深入浅出SVM(支持向量机)
支持向量机是机器学习领域中经典的分类算法之一,最早由Corinna Cortes, Vladimir Vapnik于1995年提出。对原论文感兴趣的读者可下载此论文Support-Vector Network
简介
分类学习的最基本思想就是基于给定的训练集 D D D,在样本空间中寻找一个划分超平面,将不同类别的样本分开。假如有一样本集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x m , y m ) } D = \{(x_1, y_1), (x_2, y_2), \dots, (x_m, y_m) \} D={(x1,y1),(x2,y2),…,(xm,ym)},它的划分超平面可能存在很多个,如下图所示。那我们应该选取哪一个呢?
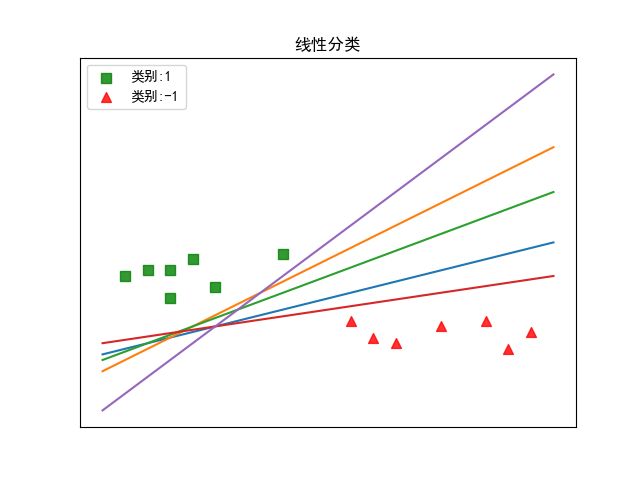
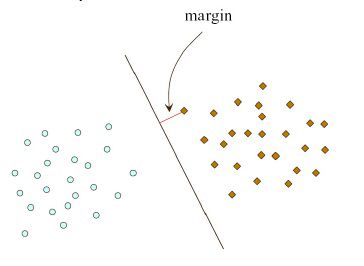
直观上看,我们应该选取正中间的划分超平面,即图中的绿色超平面。因为该划分超平面对训练样本的数据扰动“容忍性”最好,即鲁棒性最好,泛化能力最强。而且的确有理论证明,拥有最大间隔的划分超平面泛化能力最强,如下图所示(摘自常虹老师的《Support Vector Machine》)。其中,间隔就是距离划分超平面最近的点与划分超平面间的距离。
在样本空间中,划分超平面可通过如下线性方程描述,
w T x + b = 0 \bf{w}^{T}\bf{x} + b = 0 wTx+b=0
其中, w = ( w 1 , w 2 , … , w n ) \bf{w} = (w_1, w_2, \dots, w_n) w=(w1,w2,…,wn)是法向量,决定了超平面的方向。 b b b是位移项,决定了超平面与源点间的截距。因此,样本空间中任意点 x x x到划分超平面的距离即为,
d = ∣ w T + b ∣ ∣ ∣ w ∣ ∣ d = \frac{|\bf{w}^{T} + b|}{||\bf{w}||} d=∣∣w∣∣∣wT+b∣
假定超平面能将训练样本正确分类,即对于 ∀ ( x i , y i ) ∈ D \forall\ (x_i, y_i) \in D ∀ (xi,yi)∈D,如果 y i = 1 y_i = 1 yi=1,则 w T x + b > 0 \bf{w}^{T}\bf{x} + b > 0 wTx+b>0,相反则有 w T x + b < 0 \bf{w}^{T}\bf{x} + b < 0 wTx+b<0,即有
{ w T x i + b ≥ 1 , y i = 1 w T x i + b ≤ 1 , y i = − 1 \left\{ \begin{aligned} \bf{w}^{T}\bf{x_i} + b \ge 1 &, y_i = 1 \\ \bf{w}^{T}\bf{x_i} + b \le 1 &, y_i = -1 \\ \end{aligned} \right. {wTxi+b≥1wTxi+b≤1,yi=1,yi=−1
可能有读者疑问,之前不是以0为样本划分的分界点吗?这里又为何改为1了?其实,如果超平面能正确划分样本,那么总存在缩放能使得上式成立。
此外,我们将使上式等号成立的点称为支持向量,两个异类的支持向量到超平面的距离之和,
γ = 2 ∣ ∣ w ∣ ∣ \gamma = \frac{2}{||\bf{w}||} γ=∣∣w∣∣2
即为我们前面所说的间隔。因此,为找到最大间隔的划分超平面以使得模型泛化能力最强,我们需要,
m a x 2 ∣ ∣ w ∣ ∣ s . t . y i ( w T x i + b ) ≥ 1 , i = 1 , 2 , … , m \begin{aligned} &max \quad \frac{2}{||\bf{w}||} \\ &s.t. \quad y_i(\bf{w}^{T}x_i + b) \ge 1, i = 1, 2, \dots, m \end{aligned} max∣∣w∣∣2s.t.yi(wTxi+b)≥1,i=1,2,…,m
