【论文解读 WSDM 2019 | XBully】XBully: Cyberbullying Detection within a Multi-Modal Context

论文题目:XBully: Cyberbullying Detection within a Multi-Modal Context
论文来源:WSDM 2019 刘欢老师组
论文链接:https://doi.org/10.1145/3289600.3291037
关键词:网络欺凌检测;多模态;异质图;网络嵌入
文章目录
- 1 摘要
- 2 引言
- 3 问题定义
- 3.1 多模态网络欺凌检测
- 3.2 通过多模态网络表示学习的网络欺凌检测
- 3.3 挑战
- 4 XBully模型
- 4.1 Mode Hotspot Detection
- 4.2 网络表示学习
- 4.3 嵌入精炼(Embedding Refinement)
- 5 实验
- 5.1 实验设置
- 5.2 性能评估
- 5.3 定性分析
- 6 总结
- 参考文献
1 摘要
社交媒体平台上的网络欺凌是最普遍的,而且天然是多模态的。但是现有的网络欺凌识别方法仅仅聚焦于依赖对文本的分析,建立起一般的分类模型。
这些方法忽视了社交媒体数据中的多模态信息(例如 图像、视频、用户属性、事件和位置),因此不能为网络欺凌提供一个全面的理解。
通常来说,当来自不同模态的信息被一起呈现时,它经常揭示出关于应用领域的互补知识,并促进更好的学习表现。
本文通过利用社交媒体数据,研究了使用多模态内容的网络欺凌检测问题。
这一任务是具有挑战的,因为跨模态的关联和不同社交媒体sessions间结构依赖的组合是很复杂的,并且不同模态有着不同的属性信息。
为了解决这些挑战,作者提出网络欺凌检测框架XBully。该框架首先将多模态社交媒体数据定义为异质网络,然后学习网络中节点的嵌入表示。
实验结果显示本文提出的XBully方法查阅了SOTA网络欺凌检测模型。
2 引言
(1)网络欺凌的定义
网络欺凌指的是在电子设备上传递侮辱性或令人难堪的内容、照片或视频,已成为社交网络上的普遍现象。
(2)现有的方法
现有的网络欺凌检测方法主要聚焦于文本分析,这些工作试图建立一般的二分类器,将高维文本特征作为输入,并据此做预测。
尽管在实际应用中这些工作的检测性能可观,但是它们不可避免地忽视了社交媒体中不同模态的信息,例如图像、视频、用户属性和位置。
(3)使用多模态内容的重要性
例如Instgram允许用户发布图像或在任意的公开图像下评论以表达他们的观点和喜好。欺凌者可以发布羞辱性的图像或侮辱性的评论、题注(captions)或hashtags,编辑或者转发其他人的图像,甚至制造假的属性信息伪装成其他的用户。因此,在多模态环境中利用丰富的用户生成(user-generated)的内容来更深入地了解网络欺凌行为并生成准确的预测是至关重要的。
图 1展示了使用多模态上下文的网络欺凌检测问题。

(4)使用多模态上下文的挑战
1)首先,来自不同模态的信息可能是互补的,从而对学习性能起到促进作用,特别是在数据稀疏的情况下。
然而,来自于不同模态的异质信息可能并不兼容,甚至有一些模态的信息可能是完全独立的。
因此,网络欺凌检测中尚未充分解决的关键问题是,如何有效地编码不同类型模态信息间跨模态的关联。
2)社交媒体数据通常不是独立同分布的(i.i.d),而是内在有着直接或间接关联的,这就限制了传统的文本分析方法的适用性。
例如,两个social media sessions(例如 posts)是来自于同一个用户的或者由一对朋友所发布,基于同质性原理,它们内容间的相似性的期望是较高的。
考虑到这一点,则需要建模不同社交媒体会话(social media sessions)间的结构依赖。
3)尽管多模态社交媒体数据可用于理解人类的行为,但直接对其利用是很难的,因为不同模态经常与不同的特征类型相关联(例如 nominal, ordinal, interval, ratio等),而且在某些情况下,一些识别特定实体(例如 users)的模态不能简单地表示为特征向量。
