Oracle数据库(一)准备知识和SQL语句基础
***准备知识
1、Oracle的卸载

- oracle安装完成后,所有服务设置为手动,只启动实例服务和监听服务即可
- sqlplus密码不回显
2、sqlplus命令总结

3、scott用户表结构
- dept部门表、emp员工表、salgrade工资等级表、bonus工资条表
4、Oracle数据库、实例、表空间、用户、数据文件和数据表之间的关系

- oracle 数据库和其他数据库不一样的是 oracle 的表和其他的数据库对象都是存在用户下的;
一、SQL基本分类
1 DDL
命令:CREATE、ALTER 、DROP
修改表结构
ALTER TABLE
MODIFY (column definition);
ADD (column definition);
DROP COLUMN column;
查看表结构
DESC ;
给表里的字段加上约束条件
ALTER TABLE 表名 ADD CONSTRAINT PRIMARY KEY (字段名);
ALTER TABLE 表名 ADD CONSTRAINT UNIQUE (字段名);
改表名
alter table persons2 rename to personone;
改列名
alter table persons rename COLUMN name to pname;
2 DQL
命令:SELECT…FROM…WHERE…
- distinct是对行去重,不是对列去重
- select可以输出常量,数字原样输出,字符串加单引号,可以用 || 拼接
3 DML
命令:INSERT、UPDATE、DELETE
--oracle数据库批量insert
insert all into persons2 values(1,'haha',23)
into persons2 values(2,'haha',23)
into persons2 values(3,'haha',23)
into persons2 values(4,'haha',23)
into persons2 values(5,'haha',23)
select 1 from dual;4 DCL
命令:GRANT、REVOKE、COMMIT、ROLLBACK
授予对象权限
GRANT SELECT,UPDATE ON order_master
TO MARTIN;
取消对象权限
REVOKE SELECT,UPDATE ON order_master
FROM MARTIN;
事务相关
UPDATE xxx;
SAVEPOINT mark1;
DELETE FROM xxx;
SAVEPOINT mark2;
ROLLBACK TO SAVEPOINT mark1;
COMMIT;
二、where | group by | order by | having等关键词的使用
--执行顺序
select from where group by having order by1、关于聚合函数和 group by
- 查询列使用聚合函数,如果没有使用别名,用原列名进行group by 不会报错
- 使用聚合函数的列如果使用别名,且group by 后面跟别名则会报错
- select中有聚合函数但是后面没有group by,则select子句中不能再出现其他的字段
- 使用了group by 后select子句中只能出现聚合函数和分组字段
- 聚合函数嵌套之后,select子句中只能嵌套的聚合函数,不能包含其他的字段
2、伪列 rowid 和 rownum(伪表dual)
-
rownum(行号)
- 行号是自动生成的,但是一旦select出来就是临时表的一个列了,是固定的值
- rownum 只能用小于
- 行号的应用:查询第一行;查询第n到m行(实现分页操作),具体代码的形式如下

- rowid
- 数据行唯一的物理地址的编号(案例:数据去重并保留最早的数据)
3、关于限定查询 where
- select 中定义的别名在 where 中不能使用
- not in 和 null 不能一起使用
- is null 和 is not null
- null 做计算结果为 null
- 多条件用 and 和 or 连接的时候每个条件用()分割
- where不许使用聚合函数(统计函数),这也是他和 having 不同的地方
4、关于 order by
- 最后执行,可以使用select中定义的别名
- order by 后面可以跟多个字段,实现按多字段的排序
5、关于执行顺序
- from > where > group by > having > select > order by
三、多表关联查询与子查询
###准备
- 多表查询产生笛卡尔积,查询后的行数是各表的行数相乘;
- 使用连接条件就是为了去除无用的笛卡尔积;
1、表连接
(1)自连接:FROM e , e1 WHERE e.id = e1.id
(2)外连接:
- 左外连接:FROM e JOIN d ON e.id = d.id(+)
- 右外连接:FROM e JOIN d ON e.id(+) = d.id
- 全外连接(SQL99里的语法):A full outer join B on 条件
- 外连接的另一种写法:
select e.ename,e.deptno,d.dname from emp e,dept d where e.deptno = d.deptno;(3)说明:
- 使用连接时:(+)是 oracle 的独有写法,一般是 (left)right join on
- 使用连接是为了消除无效的笛卡尔积
- 要有关联字段才能实现多表查询
- 关联字段不局限于等于的连接
- 超过2个表,加一个表加一个连接条件
- 可以关联自身查询
- 多表查询的关键在于确定要查哪些表和表之间的关联条件是什么
- sql1999多表查询语法,如下:

2、子查询(单行|多行)
- from子句中使用子查询:子查询的结果是多行多列,看成一个临时表作为数据源
- where子句中使用子查询:子查询的结果可以是单行单列,多行单列(in | not in)或者单行多列,单行多列的情况比较少
- having子句中使用子查询:当使用了聚合函数后才会使用
- select子句中的子查询一般不使用
- 关于确定数据范围的 in all(比所有数据大)any(比任意一个大)
- 子查询的效率高于多表查询,尽量少用多表查询
3、结果集的交并差
| 并集 | union(去重) union all(不去重) |
| 交集 |
intersect |
| 差集 | minus |
- 可以不断连接查询结果,前提是要保证列字段相同
四、常用函数
1 单行函数:字符|数值|日期|转换|通用
| 字符串函数 |
| length、substr、trim、replace、||(拼接字符串) |
- oracle 区分大小写
- oracle 字符串的索引左边从1开始,右边从-1开始
- substr函数在oracle里支持负索引的截取
| 数值函数 |
| round(3.1415926,3) 四舍五入 |
| trunc(3.1415926,3) 直接按位截取 |
| mod(列1,列2) 求余数 |
| 日期函数 |
| sysdate 当前日期(伪列) |
| last_day(sysdate) 当月最后一天 |
| next_day(sysdate,'星期日') 下次出现星期日的日期 |
| add_months(sysdate, 4) 4个月之后的日期 |
| months_between('1-2月-2017',sysdate) 两个日期之间的月份 |
- 日期1-日期2 = 天数
| 转换函数(进行数据类型的转换) |
| to_char、to_date、to_number |
- to_char(sysdate,‘mm’)可以截取年月日
- to_char 第二个参数是转换格式,如果是数字转字符的话,9表示任意的数字,L表示本地的货币符号
- oracle有类型的自动转换机制(隐式转换)
| 通用函数(适用于所有的数据类型以及空值) |
| nvl(列名,0) 处理空值 |
| decode(列名,if1,then1,if2,then2......else) 列的值为if1则返回then1,if2则返回then2,否则返回else的值 |
2 聚合函数(多行)
| avg,max,min,sum,count(跨行对列进行计算) |
- count不会统计字段为null
五、数据更新与事务管理
1、数据更新
- 表的复制:create table myemp as select * from emp
- 数据插入:字段名不写的时候数据的值要根据表中的顺序插入而且不能有少数据的情况;插入时间和时间磋的时候可以用to_date进行转换
- 数据更新:update 一定要用 where 子句来限定
- 数据删除:工作中删除操作要慎重,通常用逻辑删除,而不用物理删除
2、事务管理
- 数据表的增删改会涉及到数据的变化,要考虑到数据的完整性,因此引入事务;
- 统一业务分步完成,要么全成功,要么全失败;
- 数据库通过缓冲区实现事务的管理;
- 一个session:一个会话 、一个用户 、一个独立的事务处理;
- commit 和 rollback;
- 死锁的概念:两个session操作同一条数据,一方进行了跟新,且没有进行提交或者回滚,另一方则处于等待,反之也是这样
- 发生 ddl 操作数据自动提交;
3、事务的隔离级别
(1)四种隔离级别
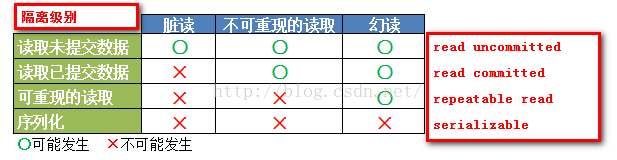
(1)说明:
- 脏读:一个事务读取另一个事务尚未提交的修改就是脏读;
- 不可重复读:同一查询在同一事务中多次进行,在此期间,其他事务提交了对数据的修改或删除,每次返回不同的结果;
- 幻读:同一查询在同一事务中多次进行,其他事务做了插入操作并提交了,虽查询条件相同,但每次返回的结果集不同;
- oracle 支持后面的三种事务隔离级别,默认是 read committed;
- 四种隔离级别从上到下:安全级别越来越高,性能越来越差;
六、表的创建与管理
1、常用的数据类型
-
varchar2(m)、number(n,m)、DATE、CLOB(大文本类型)
2、表的创建
3、表的重命名
- rename old to new
- 数据字典的概念:oracle数据库对象通过数据字典来管理(user_tables就是一个数据字典)
4、截断表(truncate)
5、复制表(结构复制)
6、删除表
7、闪回技术(oracle)
- 强制删除表:drop table myemp purge
- 清空回收站:purge recyclebin
8、修改表结构(不建议使用)
9、总结:

七、约束创建与管理
1、非空约束:not null
2、唯一约束:unique
- 可以通过给约束起别名的方法来是约束报错的信息更加具体:constraint uk_email unique(email)
3、主键约束:primary key(非空唯一)
- 复合主键:所有字段均相同才重复,一般不使用;
- 指定主键约束的名字:
constraint pk_pid primary key(pid)4、检查约束:check
- 用途:约束字段的合法范围
- 写一个类似 where 子句的过滤条件
- 检查约束越多速度越慢
5、外键约束:foreign key reference
(1)限制一:两个表存在主外键关系,要先删除子表才能删除父表,或者采取强制删除的方法
drop table member cascade constraint(2)限制二:父表关联子表外键的字段必须设置唯一约束或者主键约束
(3)限制三:删除父表的数据的时候,如果子表存在对应的记录,则父表的数据无法删除,解决方法有两个:
- 级联删除:on delete cascade
- 级联更新:on delete set null
6、添加和删除约束
- 添加非空约束只能采取修改表结构的方法
- 删除约束的语法:alter table emp drop constraint pk
- 添加约束一定要设置名称
八、使用总结
1、关于空值(null)
(1)空值不等与空值;
(2)包含 null 的表达式永远为 null;
(3)排序时的空值处理:通过以下方式放在最前面或者末尾

(4) 聚合函数会忽略空值,nvl 使聚合函数无法忽略空值;
(5)子查询的空值问题:
- 单行:任何值都不等于空值;
- 多行:not in 不能和 null 共用;
2、sql 优化
(1)select * 和count(*)等表述方式比较慢,建议使用具体的字段;
(2)子查询的效率高于多表查询,尽量少用多表查询;