不难看出,最大化 2 ∣ ∣ w ∣ ∣ \frac{2}{||\bf{w}||} ∣∣w∣∣2等价于最小化 ∣ ∣ w ∣ ∣ 2 ||\bf{w}||^{2} ∣∣w∣∣2(后面,我会解释为什么需要这样改写)。因此,上式可改写为,
m i n 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y i ( w T x i + b ) ≥ 1 , i = 1 , 2 , … , m \begin{aligned} &min \quad \frac{1}{2}||\bf{w}||^{2}\\ &s.t. \quad y_i(\bf{w}^{T}x_i + b) \ge 1, i = 1, 2, \dots, m \end{aligned} min21∣∣w∣∣2s.t.yi(wTxi+b)≥1,i=1,2,…,m
这就是支持向量机的原型。
算法推导
前面说到,为获得最优划分超平面,我们需要求解下式,
m i n 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y i ( w T x i + b ) ≥ 1 , i = 1 , 2 , … , m \begin{aligned} &min \quad \frac{1}{2}||\bf{w}||^{2} \\ &\begin{aligned} s.t. \quad &y_i(\bf{w}^{T}x_i + b) \ge 1, i = 1, 2, \dots, m \end{aligned} \end{aligned} min21∣∣w∣∣2s.t.yi(wTxi+b)≥1,i=1,2,…,m
这是一个典型的二次优化问题。与一般的优化问题相比,二次优化是较难解决的。然而,“稳住,我们能赢!”。因为,我们有拉格朗日大神!(再次拜服拉格朗日老前辈)。利用大名鼎鼎的拉格朗日乘子法,我们可以轻松解决这类问题。对拉格朗日问题感兴趣的同学,可以观看我的另一篇博客——原来拉格朗日乘子法这么简单!。
因此,根据拉格朗日乘子法,我们有,
L ( w , b , λ ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 m λ i ( 1 − y i ( w T x i + b ) ) L(\mathbf{w}, b, \mathbf{\lambda}) = \frac{1}{2}||\mathbf{w}||^{2} + \sum_{i = 1}^{m}\lambda_i(1 - y_i(\mathbf{w}^{T}\mathbf{x}_i + b)) L(w,b,λ)=21∣∣w∣∣2+i=1∑mλi(1−yi(wTxi+b))
其中, λ = ( λ 1 , λ 2 , … , λ m ) , λ i ≥ 0 \mathbf{\lambda} = (\lambda_1, \lambda_2, \dots, \lambda_m), \lambda_i \ge 0 λ=(λ1,λ2,…,λm),λi≥0是对应的拉格朗日乘子。令 L ( w , b , λ ) L(\mathbf{w}, b, \mathbf{\lambda}) L(w,b,λ)对 w \mathbf{w} w和 b b b求偏导,并为零,得,
w = ∑ i = 1 m λ i y i x i 0 = ∑ i = 1 m λ i y i \begin{aligned} \mathbf{w} &= \sum_{i = 1}^{m}\lambda_iy_i\mathbf{x}_i \\ 0 &= \sum_{i = 1}^{m}\lambda_iy_i \\ \end{aligned} w0=i=1∑mλiyixi=i=1∑mλiyi
将上式代入拉格朗日函数,可得,