因此,提出的框架需要使用一种表达方式来表示具有不同特征类型的模态。
(5)作者提出
作者提出XBully模型,用联合的方式建模了多模态社交媒体数据。特别地,为了捕获到模态间跨模态的关联和不同社交媒体会话间的结构依赖,我们使用co-existence和邻居关联,将多模态社交媒体数据建模成异质网,目的是学习到网络中节点的嵌入表示。
由于数据的稀疏,我们为每个模态识别了一些热点(hotspots),这些热点提供了类似模态属性值的简要总结。
对于nomianls(无属性的模态),我们在构建异质网络时使用它们的元信息形成节点,例如 userIDs。
在学习了异质网络中节点的嵌入表示之后,对于每个社交媒体会话,可以通过拼接这一会话中的节点嵌入得到该会话的数值向量。
许多现成的机器学习方法可以直接使用这些向量,提供准确的网络欺凌检测,并且对网络欺凌行为有一个更深层次的理解。
(6)本文贡献
1)问题形式化:形式化定义了使用多模态上下文的网络欺凌检测问题。
2)算法:提出了XBully框架,由三个核心部分组成:
- 热点检测器(hotspot detector):识别每个模态的centroids;
- 构建异质网:通过利用检测到的hotspots和nominals实例的co-existence和neighborhood关联,构建一个异质网;
- 联合嵌入模块:将跨模态关联和不同社交媒体会话间的结构依赖编码,以学习到抗噪声的嵌入表示。
3)评估:在2个社交媒体数据集上进行了实验,证明了本文模型的功效。
3 问题定义
3.1 多模态网络欺凌检测
定义1 使用多模态上下文进行网络欺凌检测
定义1:给定一组有 M M M个模态的社交媒体会话 C C C(例如 posts),使用多模态上下文的网络欺凌检测目的是,通过利用多个模态的信息,例如文本特征、空间位置、视觉线索和会话间的关联,识别出网络欺凌的实例。
本文实验中使用从Instagram会话中抽取出的如下的模态:
- User:是典型的名词(nominals),我们使用用户间的关联来编码社交媒体会话间的依赖关系;
- Image:一张图像相关的元信息形成了一个元组,由分享数、喜欢数和描述该图像的类型标签组成;
- Profile:用户的元数据形成了一个元组,由粉丝数、关注数、整体评论数和收到的整体喜爱数组成;
- Time:发布图像的时间戳。将一天的24小时按照秒数计算,时间戳是计算和12:00 am的偏移,其范围是[0, 86400]。
- Text:对会话的文本进行心理层面的分析,例如图像的描述和评论,并通过LIWC[1]得到心理学特征。这是由于有研究表明心理分析可以为网络欺凌行为提供见解。
3.2 通过多模态网络表示学习的网络欺凌检测
令 C C C表示社交媒体会话语料,将每个会话 s ∈ C s\in C s∈C定义成一个元组 < x s 1 , x s 2 , . . . , x s M , y s 1 , . . . , y s N > <\mathbf{x}_{s1}, \mathbf{x}_{s2}, ..., \mathbf{x}_{sM}, y_{s1}, ..., y_{sN}> <xs1,xs2,...,xsM,ys1,...,ysN>。其中 M M M和 N N N分别表示模态数(modes)和标称(nominals)数。例如,一个geo-tagged社交媒体会话可能有位置信息 x s m = [ 34.0489 , 111.0937 ] \mathbf{x}_{sm} = [34.0489, 111.0937] xsm=[34.0489,111.0937]。
此外,不同的会话是通过用户之间的社交关联内在彼此连接的。我们的目标是将原始的语料 C C C,通过捕获其多模态特征,将其表示为异质网 G G G,并为网络中每个节点学习到高质量的嵌入表示。
