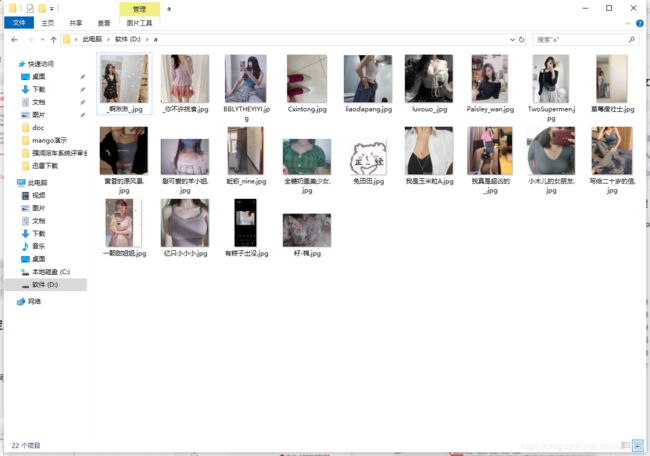
python爬取微博评论及评论中的图片
废话不多说,直接开干。什么原理啊、吹牛逼啊,就不啰嗦了。
众所周知啊,微博、豆瓣、知乎啊这些大佬们的数据爬取十分困难,后台接口、页面什么的经常变化。本文爬取时间为2020-05-21,如果后面大家发现爬取不了,也不要烦躁骂娘。搜最新的博客就可以了。原理差不多。
1、首先我们爬取的为微博手机端的数据
- 打开微博手机端,浏览器中按F12到开发者模式,打开手机端调试以及network和XHR模式,登录并刷新,效果如下:
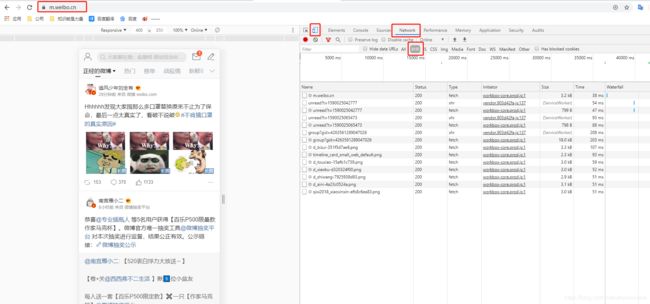
- 找到你要爬取的微博,我这里爬取一个博主发的一个贴,里面是一些美女发的自拍。
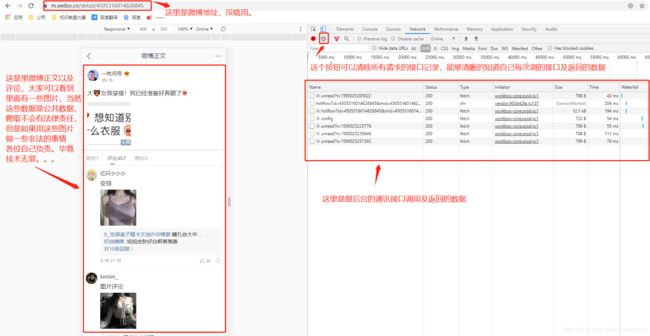
2、到这里基本上你要的数据已经确定。那我们来分析怎么拿到微博的数据
- 首先微博数据如果没有登录,只能拿到前20条数据,后面数据是拿不到的。所以前面说的登录是必须的。而登录之后微博会返回Cookie给你,后续调用接口带上Cookie就可以拿到所有数据。Cookie获取地方在这里找:

- 下面,我们开始分析数据。
- 首先看第一次请求接口,拿到的数据。这里我会圈出几个提别需要注意的地方

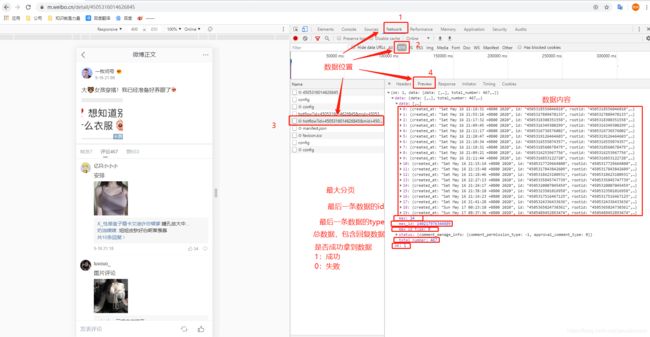
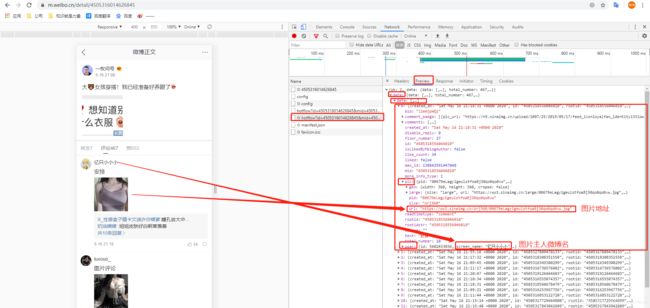
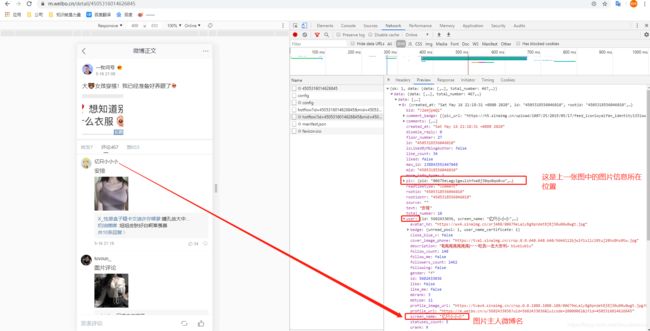