max λ ∑ i = 1 m λ i − 1 2 ∑ i = 1 m ∑ j = 1 m λ i λ j y i y j x i T x j s . t . ∑ i = 1 m λ i y i = 0 λ i ≥ 0 , i = 1 , 2 , … , m \begin{aligned} &\max\limits_{\mathbf{\lambda}} \quad \sum_{i = 1}^{m}\lambda_i - \frac{1}{2}\sum_{i = 1}^{m}\sum_{j = 1}^{m} \lambda_i \lambda_j y_i y_j \mathbf{x}_i^{T} \mathbf{x}_j \\ &\begin{aligned} s.t. \qquad &\sum_{i = 1}^{m}\lambda_iy_i = 0 \\ &\lambda_i \ge 0, i = 1, 2, \dots, m \\ \end{aligned} \end{aligned} λmaxi=1∑mλi−21i=1∑mj=1∑mλiλjyiyjxiTxjs.t.i=1∑mλiyi=0λi≥0,i=1,2,…,m
因此,求解出 λ \mathbf{\lambda} λ之后,即可得到模型,
f ( x ) = w T x + b = ∑ i = 1 m λ i y i x + b \begin{aligned} f(\mathbf{x}) &= \mathbf{w}^{T}\mathbf{x} + b \\ &= \sum_{i=1}^{m} \lambda_iy_i \mathbf{x} + b \\ \end{aligned} f(x)=wTx+b=i=1∑mλiyix+b
而在求解过程中,根据拉格朗日乘子法,我们不难发现上述过程满足KKT条件,
{ λ i ≥ 0 y i f ( x i ) − 1 ≥ 0 λ i ( y i f ( x i ) − 1 ) = 0 \left\{ \begin{aligned} \lambda_i &\ge 0 \\ y_if(\mathbf{x}_i) - 1 & \ge 0 \\ \lambda_i(y_if(\mathbf{x}_i) - 1) &= 0\\ \end{aligned} \right. ⎩⎪⎨⎪⎧λiyif(xi)−1λi(yif(xi)−1)≥0≥0=0
因此,对于任意样本 ( x i , y i ) (\mathbf{x}_i, y_i) (xi,yi),总有 λ i = 0 \lambda_i = 0 λi=0或者 y i f ( x i ) = 1 y_if(\mathbf{x}_i) = 1 yif(xi)=1。若 λ i = 0 \lambda_i = 0 λi=0,则对应样本不会在求和过程中出现,即不会对最终的划分超平面产生影响;若 λ i > 0 \lambda_i > 0 λi>0,则必有 y i f ( x i ) = 1 y_if(\mathbf{x}_i) = 1 yif(xi)=1,则对应样本位于最大间隔边界上,即是一个支持向量。这显示出支持向量机的一个重要性质:最终的划分超平面只与支持向量有关,大部分的样本都无需保留。
于是,我们可以这一性质,求解出
b = 1 ∣ S V ∣ ∑ x i ∈ S V ( y i − w T x i ) b = \frac{1}{|SV|}\sum_{\mathbf{x}_i \in SV}(y_i - \mathbf{w}^{T}\mathbf{x}_i) b=∣SV∣1xi∈SV∑(yi−wTxi)
可是,又如何求解出 λ \lambda λ呢?如果 λ \lambda λ未知,我们是无法求解出模型 f ( x ) f(\mathbf{x}) f(x)的。幸好,人们利用问题本身的特性,设计了很多高效算法,SMO算法是其中著名的一个代表。
SMO算法的思路很简单——在参数初始化之后,重复以下两个步骤直至收敛:
- 选取一对需更新的变量 λ i \lambda_i λi和 λ j ; \lambda_j; λj;
- 固定 λ i \lambda_i λi和 λ j \lambda_j λj之外的参数,求解对偶函数获得更新后的 λ i \lambda_i λi和 λ j . \lambda_j. λj.
