自然语言处理一:基于朴素贝叶斯的语种检测
本文来自是对七月在线寒小阳自然语言处理课程的总结。
本文使用朴素贝叶斯完成一个语种检测的分类器,准确度经过简单的参数调优可以达到99.1%。

机器学习的算法要取得好效果,离不开数据,咱们先拉点数据(twitter数据,包含English, French, German, Spanish, Italian 和 Dutch 6种语言)瞅瞅。
# 读取数据
in_f = open('data.csv')
lines = in_f.readlines()
in_f.close()
# 把数据和标签以list形式存入到dataset中
dataset = [(line.strip()[:-3], line.strip()[-2:]) for line in lines]查看数据的样子
print(dataset[:5])[('1 december wereld aids dag voorlichting in zuidafrika over bieten taboes en optimisme',
'nl'),
('1 mill\xc3\xb3n de afectados ante las inundaciones en sri lanka unicef est\xc3\xa1 distribuyendo ayuda de emergencia srilanka',
'es'),
('1 mill\xc3\xb3n de fans en facebook antes del 14 de febrero y paty miki dani y berta se tiran en paraca\xc3\xaddas qu\xc3\xa9 har\xc3\xadas t\xc3\xba porunmillondefans',
'es'),
('1 satellite galileo sottoposto ai test presso lesaestec nl galileo navigation space in inglese',
'it'),
('10 der welt sind bei', 'de')]
为了一会儿检测一下咱们的分类器效果怎么样,我们需要一份测试集。
所以把原数据集分成训练集的测试集,咱们用sklearn自带的分割函数。
from sklearn.model_selection import train_test_split
x, y = zip(*dataset)
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1)模型要有好效果,数据质量要保证
我们用正则表达式,去掉噪声数据
import re
def remove_noise(document):
noise_pattern = re.compile("|".join(["http\S+", "\@\w+", "\#\w+"]))
clean_text = re.sub(noise_pattern, "", document)
return clean_text.strip()
remove_noise("Trump images are now more popular than cat gifs. @trump #trends http://www.trumptrends.html")输出为:
'Trump images are now more popular than cat gifs.'下一步要做的就是抽取特征,构建模型
from sklearn.feature_extraction.text import CountVectorizer
N = range(1, 10, 1)
test_score_list = []
for n in N:
vec = CountVectorizer(
lowercase=True, # lowercase the text
analyzer='char_wb', # tokenise by character ngrams
ngram_range=(1, n), # use ngrams of size 1 and 2
max_features=1000, # keep the most common 1000 ngrams
preprocessor=remove_noise
)
vec.fit(x_train)
# 把分类器import进来并且训练
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
classifier.fit(vec.transform(x_train), y_train)
# 看看我们的准确率如何
s = classifier.score(vec.transform(x_test), y_test)
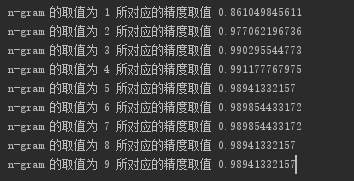
print('n-gram 的取值为',n,'所对应的精度取值',s)
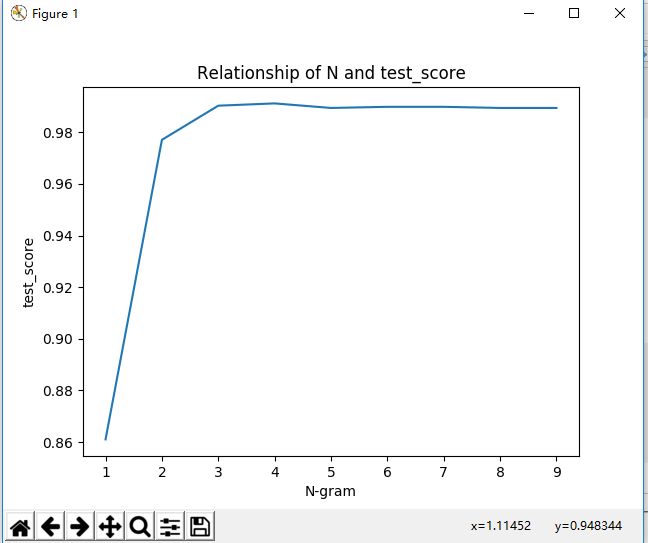
test_score_list.append(s)由下图可以看出当ngram的取值为4是精度最高:
画出不同gram的不同取值对最后结果的影响
import matplotlib.pyplot as plt
plt.plot(N, test_score_list)
plt.title('Relationship of N and test_score')
plt.xlabel('N-gram')
plt.ylabel('test_score')
plt.show()图如下: