的维度的4k倍(k为RPN中设定的anchor数)。此后,将模板图像的feature map在channel上按序等分为4k份,作为4k个卷积核,在检测图像的feature map完成卷积操作,得到一个维度为4k的score map。该score map同样在channel上按序等分为k份,得到对应k个anchor的k个维度为4的score map,四个维度分别对应anchor的(x,y,w,h),是关于目标的坐标及尺寸。
EAO
VOT简介
- 相机移动(camera motion,即抖动模糊)
- 光照变化(illumination change)
- 目标尺寸变化(object size change)
- 目标动作变化(object motion change,和相机抖动表现形式类似,都是-模糊)
- 未退化(non-degraded)。
Accuracy
- 借鉴IoU定义,精度为:
ϕ t = A t G ∩ A t T A t G ∪ A t T \phi_{t}=\frac{A_{t}^{G} \cap A_{t}^{T}}{A_{t}^{G} \cup A_{t}^{T}} ϕt=AtG∪AtTAtG∩AtT - 其中 A t G A_{t}^{G} AtG 代表第t帧 ground truth对应的bounding box, A t T A_{t}^{T} AtT 代表第t帧tracker预测的bounding box!
- 重复N次,第t帧上跟踪器的精确度:
Φ t ( i ) = 1 N r e p ∑ i = 1 N r e p Φ t ( i , k ) \Phi_{t}(i)=\frac{1}{N_{r e p}} \sum_{i=1}^{N_{r e p}} \Phi_{t}(i, k) Φt(i)=Nrep1i=1∑NrepΦt(i,k) - 更详细一些, 定义 Φ t ( i , k ) \Phi_{t}(i, k) Φt(i,k) 为第 i i i 个tracker在第 k k k 次重复(repetition, tracker会在一个序列上重复跑多次) 中在第 t t t 帧上的accuracy。设重复次数为 N r e p , N_{r e p}, Nrep,
- 第i个tracker的average accuracy定义为:
ρ A ( i ) = 1 N valid ∑ t = 1 N valid Φ t ( i ) \rho_{A}(i)=\frac{1}{N_{\text {valid}}} \sum_{t=1}^{N_{\text {valid}}} \Phi_{t}(i) ρA(i)=Nvalid1t=1∑NvalidΦt(i) - 其中 N v a l i d N_{v a l i d} Nvalid 代表有效帧 (valid frames) 的数量!
Robustness
- 用来评价tracker跟踪目标的稳定性,数值越大,稳定性越差
- 第i个tracker的average robustness:
ρ R ( i ) = 1 N r e p ∑ k = 1 N r e p F ( i , k ) \rho_{R}(i)=\frac{1}{N_{r e p}} \sum_{k=1}^{N_{r e p}} F(i, k) ρR(i)=Nrep1k=1∑NrepF(i,k) - 定义 F ( i , k ) F(i, k) F(i,k) 为第 i i i 个tracker在第 k k k 次重复中 f a i l u r e failure failure的次数!
VOT2013
- 6大属性!左上和右下角的点坐标!
- A和R分别排名,再平均得到综合排名,AR-rank:首先让tracker在同一属性的序列下测试,对得到的数据(average accuracy/average robustness)进行加权平均,每个数据的权重为对应序列的长度,由此得到单个tracker在该属性序列上的数据,然后对不同tracker在该属性序列下进行排名。得到单个tracker在所有属性序列下的排名后,求其平均数(不加权)得到AR rank。
- equivalent tracker的概念——accuracy和robustness可以利用非参数检验来验证两个tracker之间的评价是否存在显著差异。TODO!!!
VOT2014
- EFO(Equivalent Filter Operations ),衡量tracking速度的新单位,先会测量在一个600600的灰度图像上用3030最大值滤波器进行滤波的时间,以此得出一个基准单位,再以这个基础单位衡量tracker的速度,以此减少硬件平台和编程语言等外在因素对tracker速度的影响
- 衡量equivalence的另一种机制——practical difference TODO!!!
VOT2015
- VOT2015提出,基于AR rank的评价方式没有充分利用accuracy和robustness的原始数据(raw data),所以创造了一个新的评价指标 —— EAO(Expected Average Overlap)。正如字面意思,这个评价指标只针对基于overlap定义的accuracy

- AR rank的新表示方法 TODO!!!
- 重新定义的Robustness还可以叫做reliability,可以解释为“上一次跟踪失败后能够持续跟踪SSS帧的概率” R S = e − S M R_{S}=e^{-S M} RS=e−SM ,M是原始值,S自定义的值
VOT2016
- VOT2016相比VOT2015变化不大,评价指标上,从OTB(另外一个测试平台,开头提到过)引入了AO(Average Overlap),与EAO的不同之处也仅在于AO没有VOT的重启机制。
项目二: UAV-DET
RetinaNet
RetinaHead
- 流程,assignment过程怎么样?
- 和YOLOHead/SSDHead区别
- 和FasterRCNNHead区别
MobileNet/ShuffleNet
Attention in CNN
CBAM
Non-global
平衡
FPN-BFP (Libra-RCNN)
- XXX
Loss改进
- Classifier: Focal Loss - Generalized Focal Loss
- Regression: Smooth L1 Loss - Balanced L1 Loss (Libra-RCNN)
多尺度训练/测试
项目三:防抖
图像特征
HOG/fHOG特征
HOG
- Gamma校正和灰度化
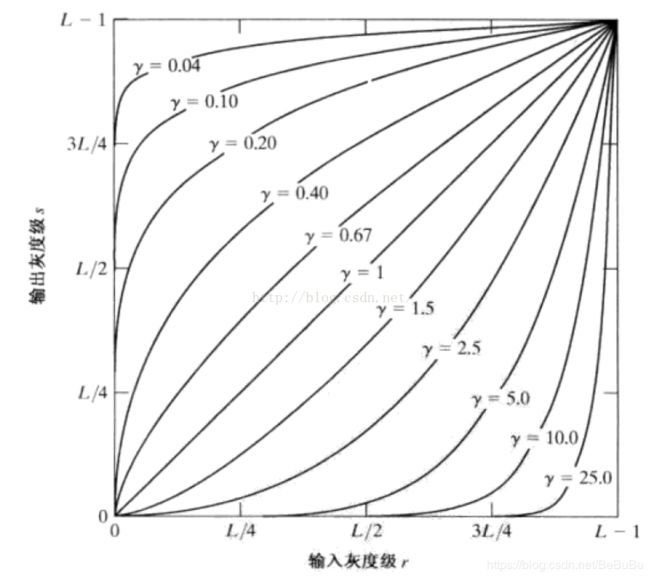
- 计算图像像素梯度图 (Sobel算子)
- 计算梯度直方图: 联合一个8×8的小格子内部一些像素,计算其梯度幅度和梯度方向的统计直方图,这样一来就可以以这个梯度直方图来代替原本庞大的矩阵。每个像素有一个梯度幅度和梯度方向两个取值,那么一个小格子一共有8×8×2=128个取值;[0,180]分为9组
- Block归一化:HOG在选取8×8为一个单元格的基础之上,再以2×2个单元格为一组,称为block。作者提出要对block进行归一化,由于每个单元cell有9个向量,2×2个单元格则有36个向量,需要对这36个向量进行归一化
- HOG特征描述:每一个16×16大小的block将会得到36大小的vector,一个64×128大小的图像,按照上图的方式提取block,将会有7个水平位置和15个竖直位可以取得,所以一共有7×15=105。图片HOG特征的总维度36×105=3780!
fHOG
- 建立像素级特征映射:计算梯度幅值和方向!可以使用对方向敏感 B1(0-360度)也可以使用对方向不敏感 B2(0-180度)
B 1 ( x , y ) = round ( p θ ( x , y ) 2 π ) m o d p B 2 ( x , y ) = round ( p θ ( x , y ) π ) m o d p \begin{array}{l} B_{1}(x, y)=\operatorname{round}\left(\frac{p \theta(x, y)}{2 \pi}\right) \bmod p \\ B_{2}(x, y)=\operatorname{round}\left(\frac{p \theta(x, y)}{\pi}\right) \bmod p \end{array} B1(x,y)=round(2πpθ(x,y))modpB2(x,y)=round(πpθ(x,y))modp - 空间聚合:增加36维!利用三线插值进行处理,这种处理也是合理的。能进一步较小混叠效应,通过插值可以使得每个像素对其周围的四个cell的特征向量产生贡献!
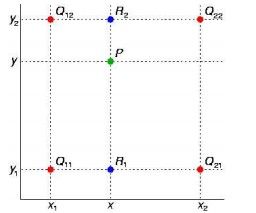
- 归一化和截断。四个归一化因子,考虑中间的cell5,绿色的四个方式!