至此,支持向量机的基本思路已经阐述完毕,是不是很简单啊,一目了然!
软间隔与正则化
在前面的讨论中,我们假设存在一个超平面能将所有样本正确划分。然而,在现实生活中,很难找到能正确划分全部样本的超平面,如下图所示(摘自周志华老师的《机器学习》)。

缓解该问题的方法一个方法就是允许支持向量机在一些样本上出错,即引入松弛变量 ξ \xi ξ,
y i ( w T x i + b ) ≥ 1 − ξ i y_i(\mathbf{w}^{T}\mathbf{x}_i + b) \ge 1 - \xi_i yi(wTxi+b)≥1−ξi
而这就是我们所说的软间隔。显而易见,硬间隔要求对所有样本划分正确。当然,在最大化间隔的同时,不满足约束的样本应尽可能地少。于是,优化目标改写为,
min w , b , ξ i 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ξ i s . t . y i ( w T x i + b ) ≥ 1 − ξ i , ξ i ≥ 0 , i = 1 , 2 , … , m \begin{aligned} &\min\limits_{\mathbf{w}, b, \xi_i} \quad \frac{1}{2}||w||^{2} + C\sum_{i = 1}^{m}\xi_i \\ &\begin{aligned} s.t. \quad & y_i(\mathbf{w}^{T}\mathbf{x}_i + b) \ge 1 - \xi_i, \\ & \xi_i \ge 0, i = 1, 2, \dots, m \\ \end{aligned} \end{aligned} w,b,ξimin21∣∣w∣∣2+Ci=1∑mξis.t.yi(wTxi+b)≥1−ξi,ξi≥0,i=1,2,…,m
这里, C C C是正则化因子,用于平衡边界最大化和训练误差最小化。
因此,有拉格朗日函数,
L ( w , b , λ , μ ) = 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i ξ i + ∑ i = 1 m λ i [ 1 − ξ i − y i ( w T x + b ) ] − ∑ i μ i ξ i L(\mathbf{w}, b, \mathbf{\lambda}, \mathbf{\mu}) = \frac{1}{2}||\mathbf{w}||^{2} + C\sum_{i}\xi_i + \sum_{i = 1}^{m}\lambda_i[1 - \xi_i - y_i(\mathbf{w}^{T}\mathbf{x} + b)] - \sum_i \mu_i \xi_i L(w,b,λ,μ)=21∣∣w∣∣2+Ci∑ξi+i=1∑mλi[1−ξi−yi(wTx+b)]−i∑μiξi
这里, λ i ≥ 0 , μ ≥ 0 \mathbf{\lambda}_i \ge 0, \mathbf{\mu} \ge 0 λi≥0,μ≥0都是拉格朗日乘子。于是,我们利用拉格朗日乘子法求解,
max λ ∑ i = 1 m λ i − 1 2 ∑ i = 1 m ∑ j = 1 m λ i λ j y i y j x i T x j s . t . ∑ i = 1 m λ i y i = 0 0 ≤ λ i ≤ C , i = 1 , 2 , … , m \begin{aligned} &\max\limits_{\lambda} \quad \sum_{i = 1}^{m}\lambda_i - \frac{1}{2}\sum_{i = 1}^{m}\sum_{j = 1}^{m}\lambda_i \lambda_j y_i y_j \mathbf{x}_i^{T}\mathbf{x}_j \\ &\begin{aligned} s.t. \qquad &\sum_{i = 1}^{m}\lambda_iy_i = 0 \\ & 0 \le \lambda_i \le C, i = 1, 2, \dots, m\\ \end{aligned} \end{aligned} λmaxi=1∑mλi−21i=1∑mj=1∑mλiλjyiyjxiTxjs.t.i=1∑mλiyi=00≤λi≤C,i=1,2,…,m
