CrowdPose: Efficient Crowded Scenes Pose Estimation and A new Benchmark
arxiv
上交卢策武团队新出的关于多人pose的文章.和alphapose一样属于top-down的方法.该文并没有着重于设计新的网络结构,而转向于设计新的label和loss计算方式,从而提高原有的网络pose检测能力.
首先文章指出, 多人pose这部分已经发展的很快,并且效果也挺好.但目前而言,所有的多人pose都是在类似于公开的COCO, MPII, ai-challenger等这些数据集上训练,而这些数据集并没有特意的去区分哪些是’crowd scene’, 哪些不是.所以,这些多人pose网络在这些数据集上的训练效果,可能没有办法很好的去解决’crowd scene’这种情况.因此,文章根据这个现状,提出了一个新的dataset(CrowdPose dataset)以及一个新的loss计算方法.
CrowdPose Dataset
首先文章提出了一个’crowd index’用来表示图片’crowd’的程度,计算方式如下:
n表示图片上总共有多少个人, 分母表示第 i i i个人总共标注了多少个关键点,分子表示在这个人的 b b o x bbox bbox里面,有多少个关键点不属于这个人但却出现在这个人的 b b o x bbox bbox内(所以才叫’crowd’). 显而易见,这个值越大,说明人’crowd’的程度越严重.
文章收集了一系列的图片,全部使用14joints表示,一开始粗略使用了30000张图片,然后从这里面挑选出20000张质量好的图片,作为crowd dataset.下图文章使用的crowd dataset和其它开源的数据集在 crowd index上的一个对比:

Loss Design
以往的多人pose模型loss,都是简单的把不属于当前这个人的joint当做背景直接抑制掉.文章认为直接抑制掉这些joint不利于最后的推理.因为虽然这些关节点不属于这个人,但它确实另外一个人的正确的关节点.文章把在一个人的region内的属于它的关节点叫做target joints, 在其内的不属于这个人的关节点叫做interference joints. 在计算loss的时候,会根据joint的类别给个权重计算loss,这样可以即抑制了interference joints又保留了只不过其所占比重略低. 我可能说的不大清楚,还是直接看原文吧:

Person-Joint Graph
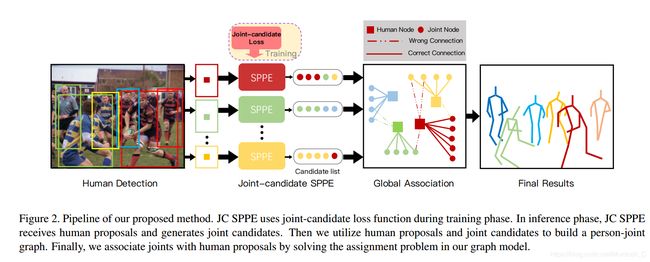
除了改变loss的计算方式,文章还提出了另外一个改进的地方,就是不使用传统的NMS去提取关节点而是构建一个Person-Joint Graph来整理最后得到的关节点. 首先,由于是crowd scene, 那么两个不同的人提取出的框就有很大一部分重叠,这就造成同一个人的同一个关节处会多次重复提取得到不同位置的点.如果直接根据每个关节点的响应值来构建最后的pose, 那么crowd严重的两个人有可能连到同一个点上去.因此,在构图之前,先把有歧义的点想除掉,具体方法就是判断两个点的欧氏距离,如果小于设定的阈值,就认为是同一个人的同一个点.还是看原文吧:

然后,就是构建Person-Joint Graph. 已human instance和joint node为图的节点, 将 joint node和human instance分别相连, 注意此时有可能连错, 因为一个人可能连到了其他人的关节点.这样,每个点都和一个人或者多个人连接起来,这就是一条边,边的权重就是该点的响应值. 我们前面提到过,一个human instance里提取出的关键点可能有两类,一类是target joints,这个是正确的属于当前人的关节点, 一类是interference joints, 这个是不正确的点. 而在loss计算的时候,我们会抑制interference joints,即最终我们得到的结果, interference joints的响应值应该比target joints响应值更低,即对应的边的权重更低.下一步就是在这个person-joint graph里找到有最大权值的子图. 方法如下:

个人理解
我觉得文章最主要的地方在于提出target joints和interference joints这个概念,因为以往从来没想过, 都是直接保留target joints, 非target joints就直接抑制掉了.文章保留了这两类点,并且打上不同比重的label, 从而让网络有意的去学习这两类点,最后再通过构建图的方法来求得最优解. 文章说code和dataset近期会开源,期待~~