spark+scala+springboot整合(jar包不冲突版本)
spark+scala+springboot+thymeleaf+echarts
springboot可以快速搭建一个web框架,之前对pom中的依赖配置不是怎么在意,但是经历过spark和scala版本问题的坑之后,发现想配置一个不出现jar包冲突的pom是多么不容易
源码地址:https://github.com/pitt1997/SpringBootSparkTest.git
scala版本:2.11.12
spark版本:2.3.0
jdk版本:1.8
pom.xml文件:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.cngroupId>
<artifactId>spring-boot-04-web-restful-crudartifactId>
<version>0.0.1-SNAPSHOTversion>
<packaging>jarpackaging>
<name>spring-boot-04-web-restful-crudname>
<description>Demo project for Spring Bootdescription>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8project.reporting.outputEncoding>
<java.version>1.8java.version>
<scala.version>2.11scala.version>
<spark.version>2.3.0spark.version>
<thymeleaf.version>3.0.9.RELEASEthymeleaf.version>
<thymeleaf-layout-dialect.version>2.2.2thymeleaf-layout-dialect.version>
properties>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>1.5.9.RELEASEversion>
<relativePath />
parent>
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<exclusions>
<exclusion>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
exclusion>
<exclusion>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
exclusion>
exclusions>
<version>3.1.0version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-aopartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-thymeleafartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>${spark.version}version>
<exclusions>
<exclusion>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
exclusion>
<exclusion>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
exclusion>
exclusions>
<scope>compilescope>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>org.codehaus.janinogroupId>
<artifactId>janinoartifactId>
<version>3.0.8version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-configuration-processorartifactId>
<optional>trueoptional>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
project>
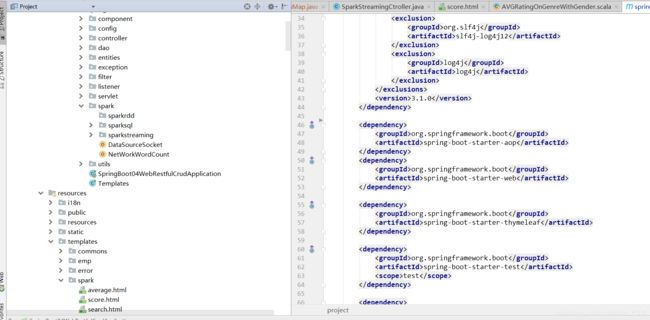
目录结构:
controller里面调用Scala程序:

Scala类:KeepFileDirectory (SparkStreaming处理监听一个文件夹流的变化)
如果放到容器里面的话需要假如@Component注解。