和将多模态特征向量简单地拼接不同,异质网学习到的节点嵌入使用一个联合的框架,捕获了不同社交媒体会话间的结构依赖,以及不同模态间的跨模态关联。
3.3 挑战
(1)Number of Distinct Feature Values
社交媒体数据通常以复杂的形式出现,并且由于其多模态的特性而表现出相当大的变化。
我们经常会遇到不同的特征类型,并且每个模态所能获取到的独有的特征值数量往往很大,这就会导致数据的稀疏性问题。
此外,网络中每个节点可用的训练数据往往有限,这使得训练过程更加复杂。
(2)Cross-Modal Correlation and Structural Dependencies
用于多模态社交媒体数据的有效的网络嵌入模型,应该保留跨模态关联和不同会话间的结构依赖的节点相似性。
传统的网络嵌入模型例如DeepWalk, LINE, node2vec,主要聚焦于编码同质网络的结构信息,不能让有效地应用到本文的问题中。
Metapath2vec是最近提出的异质网络嵌入模型,其依赖于一组预定义的元路径,用于找到节点周围的邻居节点。然而,对于本文的问题,元路径的数量通常是很大的,这使得metapath2vec不可行。
(3)Information Noise
丰富的多模态信息可以提供有价值且互补的信息,以用于识别网络欺凌行为。这样的数据可能是混乱的并且有噪声,不便于从这样的数据中获得可操作的知识。
为了解决这些挑战,我们提出了使用核密度估计(kernel density estimation, KDE)的模态热点检测(mode hotpots detection)模块,以减少独有特征值的数量。
识别出hotpots后,然后利用共存(co-existence)关系,同一会话中不同模态事件的关联,以及邻居关系,构建一个异质网,以连接不同会话中相同模态的节点。
我们设计了一个基于图的联合嵌入模块以捕获跨模态的关联和结构依赖。这一嵌入模块将异质网中所有模态的hotpots和nominal节点映射到隐层空间中。
为了缓解噪声的负面影响,我们还为每个节点识别出了信息最丰富的邻居,以改进已学得的嵌入。
框架的整体架构如图 2所示。
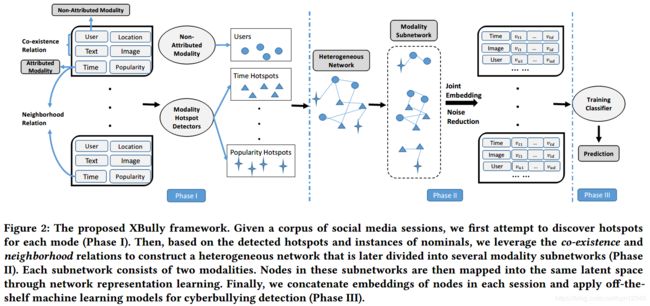
4 XBully模型
本节详细介绍了本文提出的XBully模型。首先介绍如何识别出简洁但正确的一组相似特征值的概要(mode hotspots)。然后,我们提出方法捕获跨模态的关联以及结构依赖,用于嵌入表示学习。我们还讨论了如何在嵌入训练阶段缓解噪声的负面影响。
4.1 Mode Hotspot Detection
先前的工作表明,高维特征表示不仅存在数据稀疏性问题,而且维数过高也给下游的学习任务带来了很大的挑战。为了解决这一问题,我们提出了基于KDE[2]的模态热点概念,这是一种从数据样本集合估计密度函数的非参数方法。
使用KDE,我们不需要建立任何的关于数据分布的先验知识,因为它可以从复杂的数据空间自动发现任意模态。
定义2 Mode Hotspots:给定一个社交媒体会话语料 C C C,模态 m ( m = 1 , 2 , . . . , M ) m(m=1, 2, ..., M) m(m=1,2,...,M)的mode hotspots是从 m m m进行核密度函数估计的局部最大值的集合。
然后给定 n n n个包含 m m m个模态的会话,并使用 d d d维的特征表示它们 X m = ( x 1 m , x 2 m , . . . , x n m ) X_m = (\mathbf{x}_{1m}, \mathbf{x}_{2m}, ..., \mathbf{x}_{nm}) Xm=(x1m,x2m,...,xnm),有着模态 m m m的任意 x \mathbf{x} x点的核密度为:
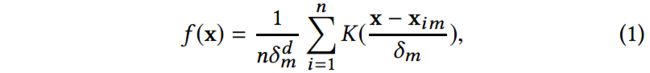
