GAN系列:论文阅读——StyleGAN(A Style-based Generator Architecture for Generative Adversarial Networks)
这篇论文感觉理论上还蛮复杂的,第一遍实在不太懂,但效果比较好又舍不得放弃,硬头皮看第二遍了。但是官方代码好难好难!
StyleGAN中的style借用自图像风格迁移,之前也看过风格迁移的论文,图像的Gram矩阵一般可以表示它的风格也就是style。这篇文章是PG-GAN之后的,主要改变了生成器的结构实现无监督地生成可控性强的图像。
PG-GAN中是通过一层层地给生成器和判别器增添卷积层同时提高分辨率的方法来生成高质量图像的。StyleGAN的motivation就是发现这种渐进的方法其实能控制图像的不同特性,低分辨率也就是coarse层主要影响图像的姿态,脸型等高级特征,高分辨率主要影响背景发色等低级特征(结合感受野的概念理解,低分辨率的特征获取更多全局信息并加以处理,比如特征从线条经过多次卷积一步步会组合出形状,会更加抽象,具有更高级的语义信息)。但PG-GAN这种结构在递进添加层的时候没有任何控制条件,导致整体的特征和细微的特征间存在耦合,耦合就导致了图像可控性差,没办法对单个特征进行调节。StyleGAN于是寻找了一种无监督但又可控性强的方法:对不同level的卷积层进行操作。
1. latent code
在之前的GAN结构中,latent code主要用于生成器最初的输入,latent code就是一个随机向量,相比于图像而言,维度更低,更容易采样。GAN生成图像的随机性就在于latent code的随机性,因此自然会想到通过控制latent code控制生成的图像。CGAN就是在latent code后面再concatenate一个code,或者更高级的情况,latent code的每一个维度对应了图像中我们关注的特性,想改变图像的特征时就找到对应的维度调整latent code的值即可。这种情况就需要latent code的解耦和,如果code中的一个维度其实耦合了多个图像特征,我们就没办法轻松调整生成图像的特性了。那为什么latent code本身不是已经解耦和的呢?为什么要人为找办法去解耦和呢?文中提到的原因是latent code的设定是要一定程度上匹配图像分布的概率密度的:我的理解是如果训练集的图像有30%是蓝头发的动漫人物,latent code中就要存在一些code达到接近的比例对应蓝头发;那也会有很多其他图像特征对应着code,所以一个code往往参与了很多图像特征,大概就是耦合?
当latent code只用于生成器的输入层时,随着生成器的层数增多,它的影响应该会越来越微弱。StyleGAN中,生成器的输入变成了一个常量,而latent code分别作用于生成器的每一个卷积层后,以控制图像的生成。这里有两个重点:
1. latent code作用于卷积层之前有一个变换,可以达到解耦和
2. 解耦和后的latent code作用于每一卷积层,借鉴PG-GAN的递进概念,这些层所影响/控制的特征是不同的,于是latent code对不同level的特征们分别进行了控制
初始的latent code记作![]() ,经过非线性映射得到
,经过非线性映射得到![]() ,不改变维度依然是512,这个映射通过8层的MLP实现(就是全连接层吧)。然后经过仿射变换(affine transformations)得到可以表示style的
,不改变维度依然是512,这个映射通过8层的MLP实现(就是全连接层吧)。然后经过仿射变换(affine transformations)得到可以表示style的![]() ,利用
,利用![]() 完成adaptive instance normalization(AdaIN)操作,AdaIN公式如下:
完成adaptive instance normalization(AdaIN)操作,AdaIN公式如下:
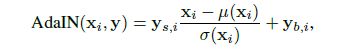
其中的下标 表示该层具体的第个feature map,所以这个操作是channel-wise的,那么仿射变换得到的
表示该层具体的第个feature map,所以这个操作是channel-wise的,那么仿射变换得到的![]() 应该是
应该是![]() 的维度,
的维度, 就是每一层卷积后的feature maps的channel数量。生成器结构如下图,虚线左侧是以前的结构,右侧是StyleGAN的结构:
就是每一层卷积后的feature maps的channel数量。生成器结构如下图,虚线左侧是以前的结构,右侧是StyleGAN的结构:

图(b)左侧就是把原始的![]() 做非线性映射,到
做非线性映射,到![]() ,再经过绿色方块A表示的仿射变换得到
,再经过绿色方块A表示的仿射变换得到![]() ,结合卷积层的输出进行AdaIN操作。相对于图像风格迁移任务,这里的style不是从图像中得到的,而是从latent code变换后得到的(风格迁移任务中有两类图像,一个是content images,一个是style images,风格迁移的目的就是保留content images的内容,用style images的风格呈现。因此基本结构可能是卷积提取content images的特征,然后加入style images提取的style,和这个StyleGAN把
,结合卷积层的输出进行AdaIN操作。相对于图像风格迁移任务,这里的style不是从图像中得到的,而是从latent code变换后得到的(风格迁移任务中有两类图像,一个是content images,一个是style images,风格迁移的目的就是保留content images的内容,用style images的风格呈现。因此基本结构可能是卷积提取content images的特征,然后加入style images提取的style,和这个StyleGAN把![]() 加进去的结构类似,这也是StyleGAN名字的来由)。
加进去的结构类似,这也是StyleGAN名字的来由)。
文中提到,从latent space采样并进行非线性映射和仿射变换的过程可以视作是从已学习到的分布中对某style图像采样,即每一层卷积后融入的style都是不同的,最后生成器相当于从这么多种styles的集合中生成一张新图像,这种方法使得每一种style产生的影响都是局部的(相当于把styles解耦和了,但是这里所谓的styles代表着什么呢?应该就是姿势,肤色到眼睛,嘴巴等特征吧),这样就可以很方便地操控图像的各种特征了。
那么这种解耦和是怎么实现的呢?主要是通过AdaIN模块,仔细观察这个公式:
上式中的![]() 是每个channel的feature map中利用所有pixels求得的均值和方差,也就是把所有特征图都变成了均值为0,方差为1。这个操作相当于清除了原始输入(那个常量4*4*512)的影响(应该也清除了前面style的影响吧,所以文中会说每个style只会影响其后面的那一层卷积)。然后再用表示了该层style的
是每个channel的feature map中利用所有pixels求得的均值和方差,也就是把所有特征图都变成了均值为0,方差为1。这个操作相当于清除了原始输入(那个常量4*4*512)的影响(应该也清除了前面style的影响吧,所以文中会说每个style只会影响其后面的那一层卷积)。然后再用表示了该层style的![]() 做scale和bias。这些操作都是channel-wise的,而每一个channel的feature map其实都是从图像中提取的一种特征,每一种特征进行了单独的scale和bias操作使得特征间的关系被改变了,这也就影响了style。这里感觉很奇妙的是对均值和方差的操作和后面加上style的操作可以看作是对应的:
做scale和bias。这些操作都是channel-wise的,而每一个channel的feature map其实都是从图像中提取的一种特征,每一种特征进行了单独的scale和bias操作使得特征间的关系被改变了,这也就影响了style。这里感觉很奇妙的是对均值和方差的操作和后面加上style的操作可以看作是对应的:![]() 的scale对应于
的scale对应于![]() ,
,![]() 对应于
对应于![]() 。
。
为了进一步实现style的解耦和,文中还采用了mixing regularization的操作:在训练时,用两个latent code生成一部分图像,也就是一张图像不是由一个latent code生成的各种style控制的,而是两个code。两个latent code会有两个非线性映射后得到的![]() ,在生成器中随机选取一个节点,该节点前使用
,在生成器中随机选取一个节点,该节点前使用 ,节点后使用
,节点后使用 。该方法可以阻止相邻styles的相关(大概是因为不同的latent code非线性映射后得到的style差距比一个latent code自己产生的要大,所以肯定styles间的关联更小,本身就更不耦合?),这里其实并不太懂,但通过实验的图像能看出latent code在不同层改变时确实影响的是很准确的不同的特征,说明style的解耦和还蛮成功的。
。该方法可以阻止相邻styles的相关(大概是因为不同的latent code非线性映射后得到的style差距比一个latent code自己产生的要大,所以肯定styles间的关联更小,本身就更不耦合?),这里其实并不太懂,但通过实验的图像能看出latent code在不同层改变时确实影响的是很准确的不同的特征,说明style的解耦和还蛮成功的。

这个效果实在太好了:第一行的sourceB表示的是latent code B直接生成的图像,第一列sourceA表示的是latent code A直接生成的图像,然后接下来的coarse,middle,fine from B就是表示latent code A 到 B 在不同节点转换的结果。可以看到coarse那几行,图像整体改变是很大的,姿势发型等都变成了source B中的样子,说明确实低分辨率时latent code控制的是整体而粗糙的特征;接下来middle的几行,发型等变化变得很小,但面部细节改变的更多;到最后fine的时候,肤色发色等细节才改变,而其他方面source B已经无法产生影响了。
2. noise inputs
StyleGAN生成器的右侧还加入了方块B,这表示噪声。StyleGAN中认为,加入随机的噪声可以帮助生成图像更多样化也更真实。比如头发部分,发丝的细节有很高的随机性,真实情况也确实如此,只要服从正确的分布,随机采样得到的结果仍然是合理的。
之前的生成器是如何保证生成图像的多样性的呢?之前生成器的输入只有一个,也就是说网络的变量其实只有这一个输入的latent code。要想具有多样性,只能在后续的操作中实现:需要时,从前一层的激活值中产生空间上有变化的伪随机数值。这种变化其实是具有一定周期性的(可能因为是伪随机吧,虽然我不太懂),很难不重复,因此我们会看到生成图像中总是会有很多相似的图像。StyleGAN则是在每一次卷积后给每个像素都加了噪声以实现多样性,而且效果很好,这个噪声只影响了需要多样性的局部,不改变图像关键的特征,如下图所示:

图(b)就是需要多样性的部分,图(c)是对100种随机噪声的结果进行了平均,像素值大的也就是偏白色的部分就是每一次叠加噪声都会影响的部分,可以看到几乎都是头发,背景等这种局部,关键的眼部,面部和姿态等都未受到影响。另一个效果图也很有趣:

这里图(a)是每一层都加了noise的结果,图(b)是未加noise,图(c)是在高分辨率加上了noise,图(d)则是在低分辨率加上了noise,可以看到图像都有区别,noise在不同层产生的影响也各不同,全部加上noise明显最真实而且细致。这可以看作生成器其实在每一层都有多样性的需求,因此在每一层都加上noise时,网络就会从最简洁的方法获取多样性(noise)这里,而不是自己产生伪随机变化了。
文中有提到,style模块(就是latent code和AdaIN那部分)控制的是整体的图像风格,因为所有的操作都是针对整张特征图的;随机噪声的部分则是控制了图像局部的多样性,因为噪声是单独加在了每个像素上的,每个像素改变的值都不同。如果生成器想通过随机噪声的部分改变图像风格,判别器会抑制这种行为(没太懂)。
在latent code解耦和的部分,文中提出了两个度量方法:Perceptual path length和Linear separability。因为这部分理论不太懂,打算再查查资料或者其他论文再说。