不难看出,我们只需按照之前的步骤,即可求解软间隔的支持向量机。
核函数
细心的读者不难看出,本篇博客前面的讨论中,都假设样本是线性可分的。然而在现实任务中,原始样本空间也许并不存在一个能正确划分样本的超平面,即原始样本空间不是线性可分的,如下图所示。
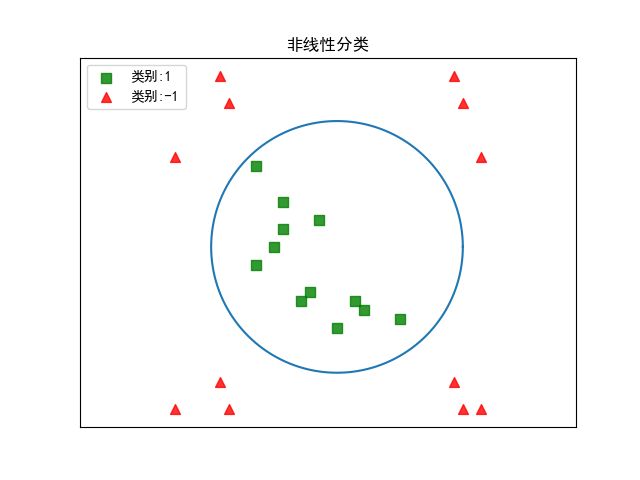
幸运的是,有理论证明,如果原始空间是有限维的,那么一定存在一个高维特征空间使样本可分。因此,对于这样的问题,可将原始样本空间映射到更高维的特征空间,使得样本在这个特征空间线性可分,如下图所示(摘自周志华老师的《机器学习》)。

令 ϕ ( x ) \phi(\mathbf{x}) ϕ(x)表示 x \mathbf{x} x映射后的特征向量。于是,在特征空间中划分超平面为,
f ( x ) = w T ϕ ( x ) + b f(\mathbf{x}) = \mathbf{w}^{T}\phi(\mathbf{x}) + b f(x)=wTϕ(x)+b
同样地,有优化函数,
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ξ i s . t . y i ( w T ϕ ( x ) + b ) ≥ 1 − ξ i ξ i ≥ 0 , i = 1 , 2 , … , m \begin{aligned} &\min\limits_{\mathbf{w, b}} \quad \frac{1}{2}||\mathbf{w}||^{2} + C\sum_{i = 1}^{m}\xi_i\\ &\begin{aligned} s.t. \quad &y_i(\mathbf{w}^{T}\phi(\mathbf{x}) + b) \ge 1- \xi_i \\ &\xi_i \ge 0, i = 1, 2, \dots, m \end{aligned} \end{aligned} w,bmin21∣∣w∣∣2+Ci=1∑mξis.t.yi(wTϕ(x)+b)≥1−ξiξi≥0,i=1,2,…,m
对偶问题即为
max λ ∑ i = 1 m λ i − 1 2 ∑ i = 1 m ∑ j = 1 m λ i λ j y i y j ϕ ( x i ) T ϕ ( x j ) s . t . ∑ i = 1 m λ i y i = 0 0 ≤ λ i ≤ C , i = 1 , 2 , … , m \begin{aligned} &\max\limits_{\lambda} \quad \sum_{i = 1}^{m}\lambda_i - \frac{1}{2}\sum_{i = 1}^{m}\sum_{j = 1}^{m}\lambda_i \lambda_j y_i y_j \phi(\mathbf{x}_i)^{T}\phi(\mathbf{x}_j) \\ &\begin{aligned} s.t. \qquad &\sum_{i = 1}^{m}\lambda_iy_i = 0 \\ & 0 \le \lambda_i \le C, i = 1, 2, \dots, m\\ \end{aligned} \end{aligned} λmaxi=1∑mλi−21i=1∑mj=1∑mλiλjyiyjϕ(xi)Tϕ(xj)s.t.i=1∑mλiyi=00≤λi≤C,i=1,2,…,m