其中, K ( ⋅ ) K(\cdot) K(⋅)表示预定义的核函数, δ m \delta_m δm是模态 m m m的核带宽(kernel bandwidth)。我们进一步使用[3]中的meanshift算法识别mode hotspots。
4.2 网络表示学习
利用共现(co-existence)关系和邻居关系,捕获到跨模态关联和结构依赖信息。
共现关系:当两节点共存于同一社交媒体会话时,他们之间建立起共现关系;
邻居关系:mode hotspots间的邻居关系建立在modality continuity[4]的思想上,它依赖的思想是,附近的物体比远处的物体有更紧密的联系。
我们首先定义节点核(node kernel),在此基础上形成邻域关系:
定义 3 Node Kernel:对于mode m m m中的两个mode hotspots u i , u j u_i, u_j ui,uj,其特征向量分别为 x i , x j \mathbf{x}_i, \mathbf{x}_j xi,xj,他们之间的kernel strength为:
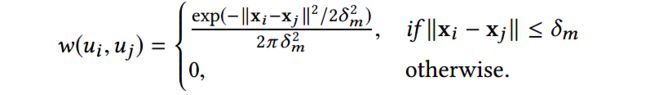
因此,mode hotspot v v v在异质网上的邻居就是一组和hotspot v v v生成了非零kernel strength值的mode hotspots。
此外,对于nominal节点,我们利用不同会话间的依赖(例如 social relations)关系,根据它们的结构信息,定义邻居关系。
例如,一个Instagram会话可能有5中不同的模态:user, image, profile, time, comments(text)。根据共现关系的定义,我们可以在异质网中构建出如下的10中类型的边:user-image, user-profile, user-time, user-text, image-profile, image-text, image-text, profile-time, profile-text 和 time-text。
此外,邻居关系也可以生成如下的4中边类型:image-image, profile-profile, time-time 和 text-text,并且和nominal节点有关的user-user边是使用用户间的社交关联建立的。
根据如上的边类型的定义,我们考虑以下的三种情况来定义边的权重:1)归一化的共现值(0和1之间);2)kernel strength(0和1之间);3)nominal节点间的依赖(0和1之间)。
由于网络是异质的,因此无法直接使用传统的同质网络嵌入算法,例如DeepWalk和node2vec。于是,根据文献[5],我们将异质网分解成多个模态子网络(每个子网络有两种模态),并对每个子网络学习嵌入表示。
(1)首先,我们定义所有模态子网络为 G S G_S GS。对于任意两种不同的模态 A , B ∈ ( 1 , 2 , . . . , M + N ) A, B\in (1, 2, ..., M+N) A,B∈(1,2,...,M+N),我们可以构建一个模态子网络 G A B ∈ G S G_{AB}\in G_S GAB∈GS。
如下的条件概率定义了从模态为 A A A的节点 i i i生成模态为 B B B的节点 j j j的概率:
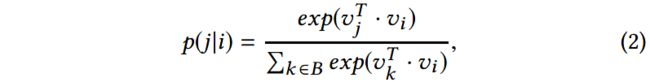
其中 v j v_j vj表示模态为 B B B的节点 j j j的嵌入表示, v i v_i vi表示模态为 A A A的节点 i i i的嵌入表示。
(2)接着,通过最小化给定中心节点的上下文节点的条件分布于经验分布之间的距离来学习嵌入。
