【数据结构】通过Trie字典树实现敏感词过滤
一、基本概念
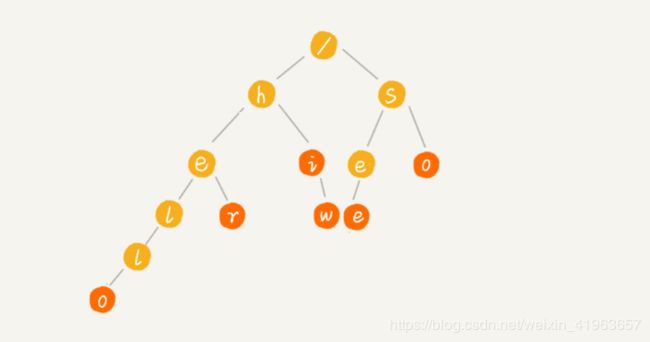
Trie字典树主要用于存储字符串,Trie的每个Node保存一个字符。用链表来描述的话,就是一个字符串就是一个链表。每个Node都保存了它的所有子节点。
如下图所示,根节点不包含任何信息。每个节点表示一个字符串中的字符,从根节点到红色节点的一条路径表示一个字符串。红色节点不一定是叶子节点。
使用Trie这种数据结构存储字符串,查询每个字符串的时间复杂度,只和该字符串长度相同。
二、代码实现
1.首先将基本模型构建出来
创建一个名为TrieNode的类,该类就是我们需要去完善形成的一个Trie的数据结构类。其中有一个Node内部类,Node用来代表Trie中的每一个节点,其中isWord表示首节点到该节点的路径是一个单词,next指向了下一个节点。
public class TrieNode {
//是不是敏感词的结尾
private boolean end = false;
//Character代表当前节点的字符,TrieNode代表了下一个节点
private Map subNodes = new HashMap<>();
public void addSubNode(Character key, TrieNode node) {
subNodes.put(key, node);
}
//查看下一个节点有没有对应的字符
TrieNode getNextSubNode(Character key) {
return subNodes.get(key);
}
boolean isEndWord() {
return end;
}
void setEndWord(boolean end) {
this.end = end;
}
} 2.构建添加敏感词方法
将传入的word进行遍历添加到Trie的分支上,对于已经存在的字符就不用再添加
private TrieNode root = new TrieNode();
public void addWord(String word){
TrieNode tempNode = root;
for(int i = 0 ; i < word.length();i++){
Character c = word.charAt(i);
//判断该字符是否已存在
TrieNode node = tempNode.getNextSubNode(c);
//若不存在则添加
if(node == null){
node = new TrieNode();
tempNode.addSubNode(c,node);
}
tempNode = node;
if(i == word.length()-1){
tempNode.setEndWord(true);
}
}
}3.构建过滤敏感词的方法
需要将待查询的word的每个字符遍历看是否存在,将传入的字符串中不是敏感词的就加入到StringBuilder中,如果是敏感词则用***代替。
public String filter(String words){
String replacement = "***";
TrieNode tempNode = root;
int begin = 0;
int position = 0;
StringBuilder result = new StringBuilder();
while(position < words.length()){
char c = words.charAt(position);
tempNode = tempNode.getNextSubNode(c);
//如果这个字符不在敏感词中则添加到结果中
if(tempNode == null){
result.append(words.charAt(begin));
position = begin+1;
begin = position;
tempNode = root;
}else if(tempNode.isEndWord()){
//发现敏感词进行打码
result.append(replacement);
position += 1;
begin = position;
tempNode = root;
}else{
++position;
}
}
//把最后一串加上
result.append(words.substring(begin));
return result.toString();
}4.测试代码
public class main {
public static void main(String[] args) {
Trie trie = new Trie();
trie.addWord("色情");
System.out.println(trie.filter("hello,色情"));
}
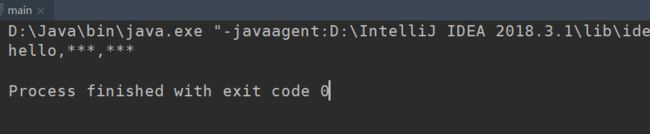
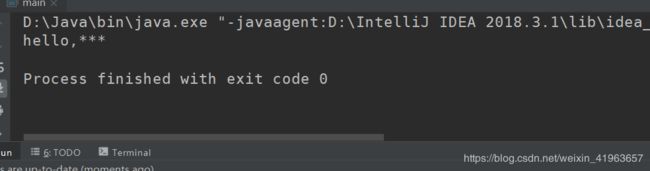
}可以看到将敏感词色情过滤成了***
但是这时如果传入的是"hello,色 情“ ,如下图代码
public class main {
public static void main(String[] args) {
Trie trie = new Trie();
trie.addWord("色情");
System.out.println(trie.filter("hello,色 情"));
}
}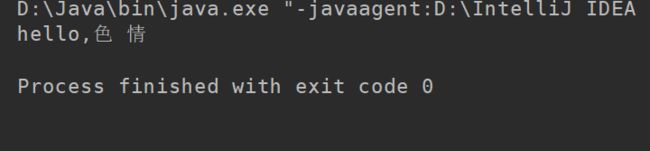
可以看到,如果在敏感词的中间加入一个空格或者其他字符,过滤方法就无能为力了,这说明我们的代码还是存在很大的问题。
5.进一步优化代码,解决缺陷
0x2E80,0x9FFF是东亚文字的范围
public boolean isSymbol(char c){
int ic = (int)c;
//如果不是东亚文字则返回false
if(ic<0x2E80 || ic>0x9FFF)
return false;
return true;
}在过滤方法中进行调用
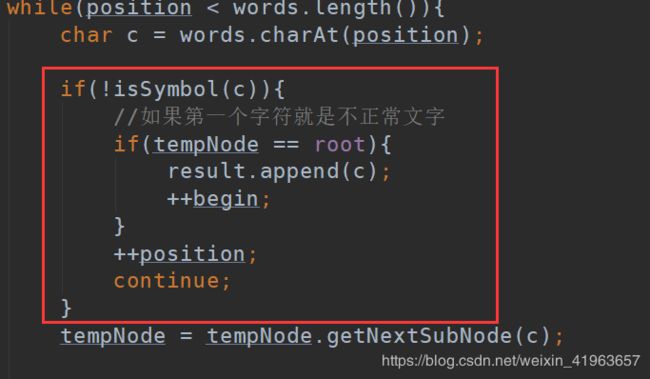
6。最终测试
public class main {
public static void main(String[] args) {
Trie trie = new Trie();
trie.addWord("色情");
System.out.println(trie.filter("hello,色&&^@情,色, 情"));
}
}