LRU算法实现
LRU,即最近最少使用,是一种缓存算法,其核心思想是使用一个Map来保存数据并使用双向链表来维持顺序——它是将插入的每一条记录都包装成一个节点,每个节点包含两个其他节点的引用,一个指向前一个节点,另一个指向后一个节点,(如下图所示:)
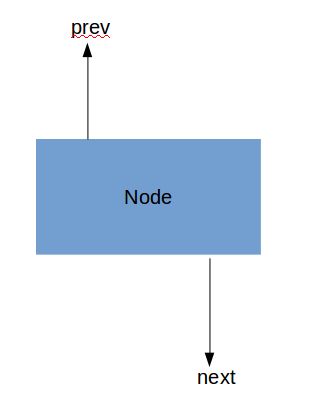
其中Node的数据结构为:
class CacheNode {
Object key;
Object value;
CacheNode prev;
CacheNode next;
CacheNode() {
}
}开始链表是按照数据插入的顺序来保存数据的,当查询某个数据后会将该数据移到链表的头部(即最近访问数据放到头部),因此链表最末端的节点即为最近最少访问的节点,这样当数据存满时继续插入会将链表最末端的节点移除。
具体实现见以下代码:
import java.util.concurrent.ConcurrentHashMap;
public class LruCache {
//缓存的数量限制
private int cacheSize;
//当前的缓存数量
private int currentSize;
//所有节点,使用线程安全的Map
private ConcurrentHashMap nodes;
//头节点
private CacheNode last;
//尾节点
private CacheNode first;
//双向链接节点
class CacheNode {
Object key;
Object value;
//前一个节点
CacheNode prev;
//后一个节点
CacheNode next;
CacheNode() {
}
}
public LruCache(int size) {
this.cacheSize = size;
this.currentSize = 0;
nodes = new ConcurrentHashMap(size);
}
//插入数据
public void put(Object key, Object value) {
//先查询是否已存在该key,存在的话更新value,不存在的花创建一个Node并插入链表
CacheNode node = (CacheNode) nodes.get(key);
if (node == null) {
node = new CacheNode();
}
node.key = key;
node.value = value;
//若缓存已满则删除末端节点
if (currentSize >= cacheSize && last != null) {
removeLast();
}
if (currentSize == 0) {
//若只有一个节点,该节点即是头也是尾
last = node;
first = node;
} else {
node.next = first;
first.prev = node;
first = node;
}
currentSize ++;
nodes.put(key, node);
}
//查询数据@key
public Object get(Object key) {
CacheNode node = (CacheNode) nodes.get(key);
if (node != null) {
//查询成功后将该节点移到链表头部
moveToHead(node);
return node;
}
return null;
}
//移除数据@key
public void remove(Object key) {
CacheNode node = (CacheNode) nodes.get(key);
System.out.println("remove:node = " + node.value);
//System.out.println("remove:node.prev = " + node.prev.value);
//System.out.println("remove:node.next = " + node.next.value);
if (node != null) {
if (currentSize == 1) {
//若只有一条数据,不需要维护链表,直接清空即可
clear();
} else {
if (node == first) {
//移除的是头节点
if (node.next != null) node.next.prev = null;
first = node.next;
node.next = null;
} else if (node == last) {
//移除的是尾节点
if (node.prev != null) node.prev.next = null;
last = node.prev;
node.prev = null;
} else {
//移除的是中间的节点
node.prev.next = node.next;
node.next.prev = node.prev;
node.prev = null;
node.next = null;
}
currentSize --;
nodes.remove(key);
}
}
}
public void clear() {
nodes.clear();
}
//移除末端节点
public void removeLast() {
System.out.println("removeLast:last = " + last.value);
Object obj = nodes.remove(last.key);
if (obj != null) currentSize --;
if (last != null) {
if (last.prev != null)last.prev.next = null;
last = last.prev;
//last.prev = null;
}
}
//将最近访问的节点@node移到链表头部
public void moveToHead(CacheNode node) {
System.out.println("moveToHead:node = " + node.value);
//System.out.println("moveToHead:node.prev = " + node.prev.value);
//System.out.println("moveToHead:node.next = " + node.next.value);
if (node == first) return;
if (node == last) {
//将尾节点移到头部
node.prev.next = null;
last = node.prev;
node.prev = null;
node.next = first;
first.prev = node;
first = node;
} else {
//将中间节点移到头部
node.prev.next = node.next;
node.next.prev = node.prev;
node.prev = null;
node.next = first;
first.prev = node;
first = node;
}
}
//查看链表数据
public String toString() {
StringBuilder sb = new StringBuilder();
for (CacheNode node = first; node != null; node = node.next) {
