Oracle SQL排列组合之组合问题
产品部门有一个分析需求,简化后是个组合问题,简单表述如下:
表结构
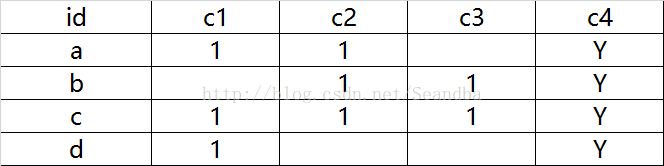
c4列表示状态,c1,c2,c3只要一个不为空,c4就为Y
现在想知道每个组合的情况
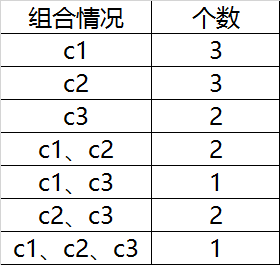
比如为什么组合(c1、c2)的值是2,因为只有2行(第1行、第3行)数据满足c1、c2都不为空
相关测试sql代码如下:
SQL> create table t (
2 id varchar2(1),
3 c1 int,
4 c2 int,
5 c3 int,
6 c4 varchar2(1)
7 );
Table created.
SQL> insert into t values ('a',1,1,null,'Y');
1 row created.
SQL> insert into t values ('b',null,1,1,'Y');
1 row created.
SQL> insert into t values ('c',1,1,1,'Y');
1 row created.
SQL> insert into t values ('d',1,null,null,'Y');
1 row created.
SQL> commit;
Commit complete.
SQL> select replace(path, '.*') path, count(1) cnt
2 from (select *
3 from (select (sys_connect_by_path(pivot_char, '.*')) Path
4 from (select regexp_substr(csv.csvdata, '[^,]+', 1, level) Pivot_char
5 from (select 'C1,C2,C3' as csvdata from dual) csv
6 connect by level <= 3)
7 connect by prior Pivot_char < Pivot_char
8 order by length(path), path) a,
9 (select nvl2(c1, 'C1', null) || nvl2(c2, 'C2', null) ||
10 nvl2(c3, 'C3', null) col_not_null
11 from t) b
12 where regexp_instr(b.col_not_null, a.path) > 0)
13 group by path
14 /
PATH CNT
---------- ----------
C1 3
C2 3
C1C2 2
C2C3 2
C3 2
C1C3 1
C1C2C3 1
7 rows selected.主要思路是构造所有可能的组合和表中实际数据关联匹配得出结果:
第一步:构造3行数据
SQL> select regexp_substr(csv.csvdata, '[^,]+', 1, level) Pivot_char
2 from (select 'C1,C2,C3' as csvdata from dual) csv
3 connect by level <= 3
4 /
PIVOT_CHAR
----------------
C1
C2
C3第二步:3行数据所有组合情况,(.*)是为了后期正则匹配
SQL> select (sys_connect_by_path(pivot_char, '.*')) Path
2 from (select regexp_substr(csv.csvdata, '[^,]+', 1, level) Pivot_char
3 from (select 'C1,C2,C3' as csvdata from dual) csv
4 connect by level <= 3)
5 connect by prior Pivot_char < Pivot_char
6 order by length(path), path
7 /
PATH
--------------------------------------------------------------------------------
.*C1
.*C2
.*C3
.*C1.*C2
.*C1.*C3
.*C2.*C3
.*C1.*C2.*C3第三步:表中实际数据的组合情况
SQL> select nvl2(c1, 'C1', null) || nvl2(c2, 'C2', null) || nvl2(c3, 'C3', null) col_not_null
2 from t
3 /
COL_NOT_NULL
------
C1C2
C2C3
C1C2C3
C1第四步:可能的7种组合和表中实际数据的组合情况关联匹配出结果,如(C1C2)可以匹配(C1)(C2)(C1C2)三种情况,最后结果如下
SQL> select replace(path, '.*') path, count(1) cnt
2 from (select *
3 from (select (sys_connect_by_path(pivot_char, '.*')) Path
4 from (select regexp_substr(csv.csvdata, '[^,]+', 1, level) Pivot_char
5 from (select 'C1,C2,C3' as csvdata from dual) csv
6 connect by level <= 3)
7 connect by prior Pivot_char < Pivot_char
8 order by length(path), path) a,
9 (select nvl2(c1, 'C1', null) || nvl2(c2, 'C2', null) ||
10 nvl2(c3, 'C3', null) col_not_null
11 from t) b
12 where regexp_instr(b.col_not_null, a.path) > 0)
13 group by path
14 /
PATH CNT
---------- ----------
C1 3
C2 3
C1C2 2
C2C3 2
C3 2
C1C3 1
C1C2C3 1
7 rows selected. 第一篇文章...