不难看出,上式的求解涉及到 ϕ ( x i T ) ϕ ( x j ) \phi(\mathbf{x}_i^{T})\phi(\mathbf{x}_j) ϕ(xiT)ϕ(xj)的计算。然而由于特征空间维度很高,导致直接计算
ϕ ( x i ) T ϕ ( x j ) \phi(\mathbf{x}_i)^{T}\phi(\mathbf{x}_j) ϕ(xi)Tϕ(xj)十分困难。而核函数的出现解决了这一问题,
k ( x i , x j ) = ϕ ( x i ) T ϕ ( x ′ j ) k(\mathbf{x}_i, \mathbf{x}_j) = \phi(\mathbf{x}_i)^{T}\phi(\mathbf{x^{'}}_j) k(xi,xj)=ϕ(xi)Tϕ(x′j)
因此,有
max λ ∑ i = 1 m λ i − 1 2 ∑ i = 1 m ∑ j = 1 m λ i λ j y i y j k ( x i , x j ) s . t . ∑ i = 1 m λ i y i = 0 0 ≤ λ i ≤ C , i = 1 , 2 , … , m \begin{aligned} &\max\limits_{\lambda} \quad \sum_{i = 1}^{m}\lambda_i - \frac{1}{2}\sum_{i = 1}^{m}\sum_{j = 1}^{m}\lambda_i \lambda_j y_i y_j k(\mathbf{x}_i, \mathbf{x}_j) \\ &\begin{aligned} s.t. \qquad &\sum_{i = 1}^{m}\lambda_iy_i = 0 \\ & 0 \le \lambda_i \le C, i = 1, 2, \dots, m\\ \end{aligned} \end{aligned} λmaxi=1∑mλi−21i=1∑mj=1∑mλiλjyiyjk(xi,xj)s.t.i=1∑mλiyi=00≤λi≤C,i=1,2,…,m
求解后,即可得到
f ( x ) = w T x + b = ∑ i = 1 m λ i y i ϕ ( x i ) T ϕ ( x ) + b = ∑ i = 1 m λ i y i k ( x , x i ) + b \begin{aligned} f(x) &= \mathbf{w}^{T}\mathbf{x} + b \\ &= \sum_{i = 1}^{m}\lambda_iy_i\phi(\mathbf{x_i})^{T}\phi(\mathbf{x}) + b\\ &= \sum_{i = 1}^{m}\lambda_iy_ik(\mathbf{x}, \mathbf{x}_i) + b\\ \end{aligned} f(x)=wTx+b=i=1∑mλiyiϕ(xi)Tϕ(x)+b=i=1∑mλiyik(x,xi)+b
可见,核函数巧妙地解决了高维空间的特征向量内积计算的难题,为支持向量机解决非线性可分的问题提供了解决方案。而常用的核函数有以下几种:
- 线性核函数
k ( x i , x j ) = x i T x j k(\mathbf{x}_i, \mathbf{x}_j) = \mathbf{x}_i^{T}\mathbf{x}_j k(xi,xj)=xiTxj
- 多项式核函数
k ( x i , x j ) = ( x i T x j + 1 ) d k(\mathbf{x}_i, \mathbf{x}_j) = (\mathbf{x}_i^{T}\mathbf{x}_j + 1)^{d} k(xi,xj)=(xiTxj+1)d
- RBF核函数
k ( x i , x j ) = e x p ( − ∣ ∣ x i T − x j ∣ ∣ 2 s 2 ) k(\mathbf{x}_i, \mathbf{x}_j) = exp(-\frac{||\mathbf{x}_i^{T} - \mathbf{x}_j||}{2\bf{s}^{2}}) k(xi,xj)=exp(−2s2∣∣xiT−xj∣∣)