sb.append(node.key).append(" " + node.value).append("\n");
}
return sb.toString();
}
}
上面代码注释已经比较详细了,链表头部和尾部的操作都比较简单,接下来主要介绍一个典型的场景同时也是最复杂的场景,理解了该场景其他的就都懂了,如下图
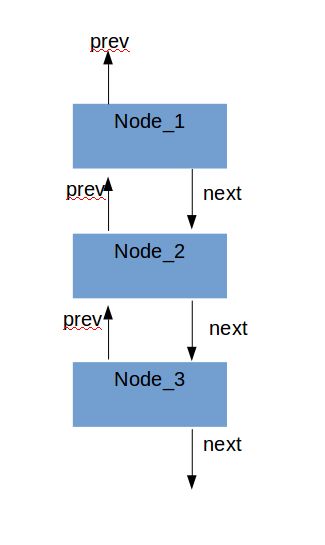
当我们访问节点2时,会将节点2移到链表头部,这里主要涉及到双向链表的顺序维护,链表的维护如下代码所示:
//1、将节点1和节点3链接起来
Node_2.prev.next = Node_2.next;
Node_2.next.prev = Node_2.prev;
//2、先将节点2从链表中抽出来
Node_2.prev = null;
Node_2.next = null;
//3、将节点2移到链表头部
Node_2.next = first;
first.prev = Node_2;
//4、链表头更新为Node_2
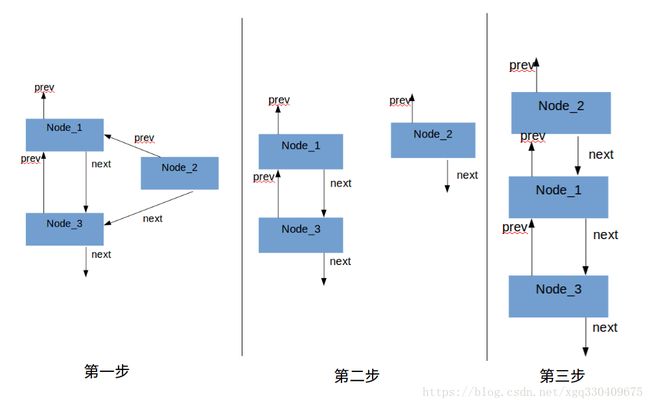
first = Node_2;第一步是将节点1和节点3链接起来,(Node_2.prev为节点1,Node_2.next为节点3);
第二步是将节点2从链表中抽出来,这里第二步必须在第一步之后是因此如果第二步先执行就访问不到节点1和节点3了;
第三步将节点2移到链表头部;
最后一步节点2栄升为头节点。
流程图如下:
以下是测试程序:
public class TestLru {
public static void main(String[] args) throws Exception {
testLru();
}
private static void testLru() {
LruCache lruCache = new LruCache(3 );
lruCache.put("key1", "1");
lruCache.put("key2", "2");
lruCache.put("key3", "3");
System.out.println(lruCache.toString());
lruCache.put("key4", "4");
System.out.println(lruCache.toString());
lruCache.get("key3");
System.out.println(lruCache.toString());
lruCache.remove("key4");
System.out.println(lruCache.toString());
lruCache.put("key5", "5");
System.out.println(lruCache.toString());
}
}输出结果:
key3 3
key2 2
key1 1
removeLast:last = 1
key4 4
key3 3
key2 2
moveToHead:node = 3
key3 3
key4 4
key2 2
remove:node = 4
key3 3
key2 2
key5 5
key3 3
key2 2输出结果符合预期,以上就是LRU的实现原理。
另外给大家介绍一个天生支持LRU的数据结构,它就是LinkedHashMap,因为LinkedHashMap本身就是一个数组加双向链表实现的,LinkedHashMap中有一个参数accessOrder,默认为false,此时链表维护的顺序是数据插入的顺序,后续的数据访问也不会改变该顺序;而当我们设置accessOrder为true时,LinkedHashMap它维护的数据顺序就是LRU了,即访问过的数据放通过调用afterNodeAccess方法将其移动到链表的头部,此时我们还需要重写LinkedHashMap的removeEldestEntry方法(默认返回false),该方法表示是否移除链表末端节点,我们可以设置为当存放数据达到可我们指定的容量时让该方法返回true即可。
public class LinkedHashMap {
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
......
public V get(Object key) {
Node e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
......
protected boolean removeEldestEntry(Map.Entry eldest) {
return false;
}
} 简单实现如下:
LinkedHashMap keyMap = new LinkedHashMap(size, .75F, true) {
protected boolean removeEldestEntry(Map.Entry eldest) {
boolean tooBig = size() >= size;
if (tooBig) {
eldestKey = eldest.getKey();
}
return tooBig;
}
};
进行测试:
import com.qdrs.upload.UploadUtil;
import java.io.Serializable;
import java.math.BigInteger;
import java.util.*;
public class UploadDemo {
public static void main(String[] args) throws Exception {
testLinkedHashMap();
}
public static void testLinkedHashMap() {
Map lruCache = Collections.synchronizedMap(new LinkedHashMap(3, 0.75F, true) {
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > 3;
}
});
lruCache.put("key1", "1");
lruCache.put("key2", "2");
lruCache.put("key3", "3");
System.out.println(lruCache.toString());
lruCache.put("key4", "4");
System.out.println(lruCache.toString());
lruCache.get("key3");
System.out.println(lruCache.toString());
lruCache.remove("key4");
System.out.println(lruCache.toString());
lruCache.put("key5", "5");
System.out.println(lruCache.toString());
}
}
输出结果:
{key1=1, key2=2, key3=3}
{key2=2, key3=3, key4=4}
{key2=2, key4=4, key3=3}
{key2=2, key3=3}
{key2=2, key3=3, key5=5}结果与预期一致。
以上,介绍了两种实现LRU的方法,但是建议先掌握了第一种方法-该方法阐述了lru实现原理;在以后的学习和工作中使用两种方法中任意一种都可以。