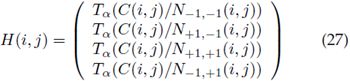
- FHOG PCA降维:作者经过实验,发现:(PCA)由前11个主特征向量定义的线性子空间基本包含了hog特征的所有信息,并且用降维之后的特征在他们的任务(目标检测)中取得了和用36维特征一样的结果。然后作者采用了另一种方法:13维特征有一个比较简单的解释,9个方向特征以及反映cell周围区域能量的四个特征。取得一样的结果!
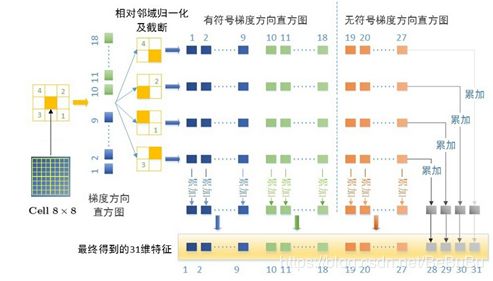
- 最终得到31维的特征向量:27个在不同归一化因子上的累加和(列和)以及4个在不同方向上的累加和(行和),27维中包含了27个bin通道,其中18个对方向敏感,9个对方向不敏感,4维分别捕获了当前cell周围4个cell组成的梯度能量。如上图所示!
特征点检测/描述
sift
static Ptr<SIFT> cv::SIFT::create ( int nfeatures = 0,
int nOctaveLayers = 3,
double contrastThreshold = 0.04,
double edgeThreshold = 10,
double sigma = 1.6
)
- 流程:
- 生成高斯金字塔,并由此生成差分高斯金字塔(DoG),该过程完成尺度空间的构建,以便后续的空间极值点检测。
- 稳定关键点的精确定位、去除不稳定特征点
- 稳定关键点信息分配
- 关键点匹配
高斯图像金字塔
- 高斯窗口 ( 6 σ + 1 ) 2 (6\sigma+1)^2 (6σ+1)2
- Tony Lindeberg指出尺度规范化的LoG(Laplacion of Gaussian)算子具有真正的尺度不变性,Lowe使用高斯差分金字塔近似LoG算子,在尺度空间检测稳定的关键点
- 尺度空间:高斯模糊 + 降采样
- 金字塔每层多张图像(Octave),金字塔每层只有一组图像,组数和金字塔层数相等,使用公式(3-3)计算,每组含有多张(也叫层Interval)图像
| 第0组(即第-1组) | 0 1 2 3 4 5 |
|---|---|
| 第1组 | 6 7 8 9 10 11 |
| 第2组 | 第一张图根据第一组中索引为9的图片降采样 |
空间极值点检测
- 每组需S+3层图像
- 由于要在相邻尺度进行比较
- 构建尺度空间需确定的参数: —尺度空间坐标 σ \sigma σ;O组(octave)数;S组内层数
σ ( o , s ) = σ 0 2 o + s S o ∈ [ 0 , … , O − 1 ] , s ∈ [ 0 , … , S + 2 ] \sigma(o, s)=\sigma_{0} 2^{o+\frac{s}{S}} o \in[0, \ldots, O-1], s \in[0, \ldots, S+2] σ(o,s)=σ02o+Sso∈[0,…,O−1],s∈[0,…,S+2]
- 关键点定位
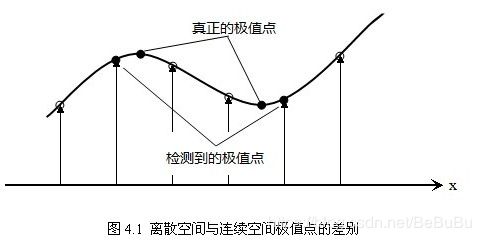
D ( X ) = D + ∂ D T ∂ X X + 1 2 X T ∂ 2 D ∂ X 2 X D(X)=D+\frac{\partial D^{T}}{\partial X} X+\frac{1}{2} X^{T} \frac{\partial^{2} D}{\partial X^{2}} X D(X)=D+∂X∂DTX+21XT∂X2∂2DX- 求导=0,得到极值点的偏移量: X ^ = − ∂ 2 D − 1 ∂ X 2 ∂ D ∂ X \hat{X}=-\frac{\partial^{2} D^{-1}}{\partial X^{2}} \frac{\partial D}{\partial X} X^=−∂X2∂2D−1∂X∂D
- 其中, X ^ = ( x , y , σ ) T \hat{X}=(x, y, \sigma)^{T} X^=(x,y,σ)T是相对于插值中心的偏移量!当大于0.5则代表需要改变点位置,反复插值迭代到收敛!(如5次)
- ∣ D ( x ) ∣ |D(x)| ∣D(x)∣小的点容易受噪声影响,将小于0.03的点删掉!
- 消除边缘响应
H = [ D x x D x y D x y D x y ] Tr ( H ) 2 Det ( H ) = ( α + β ) 2 α β = ( r β + β ) 2 r β 2 = ( r + 1 ) 2 r H=\left[\begin{array}{ll} D_{x x} & D_{x y} \\ D_{x y} & D_{x y} \end{array}\right] \\ \frac{\operatorname{Tr}(H)^{2}}{\operatorname{Det}(H)}=\frac{(\alpha+\beta)^{2}}{\alpha \beta}=\frac{(r \beta+\beta)^{2}}{r \beta^{2}}=\frac{(r+1)^{2}}{r} H=[DxxDxyDxyDxy]Det(H)Tr(H)2=αβ(α+β)2=rβ2(rβ+β)2=r(r+1)2- 取r=10,小于 1 1 2 / 10 11^2/10 112/10的点认为是边缘点,删掉!
关键点方向分配
- 对于在DOG金字塔中检测出的关键点点,采集其所在高斯金字塔图像 3 σ 3σ 3σ邻域窗口内像素的梯度和方向分布特征。
- 梯度模进行高斯加权, σ = 1.5 σ o c t \sigma=1.5 \sigma_{oct} σ=1.5σoct,按照 3 σ 3\sigma 3σ原则,窗口尺寸 4.5 σ o c t 4.5\sigma_{oct} 4.5σoct
- 梯度直方图将0~360度的方向范围分为36个柱(bins),其中每柱10度

- 以直方图中最大值作为该关键点的主方向。为了增强匹配的鲁棒性,只保留峰值大于主方向峰值80%的方向作为该关键点的辅方向
关键点特征描述
- 确定计算描述子所需的图像区域(4x4)
r a d i u s = 3 σ − o c t × 2 × ( d + 1 ) 2 r a d i u s=\frac{3 \sigma_{-} o c t \times \sqrt{2} \times(d+1)}{2} radius=23σ−oct×2×(d+1)

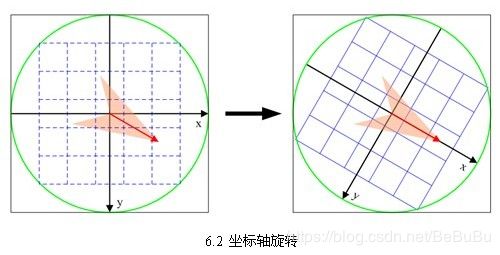
- 将坐标轴旋转为关键点的方向,以确保旋转不变性
( x ′ y ′ ) = ( cos θ − sin θ sin θ cos θ ) ( x y ) ( x , y ∈ [ − r a d i u s , r a d i u s ] ) ( x ′ ′ y ′ ′ ) = 1 3 σ − oct ( x ′ y ′ ) + d 2 \left(\begin{array}{l}x^{\prime} \\ y^{\prime}\end{array}\right)=\left(\begin{array}{cc}\cos \theta & -\sin \theta \\ \sin \theta & \cos \theta\end{array}\right)\left(\begin{array}{l}x \\ y\end{array}\right) \quad(x, y \in[-r a d i u s, r a d i u s]) \\ \left(\begin{array}{l}x^{\prime \prime} \\ y^{\prime \prime}\end{array}\right)=\frac{1}{3 \sigma_{-} \operatorname{oct}}\left(\begin{array}{l}x^{\prime} \\ y^{\prime}\end{array}\right)+\frac{d}{2} (x′y′)=(cosθsinθ−sinθcosθ)(xy)(x,y∈[−radius,radius])(x′′y′′)=3σ−oct1(x′y′)+2d
- 将邻域内的采样点分配到对应的子区域内,将子区域内的梯度值分配到8个方向上,计算其权值:owe建议子区域的像素的梯度大小按 σ = 0.5 d \sigma=0.5d σ=0.5d的高斯加权计算: w = m ( a + x , b + y ) e − ( x ′ ) 2 + ( y ′ ) 2 2 × ( 0.5 d ) 2 w=m(a+x, b+y) e^{-\frac{\left(x^{\prime}\right)^{2}+\left(y^{\prime}\right)^{2}}{2 \times(0.5 d)^{2}}} w=m(a+x,b+y)e−2×(0.5d)2(x′)2+(y′)2
- 插值计算每个种子点八个方向的梯度:双线性插值
weight = w ∗ d r k ∗ ( 1 − d r ) 1 − k ∗ d c m ∗ ( 1 − d c ) 1 − m ∗ d o n ∗ ( 1 − d o ) 1 − n =w^{*} d r^{k} *(1-d r)^{1-k} * d c^{m *}(1-d c)^{1-m} * d o^{n} *(1-d o)^{1-n} =w∗drk∗(1−dr)1−k∗dcm∗(1−dc)1−m∗don∗(1−do)1−n ;{0,1}
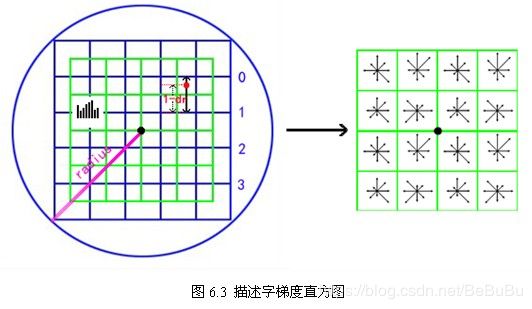
- 特征向量归一化处理:对4x4x8=128维向量进行归一化!
- 描述子向量门限:截断大于0.2的梯度值
- 按特征点的尺度对特征描述向量进行排序
- 缺点:实时性不高 + 特征点有时候小 + 边缘光滑无法准确提取特征点!
surf (Speeded Up Robust Features)
- cv::xfeatures2d::SURF
Hessian检测
H ( x , σ ) = [ L x x ( x , σ ) L x y ( x , σ ) L x y ( x , σ ) L y y ( x , σ ) ] \mathcal{H}(\mathbf{x}, \sigma)=\left[\begin{array}{ll} L_{x x}(\mathbf{x}, \sigma) & L_{x y}(\mathbf{x}, \sigma) \\ L_{x y}(\mathbf{x}, \sigma) & L_{y y}(\mathbf{x}, \sigma) \end{array}\right] H(x,σ)=[Lxx(x,σ)Lxy(x,σ)Lxy(x,σ)Lyy(x,σ)]
- L x x L_{xx} Lxx表示图像经过高斯二阶LoG卷积得到,离散化近似(盒函数):

- 那么就可以采用积分图像加速Hessian矩阵的计算!得到近似值 D x x D_{xx} Dxx等,计算指标: det ( H approx ) = D x x D y y − ( 0.9 D x y ) 2 \operatorname{det}\left(\mathcal{H}_{\text {approx }}\right)=D_{x x} D_{y y}-\left(0.9 D_{x y}\right)^{2} det(Happrox )=DxxDyy−(0.9Dxy)2,0.9是为了补偿近似的误差!
SURF的尺度空间
- SURF采用的盒函数+积分图,不需要不断的高斯模糊核子采样,而是采用不同尺寸的核函数+采用 来计算图像金字塔!