这里提一嘴,从图中可以看出我们不止能到图片信息,还能拿到图片微博微博名、回复内容、个人签名等等信息。这些信息可以直接提取存到数据库用于。。。大家自行理解。
- 获取第二页数据,正常拨动数据表使第一页数据到最底部,这个时候再拨动鼠标,页面会自动调用第二页数据,我们就可以拿到接口了,这里有几处坑,我们先分析数据,再填坑。
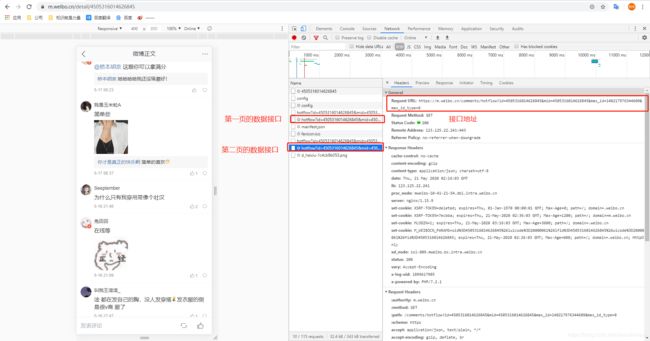
https://m.weibo.cn/comments/hotflow?id=4505316014626845&mid=4505316014626845&max_id_type=0
https://m.weibo.cn/comments/hotflow?id=4505316014626845&mid=4505316014626845&max_id=140217976344609&max_id_type=0
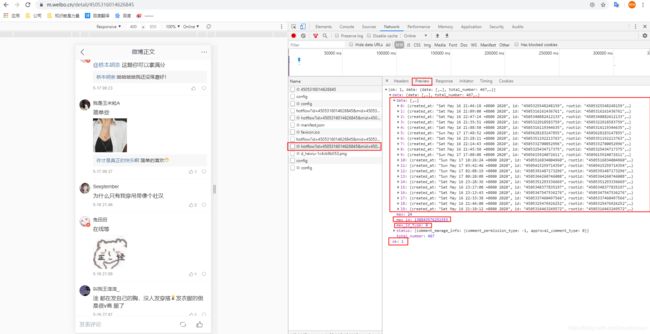
首先分析一下,这两个接口地址,第二个url比第一个url多了一个参数:max_id=140217976344609,那这个参数哪儿来的呢,我们在第一页截图的时候,返回的数据里刚好有个max_id的值,并且刚好和这个值相同。而max_id_type=0这个参数也刚好和第一页返回值里的max_id_type一致。这两个参数很重要
此处有第一个坑,很多小伙伴拿着第二个url在浏览器或postman等工具中调用想拿数据,结果没拿到,返回这个玩意:

心想:我***?我数据呢???小朋友你是否有很多问好???