- Sigmoid核函数
k ( x i , x j ) = t a n h ( 2 x i T x j + 1 ) k(\mathbf{x}_i, \mathbf{x}_j) = tanh(2\mathbf{x}_i^{T}\mathbf{x}_j + 1) k(xi,xj)=tanh(2xiTxj+1)
不过,可能有读者对核函数仍抱有疑惑——它是如何找到对应的特征空间。以多项式核函数为例,假设 d = 2 d = 2 d=2,原始空间的维度 D = 2 D = 2 D=2,则
k ( x i , x j ) = ( x i T x j + 1 ) 2 = ( x 1 x 1 ′ + x 2 x 2 ′ + 1 ) 2 = 1 + 2 x 1 x 1 ′ + 2 x 2 x 2 ′ + 2 x 1 x 2 x 1 ′ x 2 ′ + ( x 1 ) 2 ( x 1 ′ ) 2 + ( x 2 ) 2 ( x 2 ′ ) 2 \begin{aligned} k(\mathbf{x}_i, \mathbf{x}_j) &= (\mathbf{x}_i^{T}\mathbf{x}_j + 1)^{2} \\ &= (\mathbf{x}_1\mathbf{x}^{'}_1 + \mathbf{x}_2\mathbf{x}^{'}_2 + 1)^{2} \\ &= 1 + 2\mathbf{x}_1\mathbf{x}^{'}_1 + 2\mathbf{x}_2\mathbf{x}^{'}_2 + 2\mathbf{x}_1\mathbf{x}_2\mathbf{x}^{'}_1\mathbf{x}^{'}_2 + (\mathbf{x}_1)^{2}(\mathbf{x}_1^{'})^{2} + (\mathbf{x}_2)^{2}(\mathbf{x}_2^{'})^{2}\\ \end{aligned} k(xi,xj)=(xiTxj+1)2=(x1x1′+x2x2′+1)2=1+2x1x1′+2x2x2′+2x1x2x1′x2′+(x1)2(x1′)2+(x2)2(x2′)2
因此,对应的特征向量为,
ϕ ( x ) = ( 1 , 2 x 1 , 2 x 2 , 2 x 1 x 2 , ( x 1 ) 2 , ( x 2 ) 2 ) T \phi(\mathbf{x}) = (1, \sqrt{2}\mathbf{x}_1, \sqrt{2}\mathbf{x}_2, \sqrt{2}\mathbf{x}_1\mathbf{x}_2, (\mathbf{x}_1)^{2}, (\mathbf{x}_2)^{2})^{T} ϕ(x)=(1,2x1,2x2,2x1x2,(x1)2,(x2)2)T
至此,核函数的基本概念已经为大家阐述完毕。
总结
支持向量机是一种对数据进行二元分类,其决策边界是对学习样本求解的最大边距超平面。其优缺点如下:
-
优点
- 支持向量机泛化能力强,可以证明支持向量机的泛化误差,
E m [ P ( E r r o r ) ] ≤ E m [ # o f S V s ] m E_m[P(Error)] \le \frac{E_m[\# \ of\ SVs]}{m} Em[P(Error)]≤mEm[# of SVs]
- 支持向量机很好地通过利用空间映射的思想和核函数的技巧解决了非线性分类问题,避免了维灾难难题;
- 支持向量机拥有很好的鲁棒性。其最终模型“抛弃”了大量的冗余样本,只与支持向量有关,而后者只占有很小的比例。
-
缺点
- 支持向量机的时间复杂度为 O ( N 3 ) O(N^{3}) O(N3),空间复杂度为 O ( N 2 ) O(N^{2}) O(N2)。因此,在样本数量很大时,支持向量机的分类效果不好;
参考文献
周志华,《机器学习》
常虹,《Support Vector Machines》