- 99,1515,2121,2727 二倍增大
- 左图是sift算法,其是图像大小减少,而模板不变(这里只是指每组间,组内层之间还是要变的)。而SURF算法(右图)刚好相反,其是图像大小不变,而模板大小扩大

兴趣点主方向获得
- SURF方法则是通过计算其在x,y方向上的haar-wavelet响应,这是在兴趣点周围一个6s半径大小的圆形区域内。当然小波变换的大小也同尺度参数s有关,其步长为s,其大小为4s

- 60度
SURF描述子
- SURF也是通过建立兴趣点附近区域内的信息来作为描述子的
- SURF首先在兴趣点附近建立一个20s大小的方形区域,为了获得旋转不变性,同sift算法一样,我们需要将其先旋转到主方向,然后再将方形区域划分成16个(44)子域。对每个子域(其大小为5s5s)我们计算25(5*5)个空间归一化的采样点的Haar小波响应dx和dy
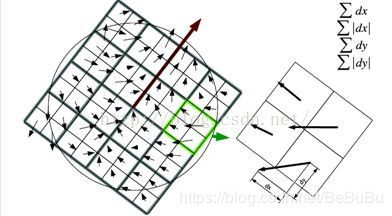
- 之后我们将每个子区域(共4*4)的dx,dy相加,因此每个区域都有一个描述子(如下式),为了增加鲁棒性,我们可以给描述子再添加高斯权重(尺度为3.3s,以兴趣点为中心)
- 所以最后在所有的16个子区域内的四位描述子结合,将得到该兴趣点的64位描述子

- 也建立128位的SURF描述子,其将原来小波的结果再细分,比如dx的和将根据dy的符号,分成了两类,所以此时每个子区域内都有8个分量,SURF-128有非常好效果
快速索引匹配
- 我们发现兴趣点其Laplacian(Hessian矩阵的迹)的符号(即正负)可以将区分相同对比形状的不同区域,如黑暗背景下的白斑和相反的情况。
- 只需要为其中一个建立描述子,而给另一个索引,而在匹配过程中,只要比较一个描述子,就能确定两个位置

光流
![]()

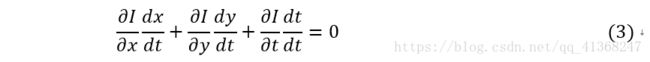
![]()
- 约束方程只有一个,而方程的未知量有两个,这种情况下无法求得u和v的确切值,基于梯度(微分)的方法、基于匹配的方法、基于能量(频率)的方法、基于相位的方法和神经动力学方法
- 基于梯度(微分)的方法:Lucas-Kanade(LK)算法(稀疏) / Horn-Schunck(81)算法;Farneback (03) (稠密):
- Farneback:Two-Frame Motion Estimation Based on PolynomialExpansion 2003
- Horn-Schunck:Determining optical flow 1981
- 稠密光流是一种针对图像或指定的某一片区域进行逐点匹配的图像配准方法,它计算图像上所有的点的偏移量,从而形成一个稠密的光流场。通过这个稠密的光流场,可以进行像素级别的图像配准;与稠密光流相反
- 稀疏光流并不对图像的每个像素点进行逐点计算。它通常需要指定一组点进行跟踪,这组点最好具有某种明显的特性,例如Harris角点等,那么跟踪就会相对稳定和可靠。稀疏跟踪的计算开销比稠密跟踪小得多。