节点 i i i的经验分布定义为 p ′ ( j ∣ i ) = w i j d i p^{'}(j|i)=\frac{w_{ij}}{d_i} p′(j∣i)=diwij。其中 w i j w_{ij} wij是边 i − j i-j i−j的权重, d i d_i di是节点 i i i的出度,例如 d i = ∑ j ∈ B w i j d_i = \sum_{j\in B} w_{ij} di=∑j∈Bwij。
因此,损失函数定义为:
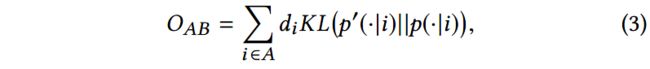
其中 K L ( ⋅ ) KL(\cdot) KL(⋅)表示两个概率分布间的KL散度。省略常量后,上述的损失函数可以重写成如下的形式:
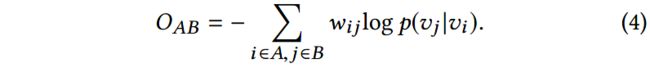
由于每个子网络只有两种模态的节点,因此一共有4种类型的边: A − A , A − B , B − A , B − B A-A, A-B, B-A, B-B A−A,A−B,B−A,B−B。模态子网络 G A B G_{AB} GAB的整体损失函数为:
4.3 嵌入精炼(Embedding Refinement)
尽管多模态信息有助于提高嵌入的质量,但是当网络非常稀疏时,上述模型就会出现问题。此外,当发现的mode hotspots含有很大的噪声时,可能会对嵌入表示学习节点产生不利影响。
为了解决这些问题,我们提出了noise-resilient embedding refinement方法,以自适应地为每个节点选择信息最丰富的的邻居。这一精炼方法的核心思想是找到最佳的局部权重上下文向量(predictors)以重构中心节点的嵌入。
特别地,给定 n n n个嵌入向量 v 1 , . . . , v j , . . . , v n ∈ R d v_1, ..., v_j, ..., v_n \in \mathbb{R}^d v1,...,vj,...,vn∈Rd,使用 v ^ i = ∑ j = 1 , i ≠ j n α j i v j \hat{v}_i = \sum^n_{j=1, i \neq j} \alpha_{ji}v_j v^i=∑j=1,i=jnαjivj估计 v ^ i \hat{v}_i v^i。其中 ∑ j α j i = 1 \sum_j \alpha_{ji} = 1 ∑jαji=1, α j i \alpha_{ji} αji表示 v i v_i vi受 v j v_j vj影响的程度。
本文的方法建立在文献[6]中算法的基础上,目的是自适应地为每个中心节点学习到最优的邻域结构,并且自动地量化来自其他节点的影响。可形式化为如下:
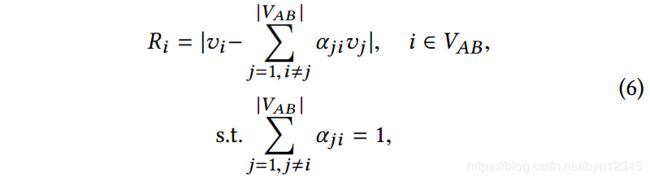
其中 V A B V_{AB} VAB表示模态子网络 G A B G_{AB} GAB中的节点集合。
通过整合上述的嵌入精炼部分,嵌入表示学习心得目标函数为:
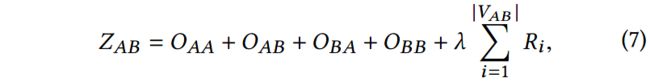
因此,多模态网络嵌入整体的目标函数为:
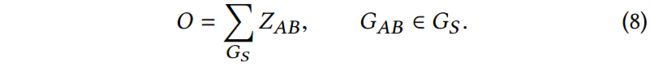
对于最终的目标函数,我们交替更新嵌入变量和影响矩阵(with entry α i j \alpha_{ij} αij)。为了更新嵌入向量,我们使用SGD优化不同模态子网络,并且引入负采样。特别地,对于边 e i j e_{ij} eij,我们随机选择 K K K个没有和节点 i i i相连的节点作为负样本。
随后通过[6]中的提出的算法进行,输入更新后的嵌入向量来更新影响矩阵。
5 实验
本节的目的是回答以下研究问题:
-
XBully框架是否优于现有的只使用文本信息的网络欺凌检测模型?
-
noise-resilient embedding refinement模块对于嵌入表示学习能发挥多大的作用?
-
本文提出的多模态网络嵌入方法是否比传统的网络嵌入方法更有助于提高检测性能?
-
XBully为心理学和社会学科学家提供了什么样的见解?
-
给定不同的模型参数,模型的鲁棒性如何?
5.1 实验设置
(1)数据集
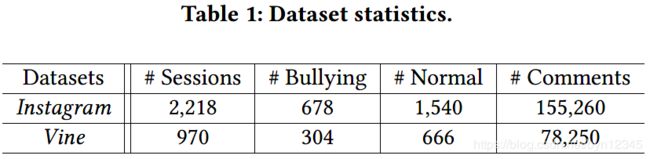
使用两个真实世界的社交媒体数据集。Instagram数据集中的每个社交媒体会话包括图像描述、用户评论和该会话创建的时间。数据集还包括用户数属性信息和用户间的社交关系。
第二个数据集是从Vine中收集的,是一个允许用户录制并编辑6秒视频的移动应用网站。每个Vine会话有视频描述、用户评论和会话的创建时间。
两个数据集的基本统计特性如表 1所示,其他的细节见[7, 8]
数据集链接:https://sites.google.com/site/cucybersafety/home/cyberbullyingdetection-project/dataset
(2)Baseline Methods
为了回答前两个研究问题,我们将XBully和使用特征工程的普通方法、两个最近提出的网络欺凌模型、以及XBully的没有noise-resilient embedding refinement变形进行比较。
- Raw Features (Raw):将所有的多模态特征进行拼接,例如网络特征和文本特征;
- Bully[9]:一个基于文本分析的预训练分类器;
- SICD[10]:SOTA网络欺凌检测模型,使用了嵌入到用户生成内容中的用户情感信息,以指导预测;
- XBully variant (Variant):没有noise-resilient embedding refinement的XBully。
我们还将提出的模型和3个广泛应用的网络嵌入模型DeepWalk,Node2vec和GraRep进行了比较。为了减少模型方差对性能评估的影响,对这些方法使用了3个分类模型,包括随机森林、线性SVM和Logistic Regression。
5.2 性能评估
本节的目的是回答第三个研究问题。我们使用了两个评估度量Macro F1(Mac F1)和Micro F1(Mic F1)。
macro-average为每个类别独立计算了度量,然后取平均作为输出。micro-average聚合了所有类别的贡献,来计算平均度量。在二分类中,Micro F1相当于Accuracy。
表 2和表 3表示了不同方法在两个数据集上的网络欺凌检测性能。


从表格中的结果可以看出:
1)在大多数情况下,XBully在两个数据集上都显著优于使用多模态拼接特征的Raw和同质网络嵌入方法(DeepWalk, Node2vec, GraRep)。
这表明了XBully的有效性,它捕获到了跨模态的关联和结构依赖。
2)XBully和其他两个网络欺凌检测方法(Bully和SICD)相比,在两个数据集上的Macro F1均超越了它们,在Instagram数据集的Micro F1度量上超越了它们。
3)使用不同的分类器时,XBully的效果也比baseline方法高,说明该模型是有效的,并且易于泛化到其他的机器学习方法上。
4)XBully比没有嵌入精炼模块的方法检测性能要高。这一结果表明在学习过程中,通过从相似的节点整合信息,对嵌入进行精炼的有效性,可以使得学得的嵌入表示对噪声更加鲁棒。
5.3 定性分析
探究经受过网络欺凌的用户和没有经历过网络欺凌的用户的社交行为。为此,我们将数据集中每个标签的置信度解释为该会话是网络欺凌的概率指标§。
为了理解XBully如何为社会学家和心理学家提供见解,我们将新的节点类型作为另一种模态引入到之前的模型中,并重新训练所有的嵌入。然后,我们提出关于 p p p的查询( p p p的范围为 ( 0.1 , 0.2 , . . . , 1.0 ) (0.1, 0.2, ..., 1.0) (0.1,0.2,...,1.0)),XBully根据余弦相似度返回最相近的mode hotspots。
我们想要回答的问题是,社交平台上的用户行为与网络欺凌的可能性之间有什么样的关系。如下的分析是基于在Instagram数据集上的实验得到的。

如图 3 a所示,当 p p p增加时,#follows也变大,即当网络欺凌的概率增加时,会话所有者关注的用户数量也会增加。这就表明,在社交媒体上更积极地关注他人的用户更有可能遭受网络欺凌。
如图 3 b所示,#followers在不同概率上分布的形状可近似为正态分布。这意味着,经历网络欺凌的用户和没有经历网络欺凌的用户在粉丝数上差别很小。
图 3 c - d表示了社交媒体会话流行度和 p p p之间的关联。在图 3 c中,一共有三个峰值,分别是在 p = 0.1 , 0.5 , 1.0 p=0.1, 0.5, 1.0 p=0.1,0.5,1.0时。并且 p = 0.1 p=0.1 p=0.1时的#likes数是 p = 0.5 , 1.0 p=0.5, 1.0 p=0.5,1.0时的两倍。在图 3 d中,当 p p p越大时,#shares数越少。
可能的解释是,大多数用户是正常用户,他们对网络欺凌相关的内容并不感兴趣。
虽然这只是初步的结论,但图 3中的趋势为跨学科的研究人员阐明了一种潜在的新方法,以衡量社交媒体互动上下文的社会影响,特别是当它们和欺凌风险相关时。
6 总结
本文解决的是网络欺凌检测任务。
现有的绝大多数方法聚焦于文本分析,来进行网络欺凌检测,忽视了社交媒体数据的多模态特性(例如 文本、图像、likes/shares)。
