使用WireShark分析HTTP协议时几种常见的汉字编码及其解码方法小结
使用WireShark分析HTTP协议时几种常见的汉字编码
本文由CSDN-蚍蜉撼青松【主页:http://blog.csdn.net/howeverpf】原创,转载请注明出处!
在使用WireShark分析HTTP协议的过程中,我们自然是首先要完成解密(若是使用了SSL)、重组(若是使用了chunked分段编码)、解压(若是使用了压缩编码)【幸运的是,除了加解密,这一系列的工作都已经在Wireshark1.8以后的版本中得到了支持】 ,得到一个基本可直接识别的HTTP报文。但此时的报文中还是会有一些部分内容,他们有着固定地格式,表面看起来也是ASCII字符,但是实际表达的意思却不能直接看得出来。这些不能直接识别的部分,很多是经过某种编码变换的中文字符串。本文要介绍的正是一些我曾经遇到并纠结过的汉字编码。
一、URL编码
编码实例:%E5%9B%9B%E5%B7%9D%E5%A4%A7%E5%AD%A6【下图中kw=之后,意为:四川大学】
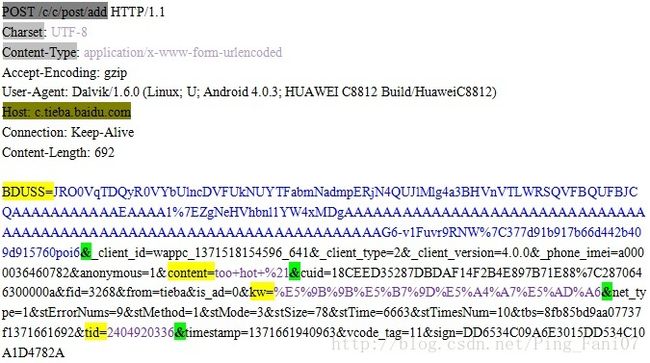
图1 使用百度贴吧客户端发表回复时的HTTP请求示例
常见位置:HTTP请求行中的URI(可能是请求静态网页时的中文路径、或是请求动态网页时的中文查询字符串)
HTTP请求正文中(当请求报文头部Content-Type头域的值为application/x-www-form-urlencoded时,如图1)
格式特点:以%开始,后面紧跟两个16进制数
编码解码:
这种编码方式由于最初用于使URL符合RFC 1738规范【RFC 1738中规定: “只有字母和数字[0-9,a-z,A-Z]、一些特殊符号“$-_.+!*'(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL。”】而被称为URL编码,应该算是HTTP请求报文中最常见的编码了。
URL编码的过程很简单,如下:
-
- 将待编码字符原先的存储编码看成一个16进制流【将原2进制流按 字节拆分,每个字节都用2位16进制数表示】;
- 在每两位16进制数(即一个完整的字节)前加一个%,得到最终编码结果;
对于汉字来说,首先要看其本身存储时所使用的编码是UTF-8还是GB2312。同样的汉字,存储编码不同,经URL编码后的结果自然也不同。例如“川”,使用UTF-8编码存储时为e5b79d,经URL编码后则为%e5%b7%9d;使用GB2312编码存储时为b4a8,经URL编码后则为%b4%a8。
解码的时候也很简单,将编码里的%号去掉,得到一个16进制流,这个16进制流转回2进制流,得到的就是原字符的存储编码。剩下的一个重要问题是怎么理解这个还原出来的存储编码(即原字符使用的存储编码方式)?分三种情况:
-
- 对于HTTP请求正文中的URL编码,我们可以查看请求头部中Charset头域的值,它指定了请求报文所使用的字符集(即存储编码方式)。如图1,因为Charset的值为UTF-8,所以我们对解码后的结果就应当按UTF-8编码理解了;
- 因为使用UTF-8编码时,一个汉字的本身存储占三个字节;而使用GB2312编码,一个汉字的本身存储占两个字节。因此如果我们能确定被编码的是纯汉字流的话,我们可以根据解码后的结果占用的字节数是3或者2的倍数来大致推断其存储编码方式;
- 上述方法都不行的话,就只能在译码的时候都试一下了,但建议先试UTF-8。
解码工具:
百度上一搜一大堆,我经常用的是由九一网络开发的一个URL编码解码百度应用,地址是http://app.baidu.com/app/enter?appid=117335,用起来还比较方便。
二、Unicode编码【网上工具多称为UTF-8编码】
编码实例:\u6d6e\u751f\u82e5\u68a6【下图中深灰底色标注,意为:浮生若梦】

图2 使用百度贴吧客户端查看“我的关注”时服务器给出的响应正文示例
常见位置:HTTP响应正文中
格式特点:以\u开始,后面紧跟四个16进制数
编码解码:
这种编码在网上多被称为UTF-8编码,其实是不太准确的。就其编码过程来看,编码时首先获取汉字对应的Unicode码,然后在Unicode码的前面加上\u就得到编码结果。每组由\u隔开的四个16进制数就对应一个汉字。
相应的,解码也很简单,只要挨个提取\u隔开的四个16进制数,以此作为Unicode编码值在UNICODE编码表里查找相应汉字即可。
解码工具:
114啦工具箱有个在线的UTF-8编码转换工具【地址是:http://tool.114la.com/site/utf8/】可以直接将这种编码转为汉字。我以前一直用的这个,但最近这个网站好像抽风了,上面好多工具都用不起了,不晓得啥时候恢复。
当前我用来解此类编码的是由站长工具提供的UTF-8编码转换工具【地址是:http://tool.chinaz.com/Tools/UTF-8.aspx】,这个工具以及很多其他类似工具的不好之处在于,他们对格式的要求太死板,如果把前述编码示例直接输入是解不出来的,必须先自行将之转换为形如浮生若梦 【将Unicode编码值前的\u替换为&#x,并在Unicode编码值后加上半角分号】的样式才行。手工解码过程略嫌麻烦。
三、八进制显示编码
编码实例:\345\233\233\345\267\235\347\234\201【下图中浅灰色标注,意为四川省】

图3 使用百度贴吧客户端定位时服务器给出的响应示例
常见位置:HTTP响应正文中
格式特点:以\开始,后面紧跟三个8进制数
编码解码:
这种编码其实并非是原始数据中实际存在的编码,它只是WireShark用以显示非ASCII字符的一种方式,所以我将之称之为显示编码。
如果你有C语言基础,那应该早就看到过,当然,在C语言的语法讲解中,这并不作为一种编码,而是归为转义字符的。
这种我所谓的显示编码,其编码规则类似于URL编码。他也是将待编码字符的存储编码按字节拆分,区别在于:
-
- 拆分后,每个字节的值用一个三位8进制数表示【URL编码中用二位16进制数表示】;
- 在每3位8进制数前加上一个反斜杆\【URL编码中在每2位16进制数前加上一个百分号%】
解码的时候,先将每3位8进制数转换成8为2进制数,然后将反斜杆去掉,得到的2进制流就是原字符的存储编码。
解码工具:
我还没有找到一个现成的,可以直接用的工具。一个可以偷懒的办法是,先用一个进制转换工具将3位8进制数转换为2位16进制数,再将所有反斜杆替换成百分号,这样这种编码就转成了URL编码,再利用前文说的URL编码解码百度应用,就可以完成手工解码了。
------本文由CSDN-蚍蜉撼青松【主页:http://blog.csdn.net/howeverpf】原创,转载请注明出处!------