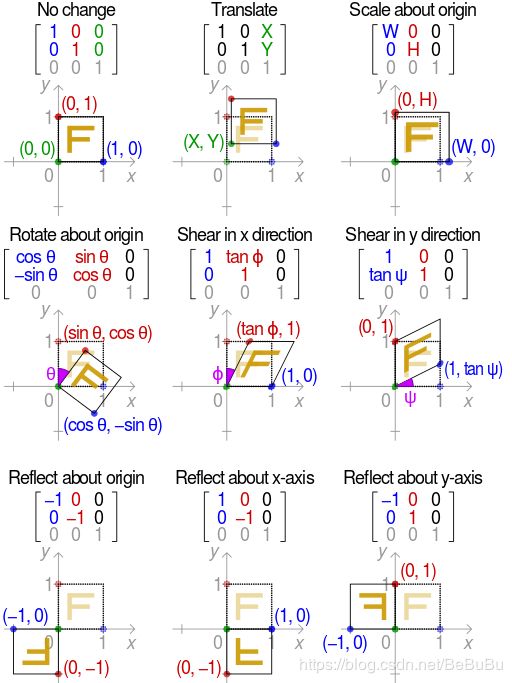
运动模型
变换矩阵
RANSAC
- RANSAC算法的基本假设是样本中包含正确数据(inliers,可以被模型描述的数据),也包含异常数据(outliers,偏离正常范围很远、无法适应数学模型的数据),即数据集中含有噪声。这些异常数据可能是由于错误的测量、错误的假设、错误的计算等产生的。同时RANSAC也假设,给定一组正确的数据,存在可以计算出符合这些数据的模型参数的方法。

- RANSAC的基本假设:
- ”内群”数据可以通过几组模型的参数来叙述其分别,而“离群”数据则是不适合模型化的数据
- 数据会受噪声影响,噪声指的是离群,例如从极端的噪声或错误解释有关数据的测量或不正确的假设
- RANSAC假定,给定一组(通常很小)的内群,存在一个程序,这个程序可以估算最佳解释或最适用于这一数据模型的参数
滤波
卡尔曼滤波
- Kalman滤波是一种线性滤波与预测方法
- A New Approach to Linear Filtering and Prediction Problems
- 分为两个步骤,预测(predict)和校正(correct)
- 预测是基于上一时刻状态估计当前时刻状态
- 校正是综合当前时刻的估计状态与观测状态,估计出最优的状态
- 预测:
x k = A x k − 1 + B u k − 1 P k = A P k − 1 A T + Q K k = P k H T ( H P k H T + R ) − 1 \begin{array}{l} x_{k}=A x_{k-1}+B u_{k-1} \\ P_{k}=A P_{k-1} A^{T}+Q \\ K_{k}=P_{k} H^{T}\left(H P_{k} H^{T}+R\right)^{-1} \\ \end{array} xk=Axk−1+Buk−1Pk=APk−1AT+QKk=PkHT(HPkHT+R)−1 - 校正:
x k = x k + K k ( z k − H x k ) P k = ( I − K k H ) P k \begin{array}{l} x_{k}=x_{k}+K_{k}\left(z_{k}-H x_{k}\right) \\ P_{k}=\left(I-K_{k} H\right) P_{k} \end{array} xk=xk+Kk(zk−Hxk)Pk=(I−KkH)Pk - 参数说明
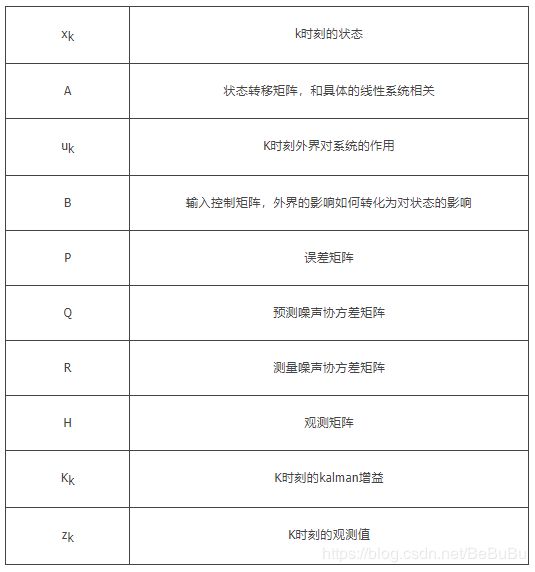
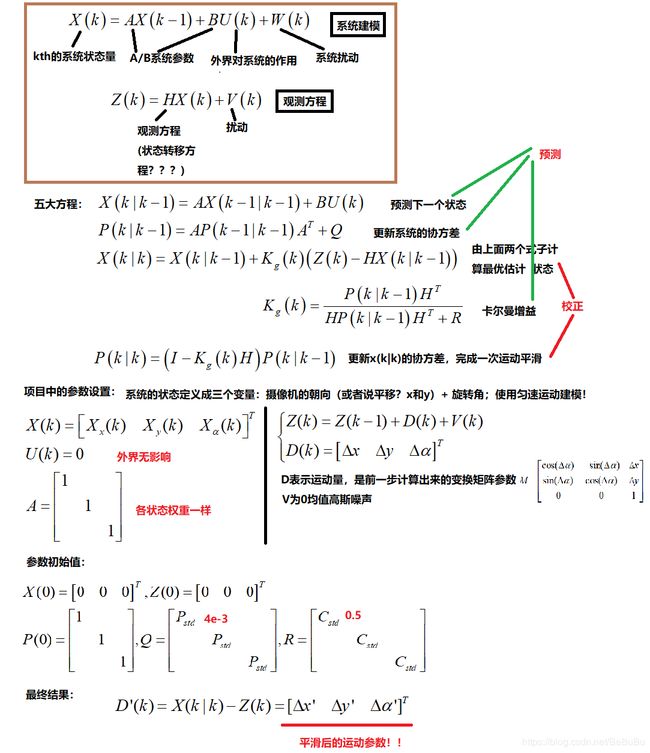
项目简化的KL
- 本项目将 K F KF KF应用于运动平滑,使用 3 3 3个参数描述系统状态,即摄像机的朝向 x x x与 y y y和旋转角 α \alpha α。
- 假设摄像机的朝向不变或者做有意义的运动,因此使用匀速运动对系统进行建模