本文提出的模型使用到了多模态的信息,认为多模态信息可以为刻画和检测网络欺凌行为提供有价值的见解。
本文基于网络表示学习提出了网络欺凌检测框架XBully。XBully首先识别出来有代表性的mode hotspots以处理多样的特征类型。然后利用跨模态的关联以及结构依赖信息,将异质网中有属性的节点和标称(nominal)节点映射到统一隐层空间中。
未来工作:
(1)加深对网络欺凌行为特征的不同模态的理解,不仅提高网络欺凌检测性能,还要阐明网络欺凌交互中就有不同角色(victims, bullies)的用户所特有的行为。
(2)计算机科学和心理学研究人员跨学科的合作,以解决这一重大社会问题。
参考文献
[1] James W Pennebaker, Martha E Francis, and Roger J Booth. 2001. Linguistic inquiry and word count: LIWC 2001. Mahway: Lawrence Erlbaum Associates 71, 2001 (2001), 2001.
[2] Emanuel Parzen. 1962. On estimation of a probability density function and mode. The annals of mathematical statistics 33, 3 (1962), 1065–1076.
[3] Chao Zhang, Keyang Zhang, Quan Yuan, Haoruo Peng, Yu Zheng, Tim Hanratty, Shaowen Wang, and Jiawei Han. 2017. Regions, periods, activities: Uncovering urban dynamics via cross-modal representation learning. In Proceedings of the 26th WWW. International World Wide Web Conferences Steering Committee, 361–370.
[4] Waldo R Tobler. 1970. A computer movie simulating urban growth in the Detroit region. Economic geography 46, sup1 (1970), 234–240.
[5] Jian Tang, Meng Qu, and Qiaozhu Mei. 2015. Pte: Predictive text embedding through large-scale heterogeneous text networks. In Proceedings of the 21th ACM SIGKDD. ACM, 1165–1174.
[6] Oren Anava and Kfir Levy. 2016. k*-nearest neighbors: From global to local. In Advances in Neural Information Processing Systems. 4916–4924.
[7] Homa Hosseinmardi, Rahat Ibn Rafiq, Richard Han, Qin Lv, and Shivakant Mishra. 2016. Prediction of cyberbullying incidents in a media-based social network. In ASONAM 2016. IEEE, 186–192.
[8] Rahat Ibn Rafiq, Homa Hosseinmardi, Richard Han, Qin Lv, Shivakant Mishra, and Sabrina Arredondo Mattson. 2015. Careful what you share in six seconds: Detecting cyberbullying instances in Vine. In ASONAM 2015. ACM, 617–622.
[9] Jun-Ming Xu, Kwang-Sung Jun, Xiaojin Zhu, and Amy Bellmore. 2012. Learning from bullying traces in social media. In Proceedings of the 2012 conference of the North American chapter of the association for computational linguistics: Human language technologies. Association for Computational Linguistics, 656–666.
[10] Harsh Dani, Jundong Li, and Huan Liu. 2017. Sentiment Informed Cyberbullying Detection in Social Media. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 52–67.