这里跟大家解释一下,为啥你拿不到数据了:
新浪微博为了避免接口重复调用,导致服务器压力过大,采取措施,在第一个接口调用完毕后,会返回max_id和max_id_type,后续调用第二页的时候带上,这个时候这两个值只能使用一次,就已经被标记为无效。后续再使用就拿不到数据了。调用第二页后同样返回max_id和max_id_type,也只能使用一次。依次类推。
到此,数据已经可以全部拿到,下面我们上代码。
- 引入所需要的包
import requests
import json
import pprint
import os
import urllib.request
- 准备Cookie和Header信息:
# headers信息大家可以不用换,用这个就可以
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Mobile Safari/537.36'
}
# cookie信息用上面截图中我们提到的cookie,复制下来粘贴到''里即可
Cookie = {
'Cookie': '将cookie信息在此处替换'
}
- 获取数据
response = requests.get(
'https://m.weibo.cn/comments/hotflow?id=4505316014626845&mid=4505316014626845&max_id_type=0',
cookies=Cookie, headers=headers)
result = json.loads(response.text)
# 此处result数据类型为字典,可以直接使用。
- 把图片url和图片主人微博名提取出来并打印
ok = result['ok']
max = result['data']['max']
max_id = result['data']['max_id']
max_id_type = result['data']['max_id_type']
datas = result['data']['data']
if ok == 1:
for data in datas:
if 'pic' in data:
username = data['user']['screen_name']
print(username)
url = data['pic']['url']
print(url)
- 获取下一页数据
# 此处用于讲解,不是全部代码,后面会有完整代码
def remaining(max_id, max_id_type):
response = requests.get(
'https://m.weibo.cn/comments/hotflow?id=4505316014626845&mid=4505316014626845&max_id={}&max_id_type={}'.format(
max_id, max_id_type), headers=headers, cookies=Cookie)
result = json.loads(response.text)
- 下载图片
# 图片地址
image_url = 'http://img.jingtuitui.com/759fa20190115144450401.jpg'
# 图片存储位置
file_path = 'D:/a/'
try:
if not os.path.exists(file_path):
os.makedirs(file_path) #如果没有这个path则直接创建
file_suffix = os.path.splitext(image_url)[1]#此处把微博名和他拼接,由于单独代码用于讲解,所以没写。后面会有完整代码。
print(file_suffix)
filename = '{}{}'.format(file_path, file_suffix) #拼接文件名。
print(filename)
urllib.request.urlretrieve(image_url, filename=filename)#,利用urllib.request.urltrieve方法下载图片
print(11111)
except IOError as e:
print(1, e)
except Exception as e:
print(2, e)
完整代码:
import requests
import json
import pprint
import os
import urllib.request
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Mobile Safari/537.36'
}
# cookie信息用上面截图中我们提到的cookie,复制下来粘贴到''里即可
Cookie = {
'Cookie': '将cookie信息在此处替换'
}
# 存放图片主人微博名和url的字典
pic_info = {}
# 剩余的url和图片主任微博名
def remaining(max_id, max_id_type):
response = requests.get(
'https://m.weibo.cn/comments/hotflow?id=4505316014626845&mid=4505316014626845&max_id={}&max_id_type={}'.format(
max_id, max_id_type), headers=headers, cookies=Cookie)
result = json.loads(response.text)
ok = result['ok']
# 没有剩余数据了,此时返回True,在main函数中就会结束循环。
if ok == 0:
return True
datas = result['data']['data']
for data in datas:
if 'pic' in data:
username = data['user']['screen_name']
print(username)
url = data['pic']['url']
print(url)
pic_info[username] = url
return False
# 下载图片
def download_pic(pic_info: dict):
for key, value in pic_info.items():
print(key, value)
image_url = value
file_path = 'D:/a/'
try:
if not os.path.exists(file_path):
os.makedirs(file_path) # 如果没有这个path则直接创建
file_suffix = key + os.path.splitext(image_url)[1]
print(file_suffix)
filename = '{}{}'.format(file_path, file_suffix) # 拼接文件名。
print(filename)
urllib.request.urlretrieve(image_url, filename=filename) # ,利用urllib.request.urltrieve方法下载图片
except IOError as e:
print(1, e)
except Exception as e:
print(2, e)
if __name__ == '__main__':
# 获取第一页的数据
response = requests.get(
'https://m.weibo.cn/comments/hotflow?id=4505316014626845&mid=4505316014626845&max_id_type=0',
cookies=Cookie, headers=headers)
result = json.loads(response.text)
ok = result['ok']
max = result['data']['max']
max_id = result['data']['max_id']
max_id_type = result['data']['max_id_type']
datas = result['data']['data']
if ok == 1:
for data in datas:
if 'pic' in data:
username = data['user']['screen_name']
print(username)
url = data['pic']['url']
print(url)
pic_info[username] = url
# 获取剩下所有的数据,max:在图中为24,但其实真实数据是三页,那为什么要用max做循环次数呢?因为如果每条评论下都没有子评论,
# 那max就是最大循环次数了,我们在剩余数据的函数里做了判断,当ok=0时,直接跳出循环了。所以不用担心多次循环问题
for i in range(max):
b = remaining(max_id=max_id, max_id_type=max_id_type)
if (b):
break
print(pic_info)
# 下载图片
download_pic(pic_info)
效果