@Component
class KeepFileDirectory {
def start() {
StreamingExample.setStreamingLogLevels()
//local[2]
val conf = new SparkConf().setMaster("local").setAppName("NetWorkWordCount")
//时间间隔:1s
val ssc = new StreamingContext(conf, Seconds(3))
//ssc.sparkContext.setLogLevel("ERROR")
//指定输入流文件夹
val lines = ssc.textFileStream("E:\\Beta\\Spark\\data\\final")
val result = lines.filter(line => (line.trim().length > 0) && line.split("\\s+").length == 4)
.map(row => (row.split("\\s+")(1).toInt, row.split("\\s+")(2).trim().toFloat))
.foreachRDD(rdd =>
rdd.foreach { x =>
println("到达result:" + x._1)
MovieRating.movieIdList.add(x._1)
MovieRating.scoreList.add(x._2)
}
)
val res = lines.filter(_.trim().length > 0).map(line => (line.split("\\s+")(1).trim().toInt,
line.split("\\s+")(2).trim().toFloat)).groupByKey()
.map(
x => {
var n = 0
var sum = 0.0
for (i <- x._2) {
sum = sum + i
n = n + 1
}
val avg = sum / n
val format = f"$avg%1.2f".toDouble
(x._1, format) //以(电影Id,平均分)格式输出至文件里面
})
res.print()
println(res)
res.foreachRDD { rdd =>
rdd.foreach {
v =>
println(v)
println("电影Id:" + v._1)
println("电影平均分:" + v._2)
MovieRating.map.put(v._1.toString, v._2.toFloat)
MovieRating.tmpMap.put(v._1.toString, v._2.toFloat)
println("map:" + MovieRating.map.get(v._1.toString))
println("tmpMap:" + MovieRating.tmpMap.get(v._1.toString))
}
}
//开始循环监听
ssc.start()
ssc.awaitTermination()
}
}
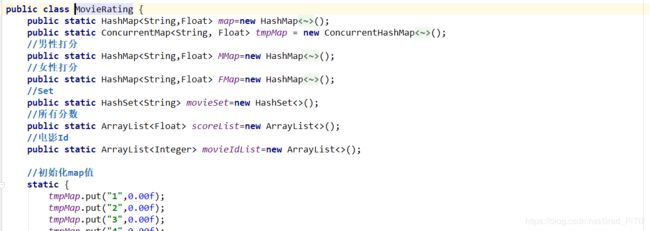
MovieRating类里面的静态变量属性作为存储数据的载体让其他程序接口使用
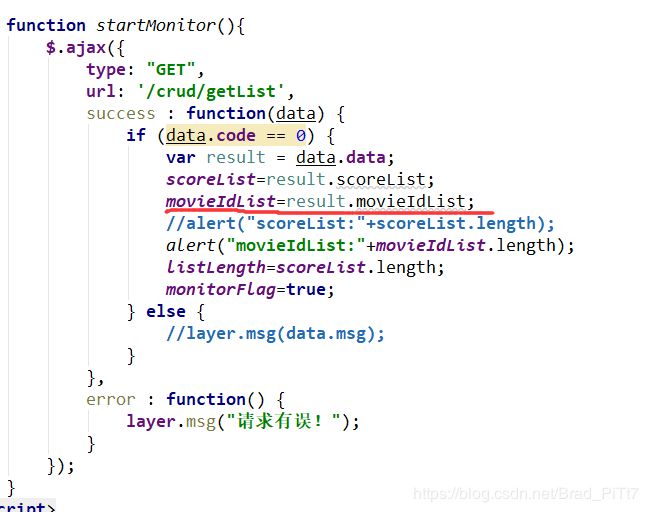
接收前端请求获取打分的list列表数据,然后返回,在前端echarts上动态显示。
@RequestMapping(value = "/getList", method = RequestMethod.GET)
@ResponseBody
public Result<ResultLists> getList(Model model) {
ResultLists resultLists=new ResultLists();
ArrayList <Integer>mlist=new ArrayList();
ArrayList <Float>slist=new ArrayList();
mlist.addAll(MovieRating.movieIdList);
slist.addAll(MovieRating.scoreList);
resultLists.movieIdList=mlist;
resultLists.scoreList=slist;
//清空list
MovieRating.movieIdList.clear();
MovieRating.scoreList.clear();
return Result.success(resultLists);
}
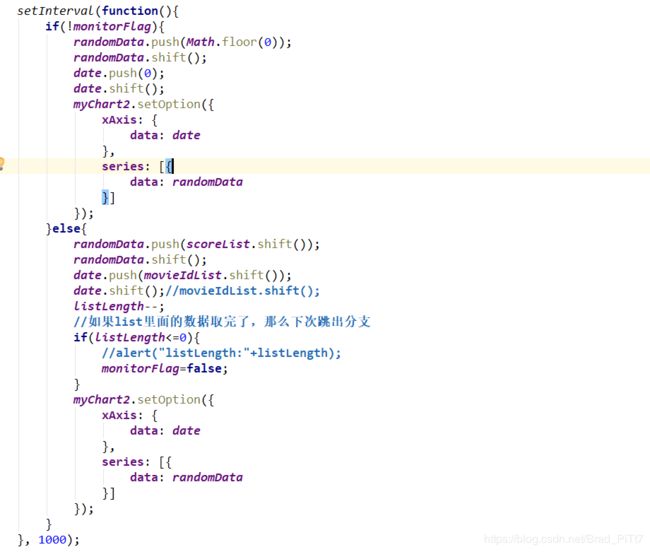
定义每秒回调自己的方法实现从右到左依次动态变化:
如果没获取后台数据,那么就都推入0,如果获取到后端返回的list数组,那么就显示list里面的数据
未上传文件的时候:

上传文件之后:

SparkSQL处理数据,显示对男女对不同电影打分的平均分:
